
B-트리
- 2-3 트리를 일반화 한 것.
- 삽입, 삭제 과정은 2-3 트리와 거의 동일하나,
- 차수(한 노드당 자식의 수)가 m 인 B-트리의 성질
- 루트는 자식이 없거나
2~m개의 자식 노드를 가짐.
- 루트는 자식이 없거나
- 루트를 제외한 모든 비단말 노드는
[m/2]~m개의 자식 노드를 가짐.
-> 자식 노드가 m 개라는건 간선이 m개니까 위의 노드에 들어갈 수 있는 자료의 수는 m-1개.
- 루트를 제외한 모든 비단말 노드는
- 모든 단말 노드는 루트로부터의 경로 길이가 동일함. (== 같은 레벨에 있다)
- 데이터베이스와 파일시스템에서 널리 사용된다.
ADT
// InsertFail : 이미 가지고 있는 값인 경우
// SearchFail : 트리에 값이 없음
// Success : 성공
// InsertIt : ?
// LessKeys : ?
enum KeyStatus { InsertFail, SearchFail, Success, InsertIt, LessKeys };
void insert(int);
void delNode(int);
enum KeyStatus ins(BTreeNode*, int, int*, BTreeNode**);
int searchPos(int, int *, int);
enum KeyStatus del(BTreeNode*, int);구현
구현은 직접 해보고 싶었는데 사실 B트리에 내 머리로 넣고 빼고 하는 것도 잘 이해 안가서 Bale 님의 코드를 참고했다. 해당 코드를 이해하고 학부 때 들은 자료구조 강의에서 쓰던 변수 방식으로 바꾸어보면서 공부했다. 원래 자료구조 코드 전체 프로세스를 외우려고 하는 편인데 이건... 못 외울듯.... 그래도 한 3일 정도 쏟으니까 이해는 할 수 있었다.
차수가 M이면 노드는 M-1 개의 데이터를 가질 수 있음.
자료형
typedef struct {
int n; // 가지고 있는 노드의 수
int data[M-1]; // 하나의 노드가 가질 수 있는 데이터 수
BTreeNode *child[M]; // subTree
} BTreeNode;
BTreeNode *root = NULL;탐색 in 노드
노드 안에 여러개의 값이 들어가 있으니
- 삽입할 땐 해당 노드에 몇 번째에 값이 들어가는지
- 삭제할 땐 어떤 노드의 몇 번째 값을 삭제하는지
알아야함.
// 해당 노드에서 찾는 값의 위치 찾기
int searchInNode(int key, int *key_arr, int n) {
int pos = 0;
while (pos < n && key > key_arr[pos])
pos++;
return pos;
}삽입
- 루트인 경우 -> 삽입
- 루트는 아니지만
- 노드에 삽입할 수 있는 경우 -> 삽입
- 노드가 꽉차서 삽입할 수 없는 경우 -> 3. 분할
- 노드 맨 마지막 위치에 삽입하는 경우 -> lastKey, lastPtr을 새로운 값으로 사용.
- 노드 맨 마지막이 아닌 경우 -> 하나씩 밀고 마지막꺼 lastKey, lastPtr 로 사용.
void insert(BTreeNode *root, int key) {
BTreeNode new;
int upKey; // 올라갈 키
enum KeyStatus value;
value = ins(root, key, &upKey, &new);
if (value == InsertFail)
printf("이미 %d 값이 존재합니다.", key);
if (value == InsertIt) {
BTreeNode *uproot = root;
root = (BTreeNode*)malloc(sizeof(BTreeNode));
root->n = 1;
root->data[0] = upKey;
root->child[0] = uproot;
root->child[1] = new;
}
}실제 삽입을 처리하는 부분.
// 삽입 처리(상태 파악)
enum KeyStatus ins(BNode* node, int key, int *upKey, BNode* *newnode)
{
// new 는 삽입될 노드, last 는 삽입될 위치의 직전 노드
BNode *newPtr, *lastPtr;
int pos, i, n, splitPos;
int newKey, lastKey;
enum KeyStatus value;
// 1. 노트가 비어있음
// 첫 값일 경우 새로운값 할당 (상태값 초기화 값 반환)
// 근데 루트가 아닐 경우 data 가 [M/2] 개 이상이어야 하니까
// 그것보다 적은 경우 회전이 필요함.
if (node == NULL)
{
*newnode = NULL;
*upKey = key;
return InsertIt;
}
// 2. 노드가 비어있지 않음
// 개수 cnt
n = node->n;
// 해당 노드에서 몇번째 인지 위치 찾기
pos = searchInNode(key, node->data, n);
// 2-1. 해당 위치에 이미 있는 값일 경우 (실패)
if (pos < n && key == node->data[pos])
return InsertFail;
// 2-2. 해당 노드에 없다면 자식 노드에 삽입이 가능한지 찾아보기.
// 원래 무조건적으로 자식노드로 내려가서 삽입됨.
value = ins(node->child[pos], key, &newKey, &newPtr);
// 삽입 아닐 경우 단순 반환(탈출용)
if (value != InsertIt)
return value;
// 2-3. 자식 노드에 삽입 가능한 경우
// 2-3-1. 해당 BNode의 data 수가 M-1보다 작을 경우 (노드에 추가)
if (n < M - 1)
{
// 새 노드의 해당 위치를 가지고 온다
pos = searchInNode(newKey, node->data, n);
// 삽입 추가를 위해 오른쪽으로 한칸씩 이동(data, ptr)
for (i = n; i>pos; i--)
{
node->data[i] = node->data[i - 1];
node->child[i + 1] = node->child[i];
}
// 해당 위치에 데이터 추가
node->data[pos] = newKey;
node->child[pos + 1] = newPtr;
++node->n; // 개수 1개 증가
return Success; // 성공 반환
}
// 2-3-2. 해당 BNode 의 data 수가 M - 1
// 2-3-2-1. 이면서 마지막 값 한자리 남았을 경우
if (pos == M - 1)
{
lastKey = newKey;
lastPtr = newPtr;
}
// 2-3-2-2. 자리가 다 찼고 삽입할 위치 마지막 아닐 경우
else
{
// 중간에 값을 갈라준다(올려줄 값)
lastKey = node->data[M - 2];
lastPtr = node->child[M - 1];
for(i = M - 2; i > pos; i--)
{
node->data[i] = node->data[i - 1];
node->child[i + 1] = node->child[i];
}
// 해당 위치에 새로운 값 할당
node->data[pos] = newKey;
node->child[pos + 1] = newPtr;
}
// 2-3-3. 분할
// 나눠줄 오른쪽 위치
splitPos = (M - 1) / 2;
// 올라갈 값(중심값)
(*upKey) = node->data[splitPos];
// 새노드 할당
(*newnode) = calloc(1,sizeof(BNode));
// 개수를 잘려진 수로 할당(split)
node->n = splitPos;
// 새노드의 수는 나머지 수 -1
(*newnode)->n = M - 1 - splitPos;
// 반복문을 통해 자식 관계 처리
for (i = 0; i < (*newnode)->n; i++)
{
// 새노드의 자식노드에 기존 ptr의 자식 노드 수 할당
(*newnode)->child[i] = node->child[i + splitPos + 1];
// 데이터 옮기기
if (i < (*newnode)->n - 1)
(*newnode)->data[i] = node->data[i + splitPos + 1];
// 마지막 키 값 넣기
else
(*newnode)->data[i] = lastKey;
}
// 개수값 할당 및 상태값 반환(재귀적으로 계속 체크)
(*newnode)->child[(*newnode)->n] = lastPtr;
// 이 과정이 끝나면 node (원래 타겟 노드) 에는 ~splitPos 까지 내용이 들어있는 거고,
// newnode 에는 splitPos + 1 ~ 부터 내용이 있는 것.
// 고로 새로운 키를 상단에 넣고 왼쪽을 node 오른쪽을 newnode 로 사용하면 됨.
return InsertIt;
}
삭제
- 루트를 삭제하게 되는 경우

// 삭제함수
void delNode(int key) {
BNode* uproot;
enum KeyStatus value;
// 상태값 처리
value = del(root, key);
// 상태값에 따라
// 삭제 실패일 경우
if (value == SearchFail) {
printf(fp2, "Key %d 값을 찾을 수 없습니다! \n", key);
}
// 루트 삭제의 경우
else if (value == LessKeys) {
uproot = root; // 루트를 옮겨 두고
root = root->child[0]; // 루트는 첫 번째 자식노드를 가지고
free(uproot); // 루트 노드 삭제
}
}삭제 처리
LessKeys 가 이해가 힘들었다. -> 재귀 호출에서 막힌 것이었음. 원래 공부하던 자료처럼 if - else 를 명시적으로 쓰지 않고 if { return } 해버리니까 머리가 뱅글뱅글...
차수가 5일 때, min 값은 2
- 삭제 실패의 경우 -> SearchFail - 찾는 키가 없는 것.
- 루트인 경우 (내부 노드와 같으나 min 값이 1이라는 것만 다름.)
- 리프인데
child[0] == NULL
2-1. 회전이 필요 없는 경우 -> Success
--node->n 이 min 보다 작은지?
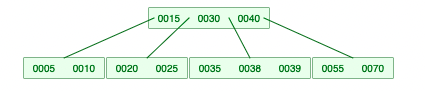
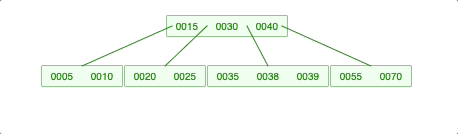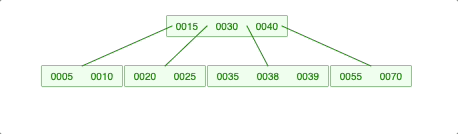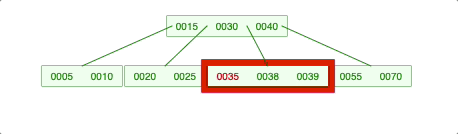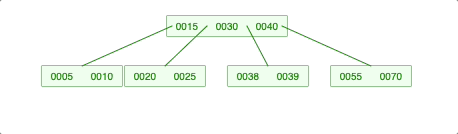
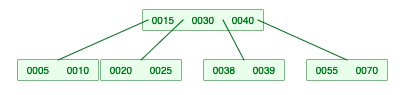
2-2. 회전이 필요한 경우 -> LessKey (나중에 재귀 호출이 돼서 처리가 되는 것임)
--node->n 이 min 보다 같거나 큰지?
2-2-1. 왼쪽 자식의 개수가 충분하면 왼쪽 자식 젤 큰 애를 가져옴.
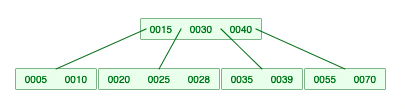
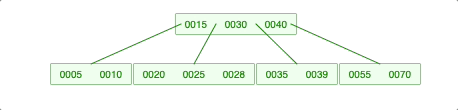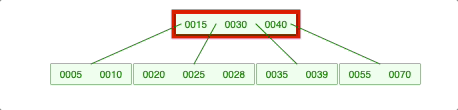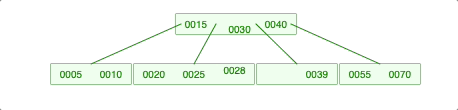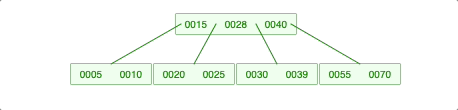
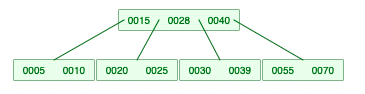
2-2-2. 왼쪽 자식의 개수는 충분하지 않지만, 오른쪽 자식의 개수가 충분하면 오른쪽 자식 젤 작은 애를 가져옴
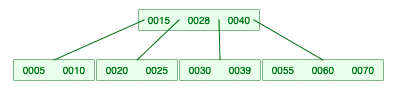
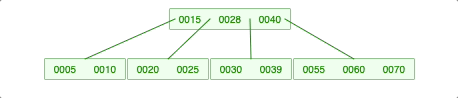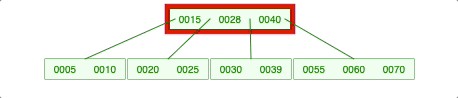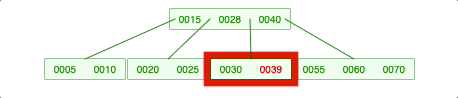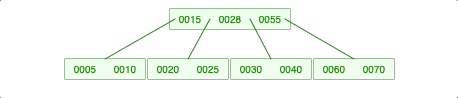
2-2-3. 양쪽 다 충분하지 않으면 위의 노드가 내려옴.
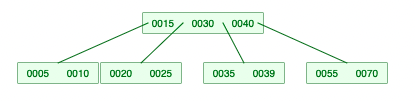
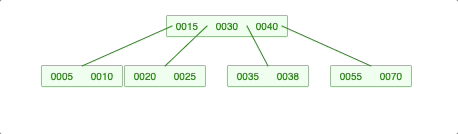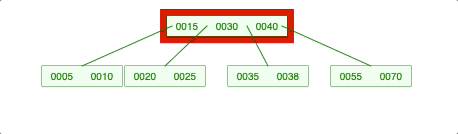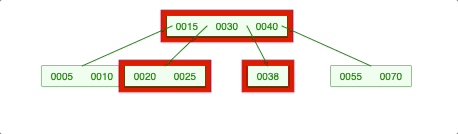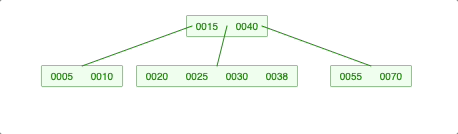
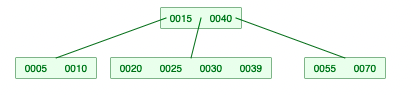
-
내부 노드이면
노드 값이랑 왼쪽 자식 제일 큰 값을 바꾼다.
재귀 호출을 통해 왼쪽 자식 제일 큰 값을 삭제 (2번으로 돌아간다.)
-> 이렇게 바뀐 리프 노드에서 LessKey 이면 회전이 필요. -> (최악의 경우 루트까지 주루루루루룩 가면서 계속 회전하게 된다.)
// 삭제 처리 (상태값 반환)
enum KeyStatus del(BNode* node, int key) {
int pos, i, pivot, n, min;
int *key_arr;
enum KeyStatus value;
BNode **child, *left, *right;
// 0. 해당 ptr이 NULL이면 삭제실패
if (node == NULL)
return SearchFail;
// 값 할당
n = node->n;
key_arr = node->data;
child = node->child;
// 자식 노드의 최소 데이터 개수.
min = (M - 1) / 2;
// 찾을 값 위치 찾기
pos = searchInNode(key, key_arr, n);
// 1. 만약 해당 노드가 leaf 노드 일 경우
if (child[0] == NULL)
{
// 탐색해서 위치 n이면 해당 노드에 없는 것임. (삭제 실패)
if (pos == n || key < key_arr[pos])
return SearchFail;
// 왼쪽으로 한칸씩 땡기기
for (i = pos + 1; i < n; i++)
{
key_arr[i - 1] = key_arr[i];
child[i] = child[i + 1];
}
// 노드 내 데이터 개수 - 1 이랑 해당 노드 최소 데이터 개수와 비교
// 2-1. 최소 데이터 개수보다 많음 -> Success
// 2-2. 적음 -> LessKeys -> root 에 있는 값을 내린다.
// ptr이 root 였다면 1과 개수 비교, ptr이 root가 아니라면 index 2 와 개수 비교
return --node->n >= (node == root ? 1 : min) ? Success : LessKeys;
}
// 3. 해당 key 값을 찾았으나 leaf 노드가 아님
// 위치가 n보다 작고 key 값 맞을 경우의 트리로 타고 내려가서
// 해당 노드에서 제일 큰 값이랑 삭제할 값 바꾸고 (이래야 올라오는 애가 다음 트리보단 작고 이전 트리보단 큰 조건에 맞음)
// 맨 마지막 값(삭제할 값이 들어간) 삭제 -> 그리고 여기서 다시 회전할 수 있는지 봄.
if (pos < n && key == key_arr[pos]) {
// qp는 위의 노드
BNode *p = child[pos];
int nkey = p->n; // key 개수
BNode *t = p->child[nkey];
while (t != NULL) {
p = t;
nkey = t->n;
t = t->child[nkey];
}
// position 정리
key_arr[pos] = p->data[nkey - 1];
p->data[nkey - 1] = key;
}
// 실제로 해당 값을 삭제하는 부분.
// key 가 원래 leaf 에 있는게 아니었는데, 교체를 해서 leaf 에 가있으므로
// 이렇게 재귀 호출을 하면 leaf 에서 지워지고, 회전할지 말지 판단해줌.
value = del(child[pos], key);
// 3-1. 회전 필요 없음.
if (value != LessKeys)
return value;
// 3-2. 삭제를 했는데, 회전이 필요 (LessKeys)
// 해당 위치가 있고 개수가 최소 회전위치보다 클 경우 회전 처리
// pos 에 있는 녀석이 수가 부족하면 그 옆 녀석에서 하나 가져와서 회전.
// 여기서 node 는 leaf가 아닌 녀석.
// 2-2-1. 왼쪽 마지막 값을 윗 노드로 가져오면 되는 경우.
if (pos > 0 && child[pos - 1]->n > min)
{
// 턴할 위치는 해당 pos -1
pivot = pos - 1;
// 왼쪽 ptr
left = child[pivot];
// 오른쪽 ptr
right = child[pos];
// 오른쪽 노드 맨 첫번째에 값을 할당하기 위해 하나씩 민다.
// 우리는 높이 2짜리로 했지만 높이가 더 높으면 충분히 child 도 있을 수 있음.
right->child[right->n + 1] = right->child[right->n];
for (i = right->n; i>0; i--)
{
// data, ptr 옮기기
right->data[i] = right->data[i - 1];
right->child[i] = right->child[i - 1];
}
// 개수 증가 : 이미 삭제를 한 상태라서 그럼.
right->n++;
// 첫 값은 pivot
right->data[0] = key_arr[pivot];
// 첫 자식 값은 왼쪽 ptr의 왼쪽 개수
right->child[0] = left->child[left->n];
// key _arr 피벗 돌기에 왼쪽 array값
key_arr[pivot] = left->data[--left->n];
return Success;
}
// 2-2-2. 오른쪽 젤 작은 값을 윗 노드로 가져오면 되는 경우.
if (pos < n && child[pos + 1]->n > min)
{
// pivot에 해당 위치값 넣기
pivot = pos;
// 피벗 기준에 따라 위치 지정
left = child[pivot];
right = child[pivot + 1];
// 왼쪽 ptr 값 할당
left->data[left->n] = key_arr[pivot];
// 왼쪽 ptr의 개수 처리
left->child[left->n + 1] = right->child[0];
// key_arr 피벗에 첫번째 data 넣기
key_arr[pivot] = right->data[0];
// 왼쪽 ptr은 개수 증가
left->n++;
// 오른쪽 ptr은 개수 감소
right->n--;
// 오른쪽 노드의 자식노드 개수만큼 처리 (한칸씩 당기기)
for (i = 0; i < right->n; i++)
{
right->data[i] = right->data[i + 1];
right->child[i] = right->child[i + 1];
}
// 오른쪽 ptr의 개수 위치에 오른쪽 ptr 개수 +1 할당
right->child[right->n] = right->child[right->n + 1];
return Success;
}
// 2-2-3. 삭제할 노드의 왼오가 전부 min 보다 작거나 같아서 가져올 수가 없음.
// 루트가 내려온다.
// 해당 위치가 n 일 경우
// 루트가 내려오고 왼쪽 노드랑 합쳐야 하니까. 본인이 right
if (pos == n)
pivot = pos - 1; // 피벗은 pos-1
// 그 외
// 루트가 내려오고 오른쪽 노드랑 합칠 것임. 본인이 left.
else
pivot = pos; // 피벗은 pos
// lptr, rptr - pivot 위치 할당
left = child[pivot];
right = child[pivot + 1];
// 왼쪽 ptr에다가 오른쪽 값 합쳐주기
left->data[left->n] = key_arr[pivot];
left->child[left->n + 1] = right->child[0];
// rptr 개수 만큼 왼쪽 ptr의 값에다가 오른쪽 ptr의 값을 할당해주기(나누기)
for (i = 0; i < right->n; i++)
{
left->data[left->n + 1 + i] = right->data[i];
left->child[left->n + 2 + i] = right->child[i + 1];
}
// 합치고 난 후 오른쪽 ptr 비우기
left->n = left->n + right->n + 1; // 개수 합쳐짐
free(right);
// array 값 재조정
for (i = pos + 1; i < n; i++)
{
key_arr[i - 1] = key_arr[i];
child[i] = child[i + 1];
}
// 개수 한개 줄이고 값 비교해서 root 값올릴지 비교
// ptr이 root 였다면 1과 개수 비교, ptr이 root가 아니라면 index 2 와 개수 비교
return --node->n >= (node == root ? 1 : min) ? Success : LessKeys;
}
출처
코드 - 자료구조 프로그래밍 Lab08) BTree (2-3 Tree) 만들기 - https://woongsin94.tistory.com/25
사진 - https://www.cs.usfca.edu/~galles/visualization/BTree.html
