개요
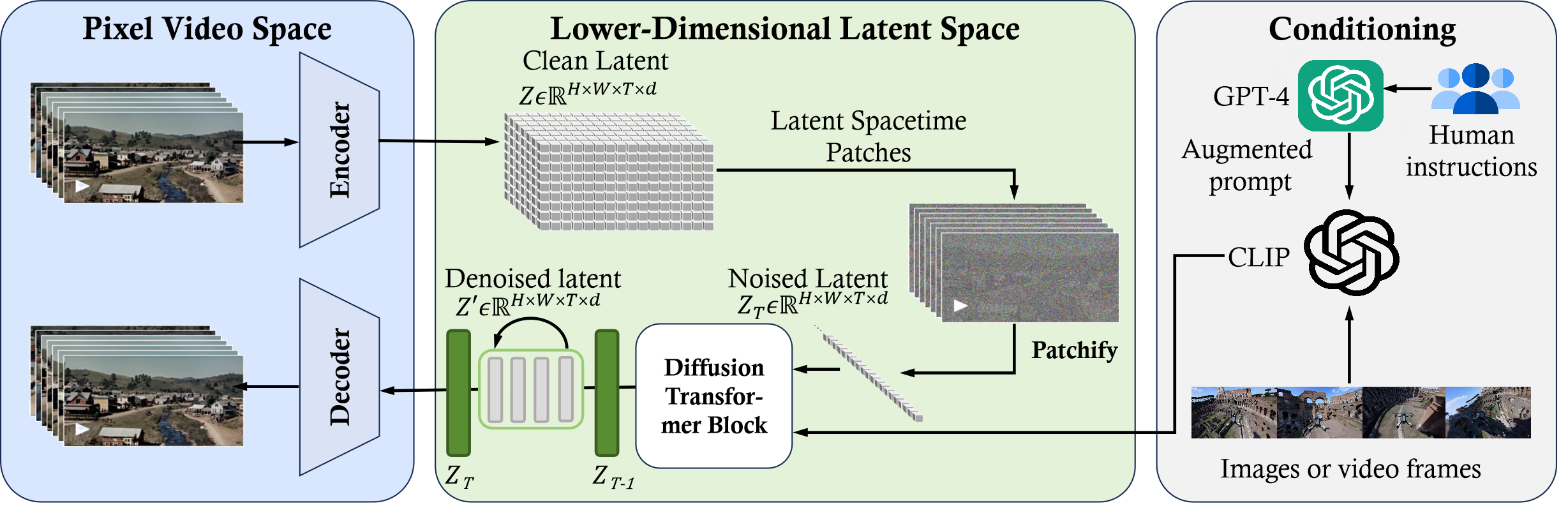
Reverse Engineering
1) Time-Space compressor: 원본 비디오를 잠재 공간에 매핑
2) ViT: 토큰화된 잠재 표현 처리 및 출력
3) CLIP: 확산 모델이 비디오 생성하도록 안내
4) Decoder: 픽셀 공간에 노이즈가 제거된 비디오를 매핑
기술
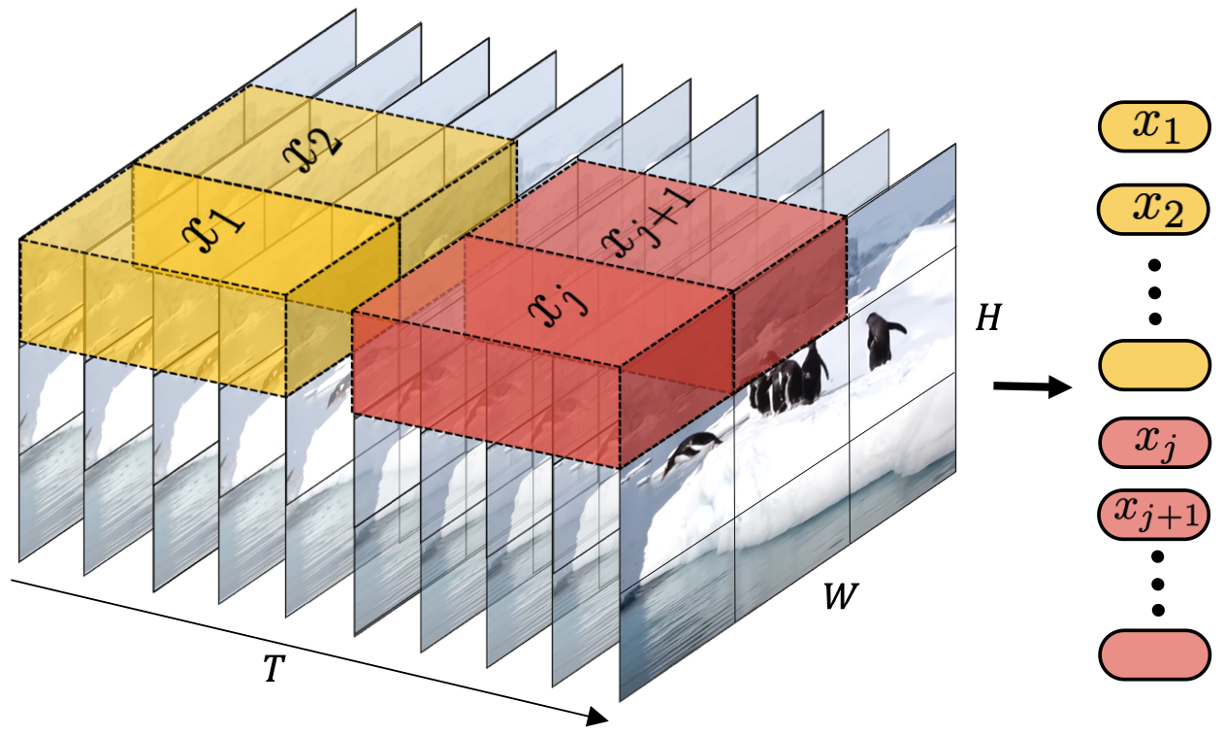
Turning visual data into Spacetime latent patches
동영상을 저차원 잠재 공간으로 압축한 후 시공간 패치로 분해하여 동영상을 패치로 변환

압축된 입력 비디오를 통해 시공간 패치 시퀀스를 추출
이미지나 비디오를 작은 부분으로 나누어 각 부분을 따로 처리
⇒ 작은 부분을 순차적으로 처리 후 조합하여 전체 데이터 처리
Video Compression Network
동영상의 차원을 줄이고 시공간적으로 압축된 잠재 패치 출력
VAE, VQ-VAE(Vector Quantiised-VAE)를 기반으로 구축
→ 크기 조정을 하지 않는 경우 고정된 크기의 잠재 공간에 매핑이 어려움
- 공간 패치 압축: 비디오 프레임을 고정 크기 패치로 변환
- 공간-시간-패치 압축: 공간적 차원과 시간적 차원을 모두 캡슐화 → 프레임 간의 움직임과 변화를 고려하여 동적인 측면 포착
⇒ 두 가지 패치 수준의 압축 접근 방식을 통해 reverse engineering 진행
Diffusion Transformer (확산 트랜스포머)
텍스트 프롬프트와 같은 컨디셔닝 정보가 주어지면 원래의 “깨끗한” 패치를 예측하도록 훈련

→훈련 연산이 증가함에 따라 샘플 품질이 현저하게 향상됨
결론
- Sora는 텍스트-조건부 확산 모델을 활용하여 대규모 영상 데이터를 훈련
- 시공간 패치(spacetime patches)를 사용하여 길이, 해상도, 종횡비가 다양한 비디오를 동시에 훈련
- 텍스트 입력에 기반하여 이미지나 비디오를 생성 후, 점진적으로 세밀하게 개선하기 위해 확산 과정을 통해 완성함
