Abstract
이미지의 diffusion 모델을 위해 트랜스포머 아키텍처를 활용하는 새로운g 클래스의 모델을 제안한다. 이 모델은 U-Net 대신에 트랜스포머를 사용하여 훈련되며, Gflops를 통해 측정되는 forward pass 복잡성의 관점에서 확장성을 분석한다.
Introduction
이 논문에서는 확산 모델에 대한 트랜스포머 기반의 새로운 클래스인 Diffusion Transformers (DiTs)를 제안한다. 이는 Vision Transformers (ViTs)의 모범 사례를 따르며 확산 모델의 효율적인 확장 가능성을 제시한다. DiTs는 네트워크 복잡성과 샘플 품질 사이의 스케일링 행동을 연구함으로써, 네트워크 복잡성(Gflops로 측정)과 샘플 품질(FID로 측정) 간의 상관 관계를 보여준다. DiTs를 확장하고 고용량 백본으로 학습함으로써, 고해상도 이미지 생성 작업에서 좋은 결과를 달성할 수 있다.
Related Work
Transformers
- 트랜스포머는 언어 영역뿐만 아니라, 비전에서도 픽셀을 자기회귀적으로 예측하고 이산 코드북에서 학습되어 확장 가능한 행동을 보여준다.
- 이 논문에서는 이미지 확산 모델의 백본으로 사용될 때 트랜스포머의 스케일링 특성을 연구한다.
Denoising diffusion probabilistic models (DDPMs)
- 최근 2년간의 DDPMs의 개선은 주로 개선된 샘플링 기술에 의해 이루어졌으며, 특히 분류기 없는 가이드, 픽셀 대신 노이즈를 예측하는 확산 모델 재정의, 저해상도 기본 확산 모델이 업샘플러와 병렬로 훈련되는 연속된 파이프라인 사용 등이 있다.
- 이전에 언급된 모든 확산 모델에 대해 컨볼루션 U-Net이 백본 아키텍처이다.
- 새로운 효율적인 아키텍처가 제안되었는데,이를 pure 트랜스포머로 탐색한다.
Architecture complexity
- 이미지 생성에서 아키텍처 복잡성을 평가할 때 매개변수 수를 사용하는 것이 일반적이다.
- 그러나 이미지 해상도와 같은 성능에 중요한 영향을 미치는 요소를 고려하지 않기 때문에, 매개변수 수는 이미지 모델의 복잡성을 제대로 반영하지 못한다.
- 대신에, 이 논문의 대부분 분석은 트랜스포머 클래스에 초점을 맞추어 계산량을 중심으로 이루어진다.
Diffusion Transformers
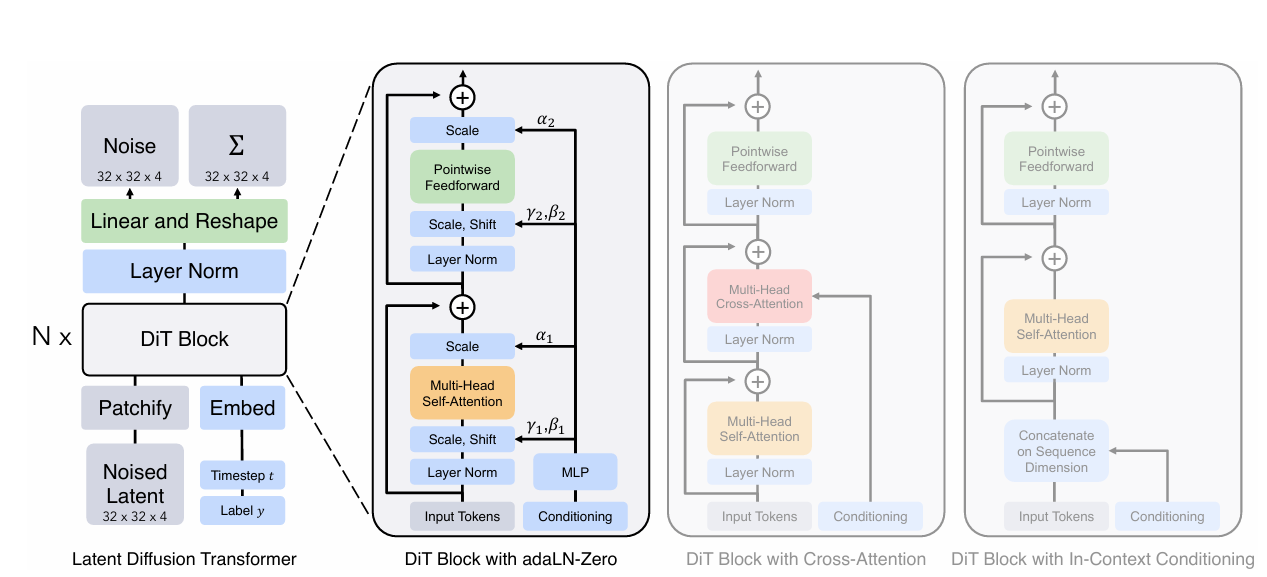
Diffusion Transformer 구조
Preliminaries
Diffusion formulation
확산 모델은 가우시안 확산 과정을 기반으로 하며 실제 데이터 x0에 점진적으로 노이즈를 적용한다. forward 과정에서 노이즈를 적용하여 xt를 생성하며, reverse 과정에서는 실제 데이터를 재구성한다. reverse 모델은 순방향 과정의 역과정을 학습하여, xt에서 xt-1의 통계를 예측한다.
모델은 주어진 데이터 x0에 대한 로그 우도의 변분 하한을 최적화하여 훈련되며, 재구성 노이즈를 예측하는 네트워크와 공분산 행렬을 예측하는 네트워크로 구성된다. 훈련된 역방향 모델을 사용하여 새로운 이미지를 샘플링할 수 있다.
Classifier-free guidance
조건부 확산 모델은 클래스 라벨 c와 같은 추가 정보를 입력으로 받으며, 이 경우 역과정은 pθ(xt-1|xt,c)가 된다. 이 설정에서, 분류기 없는 가이드는 샘플링 과정이 logp(c|x)가 높은 x를 찾도록 유도한다. 이러한 가이드는 샘플링 절차를 높은 p(x|c)를 갖는 x로 유도함으로써 개선된 샘플을 얻을 수 있다.분류기 없는 가이드는 일반적인 샘플링 기술보다 훨씬 개선된 샘플을 얻는 데 기여하며, 이러한 추세는 DiT 모델에서도 유지된다.
Latent diffusion models
LDMs은 고해상도 픽셀 공간에서 직접 확산 모델을 훈련하는 것이 계산상 불가능할 수 있기 때문에 두 단계 접근 방식을 사용한다.
(1) 학습된 인코더 E를 사용하여 이미지를 작은 공간 표현으로 압축하는 오토인코더를 학습한다.
(2) 이미지 x의 대신 표현 z = E(x)의 확산 모델을 훈련한다 (E는 고정된다).
새로운 이미지는 확산 모델에서 표현 z를 샘플링하고, 학습된 디코더를 사용하여 이미지 x로 디코딩함으로써 생성된다. LDMs는 ADM과 같은 픽셀 공간 확산 모델의 일부 Gflops만 사용하여 우수한 성능을 달성한다.
이 논문에서는 DiTs를 잠재 공간에 적용하지만, 수정 없이 픽셀 공간에도 적용할 수 있다. 이로써, 이미지 생성 파이프라인은 하이브리드 접근 방식이 되며, off-the-shelf 컨볼루션 VAE와 트랜스포머 기반의 DDPM을 사용한다.
Diffusion Transformer Design Space
Diffusion Transformers (DiTs)는 확산 모델을 위한 새로운 아키텍처로, 표준 트랜스포머 아키텍처의 스케일링 특성을 유지한다. 이미지의 공간적 표현을 위해 Vision Transformer (ViT) 아키텍처를 기반으로 하며, 다양한 디자인 요소를 포함하여 DiT의 forward pass 및 디자인 공간을 설명한다.
Patchify
DiT의 입력은 공간적 표현 z이며, 첫 번째 레이어는 patchify이다. patchify는 공간 입력을 선형적으로 임베딩하여 각 패치를 T개의 토큰 시퀀스로 변환한다. patchify이후에는 모든 입력 토큰에 대해 표준 ViT 주파수 기반 위치 임베딩을 적용한다.patchify에 의해 생성된 토큰의 수 T는 패치 크기 하이퍼파라미터 p에 의해 결정된다.
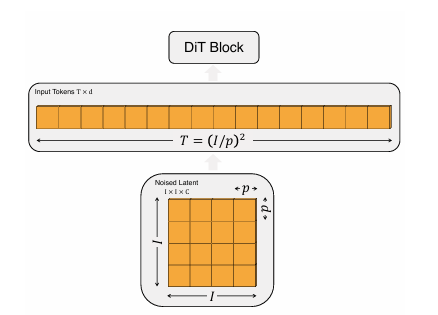
패치 크기 p가 작을수록 시퀀스 길이 증가하여 Gflops 수 증가
DiT block design
DiT의 입력 토큰은 patchify 후 transformer 블록에 의해 처리된다.
확산 모델은 노이즈 시간 단계 t, 클래스 레이블 c, 자연어 등과 같은 추가 조건부 정보를 처리하기 위해 transformer 블록의 네 가지 변형을 사용한다.
- In-context conditioning: 추가 조건부 정보인 t와 c의 벡터 임베딩을 입력 시퀀스에 두 개의 추가 토큰으로 추가하며, 최종 블록 이후에는 조건부 토큰을 시퀀스에서 제거한다.
- Cross-attention block: t와 c의 임베딩을 이미지 토큰 시퀀스와 별도의 길이 두의 시퀀스로 결합한다.트랜스포머 블록은 다중 헤드 self-attention 블록 다음에 추가적인 다중 헤드 cross-attention 레이어를 포함하도록 수정된다.
- Adaptive layer norm (adaLN) block: 이는 직접적으로 차원별 스케일 및 시프트 매개변수를 학습하는 대신, t와 c의 임베딩 벡터의 합에서 이들을 회귀한다. 세 가지 블록 디자인 중 adaLN은 가장 적은 Gflops를 추가하며, 따라서 가장 계산 효율적이다.
- adaLN-Zero block: 초기화 전략은 각 블록에서 잔여 연결 이전에 최종 합성곱 층을 0으로 초기화한다. adaLN DiT 블록의 수정을 탐구하는데, 이는 마찬가지로 이 초기화 전략을 따른다. 회귀하는 동안 뿐만 아니라 잔여 연결 이전에 DiT 블록 내에서 즉시 적용되는 차원별 스케일링 매개변수 α도 회귀한다.
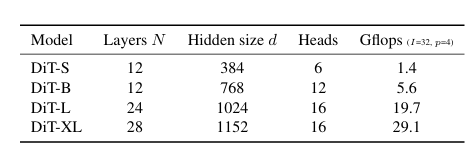
Model size
N개의 DiT 블록을 사용하며, 각 블록은 hidden dimension 크기 d에서 작동한다.ViT를 따라, N, d 및 attention heads를 함께 조절하는 표준 transformer 설정을 사용한다. DiT-S, DiT-B, DiT-L 및 DiT-XL과 같이 네 가지 구성을 사용하며 이를 통해 성능 평가를 할 수 있다.
Transformer decoder
마지막 DiT 블록 이후에는 이미지 토큰 시퀀스를 출력 잡음 예측과 출력 대각 공분산 예측으로 디코딩해야 한다. 이를 위해 표준 선형 디코더를 사용하고, 각 토큰을 p x p x 2C 텐서로 선형적으로 디코딩한다. 마지막으로, 디코딩된 토큰을 원래의 공간 배치로 재배열하여 예측된 잡음과 공분산을 얻는다.
Experimental Setup
Training
ImageNet 데이터셋을 사용하여 256x256 및 512x512 이미지 해상도에 대한 클래스 조건부 잠재 DiT 모델을 훈련하며, 초기화는 표준 가중치 초기화를 사용하고, AdamW를 이용하여 모델을 훈련한다. data augmentation은 horizontal flips만 사용하며 EMA를 사용하여 DiT 가중치의 지수 이동 평균을 유지한한다.
Diffusion
Stable Diffusion의 사전 훈련된 Variational Autoencoder (VAE) 모델을 사용하며 VAE 인코더는 RGB 이미지 x를 32x32x4의 공간 표현인 z로 다운샘플링한다. 새로운 잠재 변수를 확산 모델에서 샘플링한 후, VAE 디코더를 사용하여 픽셀로 디코딩한다.
Evaluation metrics
이미지 생성 모델의 성능을 측정하기 위해 FID를 사용하며 이전 연구와의 비교를 위해 FID-50K 및 250개의 DDPM 샘플링 단계를 사용한다.
FID는 작은 구현 세부 사항에 민감하여 정확한 비교를 위해 ADM의 TensorFlow 평가 도구를 사용하여 측정되고, Classifier-free guidance를 사용하지 않은 경우를 제외하고 보고된 FID 숫자를 사용함.
Compute
모든 모델을 JAX로 구현하고 TPU-v3 팟을 사용하여 훈련하고, DiT-XL/2은 전역 배치 크기가 256인 TPUv3-256 팟에서 약 5.7 iterations/second로 훈련된다.
Experiments
DiT block design
DiT-XL/2 모델을 기반으로 네 가지 다른 블록 디자인을 사용하여 네 개의 모델을 훈련한다. 훈련 중 FID를 측정한다.
adaLN-Zero 블록은 가장 낮은 FID를 제공하면서도 가장 계산 효율적이다. 모든 모델에서는 이후 adaLN-Zero DiT 블록을 사용함.
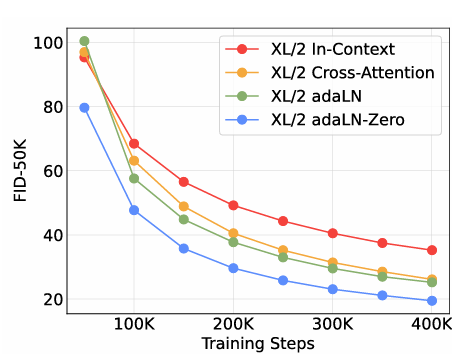
Scaling model size and patch size
DiT-L 및 DiT-XL은 상대적 Gflops 측면에서 다른 구성과 비슷. 모델 크기를 증가시키고 패치 크기를 줄이면 확산 모델의 성능이 향상된다. 트랜스포머를 더 깊고 넓게 만들면 훈련의 모든 단계에서 상당한 FID 개선이 이루어지고 패치 크기를 줄이면서 모델 크기를 일정하게 유지하면 훈련 중 FID 성능 개선된다.
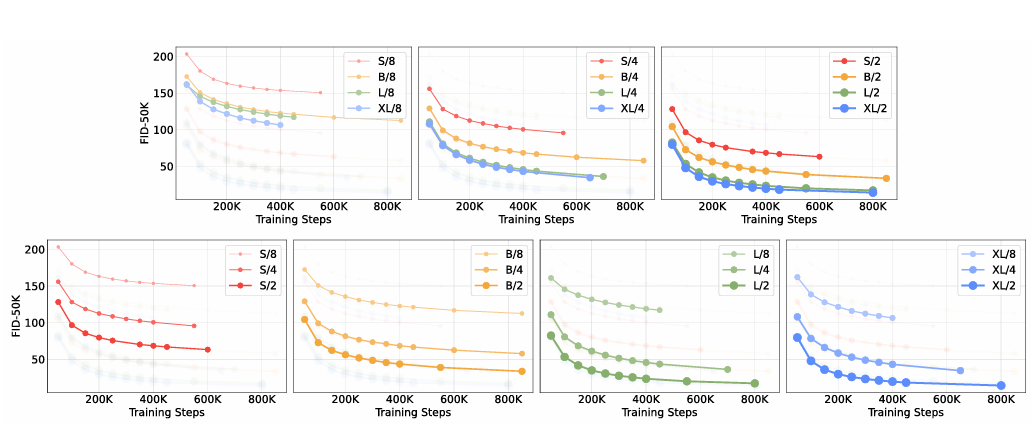
DiT Gflops are critical to improving performance
매개변수 수가 DiT 모델의 품질을 결정하는 데에 독점적이지 않음을 보여준다.
모델 크기를 유지하고 패치 크기를 줄이면 트랜스포머의 총 매개변수가 변경되지 않고 Gflops만 증가한다. 모델의 Gflops를 증가시키는 것이 성능 향상에 중요한 요소이다.
모델 구성이 유사한 경우에는 유사한 FID 값을 얻는 경향. 모델의 Gflops와 FID-50K 사이에 강력한 음의 상관 관계가 있으며, 추가적인 모델 계산이 향상된 DiT 모델의 핵심 요소이다.
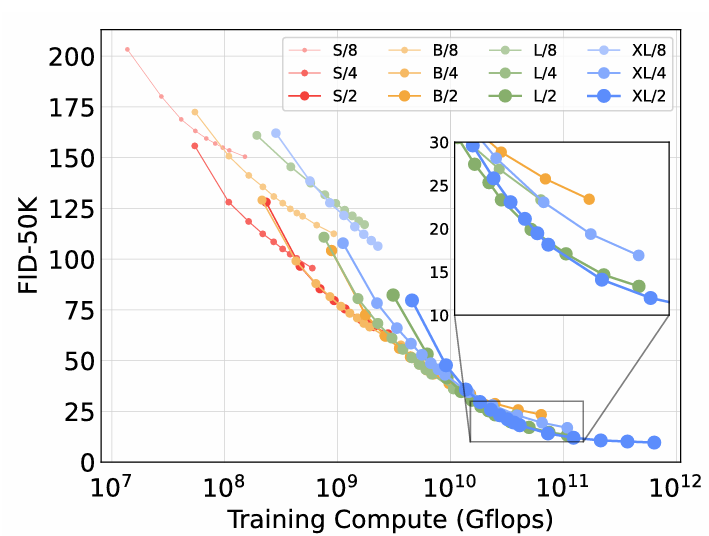
Larger DiT models are more compute-efficient
작은 DiT 모델은 더 큰 모델보다 훈련 시간이 길어져도 계산 효율이 낮아지는 경향을 보인다. 또한, 동일한 설정의 모델 중 패치 크기를 제외한 다른 모델은 훈련 Gflops를 제어해도 성능이 달라지는 것으로 나타났. 예를 들어, XL/4 모델은 XL/2 모델보다 1010 Gflops 후에 더 좋은 성능을 보인다.
Visualizing scaling
DiT 모델에서 이미지를 샘플링하여 시각적으로 스케일링이 DiT 샘플 품질에 미치는 영향을 분석한다. 모델 크기와 토큰 수를 함께 스케일링하면 시각적 품질이 현저하게 향상된다.

State-of-the-Art Diffusion Models
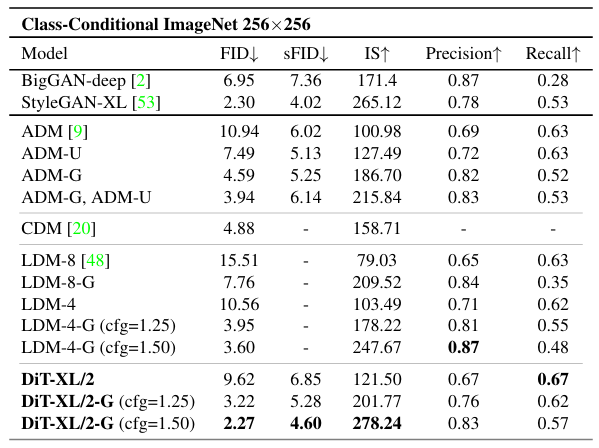
256 x 256 ImageNet
DiT-XL/2 모델을 추가 훈련하여 샘플을 확인하고 최신 클래스 조건부 생성 모델과 비교한다. classifier-free guidance를 사용하면, DiT-XL/2는 FID-50K가 3.60에서 2.27로 감소한다. DiT-XL/2는 잠재 공간 U-Net 모델보다 계산 효율적이며, 픽셀 공간 U-Net 모델보다 훨씬 더 효율적이다.
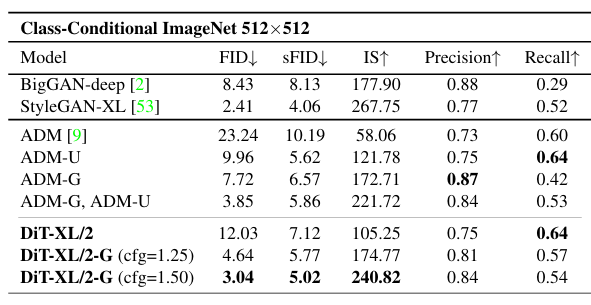
512 x 512 ImageNet
새로운 DiT-XL/2 모델을 ImageNet 데이터셋에서 512x512 해상도로 3백만 번의 반복을 통해 훈련했다. 모델은 이전의 FID를 개선하여 3.85에서 3.04로 낮추었다. 토큰 수가 증가하더라도 모델은 계산 효율적이며, 고해상도 샘플을 시각화했다.
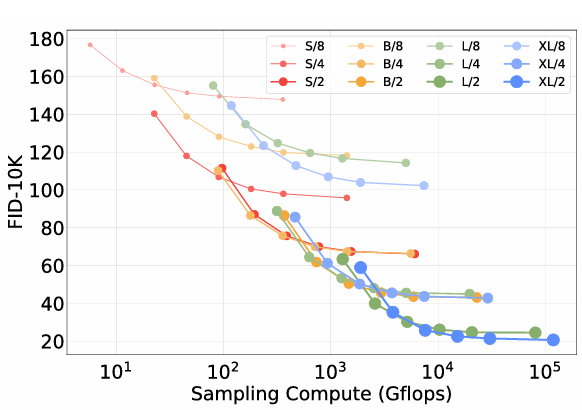
Scaling Model vs. Sampling Compute
DiT 모델은 이미지 생성 시 추가적인 샘플링 계산을 통해 더 많은 컴퓨팅을 사용할 수 있습니다. 작은 DiT 모델이 더 많은 샘플링 계산을 사용하여 더 큰 모델보다 우수한 성능을 낼 수 있는지 연구합니다. 12개의 DiT 모델을 모두 400K 훈련 반복에서 다양한 샘플링 단계를 사용하여 FID를 계산했다. 샘플링 계산을 확장해도 모델 계산 부족을 보상할 수 없다.
Conclusions
DiT는 확산 모델을 위한 간단한 트랜스포머 기반의 백본이다. DiT의 확장성 결과를 확인하고, 향후 더 큰 모델과 토큰 수로의 확장의 필요성과 DiT를 텍스트에서 이미지로의 모델에 대한 백본으로 활용할 수 있는 가능성을 제시한다.
