Deeplearning_Detection

Object detection은 물체의 클래스를 분류(classification)할 뿐만 아니라 위치 측정 (localization)까지 함께 수행하는 작업입니다.
Localization이란 이미지 내에 하나의 물체(Object)가 있을 때 그 물체의 위치를 특정하는 것인데, Detection이라 함은 다수의 물체(Object)가 존재할 때 각 Object의 존재 여부를 파악하고 위치를 특정하며 클래스 분류(Classification)까지 수행하는 것이지요.
기본적으로 물체 한 개의 위치를 찾아낼 수 있다면 반복 과정을 통해 여러 물체를 찾아낼 수 있겠죠?
그러니 먼저 localization부터 파헤쳐 보도록 하겠습니다.
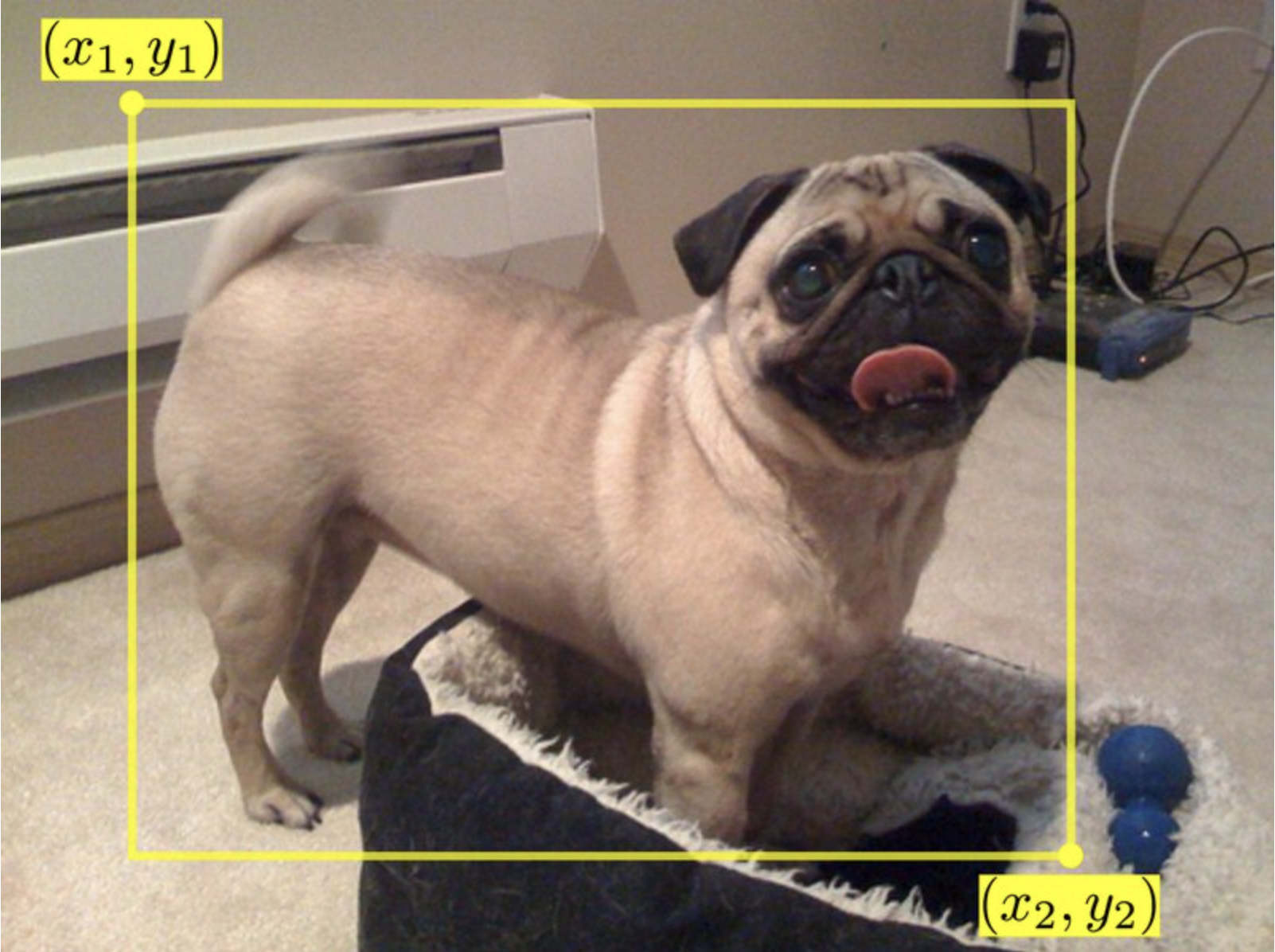
바운딩 박스(Bounding box)는 이미지 내에서 물체의 위치를 사각형으로 감싼 형태의 도형으로 정의하고 이를 꼭짓점의 좌표로 표현하는 방식입니다.
이때 2개의 점을 표현하는 방식은 두 가지가 있습니다.
첫 번째로 전체 이미지의 좌측 상단을 원점으로 정의하고 바운딩 박스의 좌상단 좌표와 우하단 좌표 두 가지 좌표로 표현하는 방식이 있습니다.
두 번째는 이미지 내의 절대 좌표로 정의하지 않고 바운딩 박스의 폭과 높이로 정의하는 방식입니다.
이 경우 좌측 상단의 점에 대한 상대적인 위치로 물체의 위치를 정의할 수 있습니다.
이번에는 직접 이미지에 박스를 그려보는 시간을 갖도록 하겠습니다.
from PIL import Image, ImageDraw
import os
img_path=os.getenv('HOME')+'/aiffel/object_detection/images/person.jpg'
img = Image.open(img_path)
draw = ImageDraw.Draw(img)
draw.rectangle((130, 30, 670, 450), outline=(0,255,0), width=2)
img
3) Intersection over Union(IOU)
면적의 절대적인 값에 영향을 받지 않도록 두 개 박스의 차이를 상대적으로 평가하기 위한 방법 중 하나가 IoU(Intersection over Union) 입니다.
import tensorflow as tf
from tensorflow import keras
output_num = 1+4+3 # object_prob 1, bbox coord 4, class_prob 3
input_tensor = keras.layers.Input(shape=(224, 224, 3), name='image')
base_model = keras.applications.resnet.ResNet50(
input_tensor=input_tensor,
include_top=False,
weights='imagenet',
pooling=None,
)
x = base_model.output
preds = keras.layers.Conv2D(output_num, 1, 1)(x)
localize_model=keras.Model(inputs=base_model.input, outputs=preds)
localize_model.summary()
앵커 박스(Anchor box)

이제 확인했던 Detection 모델로 위의 그림을 인식한다고 가정해 봅시다.
한 가지 문제가 생겼습니다. 차 사이에 사람이 있습니다.
우리는 한 칸에 한 가지 물체를 감지하기 때문에 만약 모두 차를 잡게 된다면 사람을 놓칠 수밖에 없습니다.
앵커 박스(anchor box)는 서로 다른 형태의 물체와 겹친 경우에 대응할 수 있습니다.
일반적으로 차는 좌우로 넓고 사람은 위아래로 길쭉합니다. 따라서 사람의 형태와 유사한 형태와 차와 유사한 형태의 가상의 박스 두 개를 정의합니다.
기존에 위에서 본 모델의 구조에서 두 개의 클래스로 확장해 봅시다.
차와 사람 클래스에 대해서 물체를 감지하기 위해서는 한 개의 그리드 셀에 대한 결괏값 벡터가 물체가 있을 확률, 2개의 클래스, 그리고 바운딩 박스 4개로 총 7개의 차원을 가지게 될 것입니다.
따라서 입력값이 16x16 일 때, 이 그림을 2x2로 총 4칸의 그리드로 나누었다고 하면, 결괏값의 형태는 7개의 채널을 가져 2x2x7이 됩니다.
이때 7개의 차원을 한 벌 더 늘려주어 한 개의 물체의 수를 늘려줍니다. 앵커 박스가 두 개가 된다면 결괏값의 형태는 2x2x14가 됩니다.
바운딩 박스와 앵커 박스라는 두 가지 개념이 혼동이 되시지 않나요?
바운딩 박스 : 네트워크가 predict한 object의 위치가 표현된 박스로서, 네트워크의 출력이다.
앵커 박스 : 네트워크가 detect해야 할 object의 shape에 대한 가정(assumption)으로서, 네트워크의 입력이다.
4) NMS(Non-Max Suppression)
우리가 2x2 또는 더 큰 Grid cell에서 물체가 있는지에 대한 결과를 받게 되면 매우 많은 물체를 받게 됩니다.
Anchor box를 사용하지 않더라도 2x2격자에 모두 걸친 물체가 있는 경우 하나의 물체에 대해 4개의 Bounding box를 얻게 되죠.
이렇게 겹친 여러 개의 박스를 하나로 줄여줄 수 있는 방법 중 하나가 NMS(non-max suppression) 입니다.
NMS는 겹친 박스들이 있을 경우 가장 확률이 높은 박스를 기준으로 기준이 되는 IoU 이상인 것들을 없앱니다.
이때 IoU를 기준으로 없애는 이유는 어느 정도 겹치더라도 다른 물체가 있는 경우가 있을 수 있기 때문입니다.
이때 Non-max suppression은 같은 class인 물체를 대상으로 적용하게 됩니다.
5) 정리
Convolutional implementation of Sliding Windows
Anchor box
Non-max suppression(NMS)
지금까지 위의 세 가지 개념과 CNN을 활용한 물체 검출(Object detection) 방법을 배워보았습니다.
Convolution으로 슬라이딩 윈도우를 대신함으로써 여러 window에서 Object localization을 병렬로 수행할 수 있게 되어 속도 측면의 개선이 있었습니다.
Anchor box는 겹친 물체가 있을 때, IoU를 기준으로 서로 다른 Anchor에 할당하도록 하여 생긴 영역이 다른 물체가 겹쳤을 때도 물체를 검출할 수 있도록 할 수 있게 되었습니다.
마지막으로 Non-max suppression은 딥러닝 모델에서 나온 Object detection 결과들 중 겹친 결과들을 하나로 줄이면서 더 나은 결과를 얻을 수 있게 했습니다.
이제는 위 3가지를 토대로 접근한 다양한 검출 모델을 확인해 보도록 하겠습니다.
앞에서 봐왔던 바운딩 박스 regression과 앵커 박스, 그리고 NMS를 이용하면 어느 정도 동작하는 Detection 모델을 만들 수 있습니다.
그렇다면 이보다 더 나아간 방법들은 어떤 것들이 있을까요?
Detection task는 많은 분야에서 필요하듯이 연구도 활발하게 진행되고 있습니다.
활발한 연구만큼 다양한 방법들이 있는데요.
딥러닝 기반의 Object Detection 모델은 크게 Single stage detector와 Two stage detector로 구분할 수 있습니다. 아래에서 그 예시를 볼 수 있습니다.
Many stage라고 적혀있는 방법에서는 물체가 있을 법한 위치의 후보(proposals) 들을 뽑아내는 단계, 이후 실제로 물체가 있는지를 Classification과 정확한 바운딩 박스를 구하는 Regression을 수행하는 단계가 분리되어 있습니다. 대표적으로는 Faster-RCNN을 예로 들 수 있습니다.
One stage Detector는 객체의 검출과 분류, 그리고 바운딩 박스 regression을 한 번에 하는 방법입니다.
