
Heap이란 우선순위 큐를 위해 만들어진 자료구조다. 따라서 힙에 대해 알기 전에 우선순위 큐에 대해 알아야 한다.
Priority Queue (우선순위 큐)
우선순위의 개념을 큐에 도입한 자료구조이다.
데이터들이 우선순위를 가지고 있고, 우선순위가 높은 데이터가 먼저 나오는 FIFO 구조의 선형 자료구조이다.
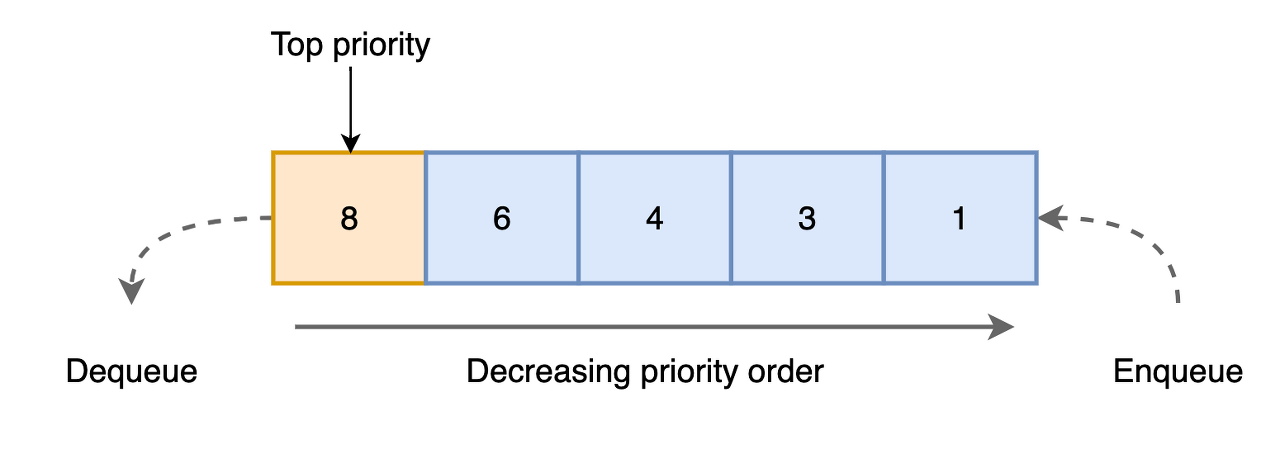
특징
- 모든 요소는 우선순위가 있습니다.
- 우선순위가 높은 요소가 우선순위가 낮은 요소보다 먼저 나옵니다.
- 두 쇼오싀 우선순위가 같으면, 큐의 순서에 따라 나옵니다.
구현 방식과 시간 복잡도
| 구현 방법 | enQueue() | deQueue() |
|---|---|---|
| 배열 (unsorted array) | Big-O(1) | Big-O(N) |
| 연결 리스트 (unsorted linked list) | Big-O(1) | Big-O(N) |
| 정렬된 배열 (sorted array) | Big-O(N) | Big-O(1) |
| 정 렬된 연결 리스트 (sorted linked list) | Big-O(N) | Big-O(1) |
| 힙 (heap) | Big-O(log N) | Big-O(log N) |
위와 같이 힙은 최악의 경우에도 Big-O(log N) 을 보장하기에 일반적으로 힙을 통해 우선순위 큐를 구현합니다.
Heap (힙)
힙은 여러 값들 중 최댓값 또는 최솟값을 빠르게 찾아서 반환하기 위래 만들어진 자료구조이다.
특징
- 완전 이진 트리(Complete Binary Tree)이다.
- 부모 노드의 키값과 자식 노드의 키값 사이에는 대소관계가 성립한다.
키값 대소관계는 부모-자식 간에만 성립되며, 형제 사이에는 대소관계가 정해지지 않는다. - 반정렬 상태
힙 트리는 중복된 값을 허용한다. (이진 탐색 트리는 중복값 허용 X)
종류
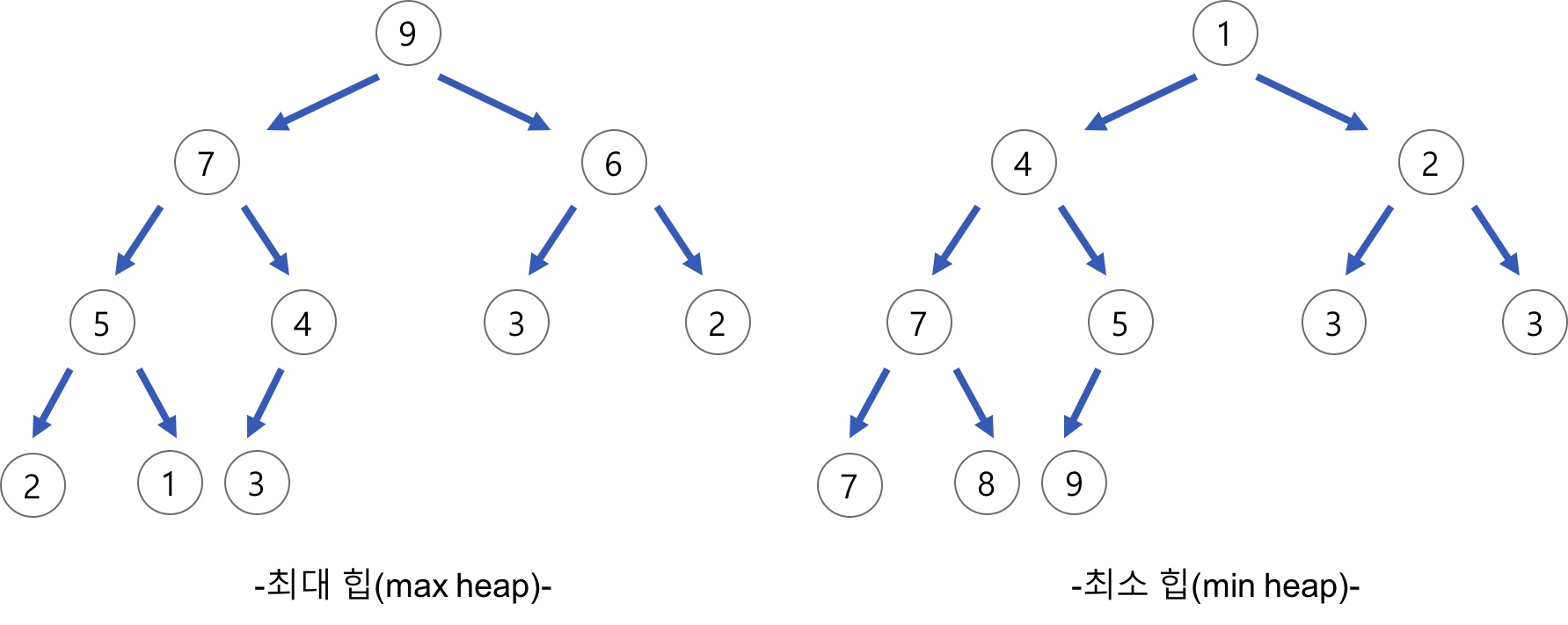
최대 힙 (Max Heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
- 가장 큰 값이 루트 노드에 위치
최소 힙 (Min Heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
- 가장 작은 값이 루트 노드에 위치
표현
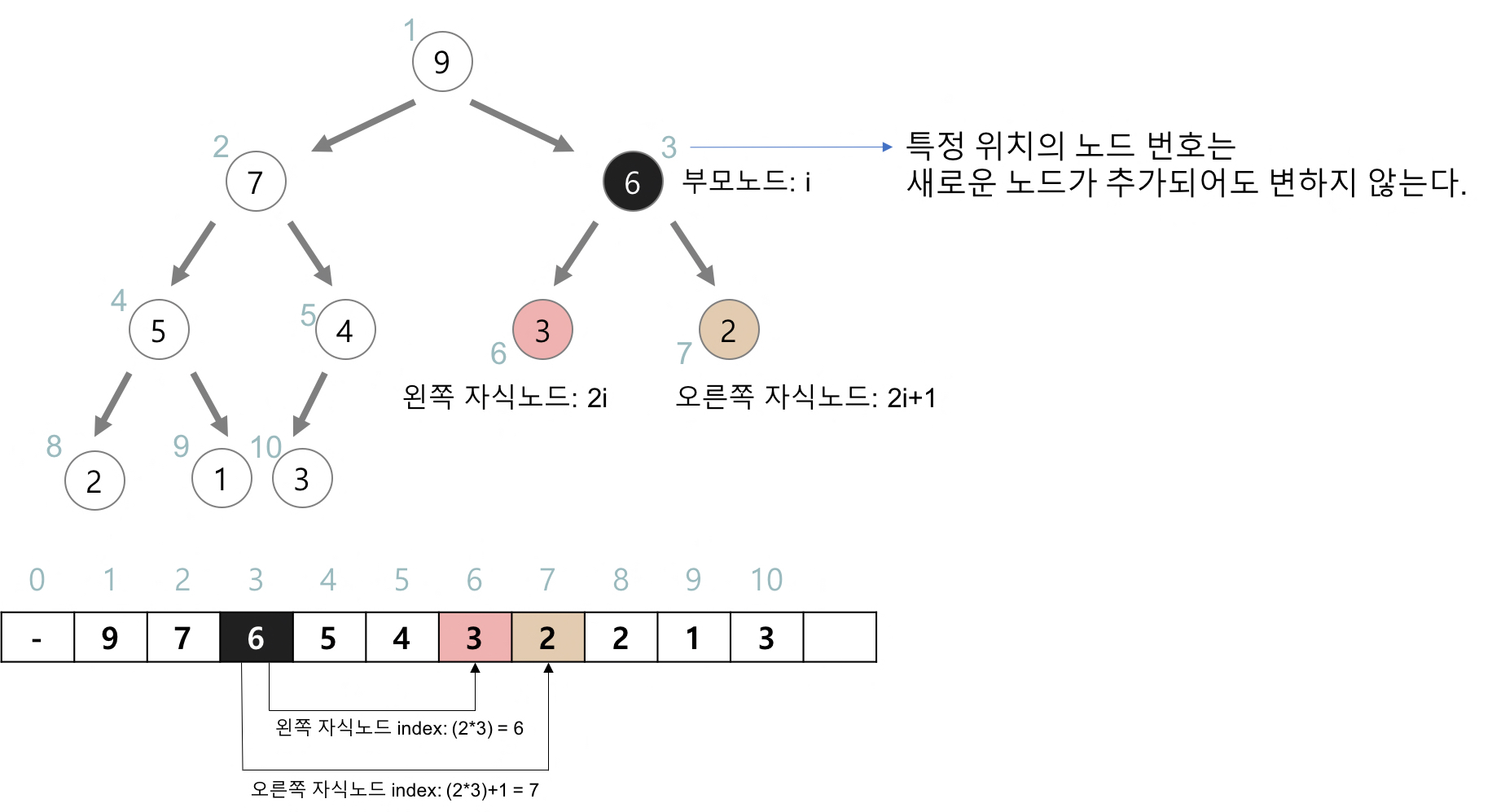
힙을 저장하는 표준적인 자료구조는 배열이다.
일반적으로 구현을 쉽게 하기 위해 index 0 사용하지 않고, 루트 노드를 index 1에 위치시킨다.
- i번째 노드의 부모 노드 index: ⌊i / 2⌋
- i번째 노드의 왼쪽 자식 노드 index: 2 * i
- i번째 노드의 오른쪽 자식 노드 index: 2 * i + 1
구현
Heapify
Heapify는 이진트리에서 힙 구조로 변경하거나 데이터를 삽입 또는 삭제 후, 힙 속성을 유지하는 작업을 수행한다.
힙의 삽입과 삭제 연산
최대 힙(Max Heap)에서 heapify의 작업은 아래와 같다.
1. 자신이 가진 값과 자식 노드 값을 비교
2. 만약 자식 노드 값이 크다면 왼쪽 오른쪽 자식 중 가장 큰 값으로 교환
3. 힙 속성이 유지될 때까지 1, 2번 과정 반복
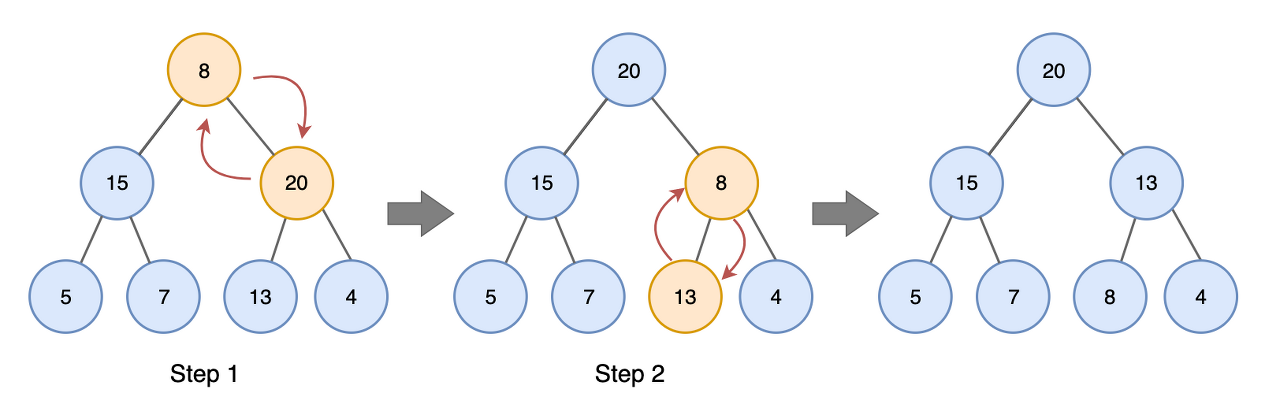
위 그림읕 통해 설명하자면,
Step 1. 루트 노드와 자신 노드의 값을 비교. 오른쪽 자식 노드의 값이 가장 크므로 루트 노드와 오른쪽 자식 노드와 swap
Step 2. 바뀐 후 다시 자식 노드들과 값을 비교. 왼쪽 자식 노드만이 자신보다 값이 크므로 왼쪽 자식 노드와 swap
위의 작업을 완료하면 이제 8은 리프 노드이므로 더이상 이동할 곳이 없고, 트리 전체적으로 힙 속성이 유지됨
void max_heapify (int arr[], int i)
{
int largest = i;
int l_child = 2 * i; // 왼쪽 자식 노드 인덱스
int r_child = 2 * i + 1; // 오른쪽 자식 노드 인덱스
int size = arr.length;
// i번째 요소와 그 자식 노드들의 값 비교
if(l_child <= size && arr[l_child] > arr[i]) // 왼쪽
largest = l_child;
if(r_child <= size && arr[r_child] > arr[largest]) // 오른쪽
largest = r_child;
// i번째 요소보다 큰 자식 노드가 존재한다면
if(largest != i) {
int tmp = arr[i]; // 자식 노드와 현재 노드 값 교환
arr[i] = arr[largest];
arr[largest] = tmp;
max_heapify (arr, largest); // 교환된 자식노드부터 다시 heapify
}
}힙의 삽입
아래는 새로운 데이터가 삽입되는 경우를 그림으로 표현한 것이다.
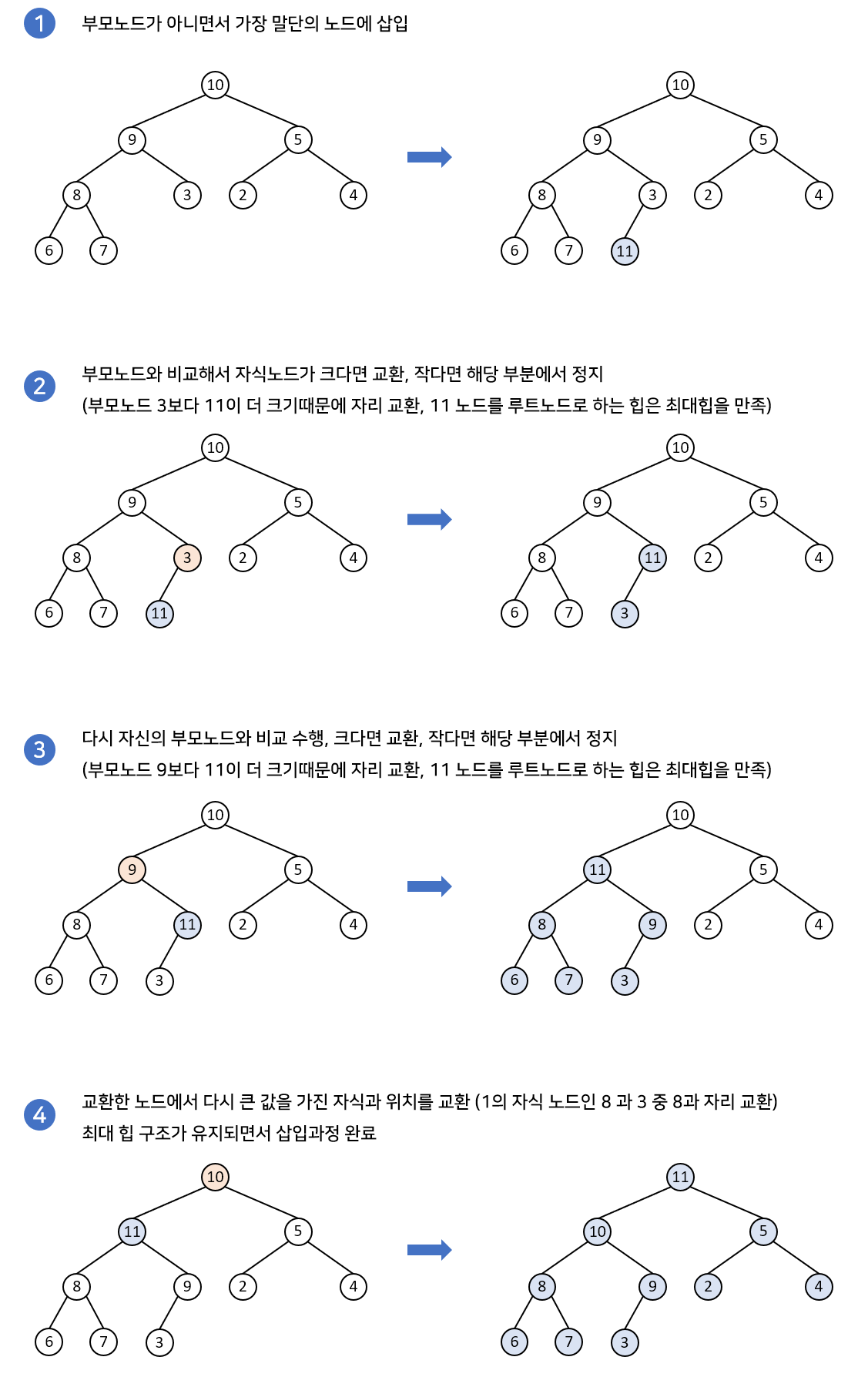
새로 삽입되는 노드는 리프노드가 아니면서 가장 말단에 있는 노드의 자식노드로 추가됩니다. 즉, 가장 마지막 노드로 삽입된다.
이후, 부모노드와 비교하면서 재구조화 과정을 수행한다.
힙의 제거
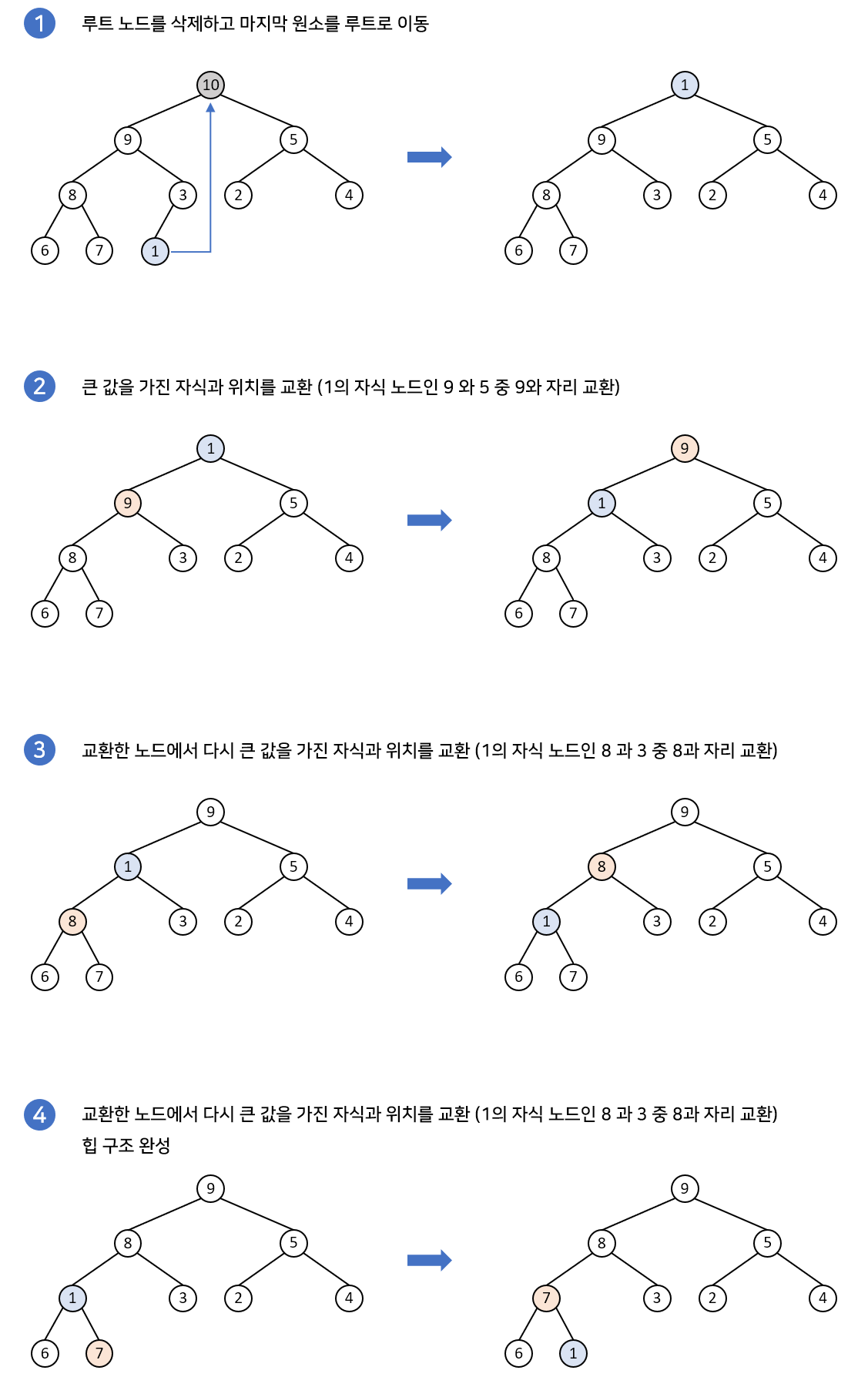
최대 힙에서 최댓값은 루트 노드이므로 루트 노드가 삭제된다.
루트 노드가 삭제되면 가장 말단노드를 루트노드 자리에 대체한 후 재구조화 과정을 수행한다.
참고
한재엽님 Github Interview_Question_for_Beginner
gyoogle님 Github tech-interview-for-developer
https://yoongrammer.tistory.com/81?category=987044
https://yoongrammer.tistory.com/80
https://gmlwjd9405.github.io/2018/05/10/data-structure-heap.html
https://st-lab.tistory.com/225
https://velog.io/@emplam27/자료구조-그림으로-알아보는-힙Heap
