regulariztion OR normalization

Regularization : 정칙화
오버피팅을 해결하기 위한 방법 중의 하나입니다.
오늘 우리가 가장 중요하게 다룰 주제이기도 하죠.
L1, L2 Regularization, Dropout, Batch normalization 등이 있습니다.
이 방법들은 모두 오버피팅을 해결하고자 하는 방법 중에 하나입니다. 오버피팅은 한국어로 과적합이라고 하며, train set은 매우 잘 맞추지만, validation/test set은 맞추지 못하는 현상을 말합니다.
비유하자면 오버피팅은 기출문제는 외워서 잘 맞추지만 새로운 응용 문제로 시험을 볼 때는 잘 풀지 못하는 경우라고 할 수 있겠습니다. 더 좋은 결과를 얻기 위해서는 새로운 시험 즉, test set 에서도 잘 맞춰야겠죠? 그래서 사용하는 Regularization 기법들은 모델이 train set의 정답을 맞추지 못하도록 오버피팅을 방해(train loss가 증가) 하는 역할을 합니다. 그래서 train loss는 약간 증가하지만 결과적으로, validation loss나 최종적인 test loss를 감소시키려는 목적을 가지고 있지요.
Normalization : 정규화
이는 데이터의 형태를 좀 더 의미 있게, 혹은 트레이닝에 적합하게 전처리하는 과정입니다.
데이터를 z-score로 바꾸거나 minmax scaler를 사용하여 0과 1사이의 값으로 분포를 조정하는 것들이 해당됩니다. 예를 들어, 금액과 같은 큰 범위의 값(10,000 ~ 10,000,000)과 시간(0~24) 의 값이 들어가는 경우, 학습 초반에는 데이터 거리 간의 측정이 피처 값의 범위 분포 특성에 의해 왜곡되어 학습에 방해를 받게 되는 문제가 있습니다. Normalization은 이를 모든 피처의 범위 분포를 동일하게 하여 모델이 풀어야 하는 문제를 좀 더 간단하게 바꾸어 주는 전처리 과정입니다.
핵심을 정리하면, Regularization은 오버피팅을 막고자 하는 방법, Normalization은 트레이닝을 할 때에 서로 범위가 다른 데이터들을 같은 범위로 바꿔주는 전처리 과정이라는 것입니다.
iris data로 예를 들어 보겠습니다.
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
target_df = pd.DataFrame(data=iris.target, columns=['species'])
# 0, 1, 2로 되어있는 target 데이터를
# 알아보기 쉽게 'setosa', 'versicolor', 'virginica'로 바꿉니다
def converter(species):
if species == 0:
return 'setosa'
elif species == 1:
return 'versicolor'
else:
return 'virginica'
target_df['species'] = target_df['species'].apply(converter)
iris_df = pd.concat([iris_df, target_df], axis=1)
iris_df.head()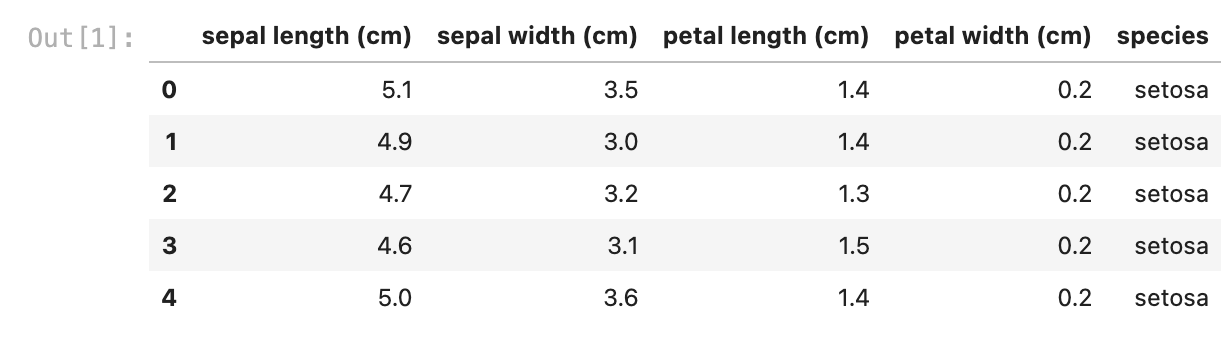
Iris data 중 virginica라는 종의 petal length(꽃잎 길이)를 X, sepal length(꽃받침의 길이)를 Y로 두고 print 해보겠습니다.
X = [iris_df['petal length (cm)'][a] for a in iris_df.index if iris_df['species'][a]=='virginica']
Y = [iris_df['sepal length (cm)'][a] for a in iris_df.index if iris_df['species'][a]=='virginica']
print(X)
print(Y)
값으로만 보니 직관적으로 잘 와닿지 않네요! 산점도로 그려봅시다.
아직 Normalization을 하지 않았기 때문에 x축과 y축은 각각의 최솟값과 최댓값의 범위로 그려집니다.
plt.figure(figsize=(5,5))
plt.scatter(X,Y)
plt.title('petal-sepal scatter before normalization')
plt.xlabel('petal length (cm)')
plt.ylabel('sepal length (cm)')
plt.grid()
plt.show()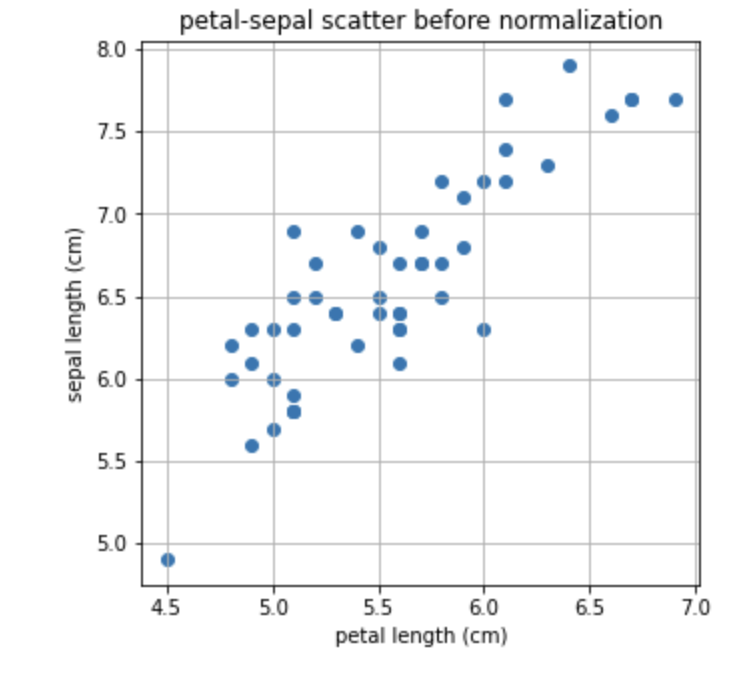
이제 0-1로 normlization을 해주는 minmax_scale를 이용해서 산점도를 다시 한번 그려보겠습니다.
from sklearn.preprocessing import minmax_scale
X_scale = minmax_scale(X)
Y_scale = minmax_scale(Y)
plt.figure(figsize=(5,5))
plt.scatter(X_scale,Y_scale)
plt.title('petal-sepal scatter after normalization')
plt.xlabel('petal length (cm)')
plt.ylabel('sepal length (cm)')
plt.grid()
plt.show()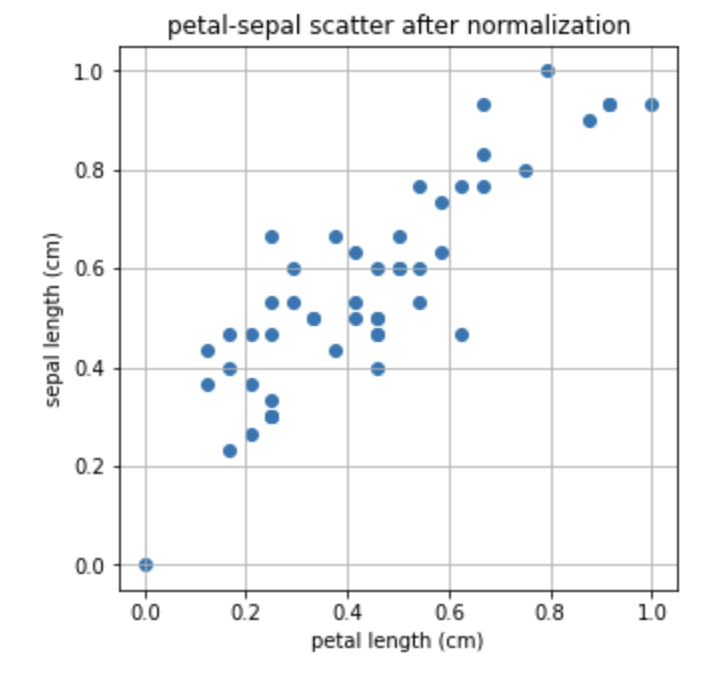
결과를 비교해보면, 가장 큰 값을 1, 가장 작은 값을 0으로 하여 축 범위가 바뀜을 확인할 수 있습니다.
데이터의 상대적인 분포는 바뀌지 않았지만, feature의 스케일이 0과 1 사이로 변환되었으므로 이후 X, Y 의 관계를 다루기 용이 해졌습니다.
sklearn.linear_model에는 L1, L2 Regression 인 Lasso와 Ridge모델도 함께 포함되어 있으므로, 이들의 차이점을 먼저 직관적으로 이해해 보겠습니다.
수학적 정의나 보다 구체적인 설명은 다음 스텝에 이어집니다.
from sklearn.linear_model import LinearRegression
import numpy as np
X = np.array(X)
Y = np.array(Y)
# Iris Dataset을 Linear Regression으로 학습합니다.
linear= LinearRegression()
linear.fit(X.reshape(-1,1), Y)
# Linear Regression의 기울기와 절편을 확인합니다.
a, b=linear.coef_, linear.intercept_
print("기울기 : %0.2f, 절편 : %0.2f" %(a,b))output = 기울기 : 1.00, 절편 : 1.06
위에서 Linear regression 으로 구한 기울기와 절편을 가지고 일차함수를 만들어 산점도와 함께 그려보겠습니다.
plt.figure(figsize=(5,5))
plt.scatter(X,Y)
plt.plot(X,linear.predict(X.reshape(-1,1)),'-b')
plt.title('petal-sepal scatter with linear regression')
plt.xlabel('petal length (cm)')
plt.ylabel('sepal length (cm)')
plt.grid()
plt.show()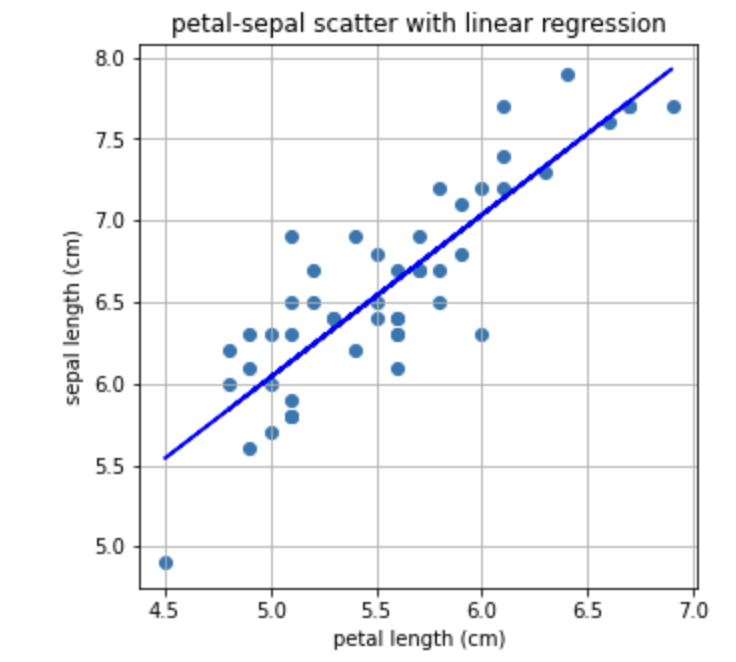
이번에는 L1, L2 Regularization으로 Regression을 해보겠습니다. 이는 Lasso, Ridge라고 부릅니다.
먼저 L1 regularization인 Lasso로 문제를 풀어보겠습니다.
#L1 regularization은 Lasso로 import 합니다.
from sklearn.linear_model import Lasso
L1 = Lasso()
L1.fit(X.reshape(-1,1), Y)
a, b=L1.coef_, L1.intercept_
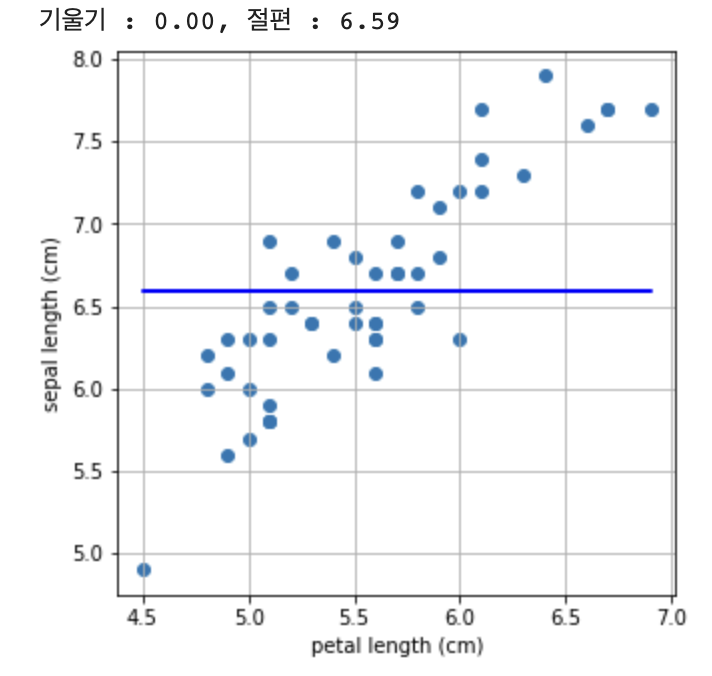
print("기울기 : %0.2f, 절편 : %0.2f" %(a,b))
plt.figure(figsize=(5,5))
plt.scatter(X,Y)
plt.plot(X,L1.predict(X.reshape(-1,1)),'-b')
plt.title('petal-sepal scatter with L1 regularization(Lasso)')
plt.xlabel('petal length (cm)')
plt.ylabel('sepal length (cm)')
plt.grid()
plt.show()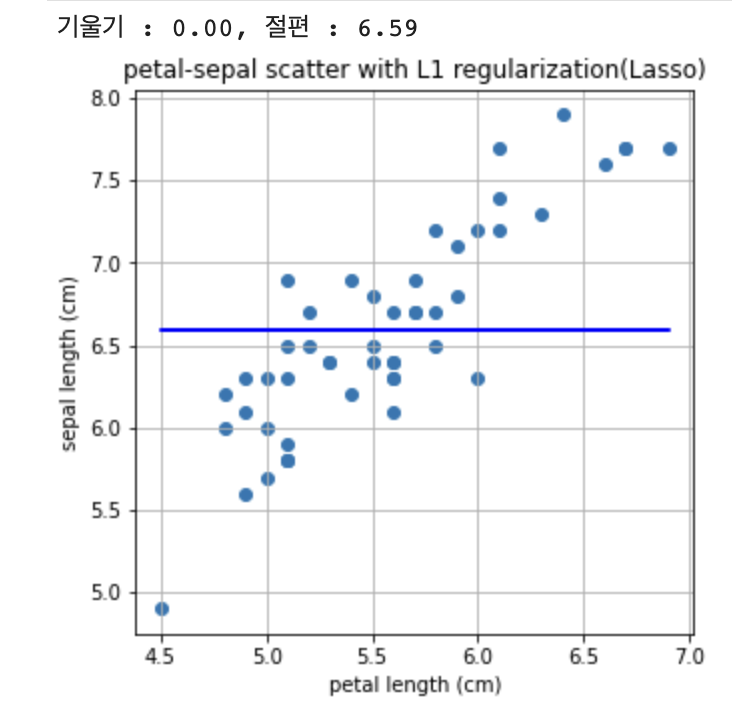
어떤가요? 혹시 기울기가 0으로 나오지 않았나요? Lasso 방법은 제대로 문제를 풀어내지 못하는 것 같습니다.
이제 같은 데이터셋으로 L2 regularization인 Ridge로 문제를 풀어보고 서로 비교해보겠습니다.
#L2 regularization은 Ridge로 import 합니다.
from sklearn.linear_model import Ridge
L2 = Ridge()
L2.fit(X.reshape(-1,1), Y)
a, b = L2.coef_, L2.intercept_
print("기울기 : %0.2f, 절편 : %0.2f" %(a,b))
plt.figure(figsize=(5,5))
plt.scatter(X,Y)
plt.plot(X,L2.predict(X.reshape(-1,1)),'-b')
plt.title('petal-sepal scatter with L2 regularization(Ridge)')
plt.xlabel('petal length (cm)')
plt.ylabel('sepal length (cm)')
plt.grid()
plt.show()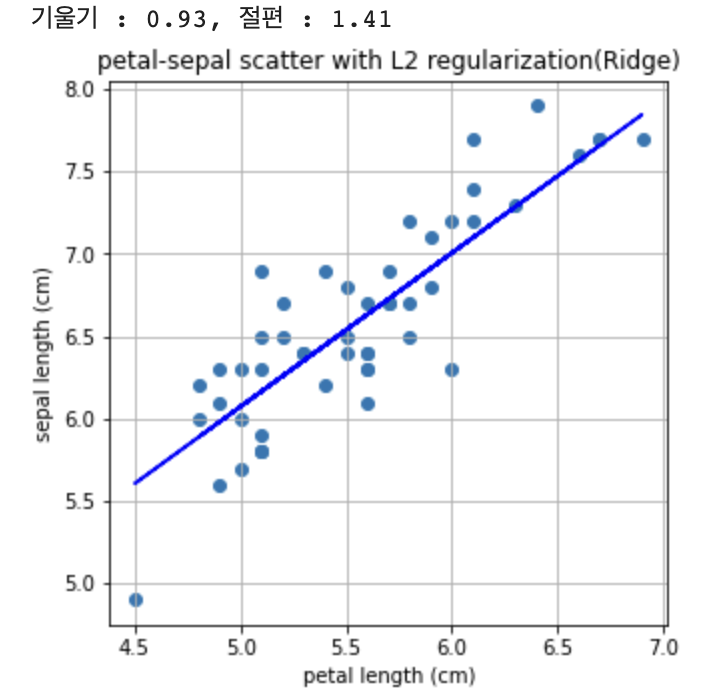
다시 다루겠지만, Linear Regression이 L2 Norm과 관련이 있습니다. 그래서 L2 Regularization을 쓰는 Ridge방법으로는 앞서 Linear Regression과 큰 차이가 없는 결과가 나옵니다.
그러나 왜 L1 Regularization을 쓰는 Lasso에서는 답이 나오지 않았을까요?
다음 스텝에서 그 이유를 알아보도록 하겠습니다!
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
target_df = pd.DataFrame(data=iris.target, columns=['species'])
def converter(species):
if species == 0:
return 'setosa'
elif species == 1:
return 'versicolor'
else:
return 'virginica'
target_df['species'] = target_df['species'].apply(converter)
iris_df = pd.concat([iris_df, target_df], axis=1)
iris_df.head()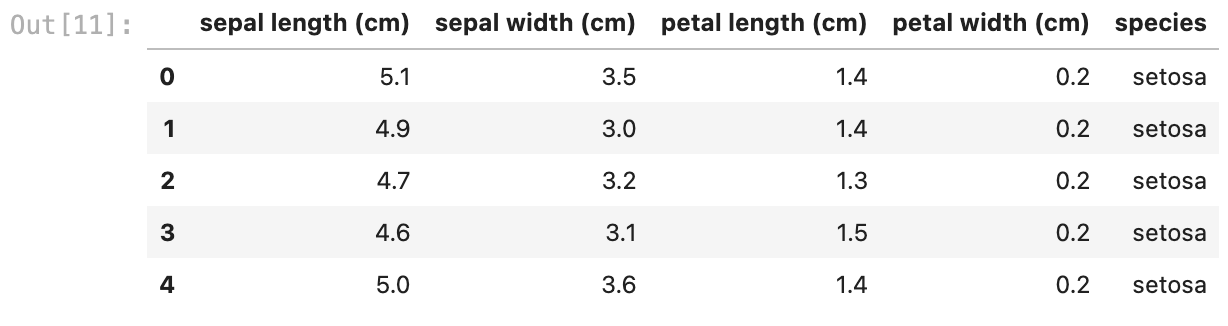
X = [iris_df['petal length (cm)'][a] for a in iris_df.index if iris_df['species'][a]=='virginica']
Y = [iris_df['sepal length (cm)'][a] for a in iris_df.index if iris_df['species'][a]=='virginica']
X = np.array(X)
Y = np.array(Y)
plt.figure(figsize=(5,5))
plt.scatter(X,Y)
plt.xlabel('petal length (cm)')
plt.ylabel('sepal length (cm)')
plt.grid()
plt.show()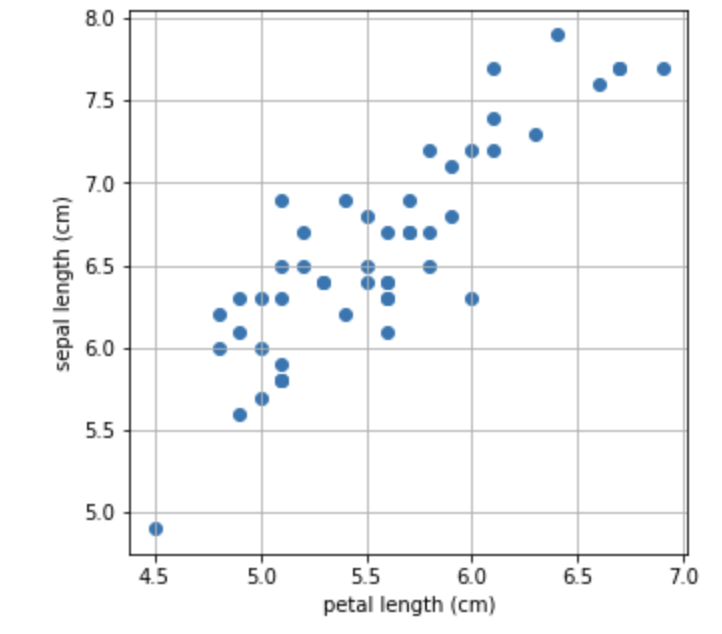
from sklearn.linear_model import Lasso
L1 = Lasso()
L1.fit(X.reshape(-1,1), Y)
a, b = L1.coef_, L1.intercept_
print("기울기 : %0.2f, 절편 : %0.2f" %(a,b))
plt.figure(figsize=(5,5))
plt.scatter(X,Y)
plt.plot(X,L1.predict(X.reshape(-1,1)),'-b')
plt.xlabel('petal length (cm)')
plt.ylabel('sepal length (cm)')
plt.grid()
plt.show()