소개글
각종 컨퍼런스에 나온 강연들을 정리해보면서 공부해보고 있습니다.
이번 포스팅은 if(kakao) 2022에서 신동화님께서 강연해주신 내용을 정리했습니다.
제목은 "터치 습관으로 비대면 금융을 더 안전하게"이며 터치 습관을 통한 인증 모델 개발에 대한 내용입니다.
말투는 편한 말투로 작성하니 양해 부탁드립니다.
발표내용
터치 습관을 이용한 인증
기존 인증 방식
- 지식 기반: 패스워드, PIN, 패턴
- 누가 홈쳐 보거나 스마트폰 화면의 자국으로 공격 위험성 존재
- 소유 기반: OTP, 인증서
- 매번 소유해야한다는 점때문에 불편함
- 생체 기반: 지문, 얼굴, 홍채, 터치 습관
무자각 인증이란
- 사용자의 무의식적인 행동패턴과 생체정보를 활용하여 명시적인 인증절차 없이 신원을 검증하는 기술
- 터치 습관을 이용하여 무자각 인증 방식을 개발하기로 함
터치 습관이란
- 인증 비밀번호 6자리를 입력한다고 가정했을 때, 각 사용자들이 가진 고유한 입력 리듬이나 패턴을 의미
- 터치 압력, 좌표, 스마트폰 센서 값 등도 함께 고려
터치 습관을 인증에 이용하겠다는 발상이 정말 기발한 것 같습니다.
만들게 된 계기
인증 결과도 중요하지만 과정도 중요함

- 카카오 뱅크 특성상 신분증과 스마트폰만 있다면 비대면 업무를 쉽게 할 수 있음
- 전체 사기 사건중 회원가입 직후 위와 같은 사기가 일어나는 비율 - 41.35%
- 그 중에서도 50대 이상 비율 - 86.86%

- 만약 터치 습관을 통해 추론한 고객의 연령대와 신분증 상의 연령대의 일치 여부를 확인할 수 있다면 사기를 막을 수 있을 것임
요즘 스마트폰 앱이 발달하면서 비대면 업무가 쉽게 이루어지고, 그만큼 사기 사건도 많이 일어난다고 합니다.
분석
인증 비밀번호에 우선 적용
- 금융활동시 가장 많이 접하는 화면 중 하나
- 회원가입 시 필수적으로 인증 비밀번호를 등록
- 추후 다른 화면들에도 적용 예정
분석에 사용한 데이터
- 터치 시간, 터치 좌표, OS, 화면 크기, 성별, 연령대 등
분석 결과
터치 리듬 유사도
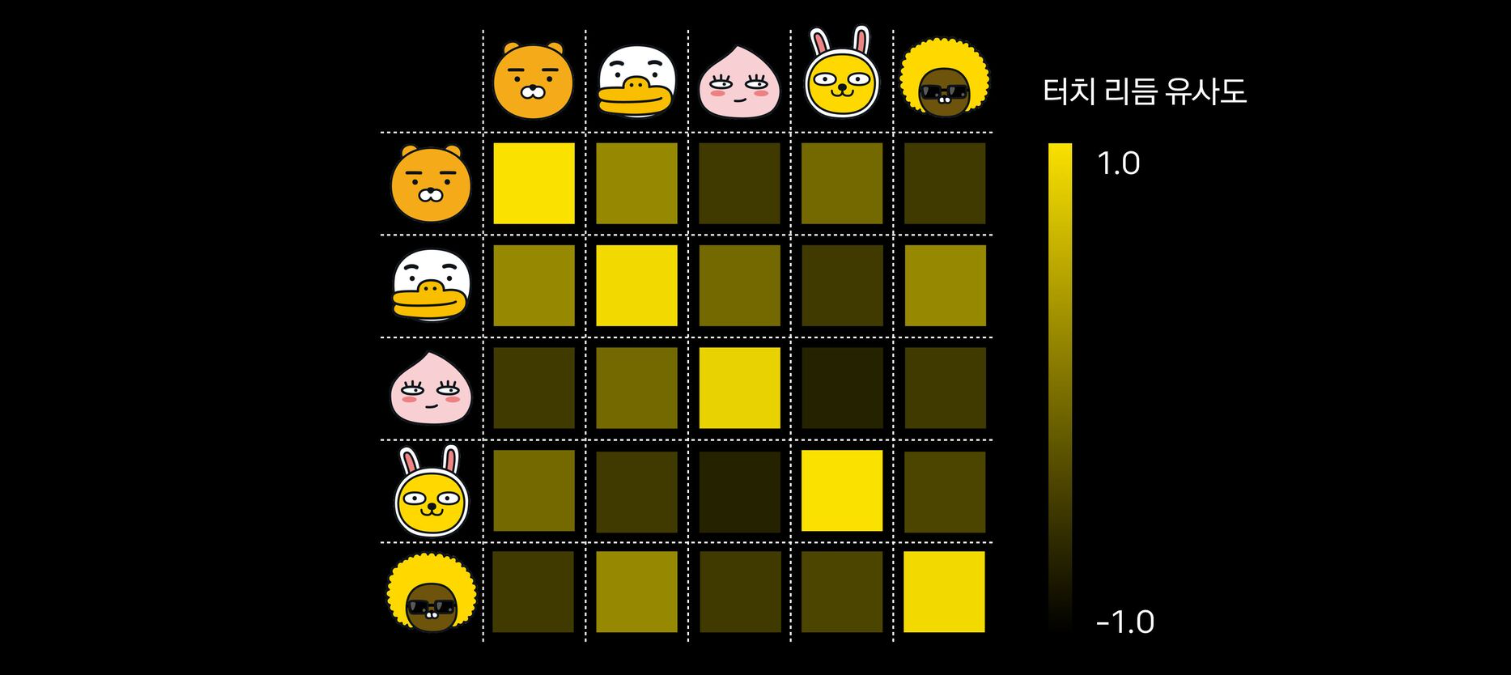
- 터치 시간 간격 리듬이 어느 정도 존재한다는 것을 파악할 수 있음
- 유사도 매트릭스를 보면 같은 사용자의 입력끼리는 유사 점수가 높음
남성/여성 터치 영역

- 남성은 버튼의 좌측하단, 여성은 버튼의 우측하단을 주로 입력하는 것을 확인할 수 있음
- 다만 이 차이가 성별때문이 아닐 수 있기 때문에 해석에 주의해야함 (왼손잡이 남성이 많았다면?)
터치 시간차
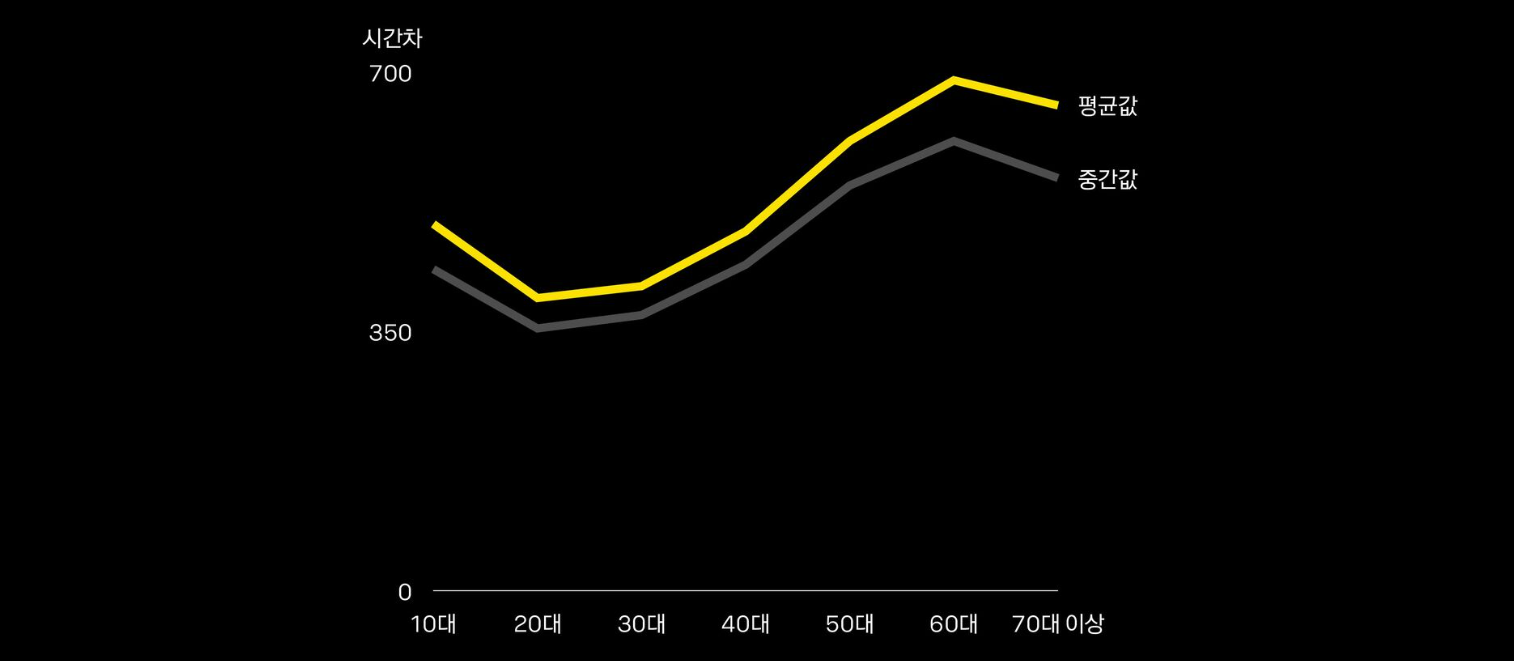
- 연령대 별 터치 시간차를 보면 고연령대가 확실히 높음
- 다만 10대의 시간차도 비교적 높은 편임
고연령/비고연령 터치 영역

- 고연령일 수록 중앙을 많이 터치하는 것을 확인
실데이터 터치 시간차 리듬
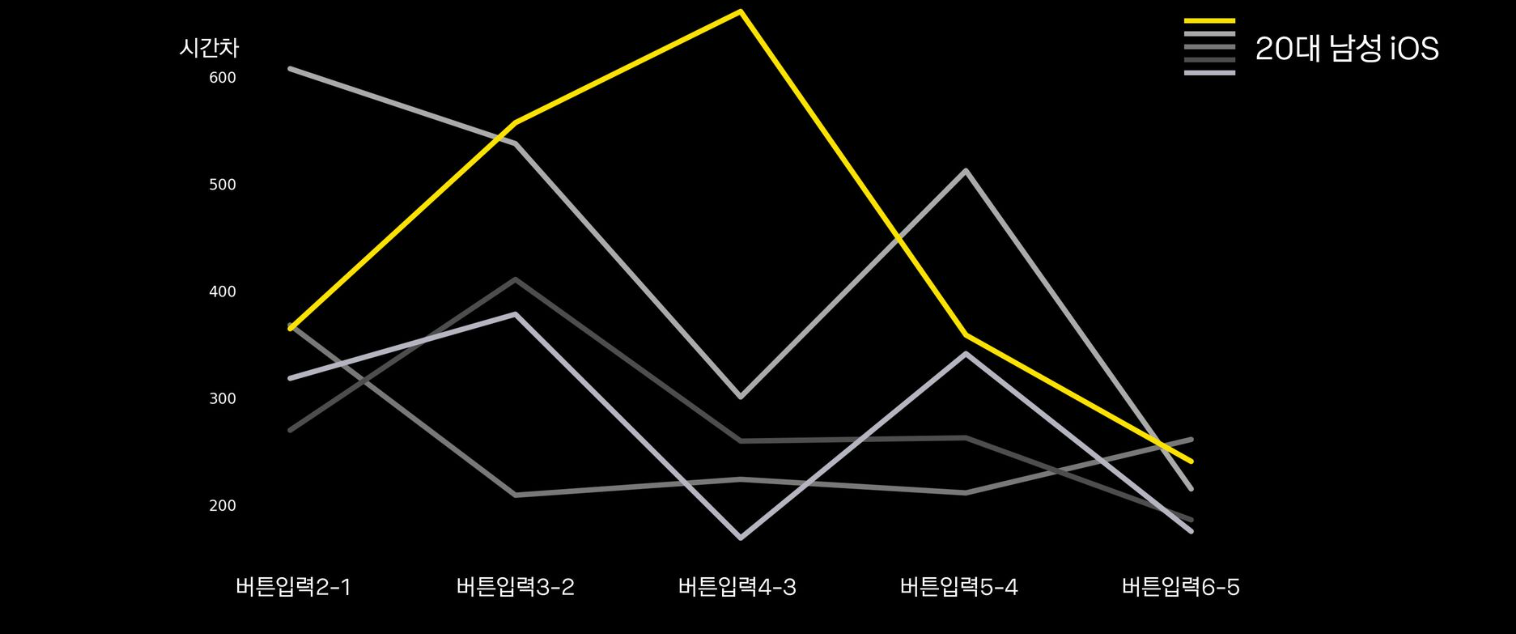
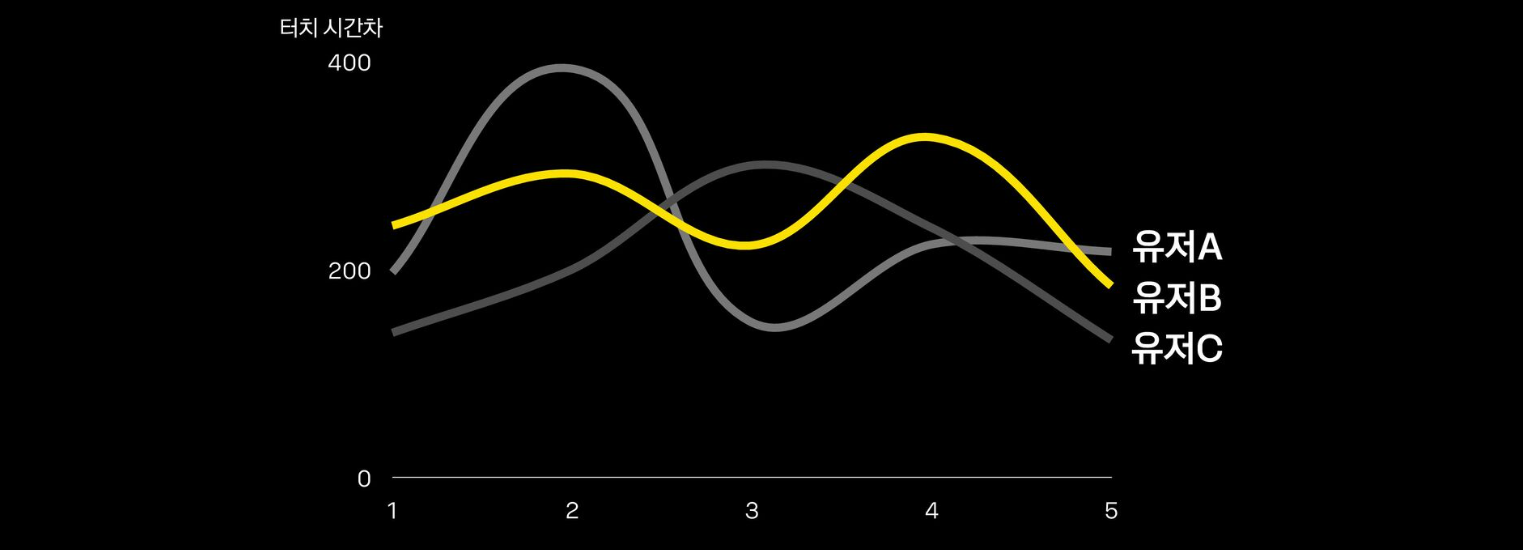
- 아이폰을 사용하는 20대 남성들의 데이터로서, 성별, 연령대, 스마트폰의 OS가 모두 같음에도 각각 리듬이 다름
- 비슷한 리듬에 대해서는 터치 좌표 확인 필요
실데이터 터치 좌표
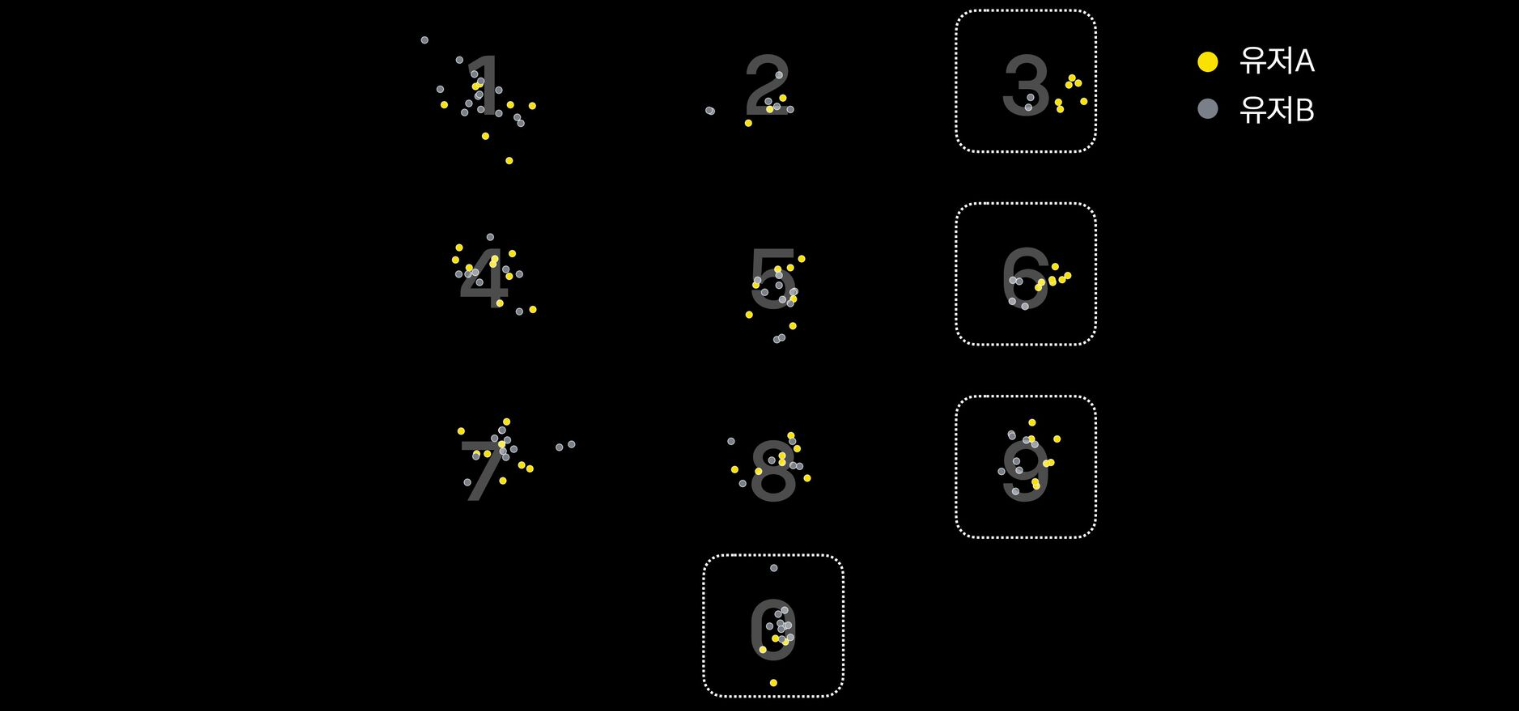
- 3, 6, 9에 대해서는 유저 A의 입력 좌표가 좀 더 오른쪽에 치우쳐져 있는 것을 확인 가능
개발
모형 개발을 위한 데이터 구성
- 터치 시간과 좌표 값으로 부터 총 75개의 파생 변수 생성
- 고연령 분류(50대 이상) 및 사용자 인증 모형에 사용
고연령 분류 모형
- 일반적인 binary classification 문제로 해결 가능
사용자 인증 모형
- 사용자별로 훈련 데이터가 많지 않음
- 전체 사용자의 89%가 5개 이내의 인증 수를 가짐
- 따라서 Metric learning 방법론을 사용하기로 함
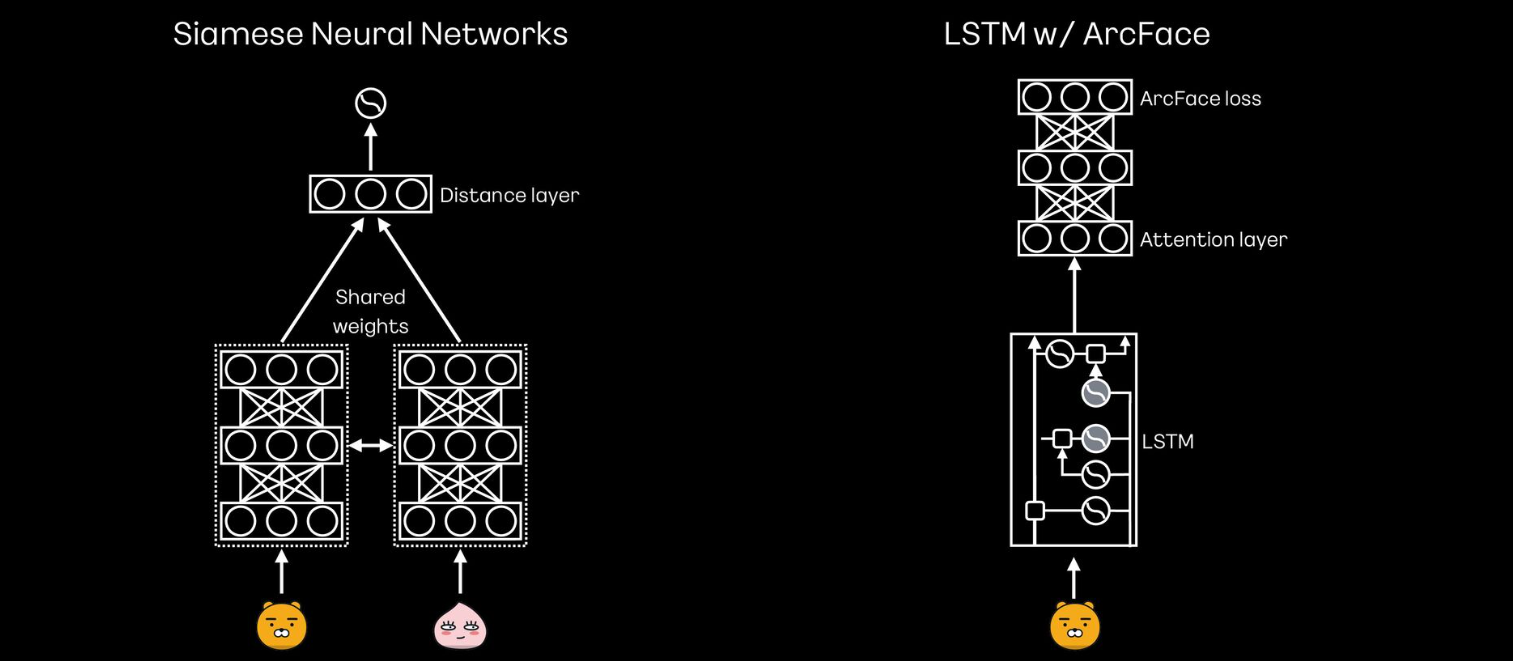
- Siamese Neural Network와 LSTM 모델을 사용
Siamese Neural Network
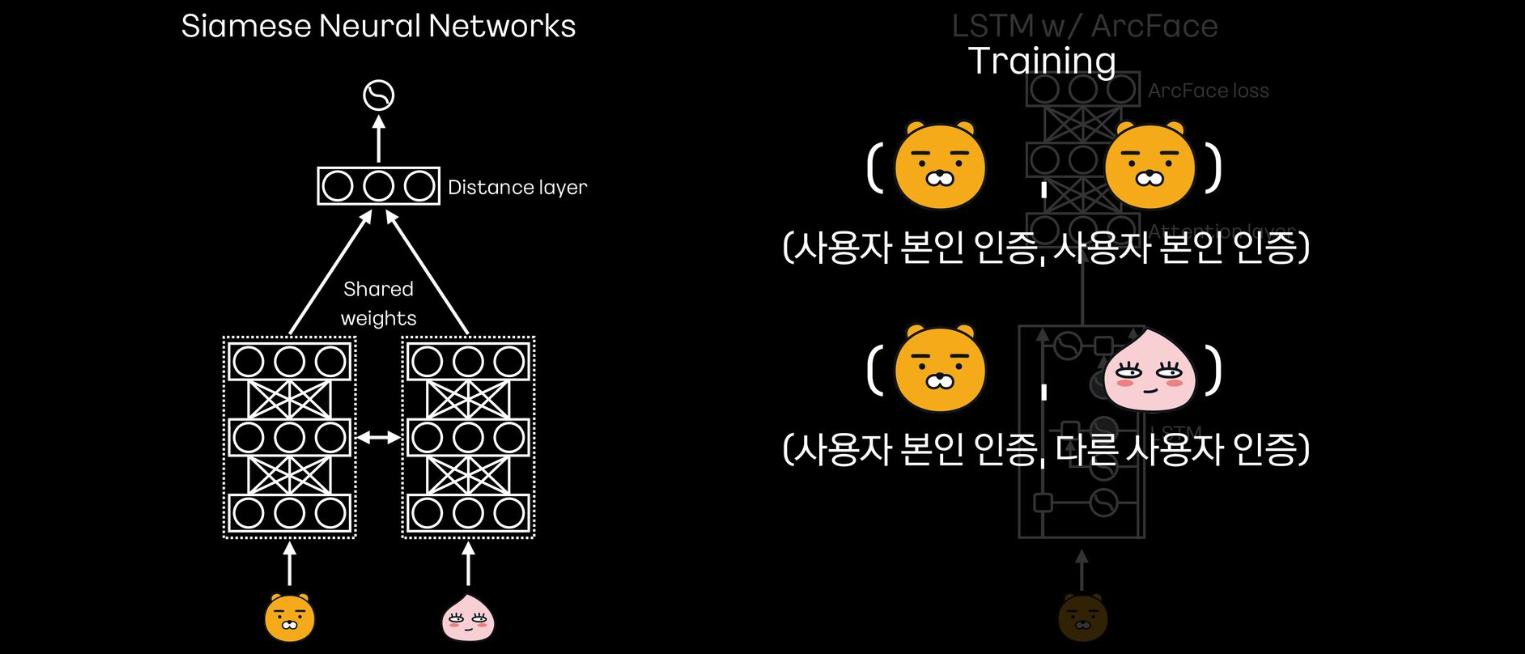
- 동일한 사용자의 인증 페어와 서로 다른 사용자의 인증 페어를 인풋으로 넣어서 훈련
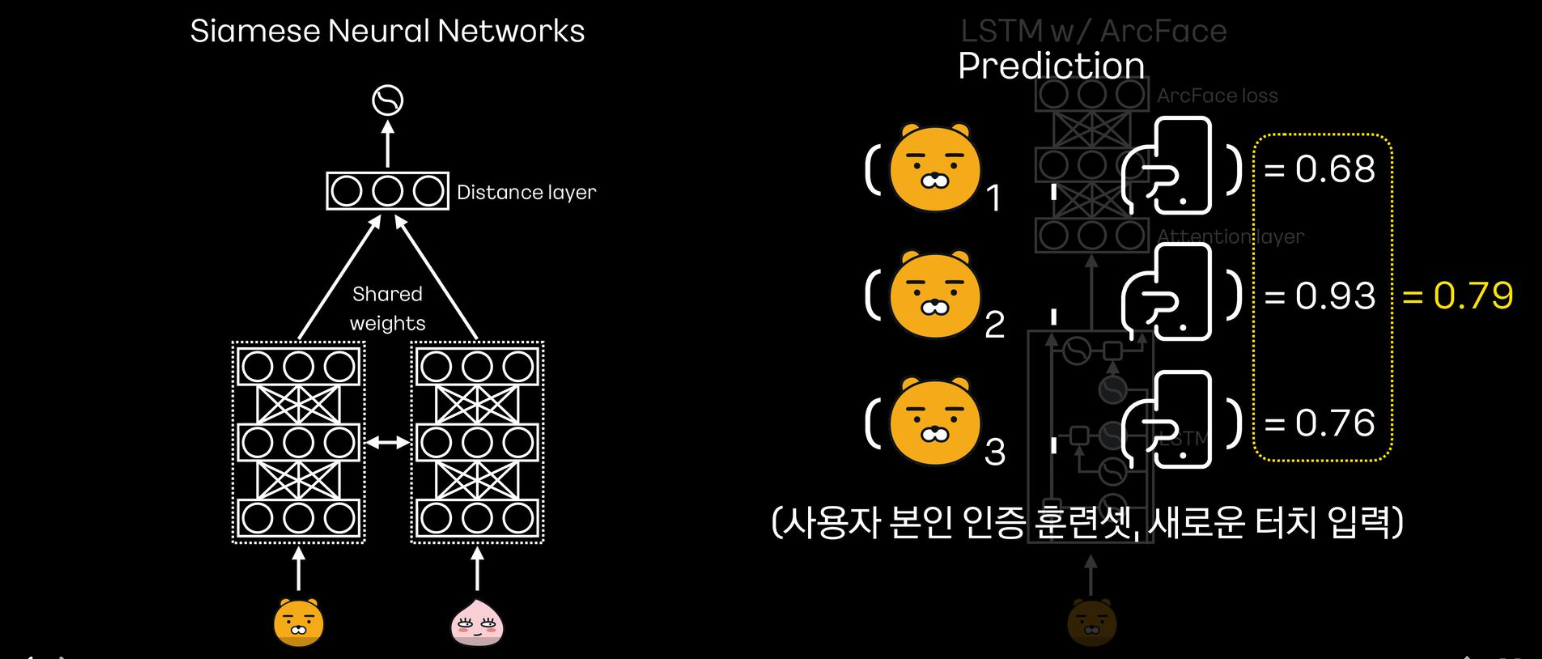
- 인증에 사용할 때는, 새롭게 들어온 터치 데이터를 사용자 본인의 데이터와 페어를 만들고 유사도 값을 계산
- 그 후 유사도 값의 평균을 구해서 특정 임계치보다 높으면 본인이라고 판단
LSTM
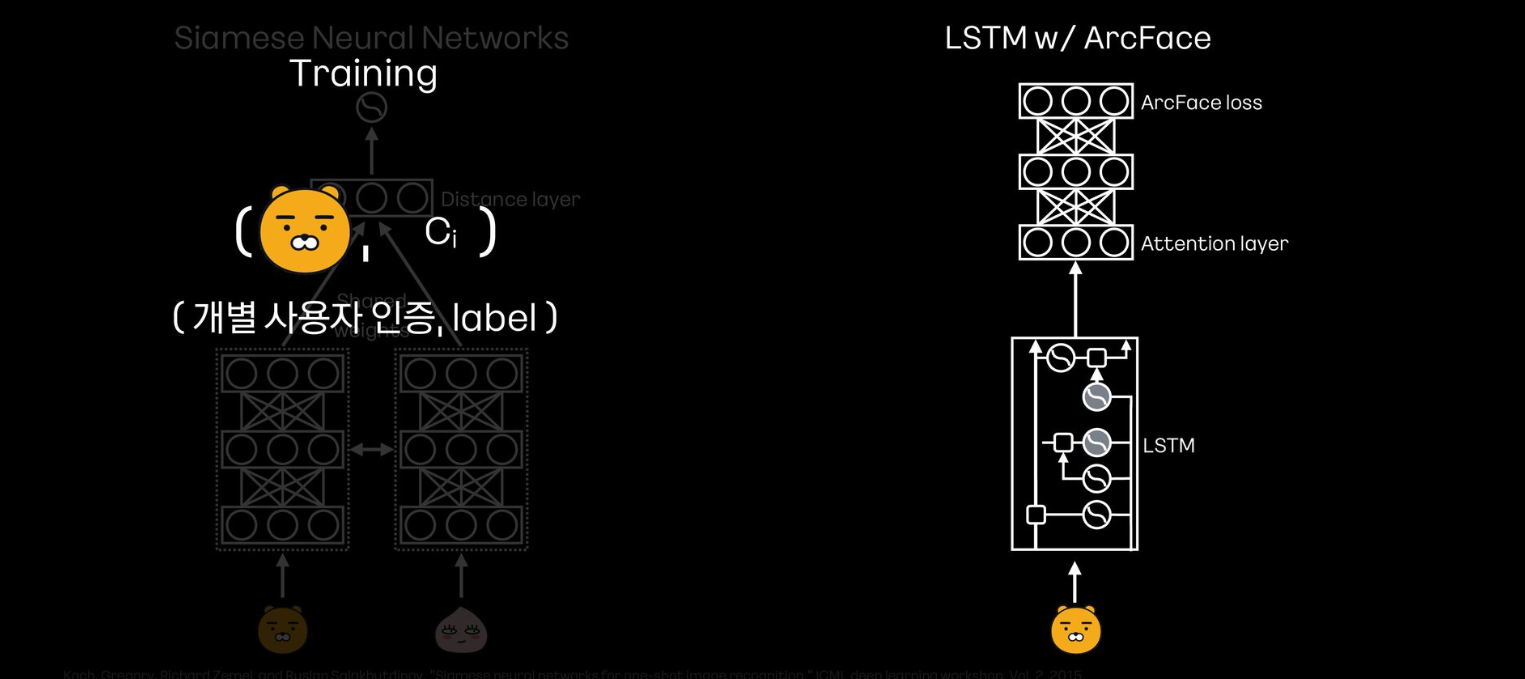
- 각 사용자의 인증과 라벨을 인풋으로 넣고 훈련
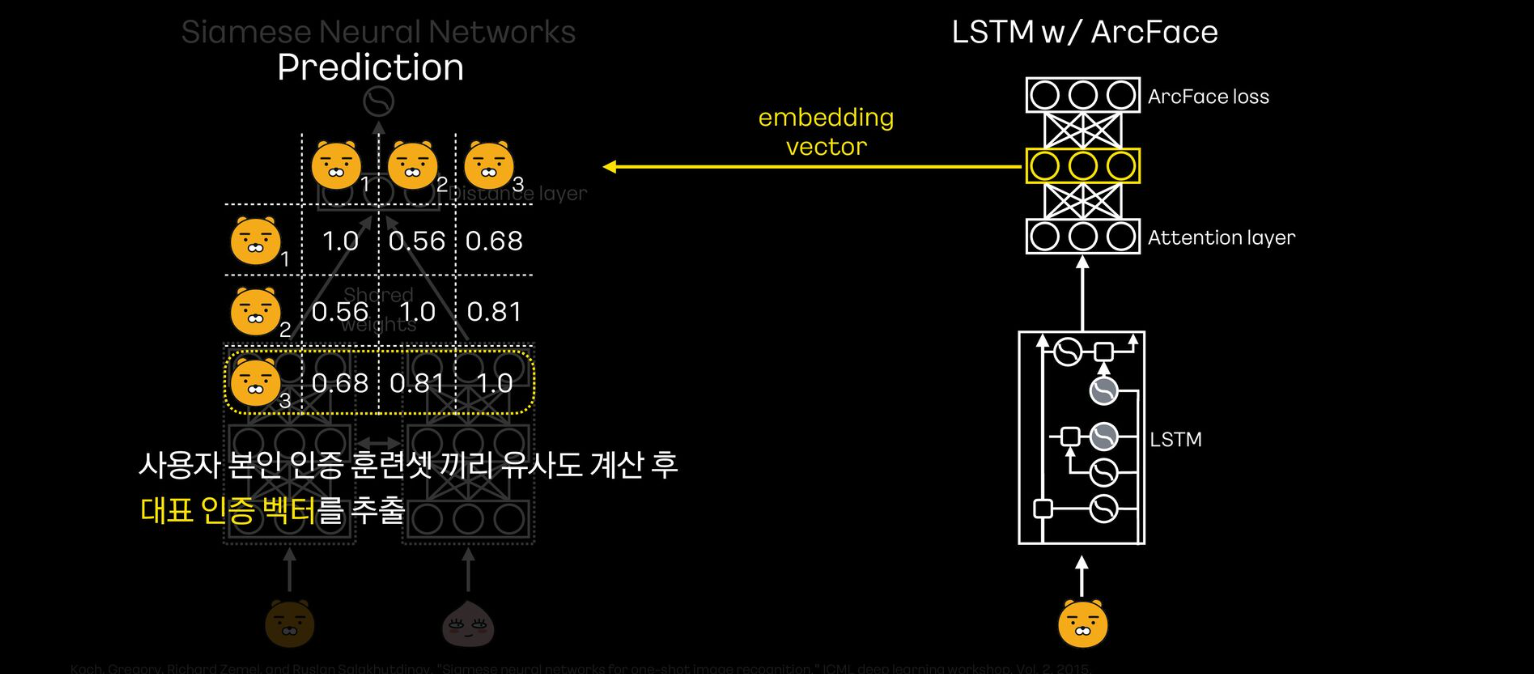
- 인증에 사용하기 위해, 우선 사용자의 인증 데이터를 모형에 넣고 embedding vector를 추출함
- 이후 인증 훈련셋끼리 코사인 유사도를 계산하고, 평균값이 가장 높은 벡터를 대표 인증 벡터로 추출
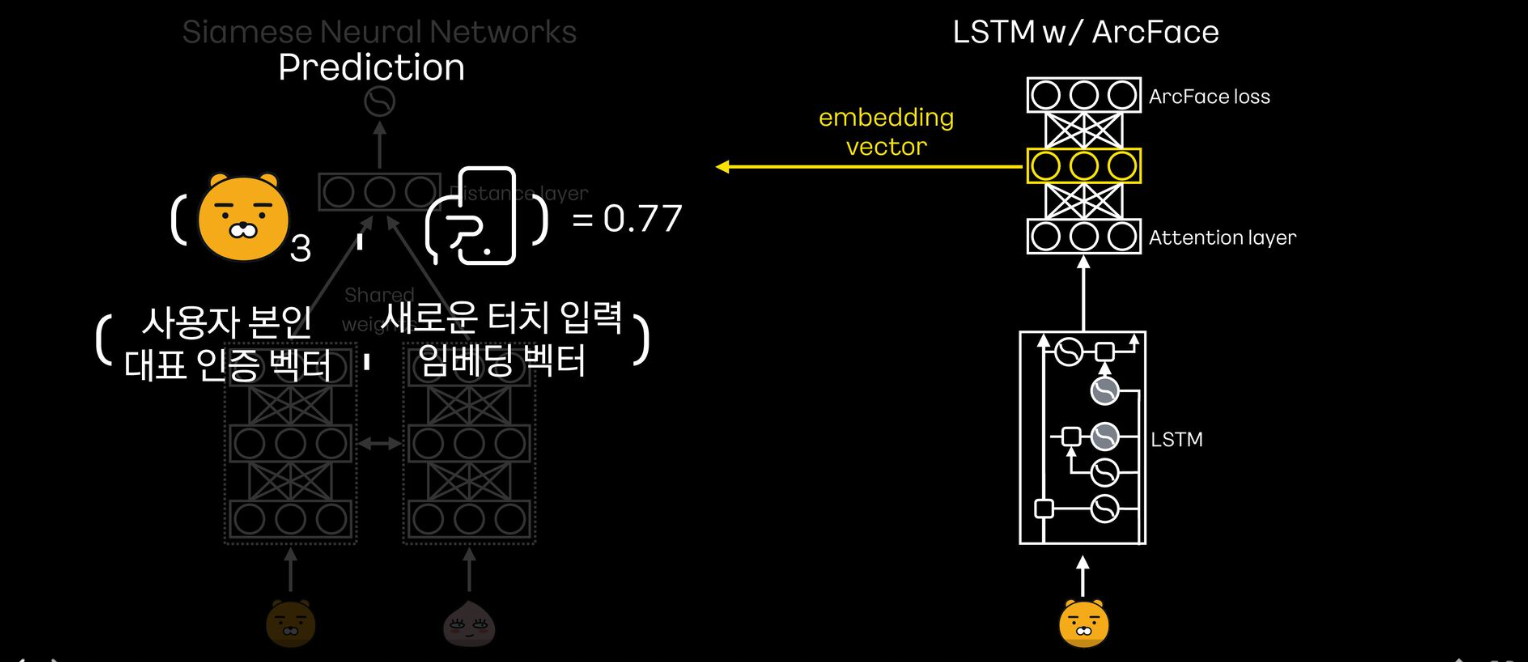
- 인증을 위해, 새롭게 들어온 터치 데이터를 모형에 넣어서 embedding vector를 추출하고, 사용자 본인의 대표 인증 벡터와 코사인 유사도를 계산함
- 유사도가 특정 임계치보다 높다면 본인이라고 판단
Classification vs Metric Learning
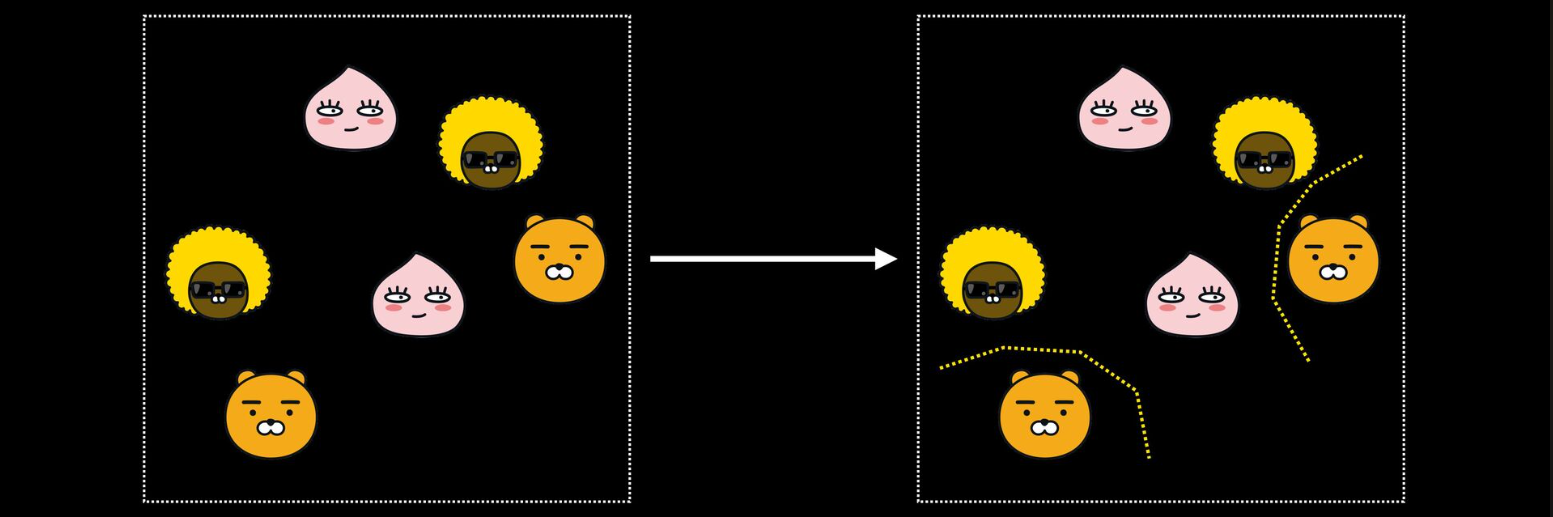
- 일반적인 Classification에서는 분류를 위한 경계선을 찾게 됨
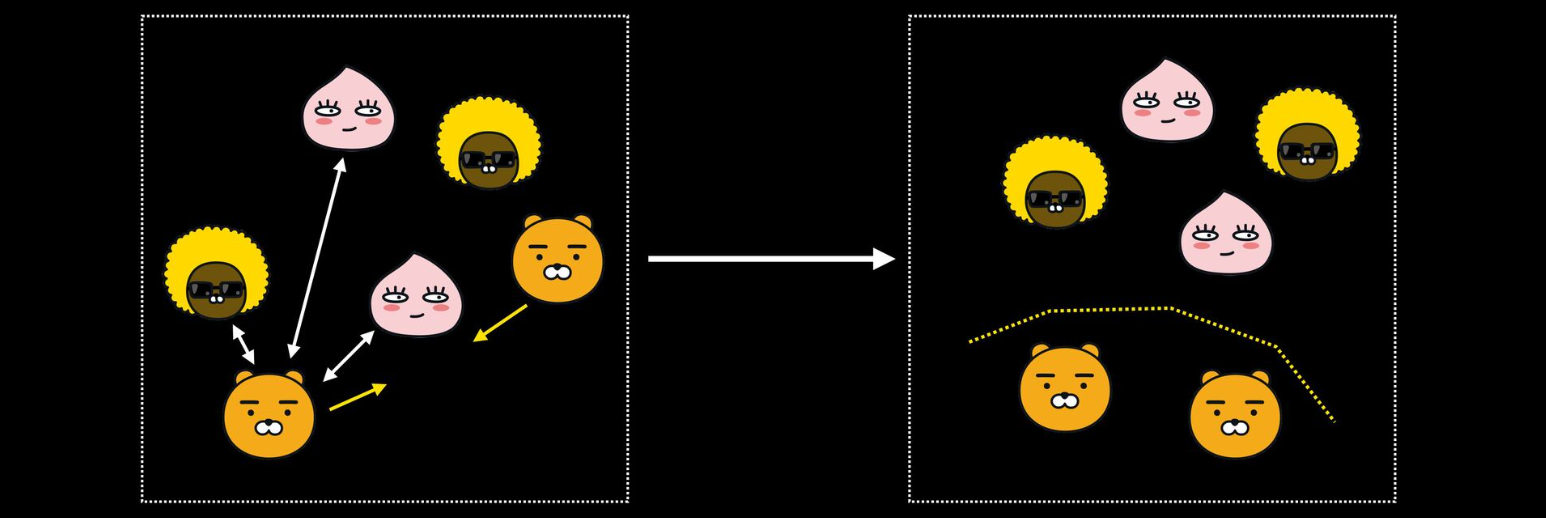
- Metric Learning에서는 같은 클래스의 객체들끼리는 더 가깝게, 서로 다른 클래스 객체들끼리는 더 멀어지게 하는 embedding space를 학습함
- 결국 서로 같다라는 정보 외에도 서로 다르다라는 정보를 이용하는 것
성능 지표
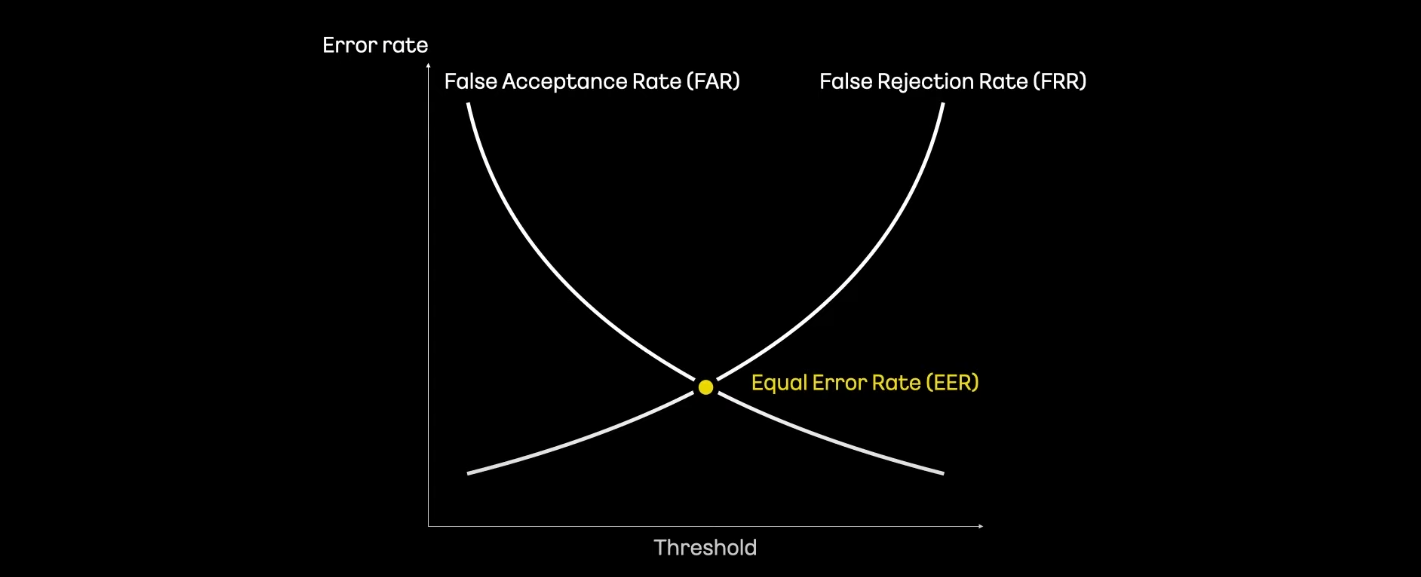
- 성능 지표로는 EER을 사용
- EER은 타인이 허용되는 비율을 의미하는 FAR과 본인이 거절되는 비율인 FRR이 같아지는 지점
- EER 값이 낮을 수록 성능이 좋은 것임
실험 결과
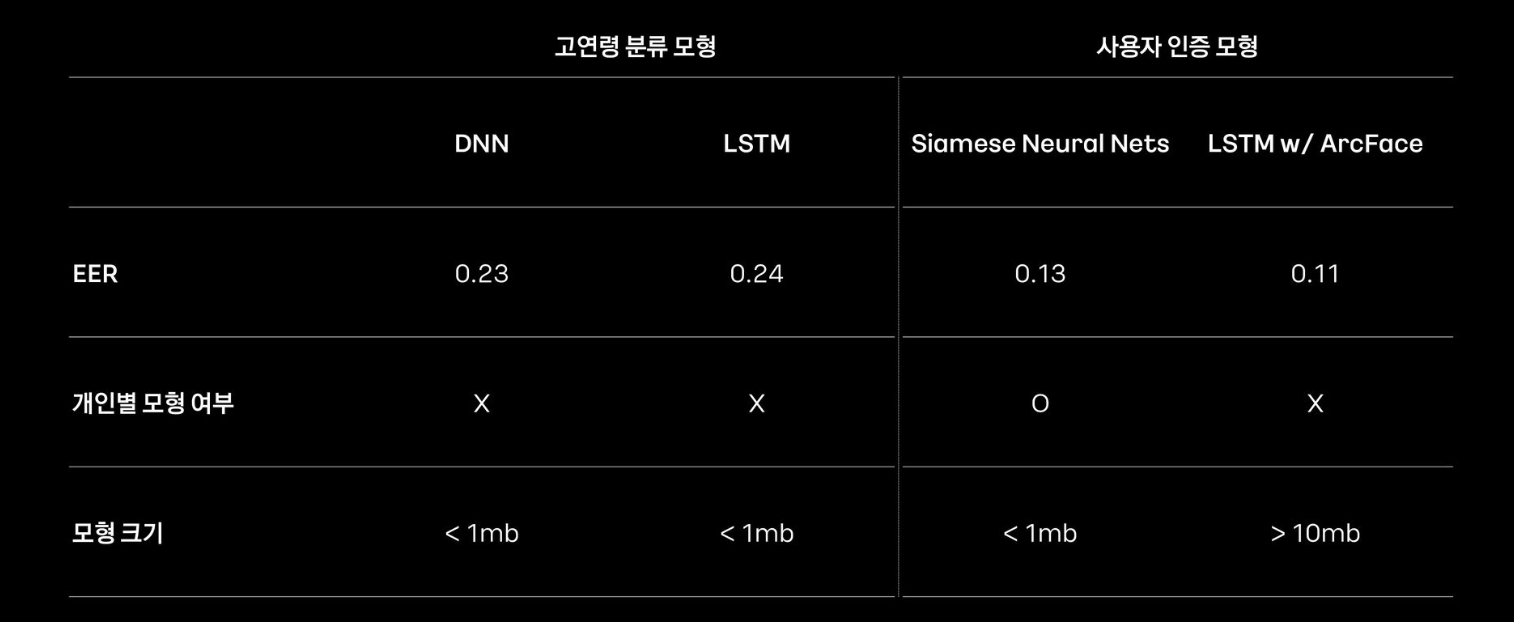
많은 양의 데이터로 먼저 학습시키고 객체를 분류하는 classification과는 달리, 데이터가 많이 없다면 Metric Learning을 사용할 수 있다고 합니다.

개발을 하며 경험한 것들을 이것저것 작성해보고 있습니다!