
Graph (그래프)
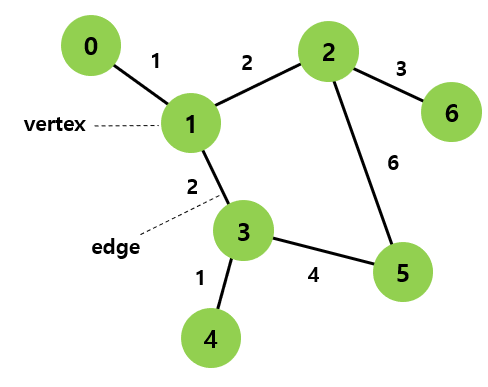
그래프란 vertex(정점, =node)과 edge(간선)으로 이루어진 자료구조를 뜻한다. 트리 또한 그래프에 속한다.
용어
- 정점(vertex): 위치 개념. node라고도 불림
- 간선(edge): 정점들을 연결하는 선. 정점과의 관계. 분기(branch)라고도 불림
- 인접 정점(adjacent vertex): 어떠한 정점에서 1개의 간선으로 직접 연결된 정점
- 정점의 차수(degree): 무방향 그래프에서 하나의 정점에 인접한 정점의 수.
- 무방향 그래프에서 존재하는 정점의 모든 차수의 합 == 무방향 그래프의 간선 수의 2배
- 진입 차수(in-degree): 방향 그래프에서 외부에서 들어오는 간선의 수. 내차수
- 진출 차수(out-degree): 방향 그래프에서 외부로 나가는 간선의 수. 외차수
- 방향 그래프에 있는 정점의 진입차수와 진출차수의 합 == 방향 그래프의 간선 수
- 경로 길이(path length): 경로를 구성하는 데 사용된 간선의 수
- 단순 경로(simple path): 경로 중에서 반복되는 정점이 없는 경우
- 사이클(cycle): 단순 경로의 시작 정점과 종료 정점이 동일한 경우
특징
- 그래프는 네트워크 모델이다
- 2개 이상의 경로가 가능하다.
즉, 노드들 사이에 무방향/방향에서 양방향 경로를 가질 수 있다. - self-loop 뿐만 아니라 loop/circuit 모두 가능하다.
- 부모-자식 관계 개념이 없다.
- 간선의 유무는 그래프에 따라 다르다.
종류
그래프는 가지고 있는 성질에 따라 여러가지로 분류할 수 있다.
Directed Graph vs Undirected Graph
방향성에 따라 그래프는 Undirected Graph (무방향 그래프)와 Directed Graph (방향 그래프)로 나뉜다.
방향성이란 정점에서 정점으로 이동할 수 있는 방향을 뜻한다.
Directed Graph (방향 그래프)
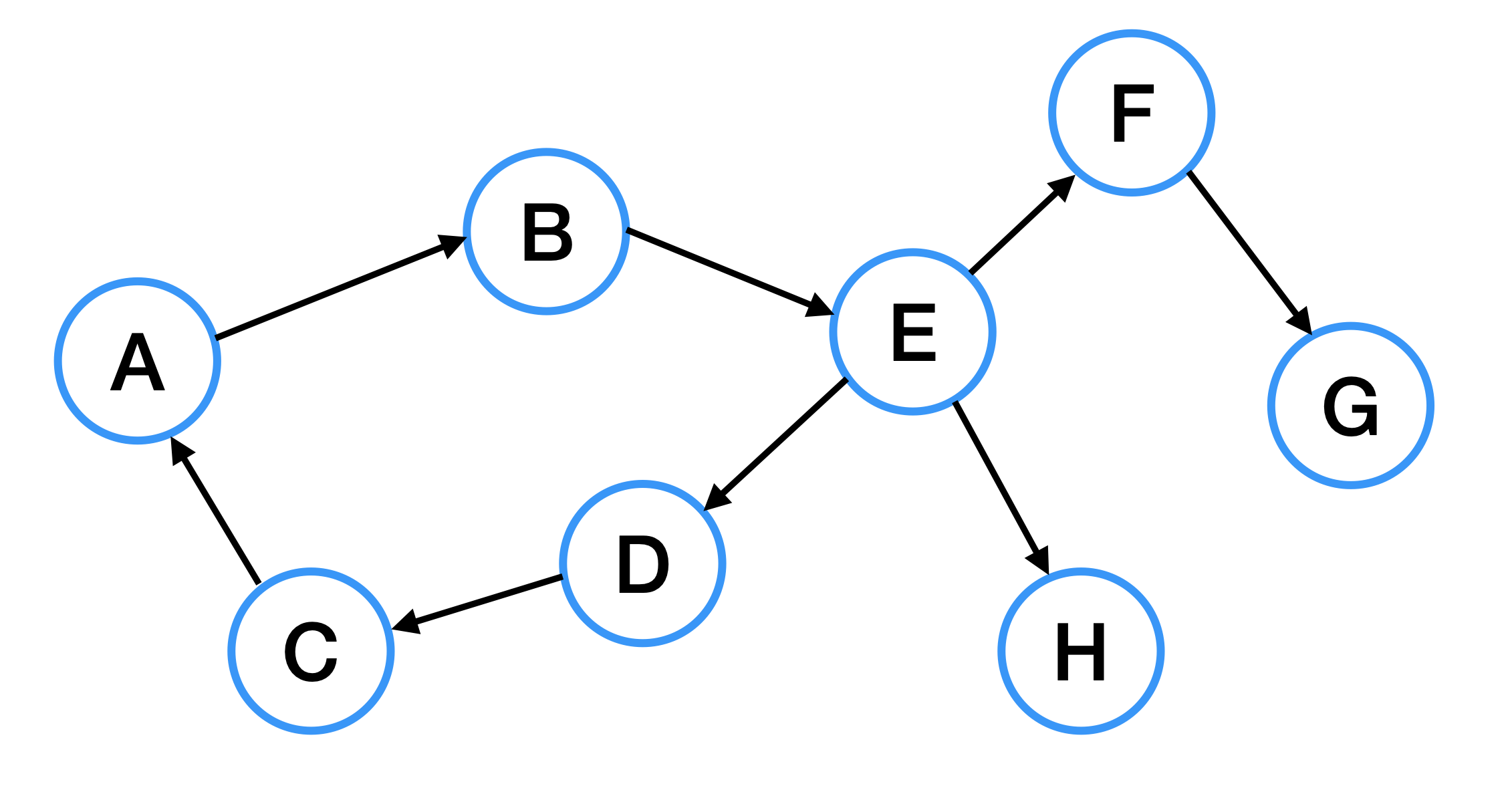
위 그림은 방향 그래프이다. 위 그래프처럼 간선에 화살표가 있다면 방향그래프이고, 화살표의 방향대로만 이동이 가능하다.
위의 그래프에서 정점 A에서 정점 E로 이동하고 싶다면, 화살표의 방향대로 A -> B -> E로 이동할 수 있다.
그리고 화살표가 반대로 되어있는 A -> C -> D -> E 로는 이동할 수 없다.
하지만 반대로 정점 E에서 정점 A로 이동하고 싶다면 E- -> D -> C -> A 이렇게 이동할 수 있다.
Undirected Graph (무방향 그래프)
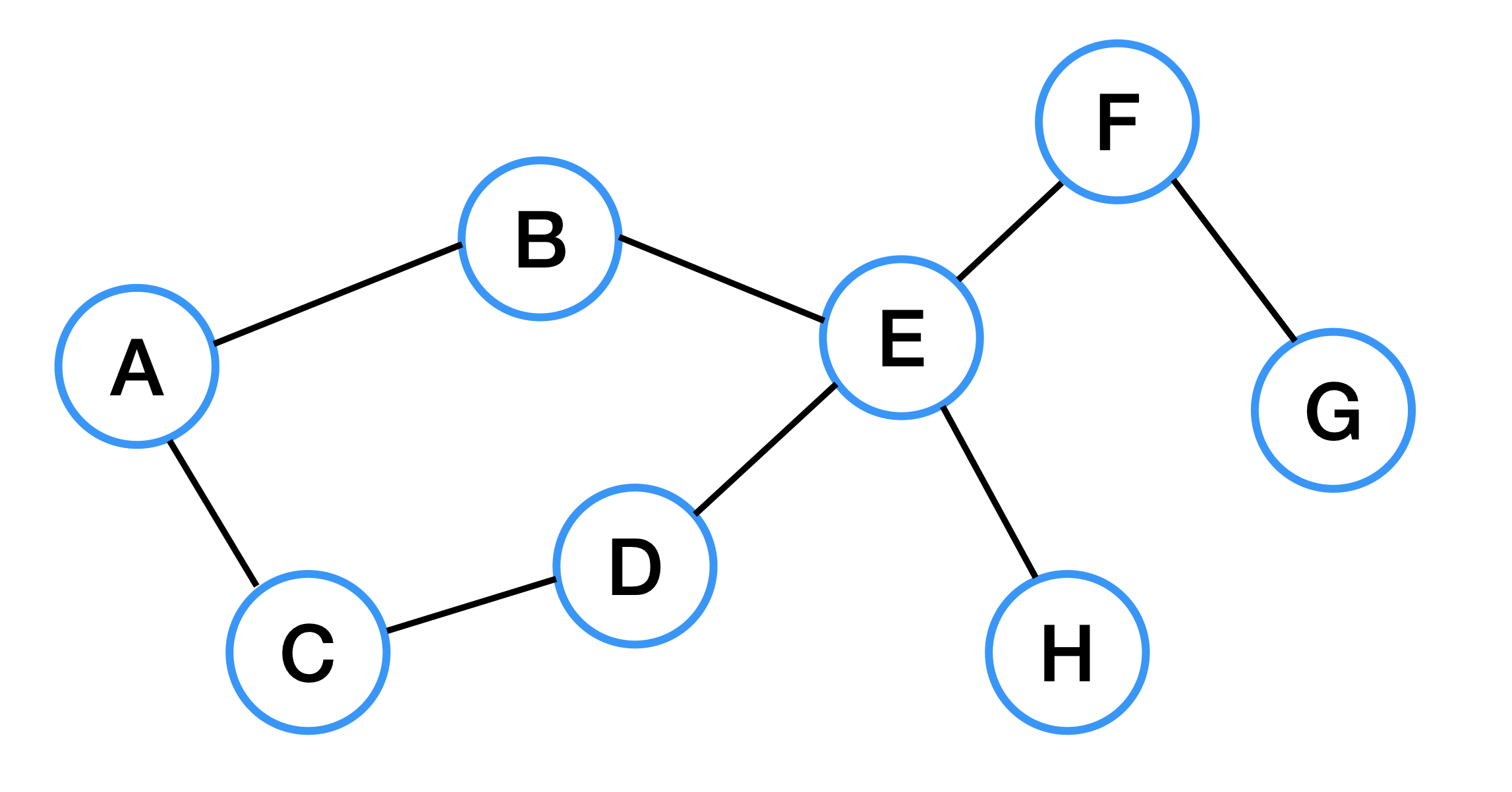
위 그림은 무방향 그래프이다. 위 그림과 같이 간선에 화살표가 없는 그래프를 무방향 그래프라고 한다. 무방향 그래프는 방향 그래프와 다르게 양방향 이동이 가능하다.
방향 그래프에서 불가능하던 A -> C -> D -> E 도 가능하다.
Connected Graph vs Disconnected Graph
Connected Graph (연결 그래프)

연결 그래프는 모든 정점에 대해 항상 경로를 가지는 그래프를 말한다. 위 그래프와 같이 간선의 개수와 상관없이 모든 정점으로 이동할 수 있다.
트리도 연결그래프에 속한다.
Disconnected Graph (비연결 그래프)
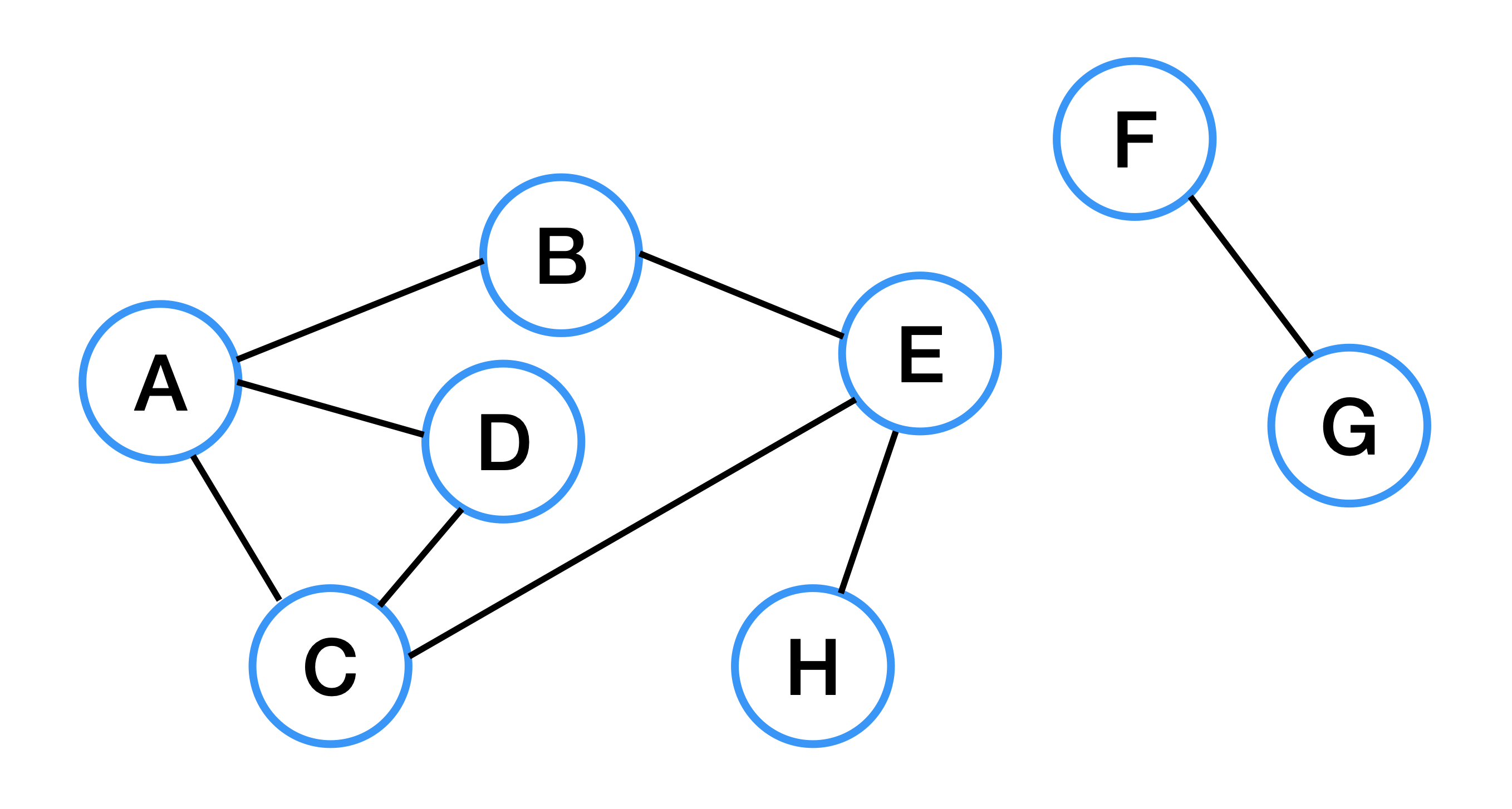
비연결 그래프는 정점들 사이에 간선이 존재하지 않아 경로가 없는 경우가 존재하는 그래프를 말한다. 위 그래프에서 보면 {E, G}가 따로 떨어져 있어, 나머지 그래프에서 E나 G로 이동할 수 없다. 이러한 그래프를 비연결 그래프라고 한다.
Cycle vs Acycle Graph
Cycle (사이클, 순환)
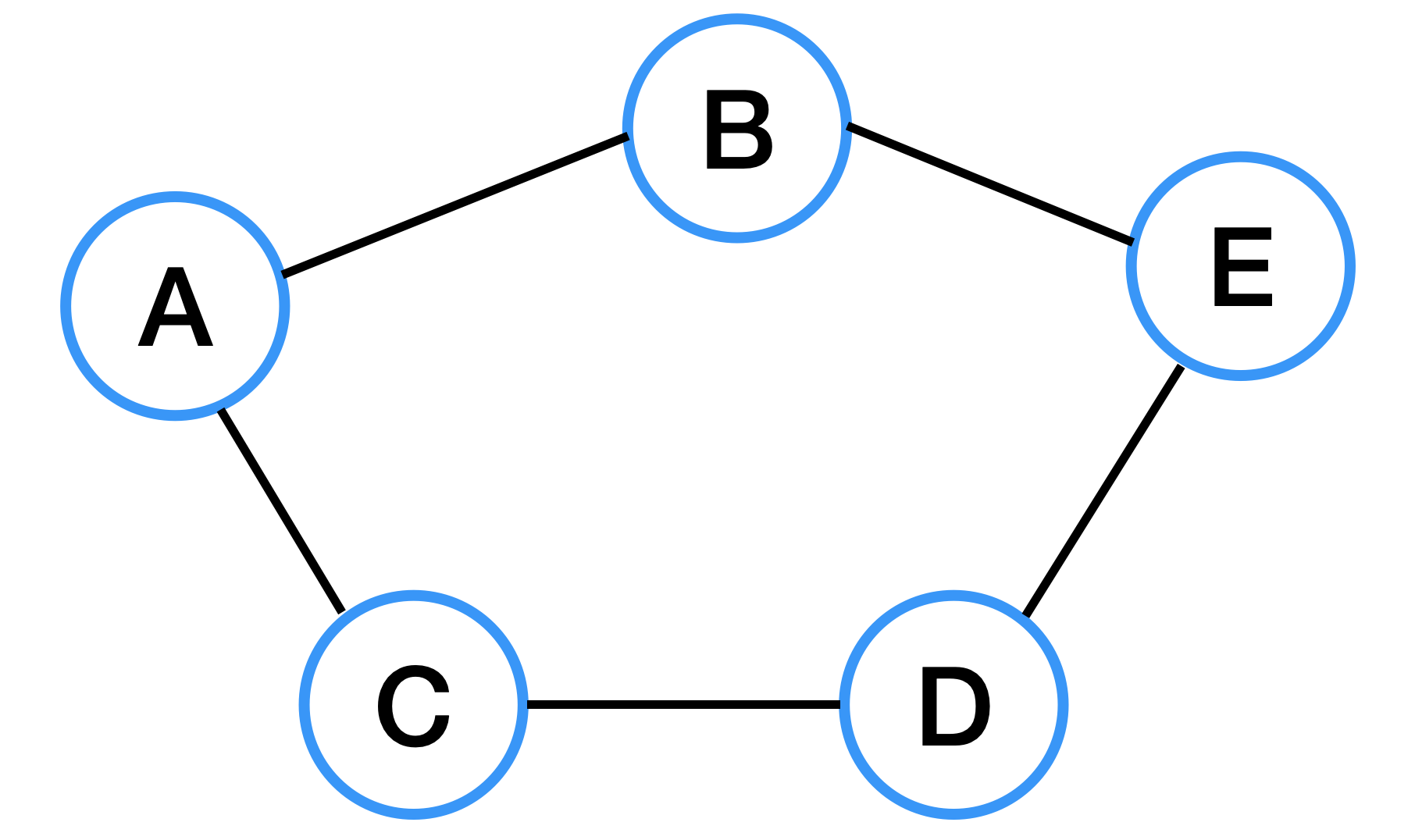
사이클이란 그래프에서 단순 경로의 시작 정점과 종료 정점이 동일한 경우를 말한다. 위의 그래프를 보면 어떤 그래프에서 시작하던간에 항상 자신으로 돌아오게 된다.
Acycle Graph (비순환 그래프)
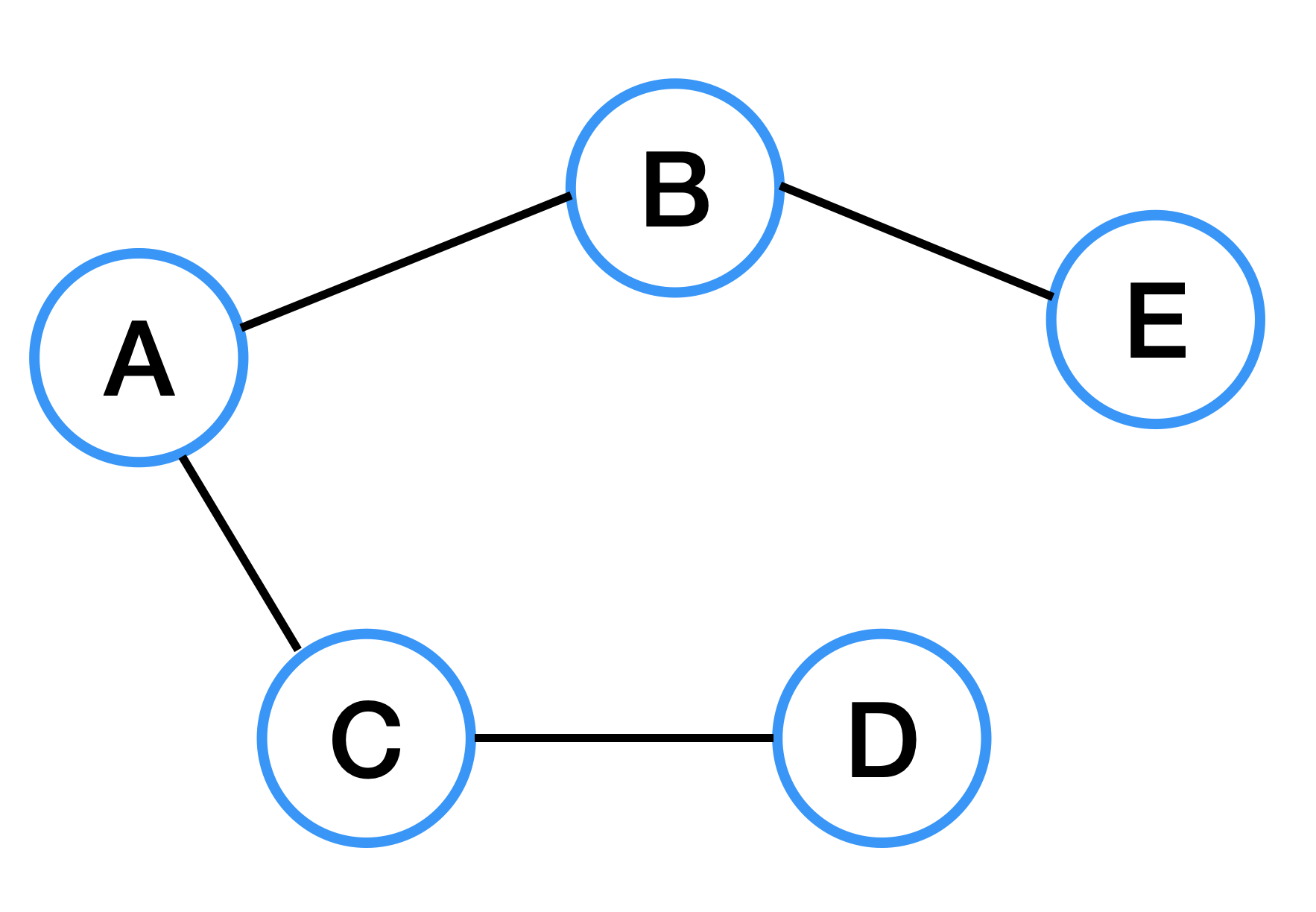
비순환 그래프는 사이클이 없는 그래프를 말한다. 위의 그래프와 같이 사이클이 존재하지 않는 경우이다.
트리는 비순환 그래프이다.
Weighted Graph (가중치 그래프)
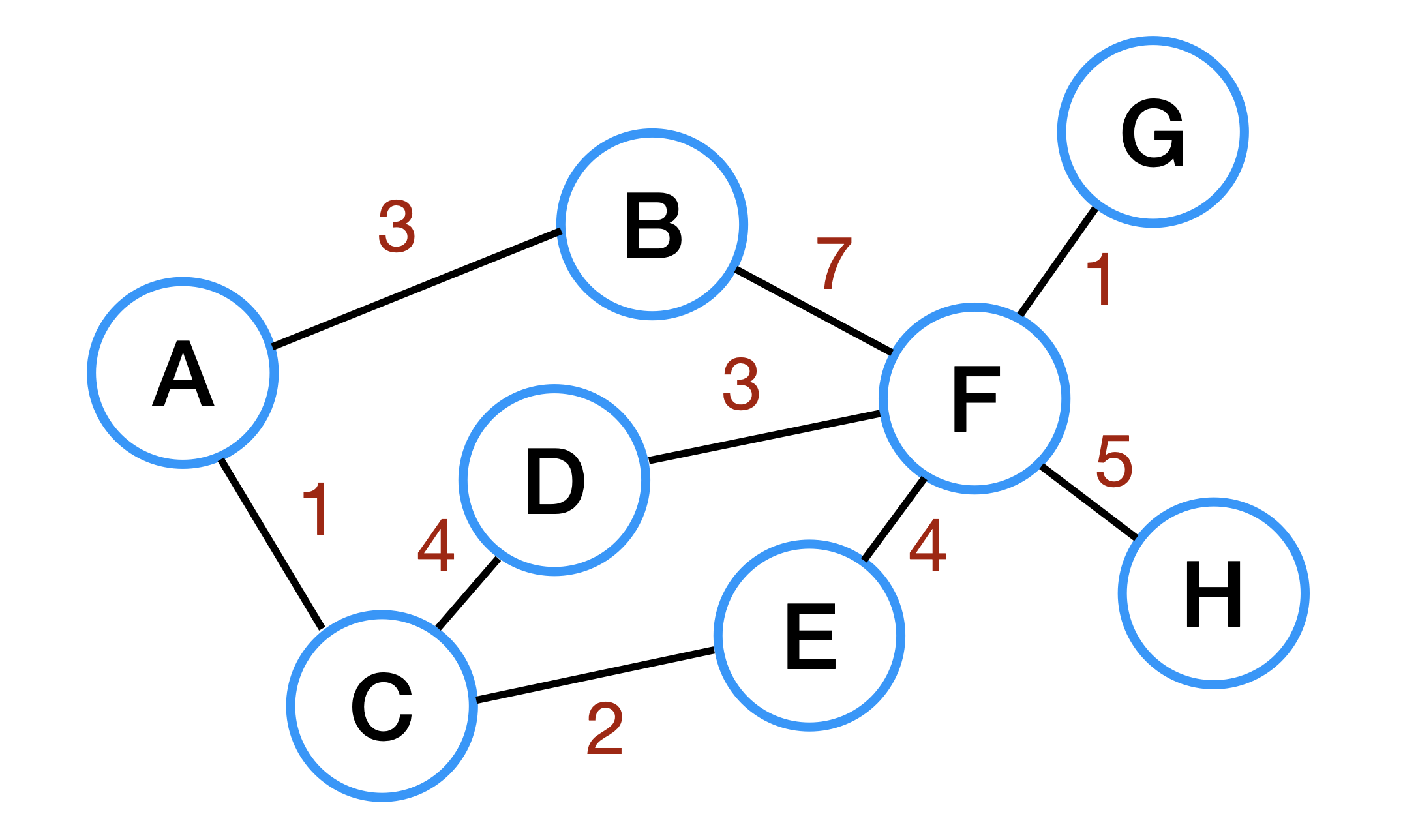
가중치 그래프란 간선에 비용 또는 가중치가 할당된 그래프이다.
'네트워크 (Network)'라고도 한다. ex) 도시-도시의 연결, 도로의 길이, 회로 소자의 용량, 통신망의 사용료 등.
Complete Graph (완전 그래프)
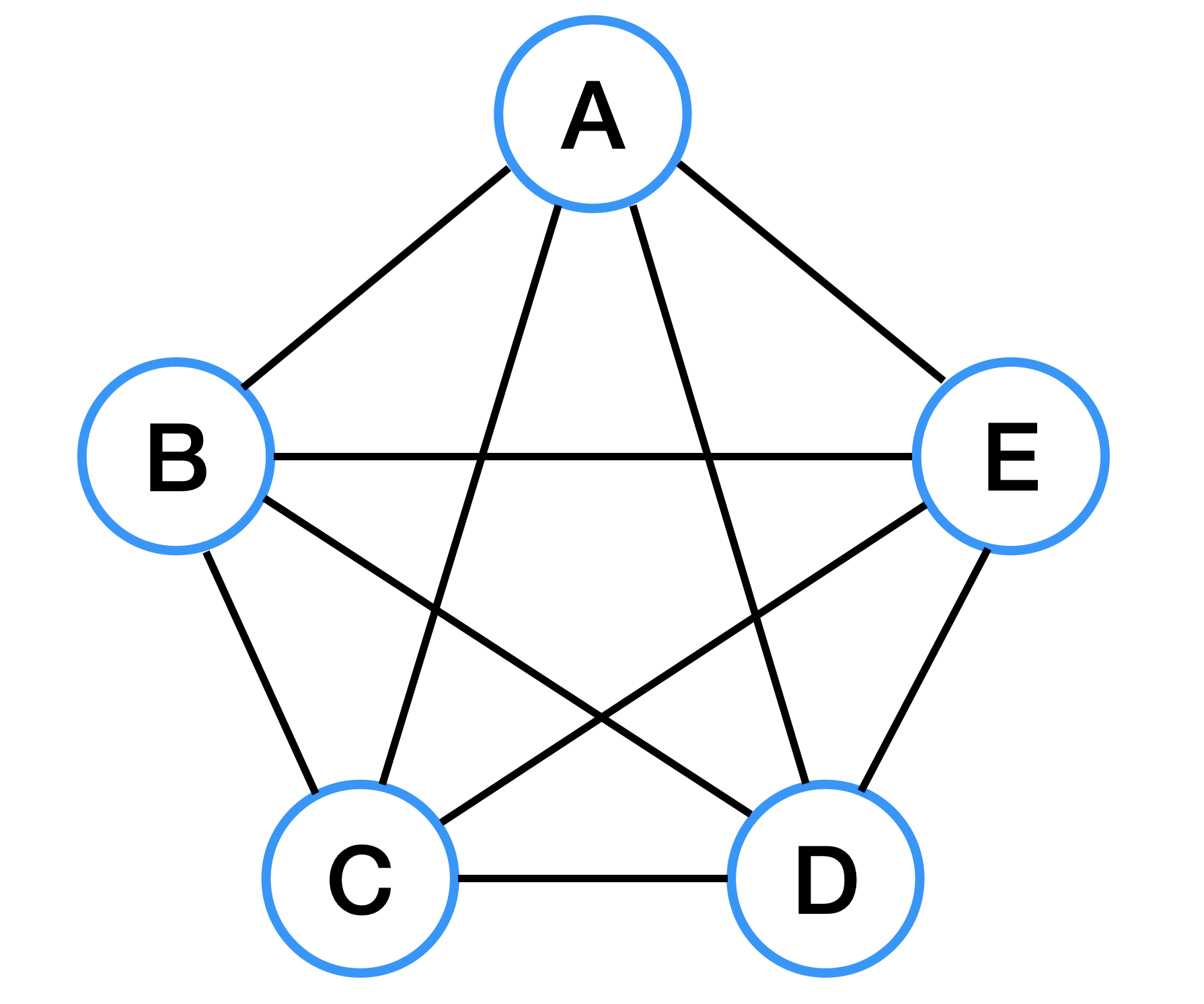
완전 그래프는 모든 정점이 서로 하나의 간선으로 연결되어 있는 그래프를 말한다.
무방향 완전 그래프의 경우, 정점이 n개일 때 간선의 수: n * (n-1) / 2
Sparse Graph vs Dense Graph
Sparse Graph (희소 그래프)
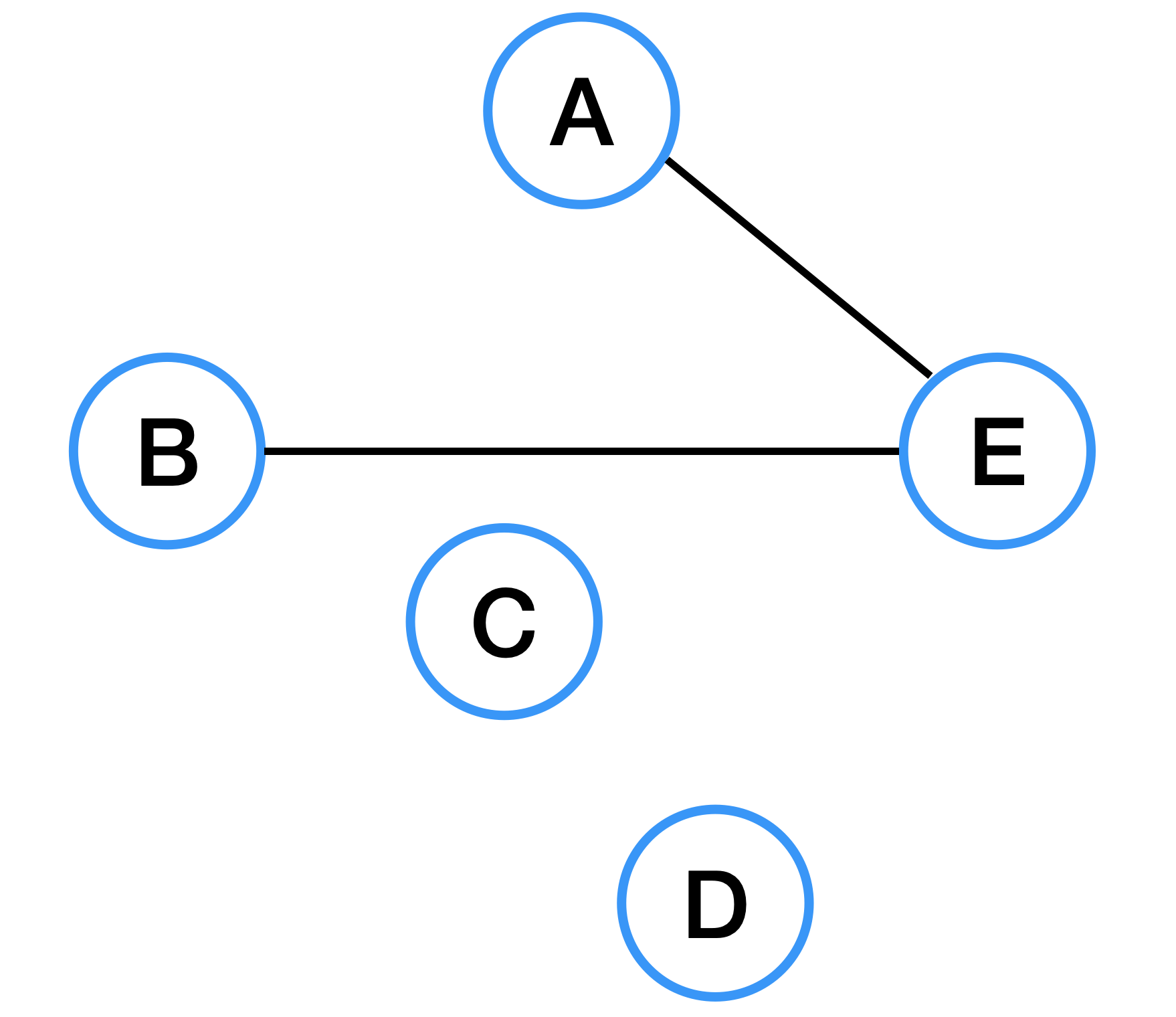
희소 그래프란 정점의 개수보다 간선 개수가 적은 그래프를 뜻한다.
Dense Graph (밀집 그래프)
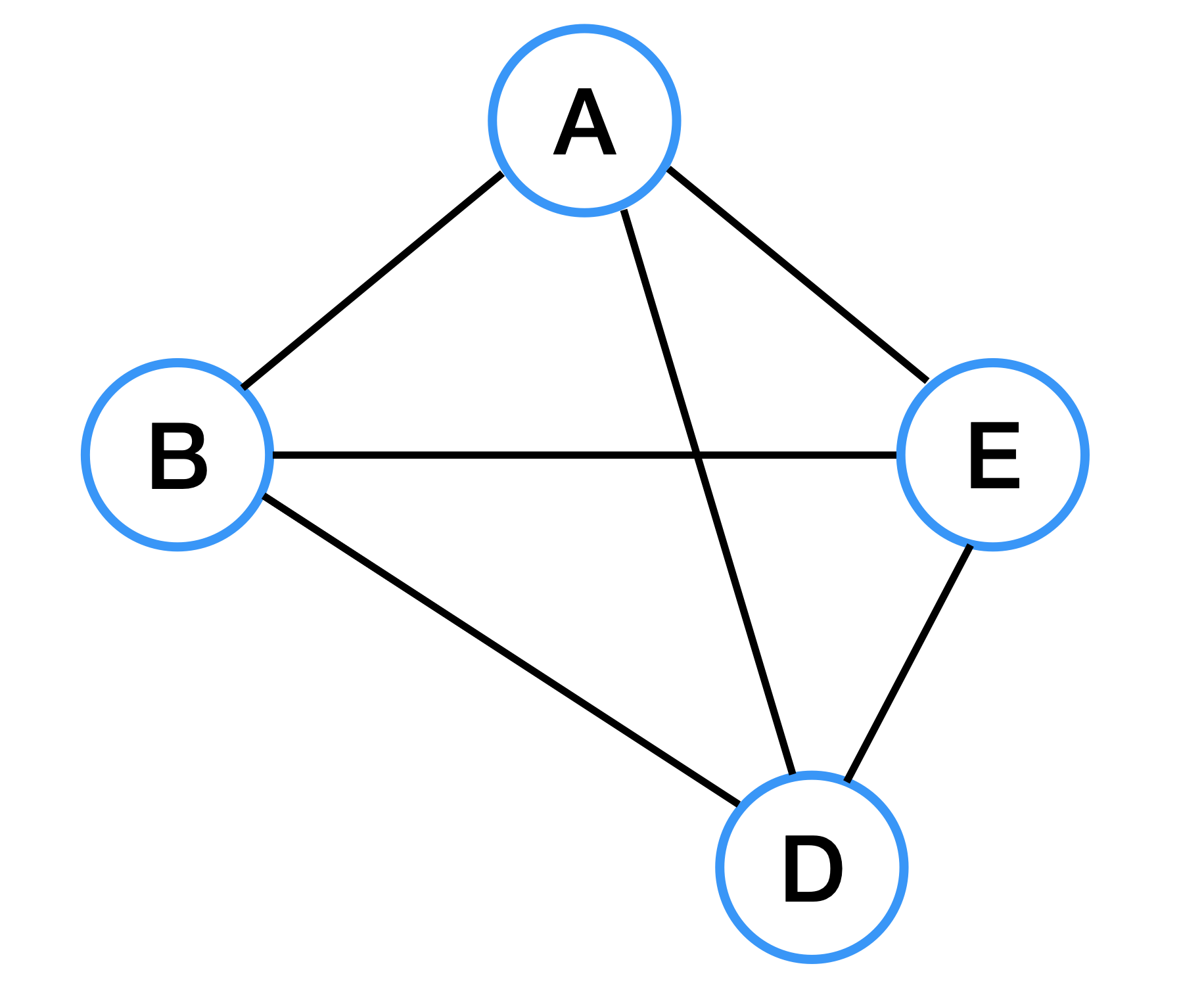
밀집 그래프란 정점의 개수보다 간선 개수가 많은 그래프를 뜻한다.
그래프의 구현
인접 리스트 (adjacent List)
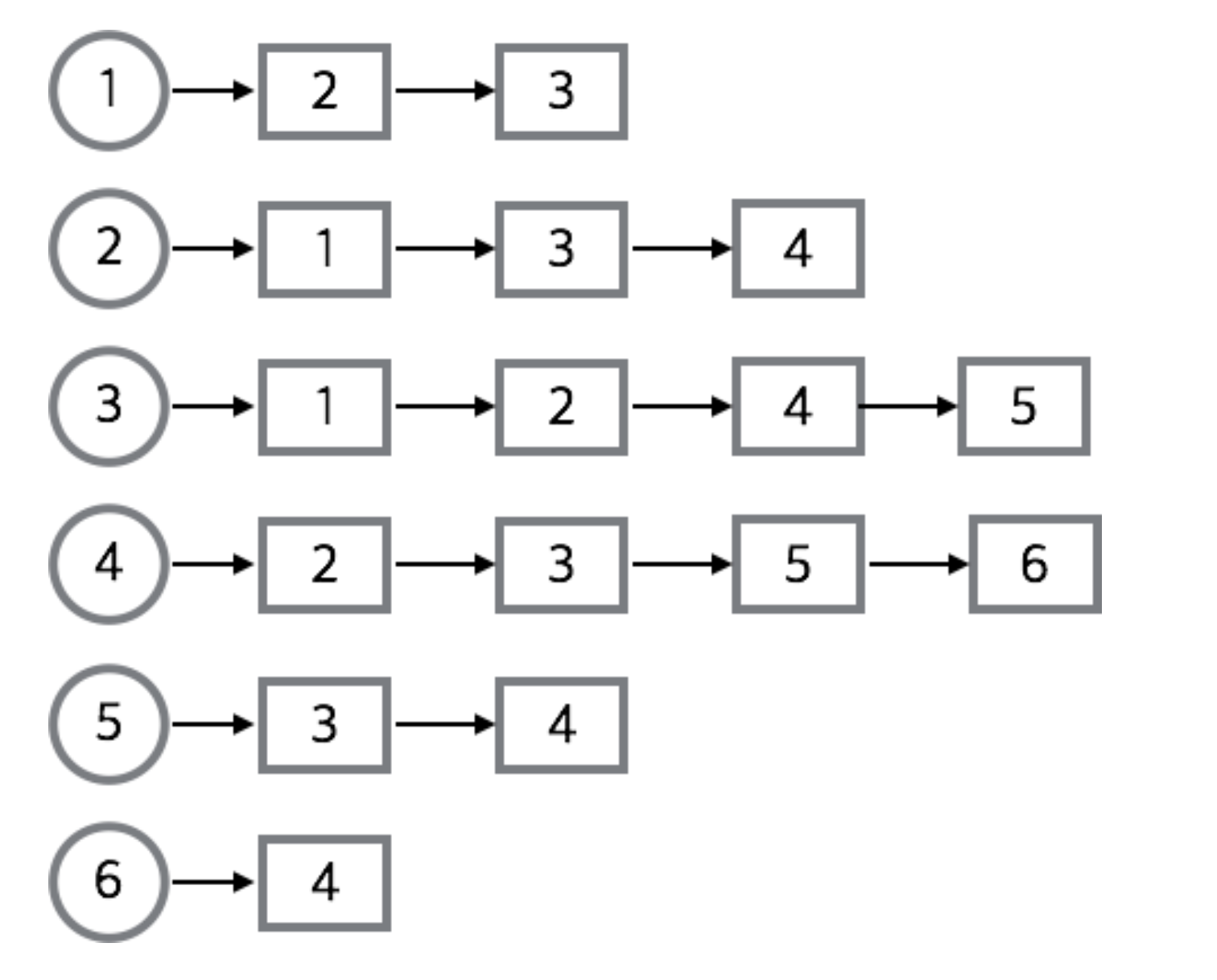
- 정점의 인접 리스트를 이용하여 구현하는 방법이다.
- 모든 정점(노드)의 인접 정점을 리스트로 만드는 방법이다.
배열과 배열의 각 인덱스마다 존재하는 또다른 리스트(배열, 동적 가변 크기 배열(ArrayList), 연결 리스트(Linked List) 등)를 이용하여 인접 리스트를 표현한다. - 무방향 그래프에서는 하나의 간선이 두번씩 저장된다.
- (a, b)와 (b, a)으로써 같은 간선이지만 출발 정점에 모두 저장되기 때문이다.
- 정점의 수 N, 간선의 수 E, 무방향 그래프의 경우
N개의 리스트, N개의 배열, 2E개의 노드가 필요하다. - 트리에서는 특정 노드(루트 노드)에서 다른 모든 노드로 접근이 가능하기에
Tree클래스가 필요 없다.
그래프에서는 특정 노드에서 다른 모든 노드로 접근이 가능하지 않기에Graph클래스가 필요하다.
class Graph {
public Node[] nodes;
}
// Node 클래스는 트리의 Node 클래스와 동일
class Node {
public String name;
public Node[] children;
}인접 행령 (Adjacency Matrix)
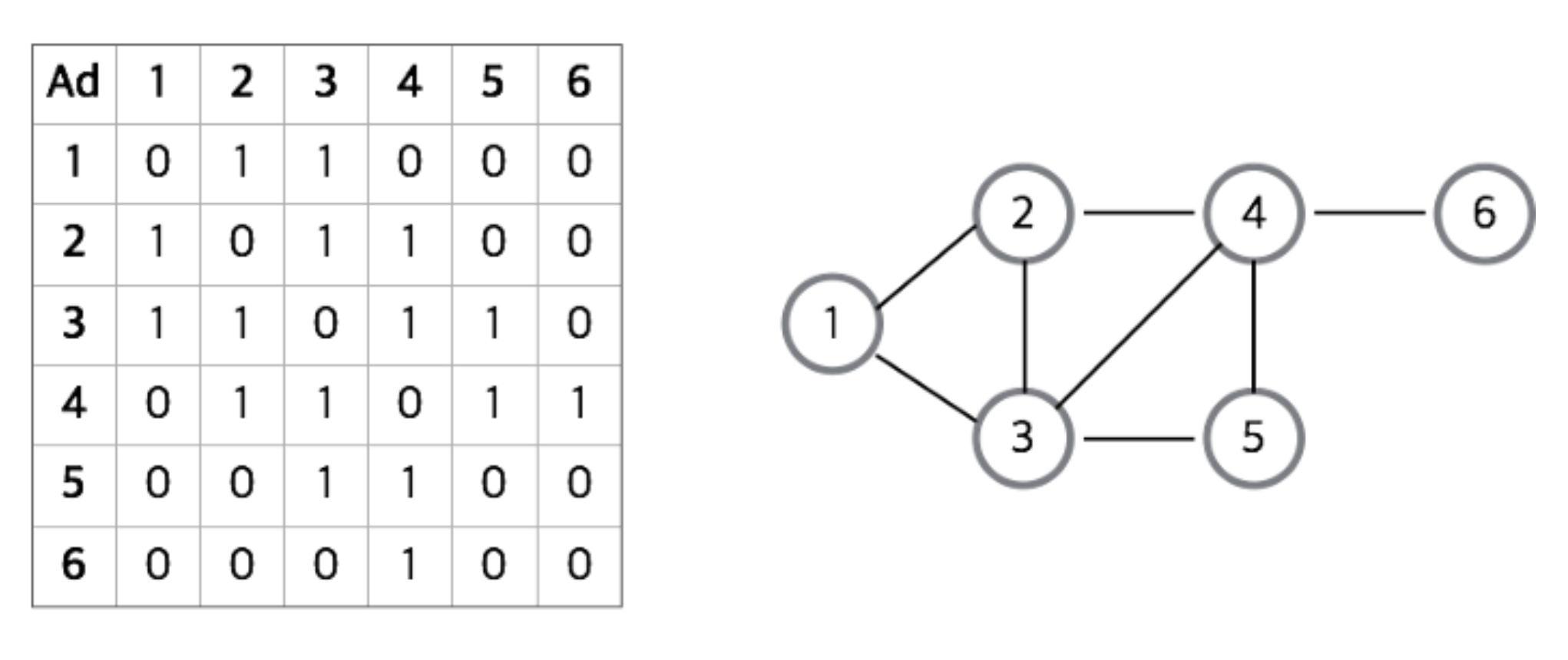
- 그래프에 V개의 정점이 있을 때, V 크기의 정방행렬을 이용하여 구현하는 방법이다.
Matrix[i][j] == 1이면 정점 i에서 j로 가는 간선이 존재하고
Matrix[i][j] == 0이면 정점 i에서 j로 가는 간선이 존재하지 않는다는 뜻이다. - 값으로 1, 0 대신 boolean을 사용해도 된다.
- 해당하는 위치의 값을 통해서 정점 간의 연결 관계를
O(1)로 알 수 있다. - 모든 정점에 대해 다른 모든 정점과의 관계를 표현한 행렬이므로,
간선 유무에 상관없이 V2의 메모리 공간이 필요하다.
구현 방법 선택
인접 리스트
- 희소 그래프(Sparse Graph)를 표현하는 데에 적당하다.
인접 리스트는 간선의 개수에 따라 필요한 메모리 공간의 크기가 달라지기 때문이다. - 장점
- 어떠한 정점의 인접 정점들을 쉽게 찾을 수 있다.
- 그래프에 존재하는 모든 간선의 수를
O(V + E)안에 알 수 있다.
(인접 리스트 전체를 조사하는 방법)
- 단점
- 모든 정점의 인접 리스트를 확인해야 하므로, 정점 간에 연결되어 있는지 확인하는 데에 오래 걸린다.
인접 행렬
- 밀집 그래프(Dense Graph)를 표현하는 데에 적당하다.
- 장점
- 두 정점을 연결하는 간선의 존재 여부(M[i][j])를 O(1)안에 즉시 알 수 있다.
- 정점의 차수는 O(N)안에 알 수 있다.
인접배열의 i번째 행(또는 열)을 모두 더하면 된다.
- 단점
- 어떤 노드에 인접한 노드들을 찾기 위해서는
모든 노드를 전부 순회해야 한다.
-> 전부 순회하지 않고 i번째 행과 i번째 열을 조사하면 된다. - 그래프에 존재하는 모든 간선의 수는 O(N2) 안에 알 수 있다.
(인접 행렬 전체를 조사하는 방법)
- 어떤 노드에 인접한 노드들을 찾기 위해서는
탐색
그래프의 탐색은 주로 2가지 방법을 사용한다.
DFS (Depth Frist Search, 깊이 우선 탐색)
그래프 상에 존재하는 임의의 한 정점을 기준으로 잡고(루트 노드) 시작하여 다음 정점을 탐색하기 전에 해당 정점을 완벽하게 탐색 후 다음 정점을 탐색하는 방법이다.
즉, 넓게 탐색하기 보다는 깊게 탐색하는 것이 우선인 방법이다.
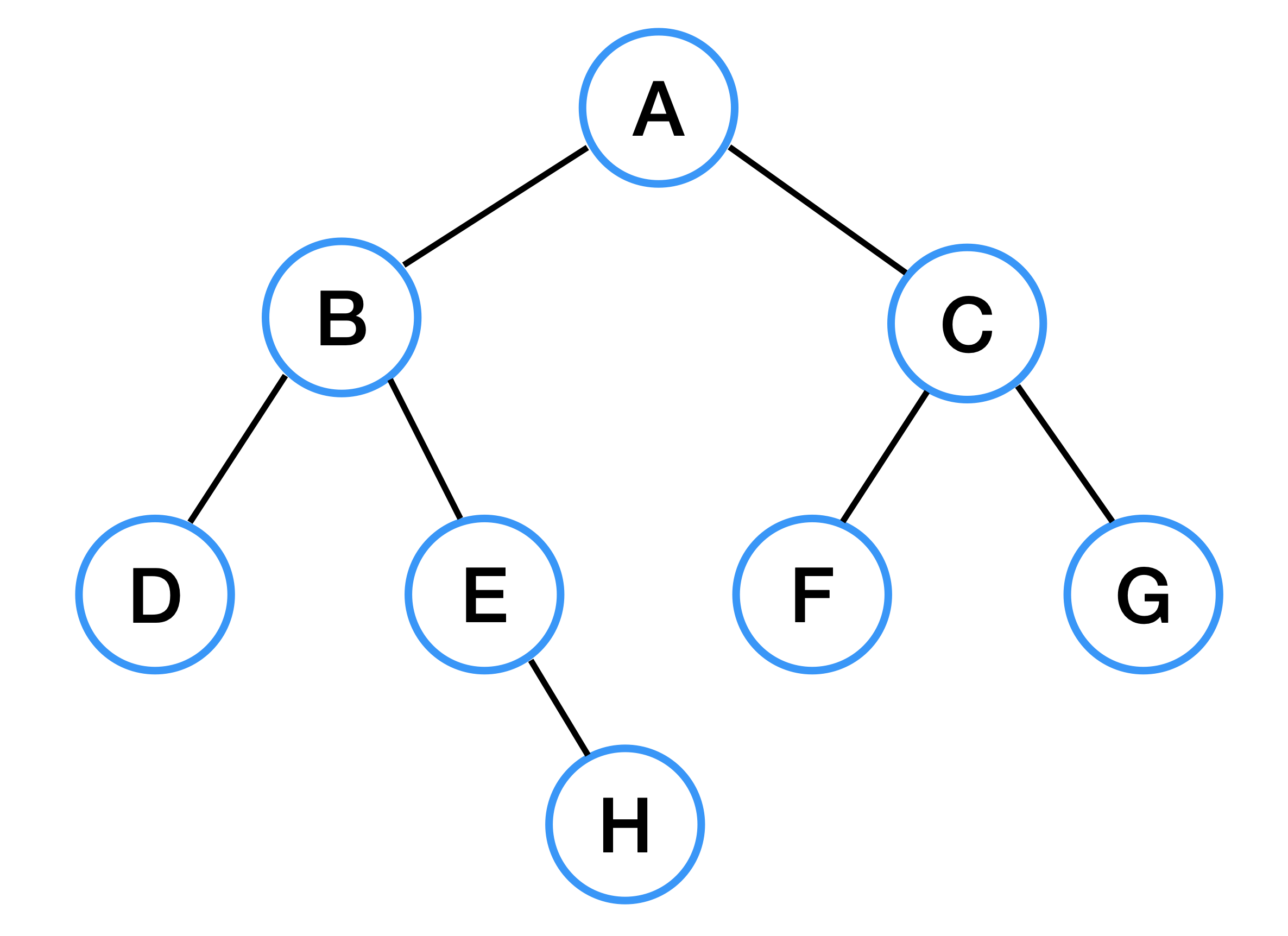
위와 같은 그래프가 있을 때 루트 노드는 임의로 어떤 것이든 잡아도 상관은 없지만, A를 루트 노드로 설정하여 DFS를 수행하면 아래와 같은 순서로 탐색하게 된다.
A -> B -> D -> E -> H -> C -> F -> G
A 노드에서 B 노드를 탐색하기 시작했으면 B 노드 아래의 노드들을 모두 탐색 한 후에 C 노드를 탐색한다는 것이 핵심이다.
DFS를 구현했을 때 탐색 순서를 보면, 노드 탐색 후 다시 이전 노드로 돌아가는 순서로 진행이 된다. 따라서 DFS를 구현하기 위해서는 Stack 자료구조를 사용해야 한다.
시간복잡도는 O(V+E)이다.
DFS는 모든 관계를 다 살펴보아야 할 때 주로 사용된다.
BFS (Breadrh Frist Search, 너비 우선 탐색)
그래프 상에 존재하는 임의의 한 정점을 기준으로 잡고(루트 노드) 시작하여 인접한 정점을 먼저 탐색하는 방법이다.
즉, 깊에 탐색하기 보다는 넓게 탐색하는 것이 우선인 방법이다.
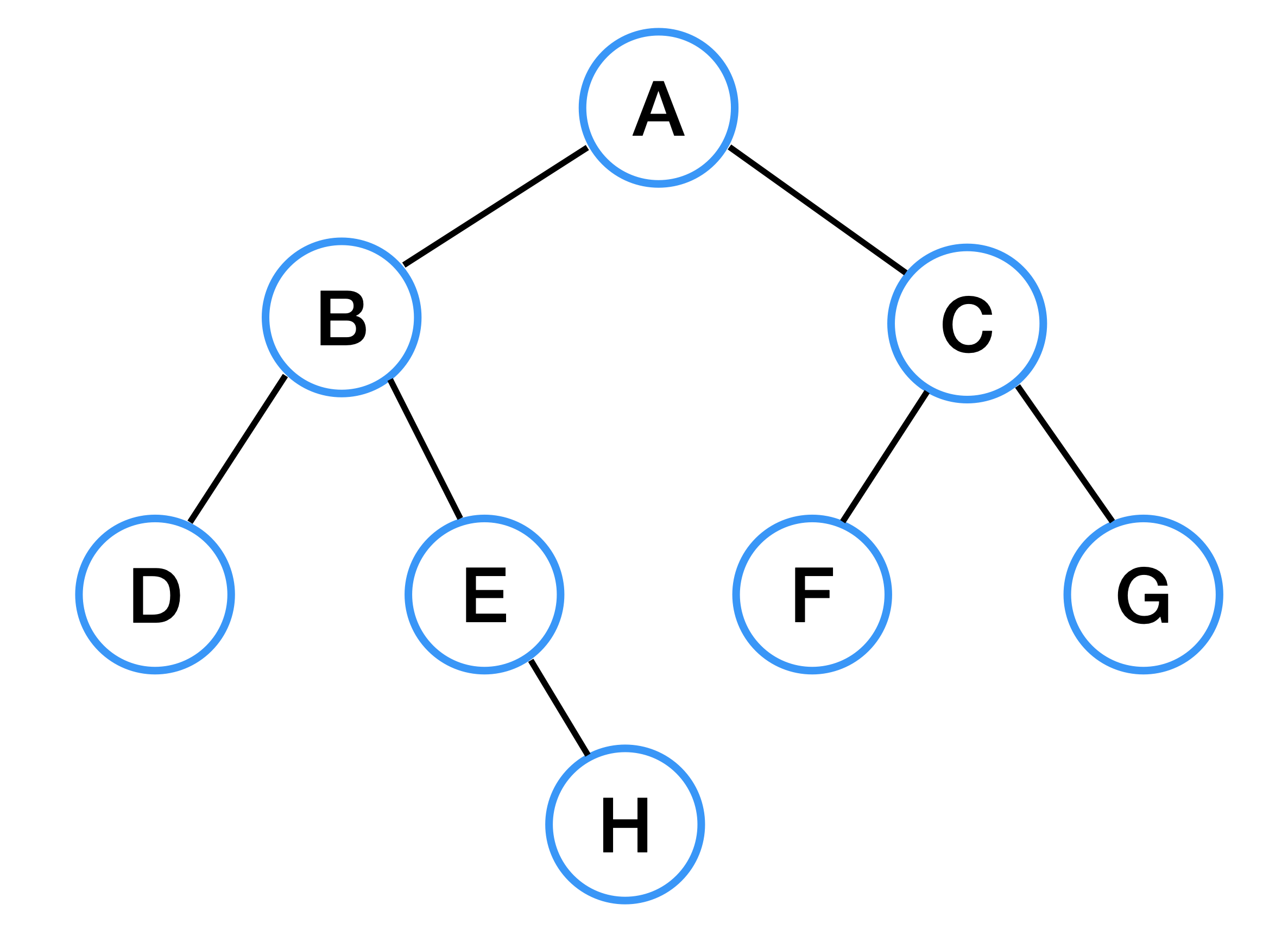
DFS에서 설명한 것과 같은 그래프이다. A를 루트 노드로 잡았을 때, BFS를 수행하면 탐색 순서는 아래와 같다.
A -> B -> C -> D -> E -> F -> G -> H
루트 노드에서 거리가 가까운 순서대로 탐색하는 방법이므로 위와 같은 순서가 된다.
BFS는 거리가 가까운 순서대로 탐색하기 위해서는 거리가 가까운 순서대로 저장될 자료구조가 필요하다. 따라서 Queue 자료구조를 사용한다.
시작하기 전에 루트 노드를 Queue에 집어넣은 후 시작한다. 그리고 하나씩 dequeue하고, dequeue한 노드에 대해 탐색 후 그와 연결된 노드들은 enqueue한다. 이러한 순서대로 수행하다보면 루트 노드를 기준으로 경로가 가까운 노드 먼저 탐색하게 된다.
BFS의 시간복잡도는 O(V+E) 이다.
BFS는 기준으로 잡은 루트 노드와의 최단 경로를 구할 때 사용한다.
참고
한재엽님 Github Interview_Question_for_Beginner
https://ko.wikipedia.org/wiki/그래프_(자료_구조)
https://gmlwjd9405.github.io/2018/08/13/data-structure-graph.html
https://medium.com/@gwakhyoeun/til-자료구조-graph-이해하기-6f92fd87a0bd
https://gamedevlog.tistory.com/15
