
model 생성
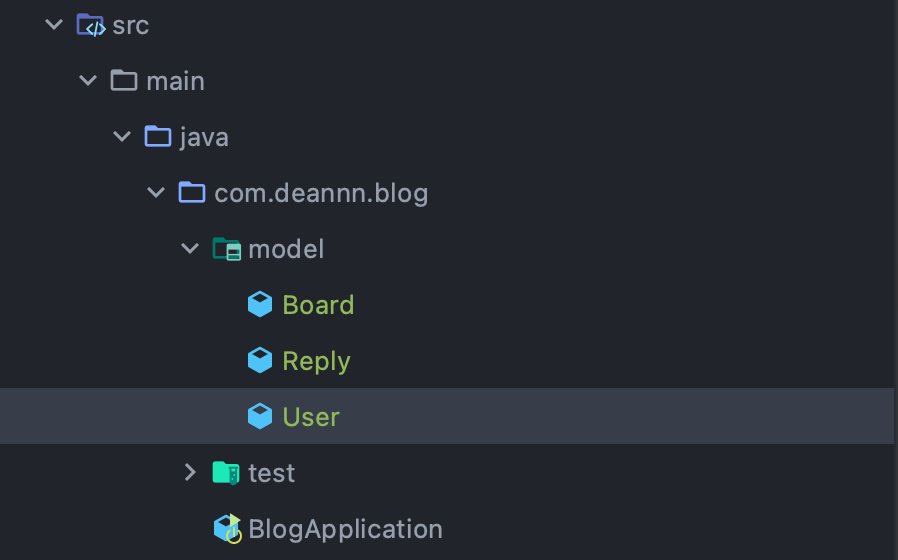
blog - src - java - com.***.blog 안에 model이라는 패키지를 만들고, Board, Reply, User라는 자바 파일을 만든다.
이 파일 별로 테이블이 만들어질 것이다.
User 테이블
public class User {
private int id;
private String username;
private String password;
private String email;
private String role;
private Timestamp createDate;
}일단 User 클래스에서 필요한 변수부터 만든다. 위처럼 코드를 넣으면 된다.
여기서 id가 primary key 역할을 할 것이다.
그리고 아래와 같이 추가한다.
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
@Column(nullable = false, length = 30)
private String username;
@Column(nullable = false, length = 100)
private String password;
@Column(nullable = false, length = 50)
private String email;
@ColumnDefault("'user'")
private String role;
@CreationTimestamp
private Timestamp createDate;
}@Entity
해당 클래스를 테이블로 인식할 수 있도록 만드는 어노테이션
@Id
해당 변수가 primary key로 사용할 수 있는 식별자의 역할을 할 수 있도록 하는 어노테이션이다.
@GeneratedValue(strategy = GenerationType.IDENTITY)
기본키 매핑 전략을 IDENTITY로 설정.
기본키 매핑 전략은 4가지가 존재한다.
- IDENTITY
- SEQUENCE
- TABLE
- AUTO
IDENTITY 전략의 개념은 대략 다음과 같다.
- 기본키 생성을 데이터베이스에 위임하는 전략이다.
- 즉, id값을 null로 하면 DB가 알아서 auto_increment(또는 시퀀스) 해준다.
그 외의 전략에 대해 자세히 알고 싶다면 이 글을 참고하자.
@Column(nullable = false, length = 30)
해당 변수를 컬럼으로 만들고, not null, length=30으로 설정.
그리고 위 코드에서 패스워드 길이가 100인 이유는 나중에 hash함수를 통해 암호화를 할 예정인데, 이 경우 비밀번호가 길어지기 때문이다.
@ColumnDefault("'user'")
해당 변수를 컬럼으로 만드는데, default 값을 'user'로 지정.
이 때에 큰따옴표 안에 문자열을 작은 따옴표로 감싸야 DB에서 문자열로 잘 인식한다.
@CreationTimestamp
해당 컬럼의 기본값을 해당 데이터가 생성된 시각으로 지정.
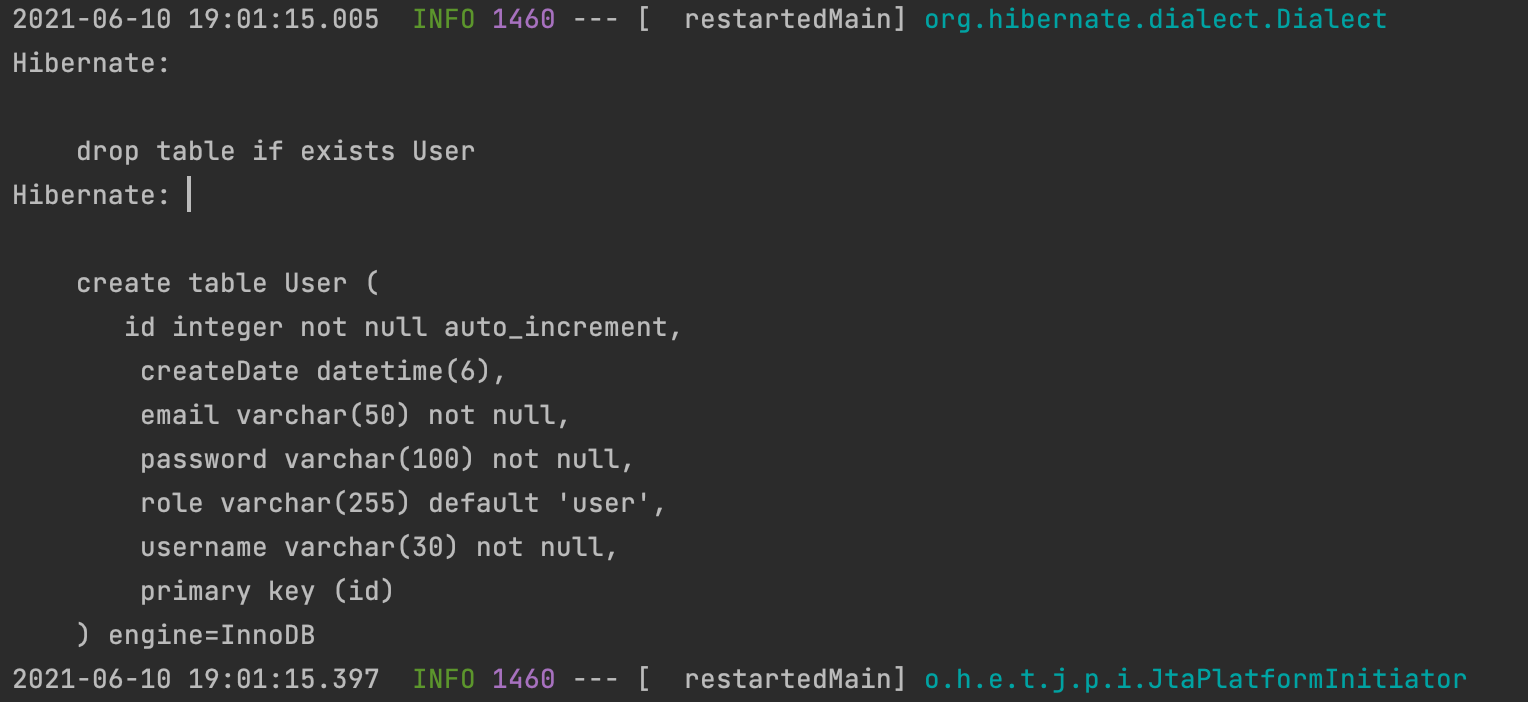
이제 프로젝트를 실행시키면 콘솔창 중간에 위 사진과 같이 SQL문이 나온다. 이는 실행한 SQL문을 보여주는 것이고, 설정을 통해 안보이게 할 수도 있다.
JPA 설정
application.yml에 보면 jpa 관련 코드들을 이전에 넣은 적이 있다.
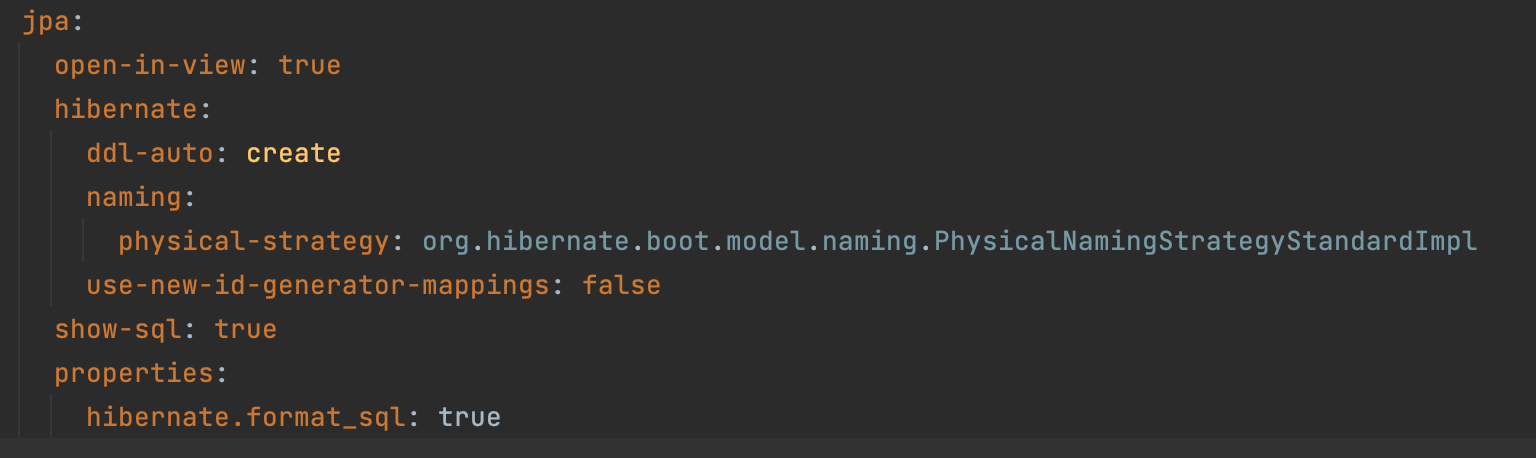
hibernate - ddl-auto
실행된 SQL문을 보면 테이블을 만들기 전에 drop table if exists User 명령어를 통해 미리 존재하던 테이블을 제거한다. 그러한 이유는 jpa 설정 중 hibernate - ddl-auto 설정이 create로 되어있기 때문이다.
ddl-auto에 넣을 수 있는 설정값은 3가지가 있다.
- create: 서버 시작 시 마다 DB 초기화
- update: 수정사항만 DB에 반영
- none: DB에 아무런 반영을 하지 않음
hibernate - naming - pysical-strategy
이 설정은 컬럼명 네이밍 전략이다. 대표적으로 두가지의 값을 넣을 수 있다.
org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
-> entity를 만들 때 DB 필드명을 클래스 안의 변수명 그대로 사용한다는 뜻.org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy
-> 변수명을 snake case로 변경하여 컬럼명으로 사용한다.
ex) myEmail -> my_email
우리는 PhysicalNamingStrategyStandardImpl를 사용한다.
hibernate - use-new-id-generator-mapping
데이터를 생성할 때 식별자(id)를 jpa의 기본 전략을 사용할 것인지에 대한 설정이다.
false로 하게 되면 jpa의 기본 전략을 사용하지 않는다. 따라서 클래스의 Id에 설정된 전략을 따른다.
show-sql
실행시켰을 때 콘솔창에 실행된 sql문을 보여줄 지에 대한 설정이다.
값을 false로 하거나 설정을 지우면 보이지 않게 된다.
hibernate.format_sql
콘솔창에 적히는 sql문을 정렬하여 보여줄 지에 대한 설정이다.
이 설정이 없으면 sql문은 한 줄로 출력된다. 이 설정이 있어요 보기 편하게 출력된다.
테이블 확인
프로젝트를 실행한 후에 테이블이 잘 만들었는지 확인해 본다.
use blog;
desc User;위 명령어를 database client에서 실행시켜본다.
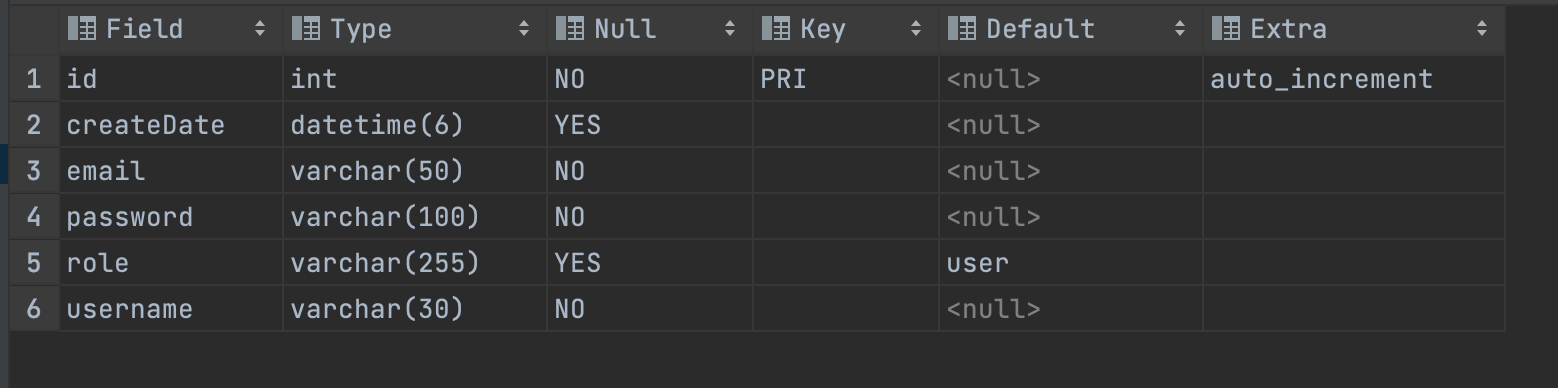
잘 만들어 졌다면 위처럼 나올 것이다. 그리고 table의 character set이 utf8인지도 확인해 보아야 한다.
SELECT default_character_set_name, DEFAULT_COLLATION_NAME
FROM information_schema.SCHEMATA
WHERE SCHEMA_NAME = "blog";
위 사진과 같이 utf8로 나오면 된다.
Board
Board.java
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Entity
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
@Column(nullable = false, length = 100)
private String title;
@Lob
private String content;
@ColumnDefault("0")
private int count;
@ManyToOne
@JoinColumn(name = "userId")
private User user;
@CreationTimestamp
private Timestamp createDate;
}Board.java에 위처럼 입력한다.
@Lob
대용량 데이터를 처리하기 위한 어노테이션.
content는 썸머노트 라이브러리를 사용할 것인데, 이 라이브러리를 사용하면 <HTML> 태그이 적용되어 디자인되기 때문에 데이터의 양이 크다. 따라서 @Lob 사용.
@ColumnDefault("0")
User 테이블을 생성할 때와 같은데, 이 컬럼에서는 default 값이 int이므로 큰 따옴표 안에 작은 따옴표가 필요 없다.
ORM에서는 컬럼 타입으로 외래키가 아닌 오브젝트도 사용 가능하다.
user를 보면 타입이 오브젝트 타입이다. 기존 DB의 경우, 오브젝트를 저장할 수 없어 외래키(FK)를 사용했다. 하지만 Java의 경우에는 오브젝트를 저장할 수 있기에 오브젝트를 변수로 사용한다.
이는 코드를 짤 때 오브젝트텍스트로 넣지만 실행 될 때 외래키를 자동으로 등록해준다.
@ManyToOne
다른 테이블을 참조할 때 다대일 관계를 형성시켜준다. 다(Many)가 현재 테이블이고 일(One)이 상대 테이블이다.
@JoinColumn(name = "userId")
외래키를 매핑할 때 사용한다. name 속성은 매핑 할 외래키 이름을 지정한다.
위 코드에서는 User 엔티티의 id 필드를 외래키로 가지고, Board 엔티티의 userId라는 필드에 매핑된다.
실제 데이터베이스에서는 userId는 int형으로 정의된다. User 엔티티의 PK인 id가 int형이기 때문이다.
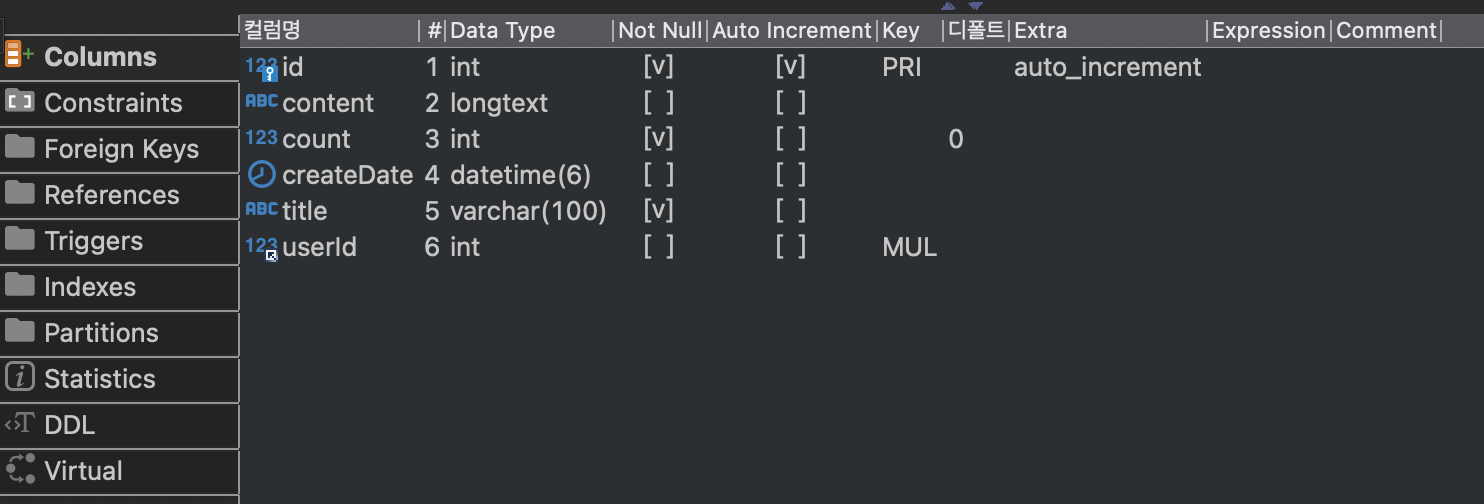
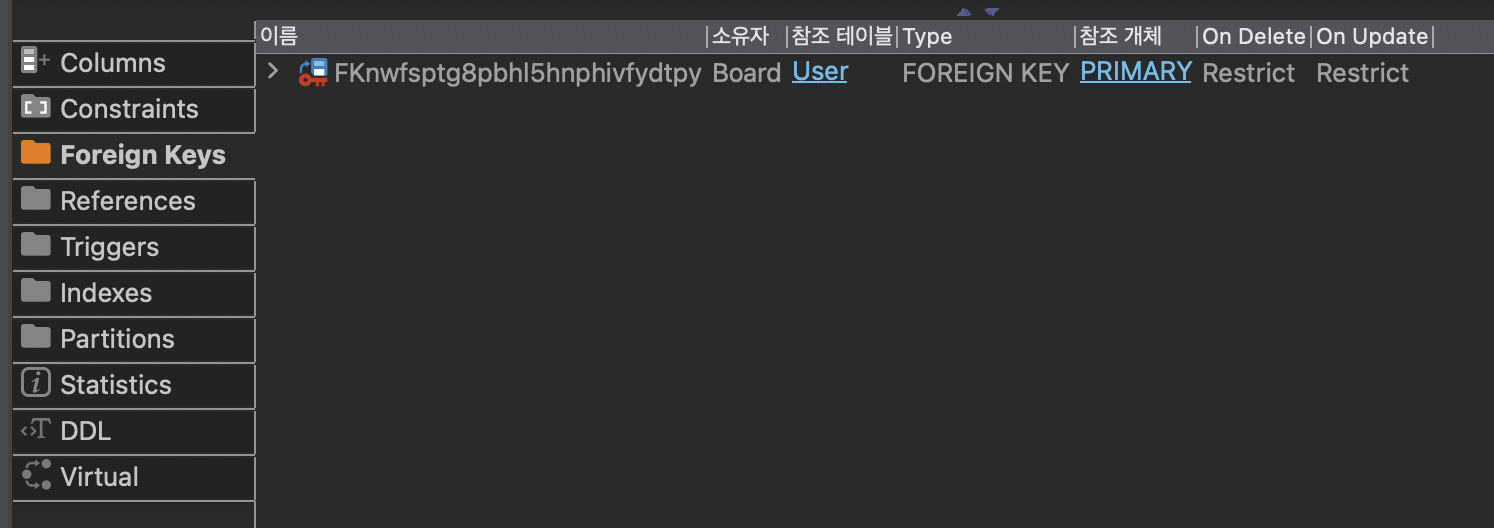
프로젝트를 실행한 후에 db client를 통해 위와 같이 테이블이 잘 생성된 것을 확인할 수 있다.
Reply
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Data
@Entity
public class Reply {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
@Column(nullable = false, length = 200)
private String content;
@ManyToOne
@JoinColumn(name="boardId")
private Board board;
@ManyToOne
@JoinColumn(name = "userId")
private User user;
@CreationTimestamp
private Timestamp createDate;
}Reply.java 파일에 위 코드를 입력한다.
그리고 실행하면
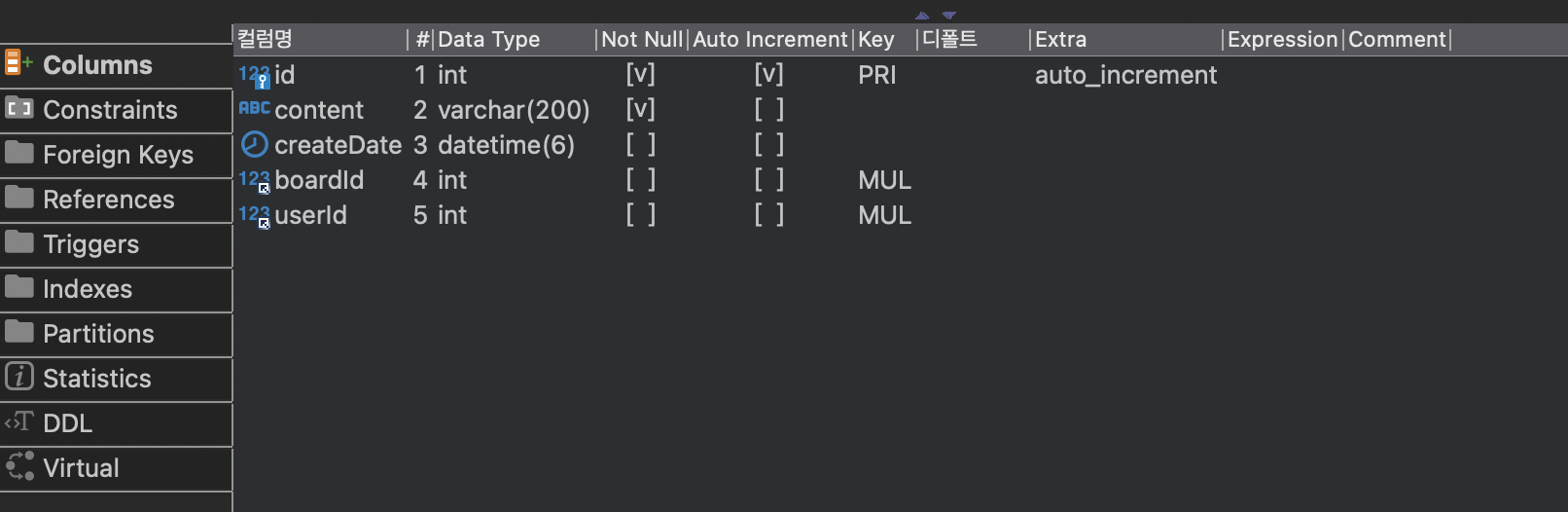
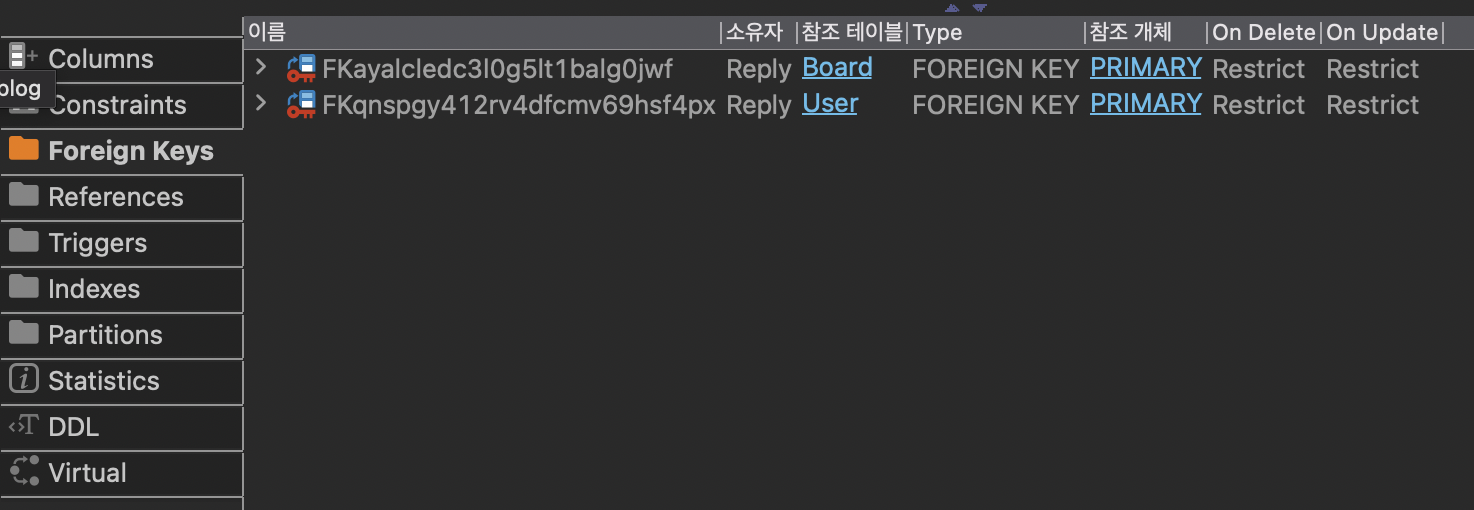
이와 같이 테이블이 만들어지고 외래키도 2개가 모두 잘 생성된 것을 확인할 수 있다.
연관관계의 주인
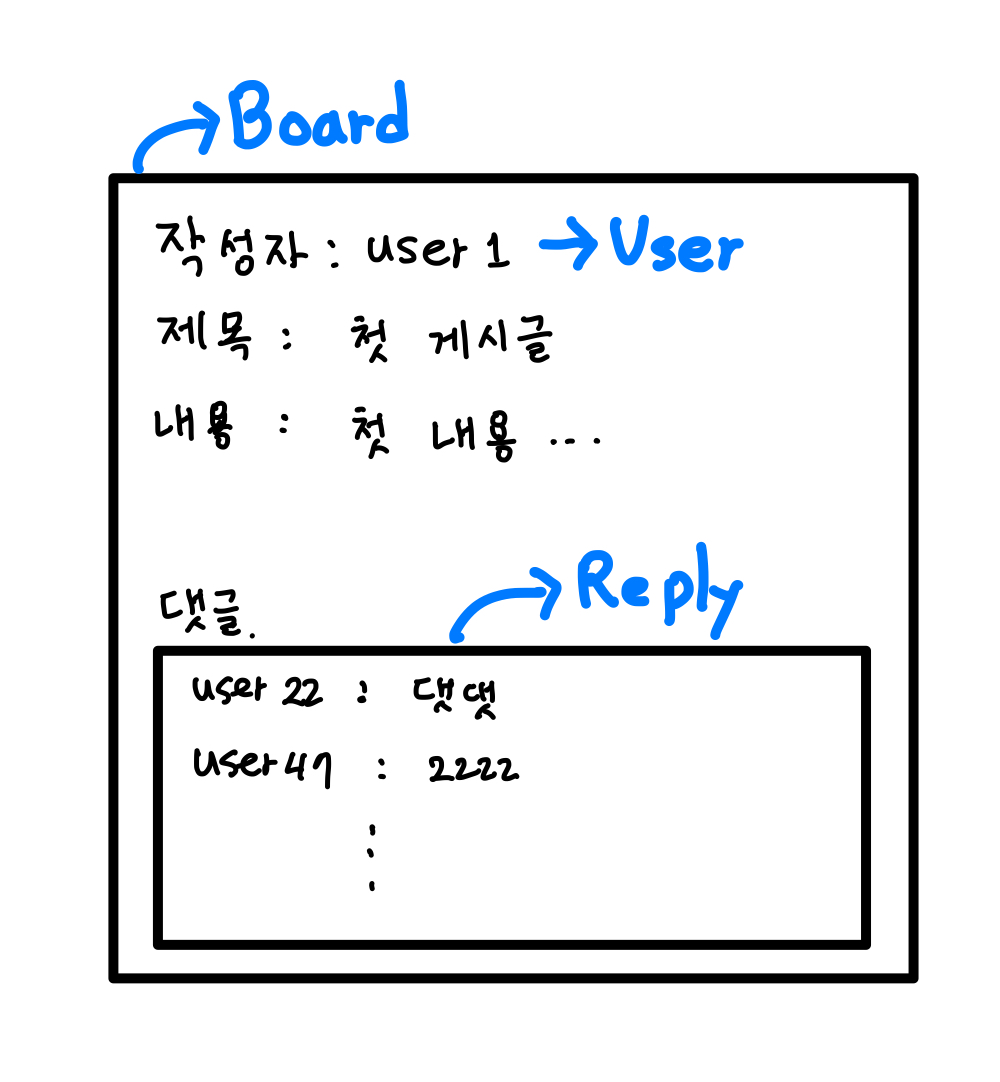
웹사이트에서 게시물을 조회할 때 볼 수 있는 화면은 주로 위와 같습니다. 게시물이 있으면 그 안에 작성자가 있고, 하단에 댓글이 있다.
해당 화면에서 필요한 데이터는 크게 Borad, User, Reply 데이터가 있다.
게시물 데이터를 조회하기 위해 Board를 select 하게 되면, 외래키로 묶여있는 작성자 정보(User)를 같이 조회할 수 있다. 그리고 Reply는 별도로 select를 해야 한다.
이러한 방법은 조회를 2번 해야 하기에 번거롭기도 하고 데이터를 두번 주고받아야 하기에 비효율적이다. 따라서 한번에 모두 조회할 수 있도록 코드를 바꾸려 한다.
@OneToMany(mappedBy = "board", fetch = FetchType.EAGER)
private List<Reply> reply;위 코드를 Board 클래스 안에 추가한다.
@OneToMany(mappedBy = "board", fetch = FetchType.EAGER)
하나의 게시물 안에는 여러개의 댓글이 존재할 수 있다. 따라서 One To Many의 관계이다. 그리고 mappedBy 속성을 사용하면, 해당 변수은 '연관관계의 주인이 아니다.' 즉, 외래키가 아니라는 뜻이다. 따라서 DB에 컬럼을 만들지 않는다. 그리고 해당 속성을 통해 연관관계의 주인을 표시한다. 표시는 해당 테이블이 참조되는 필드명을 적는다. 위에서의 "board"는 Reply 테이블의 board 필드이다.
@OneToMany어노테이션의 기본 fetch 전략은 LAZY이고, @ManyToOne 어노테이션의 기본 fetch 전략은 EAGER이다.
FetchType: LAZY(지연로딩) vs EAGER(즉시로딩)
EAGER은 엔티티를 조회할 때 연관된 엔티티도 함께 조회하는 것이다.
LAZY는 엔티티를 조회 할 때 연관된 엔티티도 함께 가져오는 것이 아닌, 연관된 엔티티의 데이터를 실제로 사용해야 할 때 조회한다.
fetch Type을 EAGER로 설정하여 board를 조회할 때에 reply도 함께 조회된다.
List<Reply>
여러개의 데이터를 한번에 받아야 하기 때문에 List 데이터타입을 사용한다.
@JoinColumn
해당 변수는 DB에 컬럼을 생성하지 않기 때문에 다른 변수들과 달리 @JoinColumn 어노테이션이 불필요하다.
위의 방법들을 통해서 Board를 조회할 때에 해당 데이터에 관련된 User, Reply 정보가 Join으로 한번에 조회하는 SQL을 보낸다. 프로젝트를 다시 실행시키면 오류없이 정상적으로 작동되며 Board 테이블에 reply 필드이 생기지 않고 외래키도 더 생성되지 않은 것을 확인할 수 있다.
연관관계의 종류
- @OneToMany (일:다)
- @OneToOne (일:일)
- @ManyToOne (다:일)
- @ManyToMany (다:다)
데이터베이스 클라이언트를 Sequal Pro를 사용중이었는데 자잘한 버그들이 원래 계속 있었는데 이번에 접속이 안되는... 그런 문제가 있었다. 접속 후 database 선택을 하면 무한로딩이 걸리는... mysql 초기화 해도 동일하고 그래서 데이터베이스 클라이언트를 바꿨다. 이번에 datagrip이랑 dbeaver 둘 다 써봤는데, dbeaver가 조금 더 편한 듯 해서 이제 계속 dbeaver 사용할듯..
