AI 논문리뷰
1.[논문 리뷰] Sora: 영상 제작 AI 모델
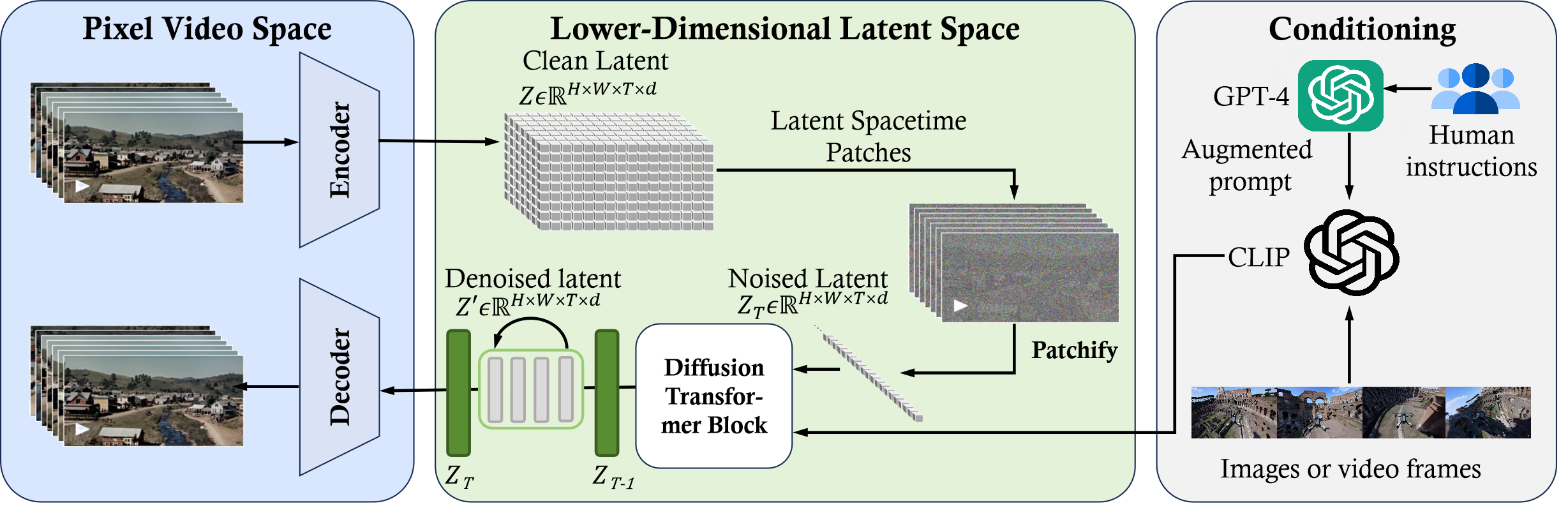
Reverse Engineering 1) Time-Space compressor: 원본 비디오를 잠재 공간에 매핑2) ViT: 토큰화된 잠재 표현 처리 및 출력3) CLIP: 확산 모델이 비디오 생성하도록 안내 4) Decoder: 픽셀 공간에 노이즈가 제거된 비디오를
2.[논문 리뷰] DNN Youtube recommendation
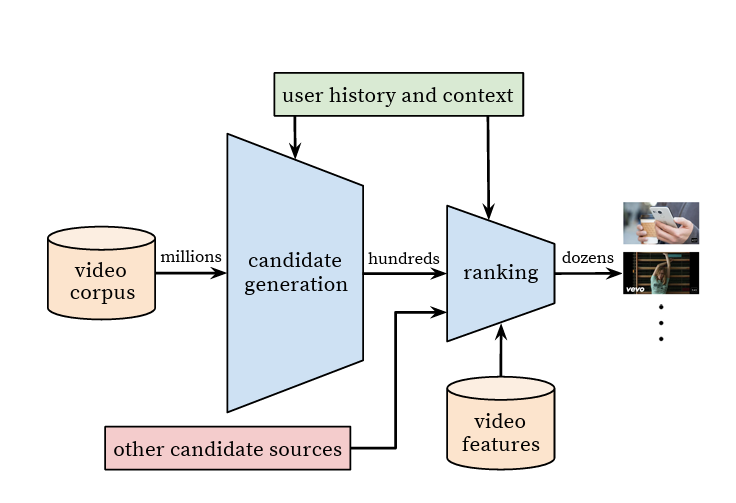
https://research.google/pubs/deep-neural-networks-for-youtube-recommendations/딥러닝을 통해 서비스의 성능을 개선Scale: 높은 scale과 latency를 고려한 추천 알고리즘 적용Freshnes
3.[논문 리뷰] HAiVA: Hybrid AI-assisted Visual Analysis Framework to Study the Effects of Cloud Properties on Climate Patterns
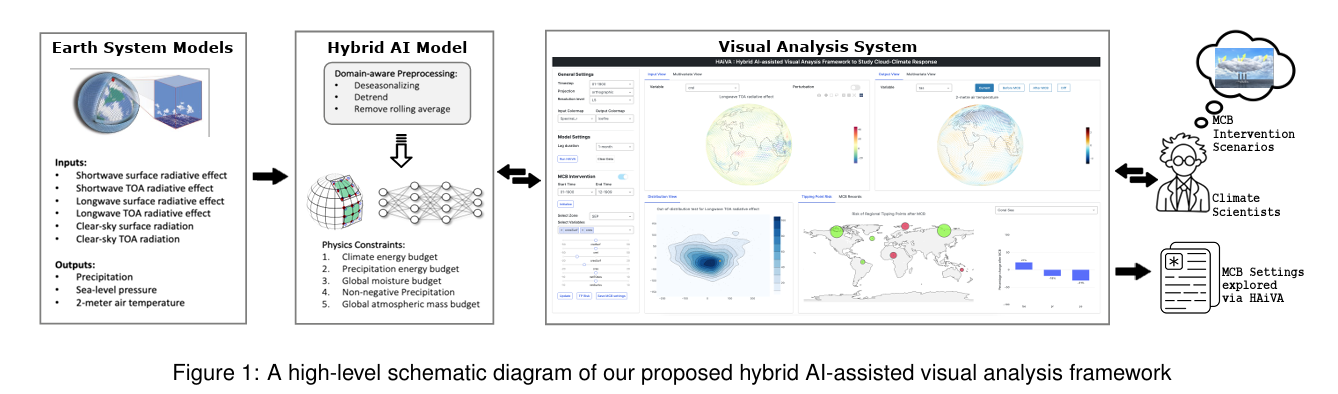
https://scholar.google.com/citations?view_op=view_citation&hl=en&user=ftHUysoAAAAJ&cstart=20&pagesize=80&citation_for_view=ftHUysoAAAAJ:e5wmG9Sq2
4.[논문 리뷰] Learning a Sparse Transformer Network for Effective Image Deraining
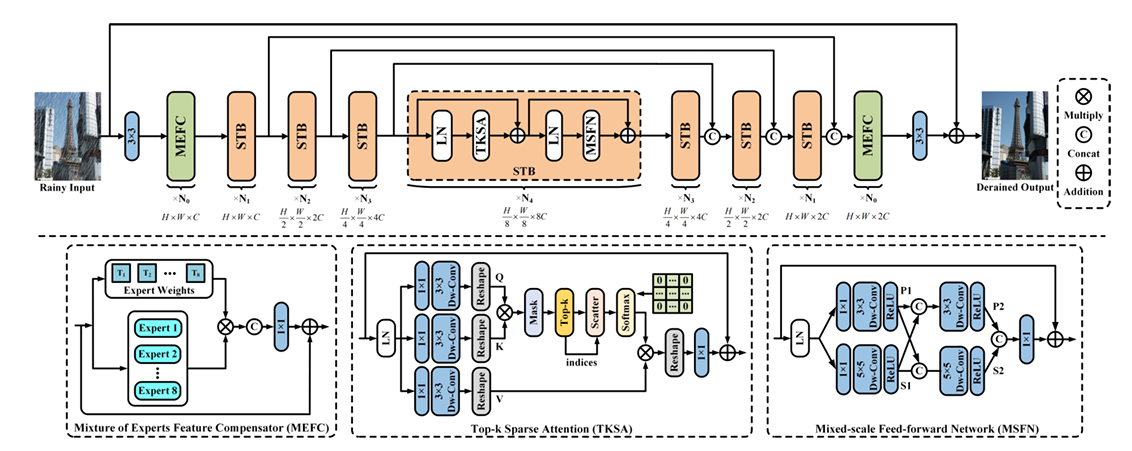
https://openaccess.thecvf.com/content/CVPR2023/html/Chen_Learning_a_Sparse_Transformer_Network_for_Effective_Image_Deraining_CVPR_2023_paper.html
5.[논문 리뷰] A Unified Approach to Interpreting Model Predictions

https://arxiv.org/abs/1705.07874사용자가 복잡한 모델들의 예측을 해석하는 것을 돕기 위해 통합 프레임워크인 SHAP(SHapley Additive exPlanations)를 제시한다. SHAP는 각 기능에 특정 예측에 대한 중요도 값을
6.[논문리뷰] FaceNet: A Unified Embedding for Face Recognition and Clustering
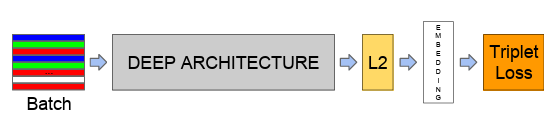
https://arxiv.org/abs/1503.03832얼굴 이미지에서 거리가 얼굴 유사성 측정에 직접 해당하는 콤팩트한 유클리드 공간으로의 매핑을 직접 학습하는 FaceNet을 제시한다. \*\*\*\*이 공간에서는 FaceNet 임베딩을 기능 벡터로 사용
7.[논문 리뷰] DialogueRNN: An Attentive RNN for Emotion Detection in Conversations
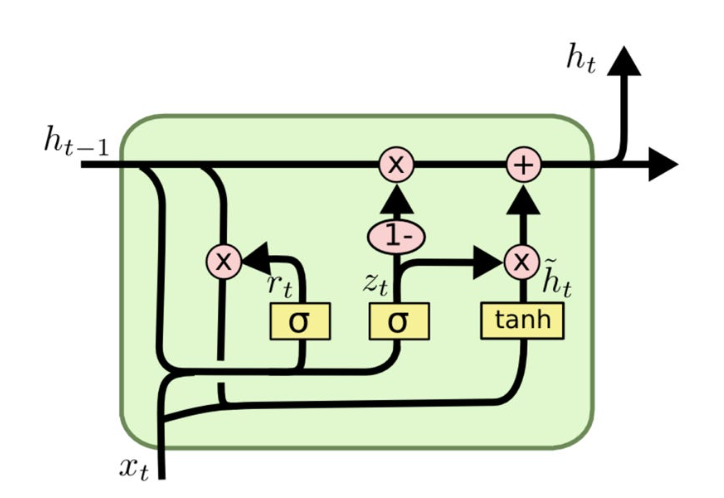
https://arxiv.org/abs/1811.00405opinion mining (Sentiment analysis): 텍스트 본문 뒤에 숨은 감정적 어조를 식별하는 방법argumentation mining: 자연어 텍스트에 논증 구조를 자동으로 추출하고
8.[논문 리뷰] Scalable Diffusion Models with Transformers
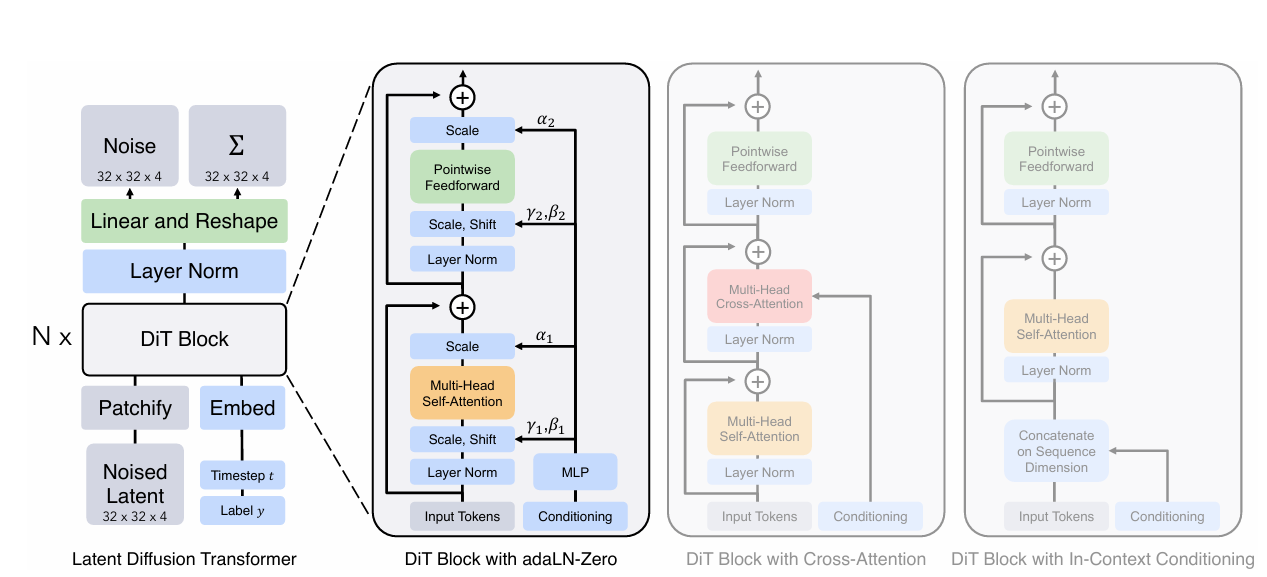
https://openaccess.thecvf.com/content/ICCV2023/papers/Peebles_Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.pdf이미지의 diffusion 모델을 위
9.[논문 리뷰] Relevance-CAM: Your Model Already Knows Where to Look
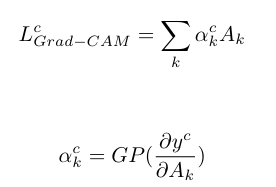
https://openaccess.thecvf.com/content/CVPR2021/papers/Lee_Relevance-CAM_Your_Model_Already_Knows_Where_To_Look_CVPR_2021_paper.pdf이 논문에서 제안된 Rele
10.[논문 리뷰] AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
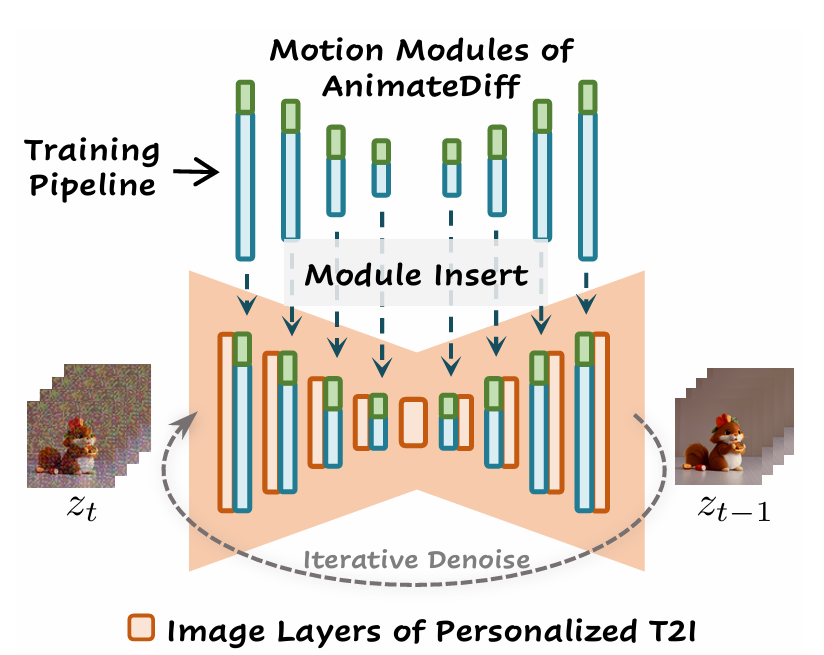
arxiv.org/pdf/2307.04725AnimateDiff라는 프레임워크와 MotionLoRA라는 기법에 관한 논문이다. AnimateDiff는 개인화된 텍스트-이미지 모델에 동적인 움직임을 추가하는 새로운 방법이다. 한 번 훈련된 후 다양한 개인화된 텍스트-이
11.[논문 리뷰] Imagic: Text-Based Real Image Editing with Diffusion Models

https://openaccess.thecvf.com/content/CVPR2023/papers/Kawar_Imagic_Text-Based_Real_Image_Editing_With_Diffusion_Models_CVPR_2023_paper.pdf텍스트를 입력
12.[논문 리뷰] Post-training Quantization on Diffusion Models
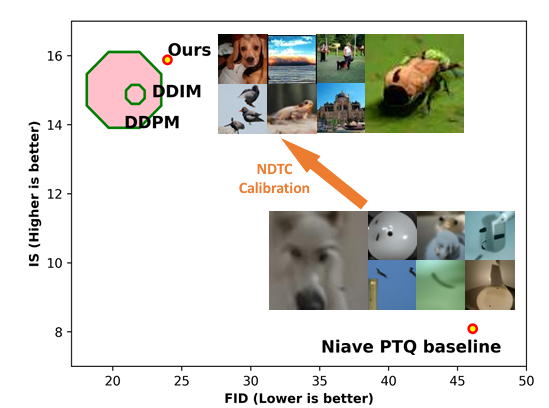
https://arxiv.org/pdf/2211.15736이 논문에서는 전통적인 노이즈 감소 시뮬레이션 모델의 느린 생성 과정을 가속화하는 새로운 접근 방식을 제안한다. 현재 모델들은 매 반복마다 무거운 네트워크를 이용해 노이즈를 추정하며, 이 과정이 시간이
13.[논문 리뷰] CatBoost: unbiased boosting with categorical features
https://arxiv.org/pdf/1706.09516새로운 그래디언트 부스팅 툴킷인 CatBoost의 핵심 알고리즘 기술을 소개한다. CatBoost는 1) 'ordered boosting'이라는 순열 기반 부스팅 방식과 2) 범주형 특성 처리를 위한 혁
14.[논문 리뷰] Structural Vibration Signal Denoising Using Stacking Ensemble of Hybrid CNN-RNN
https://arxiv.org/pdf/2303.11413최근 몇 년간 진동 신호는 다양한 공학 분야에서 발걸음으로 인한 활동 유발 구조 진동과 같은 구조 건강 모니터링, 고장 진단 및 손상 감지를 포함한 분석 및 모니터링 목적으로 많이 활용되고 있다. 그러나
15.[논문 리뷰] Attention Is All You Need
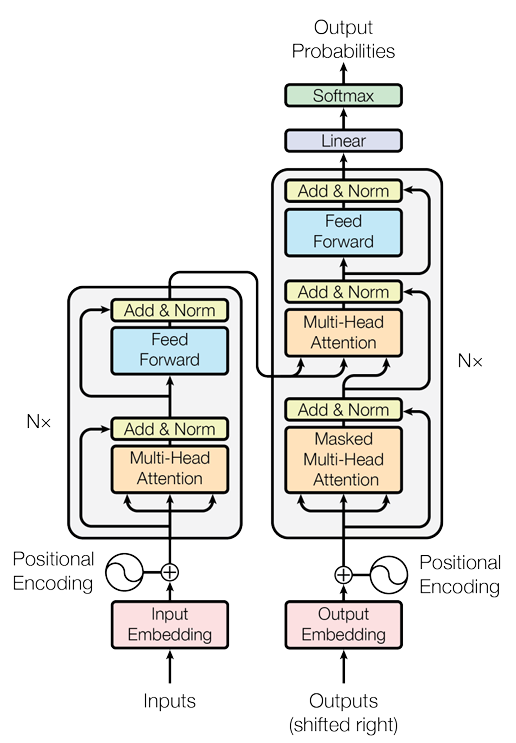
https://arxiv.org/pdf/1706.03762단순한 새로운 네트워크 구조, Transformer를 제안한다. 이는 순환 및 합성곱을 완전히 배제하고 attention 메커니즘만을 기반으로 한다. 실험 결과, 이 모델은 기존의 모델보다 우수한 품질을
16.[논문 리뷰] Continual Learning with Deep Generative Replay
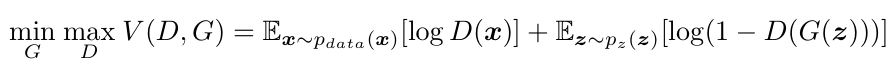
arxiv.org인공지능 훈련 시 '파괴적 망각 (catastrophic forgetting)' 문제를 해결하기 위해 딥 생성 재생(Deep Generative Replay)이라는 새로운 프레임워크가 제안되었다. 이는 생성 모델 (generator)과 과제 해결 모델
17.[논문 리뷰] Playing Atari with Deep Reinforcement Learning
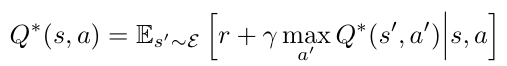
arxiv.org고차원 감각 입력으로부터 직접 제어 정책을 학습할 수 있는 첫 번째 딥러닝 모델을 소개한다. 이 모델은 Q-러닝 변형으로 훈련된 컨볼루션 신경망으로, 입력은 원시 픽셀이고 출력은 미래 보상을 추정하는 가치 함수이다. 이를 아키텍처나 학습 알고리즘의 조정
18.[논문리뷰] Few-Shot Adversarial Learning of Realistic Neural Talking Head Models

https://arxiv.org/abs/1905.08233이 논문은 타겟의 이미지에서 face landmark를 따와 소스의 이미지에 입히는 talking head model을 만드는 과정 (face reenactment)에 대해 설명하고 있다. 최근 많은 연
19.[논문리뷰] Tabular Data: Deep Learning is Not All You Need
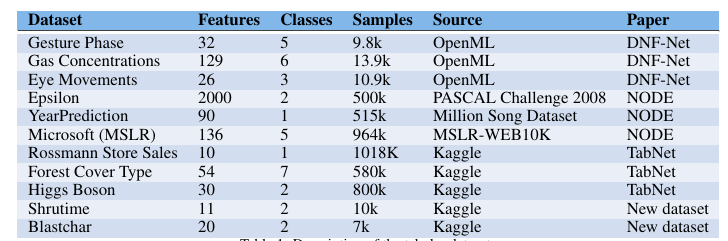
arxiv.org이 논문은 XGBoost와 새로운 딥 러닝 모델들을 다양한 데이터셋에서 비교하여, 어떤 모델이 tabular data에 더 적합한지 탐구한다. XGBoost가 딥 러닝 모델들보다 대부분의 데이터셋에서 더 뛰어난 성능을 보임.특히, 딥 러닝 모델들을 제안
20.[논문리뷰] AutoDroid: LLM-powered Task Automation in Android
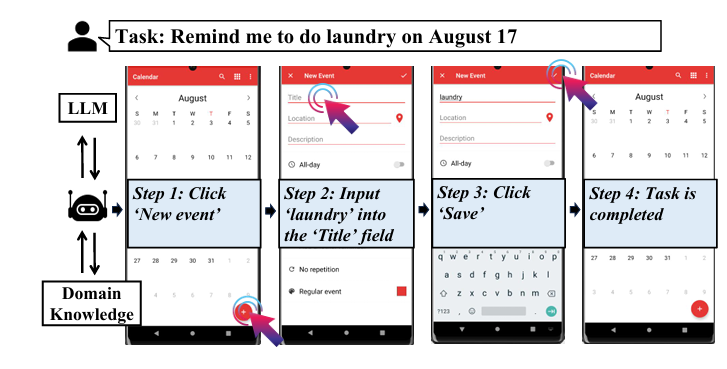
arxiv.org이 논문에서는 스마트폰에서 음성 기반의 핸즈프리 사용자 인터랙션을 가능하게 하는 모바일 작업 자동화 기술을 제안한다.LLM을 활용하여, 작업 준비, 이해, 실행을 통합된 언어 모델이 처리 → 이를 위해 LLM의 상식 지식과 앱의 도메인 지식을 결합합니
21.[논문리뷰] Zero-Shot Text-to-Image Generation
논문 링크별도의 추가 학습이나 파인튜닝 없이 모델이 새로운 데이터나 작업에서 적절히 작동할 수 있는 방법학습 데이터에 포함되지 않은 개념이나 작업에서도 모델이 일반화함→ 예: DALL-E가 "크리스마스 스웨터를 입은 고슴도치"를 텍스트로 입력받고 이미지 생성하는 능력
22.[논문 리뷰] Deep Residual Learning for Image Recognition
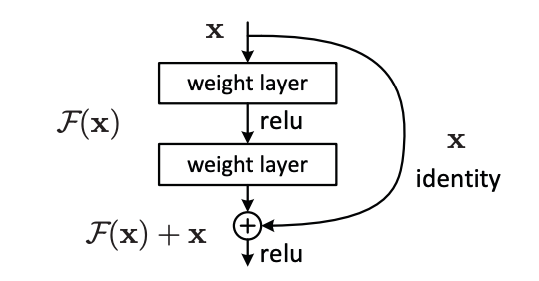
Skip Connection(Shortcut)을 통해 층이 깊어져도 학습이 가능하게 만들었고, Bottleneck 구조를 통해 연산 효율성을 챙겨서 훨씬 더 깊은 층(Layer)을 쌓을 수 있게 함층이 깊어져도 훈련을 쉽게 하기 위해서 “residual learning
23.[Abstract 요약] Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)

Artificial Hivemind: LLM 모델들이 “open-ended 질문들”(답이 정해져 있지 않은 질문)에 대해 겉보기에 다양해보이지만 의미적으로는 유사한 답변을 내놓는 현상 → 집단 지성처럼 작동논문에서는 이런 현상이 일어나는 원인에 대해서 원래 사용하던 벤
24.[Abstract 요약] Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Fre
Attention sink: softmax 기반 어텐션 매커니즘은 출력 합이 1이 되어야 해서 입력 토큰과 관련 없는 토큰 (보통 문장의 첫번째 토큰 CLS)에 가중치를 부여하는 문제논문에서는 이 문제를 해결하기 위해 SDPA (Scaled Dot-Product Att