
Trie (트라이)
트라이는 문자열 집합을 표현하는 트리 자료구조입니다. 문자열의 검색을 빠르게 도와줍니다.
원하는 원소를 찾기 위해 자주 사용되는 이진 검색 트리 등에서는 시간복잡도가 O(log N)이 걸립니다. 하지만 이러한 방법으로 두 문자열을 비교하게 된다면 문자열의 길이만큼의 시간이 걸리므로 O(M log N)의 시간이 걸립니다.
이러한 단점을 해결하고 문자열을 빠르게 탐색할 수 있는 자료구조가 트라이(Trie)입니다.
작동 원리
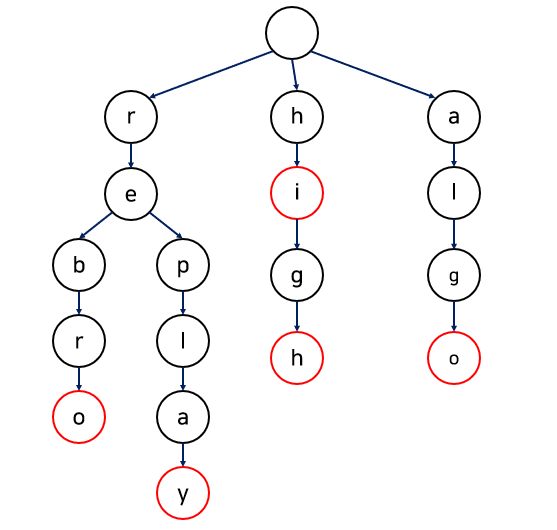
위 그림은 문자열 집합{"rebro", "replay", "hi", "high", "algo"}를 트라이로 구현하여 그 구조를 그림으로 표현한 것입니다.
트라이는 위 그림과 같이 집합에 포함된 문자열의 접두사들에 대응하는 노드들이 서로 연결된 트리이 입니다.
트라이는 각 노드마다 자손 노드를 가리키는 포인터 목록과 이 노드가 종료 노드인지를 나타내는 boolean 값 변수로 구성됩니다. 위의 그림에서 빨간 노드가 문자열의 끝을 의미합니다.
트라이는 루트에서부터 내려가는 경로에서 만나는 글자들을 모으면, 찾고자하는 문자열의 접두사들을 얻을 수 있습니다.
예를 들어 rebro를 찾는다고 하면,
r -> re -> reb -> rebr -> rebro
순서로 찾게되므로 자연스레 rebro의 점두사들을 모두 구하게 됩니다. 따라서 노드에 접두사들을 저장할 필요 없이, 문자 하나만 저장해도 충분하게 됩니다..
트라이의 장단점
장점
문자열 검색 및 추가가 빠르다.
문자열을 집합에 추가하는 경우에도 문자열의 길이만큼 노드를 따라가거나 추가하면 됩니다. 따라서 문자열의 추가와 탐색 모두 O(M)만에 가능합니다.
단점
필요한 메모리의 크기가 너무 크다.
문자열이 모두 영소문자로 이루어져 있더라도, 자식노드를 가리키는 포인터를 최대 26개(모든 알파벳)를 저장해야 합니다.
최악의 경우에는 집합에 포함되는 문자열들의 길이의 총합만큼의 노드가 필요하므로, 총 메모리는 O(포인터 크기 * 포인터 배열 개수 * 총 노드의 개수)가 됩니다.
따라서 이 단점을 해결하기 위해 보통 map이나 vector를 이용하여 필요한 노드만 메모리에 할당하는 방식을 이용하는데, 문제에 따라 메모리 제한이 빡빡한 경우에는 최적화가 까다롭습니다. 또한, 문제에서 주어진 조건을 보고 트라이를 이용할 수 있는 문제인지 파악하는 것도 중요합니다.
활용 용도
기능이 문자열을 검색하고 속도가 빠르다는 장점때문에 검색어 자동 완성, 사전에서 단어 검색, 문자열 검사 등에 자주 사용된다.
구현
아래 코드는 트라이를 직접 구현해서 문자열을 넣어보고, 문자열을 찾아보는 과정을 만든 코드입니다.
모든 문자열은 영어 소문자라는 가정하에 코드를 만들었고, 언어는 java입니다.
public class Trie_example {
static class Trie {
boolean end;
Trie[] child;
Trie() {
end = false;
child = new Trie[26];
}
public boolean insert(String str, int idx) {
if(idx == str.length()) {
end = true;
return true;
} else {
int next = str.charAt(idx) - 'a';
if (child[next] == null)
child[next] = new Trie();
return child[next].insert(str, idx + 1);
}
}
public boolean find(String str, int idx) {
int find_keyword = str.charAt(idx) - 'a';
if (child[find_keyword] == null)
return false;
if (str.length() == idx + 1) {
if (child[find_keyword].end) // 모든 알파벳과 길이가 일치한 경우
return true;
else // 찾는 알파펫보다 더 긴 단어만 저장된 경우
return false;
}
return child[find_keyword].find(str, idx + 1);
}
}
public static void main(String[] args) {
String str = "acbfh"; // 0, 2, 1, 5, 7
String str2 = "abcdd";
String str1 = "abcd";
Trie trie = new Trie();
trie.insert(str, 0);
trie.insert(str1, 0);
trie.insert(str2, 0);
trie.insert("abcde", 0);
System.out.println(trie.find("acbfh", 0));
System.out.println(trie.find("abcdd", 0));
System.out.println(trie.find("abcd", 0));
System.out.println(trie.find("abcde", 0));
System.out.println(trie.find("abcdef", 0));
}
}트라이에서 다음에 찾을 알파벳의 순서 - 1 == 인덱스 이므로
별도로 문자 데이터를 저장하지 않아도 된다.
예를 들면, 다음에 a를 찾을 순서이면 현재 트리에서 0번째 노드가 존재하는지 확인하면 되고, f를 찾을 순서이면 3번째 노드가 존재하는지 확인하면 된다.
참고
gyoogle님 Github tech-interview-for-developer
https://rebro.kr/86
https://travelbeeee.tistory.com/418

덕분에 Trie 개념과 구현부 이해했습니다. 감사합니다.
다만, 구현부 find() 함수에서
if (child[find_keyword] == null)
return false;
조건 밑에 이 조건도 추가해야 되는 것 같습니다.
if(str.length() == idx+1 && !child[find_keyword].end)
return false;
이 조건이 없으면 str보다 긴 문자열이 저장되어있을 때 IndexOutOfRange 오류가 발생하네요.
저 insert에 find("abc", 0) 같은 케이스입니다~