
1. 지도 학습과 비지도 학습?
지도학습과 비지도 학습의 차이
- 지도 학습과 비지도 학습을 구분하는 기준은, 훈련 데이터가 Label(정답)을 가지고 있는지 없는지이다.
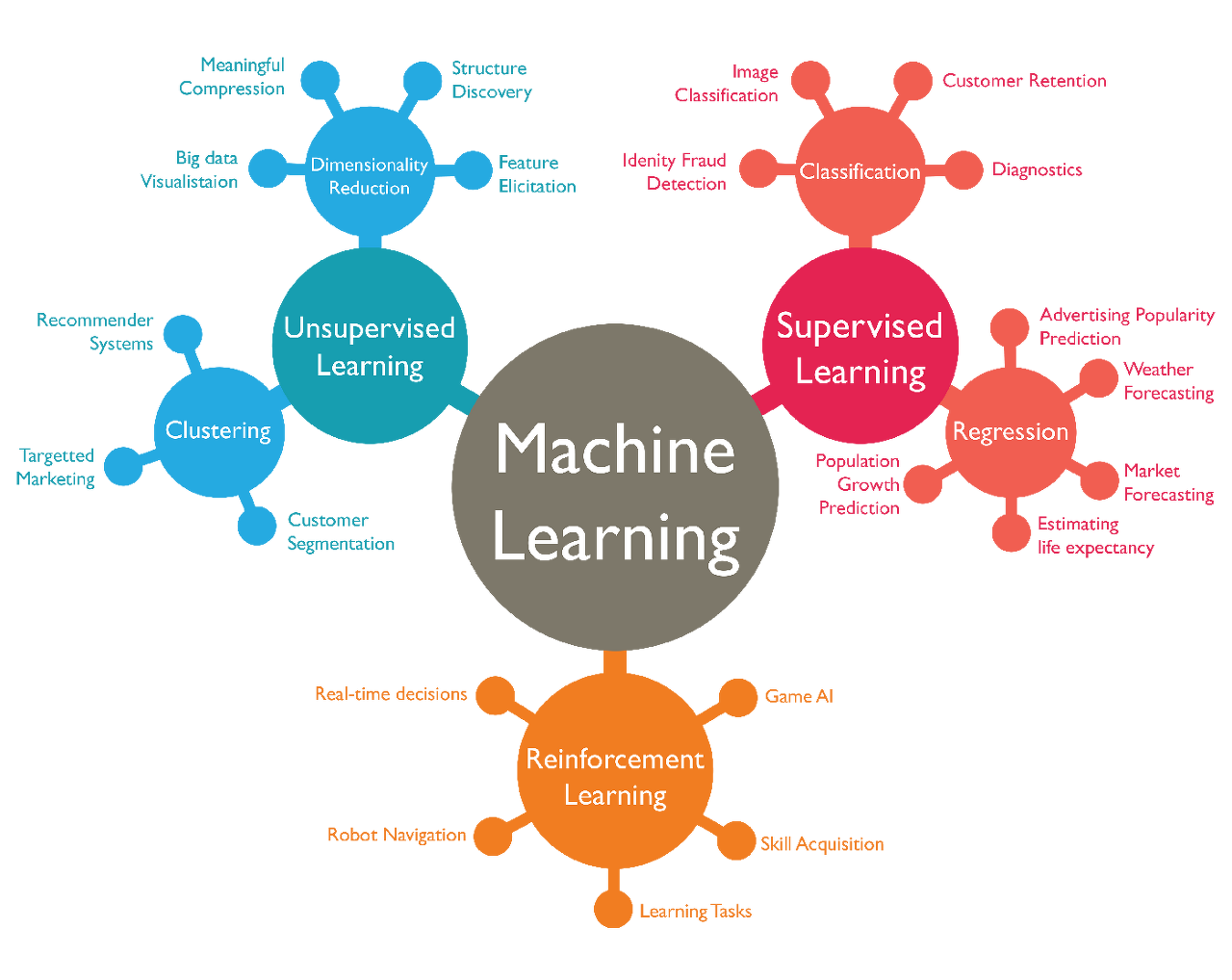
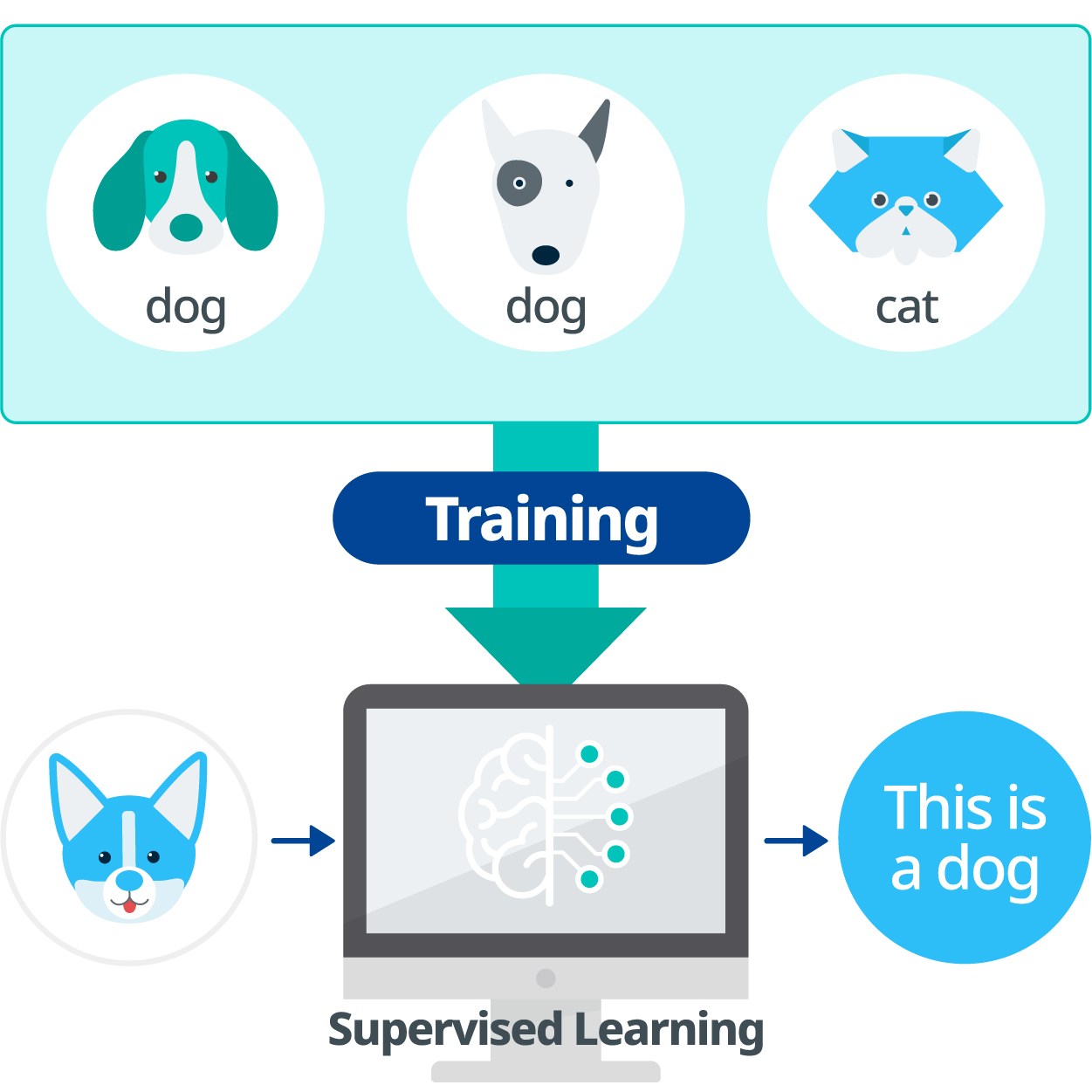
2. 지도 학습
-> 정답 레이블이 있는 데이터를 가지고 인공지능을 학습 시킴
- 지도 학습에는 분류와 회귀분석, 2가지 종류가 있다.
< 분류 >
- Classification은 Binary, Multi-Class, Multi-Label Classification으로 나뉜다.
대표적인 분류 알고리즘
- SVM, Decision Tree, KNN(K-nearest neighbor), Random Forest, Naive Bayes
< 회귀 >
- Regression은 Linear와 Non-Linear Regression으로 나뉜다.
대표적인 회귀 알고리즘
- Linear Regression, Polynomial Regression
!! 주의 !!
Logistic Regression과 Softmax Regression는
이름은 Regression이지만 실제로 하는 일은 Classification이다.
3. 비지도 학습
-> 정답 레이블이 없는 데이터를 가지고 인공지능을 학습 시킴
- 지도 학습에는 군집화와 차원 축소, 2가지 종류가 있다.
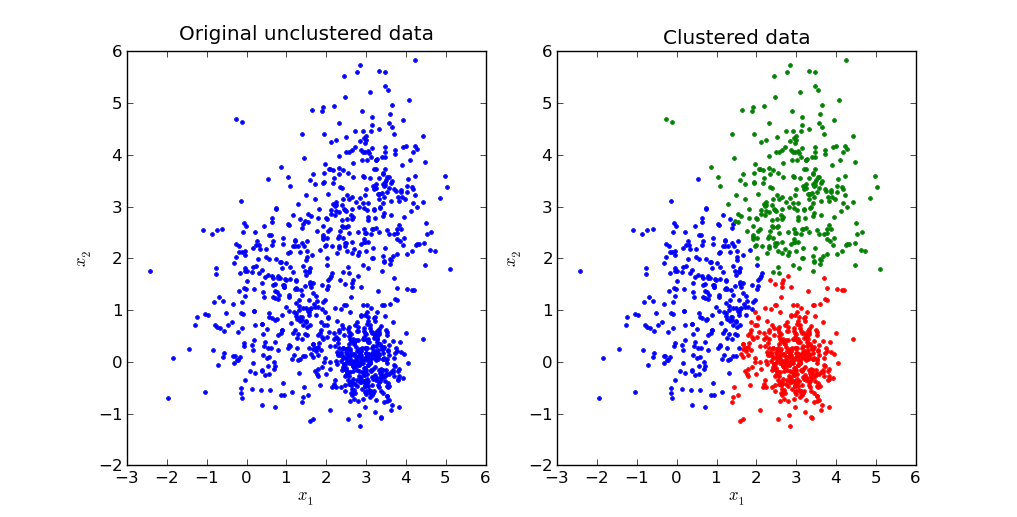
< 군집화 (Clustering) >
- 정답데이터가 없어, 차원을 바꿔가며 데이터끼리의 상관관계를 이용해 군집을 잡는다.
대표적인 군집화 알고리즘
- K-means Clustering, DBSCAN, Mean-Shift Clustering
< 차원 축소 >
- 고차원의 데이터로부터 특징을 추출하기 어렵기 때문에, 단순히 데이터를 압축하는 것이 아닌 데이터를 더 잘 설명할 수 있는 잠재적인 요소를 추출
대표적인 차원 축소 알고리즘
- PCA, LDA
4. 강화 학습
-> 학습 데이터라는 것이 아닌, 강화학습의 5가지 구성 요소를 통해 모델 에이전트를 학습해나간다.

강화학습 기초 개념
- 아기가 걸음마를 때는 장면을 생각하면 이해하기 쉽다. 아기는 두 다리로만 중심을 잡을 수 없어 기어다닌다. 하지만 수차례의 넘어짐을 통해 중심 잡는 법을 터득하고, 결국에는 두 다리로만 중심을 잡고 서있는 법을 터득한다.
강화학습 필수 요소
1. Agent
- 학습을 하는 주체 (Model)
2. Enviroment
- Agent를 학습시킬 환경
3. Action
- Agent가 Enviroment에서 내리는 행동
4. State
- Agent가 Enviroment에서 Action을 내렸을 떄 발생하는 하나의 장면
5. Reward
- Agent가 Enviroment에서 Action을 내렸을 떄 발생하는 하나의 장면으로부터 나오는 기댓값 (보상과 벌점)
대표적인 강화학습 알고리즘
- Q-Learning, DQN, Actor-Critic, A2C, A3C
강화학습은 Agent가 Enviroment에서 Action을 내리는데, 그때 생성되는 State로 부터 발생되는 Reward를 (보상을) Maximize하는 형태로 Agent를 학습한다.

HanYang ERICA Univ. Department of Artificial Intelligence