
아래 글은 deep daiv. vol.2 자연어처리 편 <NLP 트렌드 맛보기>에서 발췌한 내용입니다.
1. ChatGPT 이전의 LLM 트렌드
최근 GPT-3.5와 같이 175B의 파라미터 개수를 가지는 매우 큰 언어모델이 등장함에 따라 자연어 처리 분야가 안고 있었던 문제들을 쉽게 해결할 수 있게 되었습니다. 다만 LLM이 일정 수준 이상으로 커지게 되자 전례 없던 현상들이 보고되기 시작했는데요. 마치 모델이 언어를 이해하는 것 같은 현상이 보이는 것입니다.
- In-Context Learning(ICL) : 원하는 작업 예시나 지시를 입력으로 주게 되면, Fine-tuning(미세조정) 없이도 작업을 수행한다거나,
- Chain-of-Thought Prompting(CoT) : 원래는 제대로 답하지 못하는 질문에 추론 과정을 글로 써주면 답을 제대로 내놓는 것과 같이
모델이 오랜 시간 파라미터를 통해 학습하자, 추가 학습 없이도 일정 수준의 언어 능력이 발현되는 등의 재미난 현상을 볼 수 있었습니다.
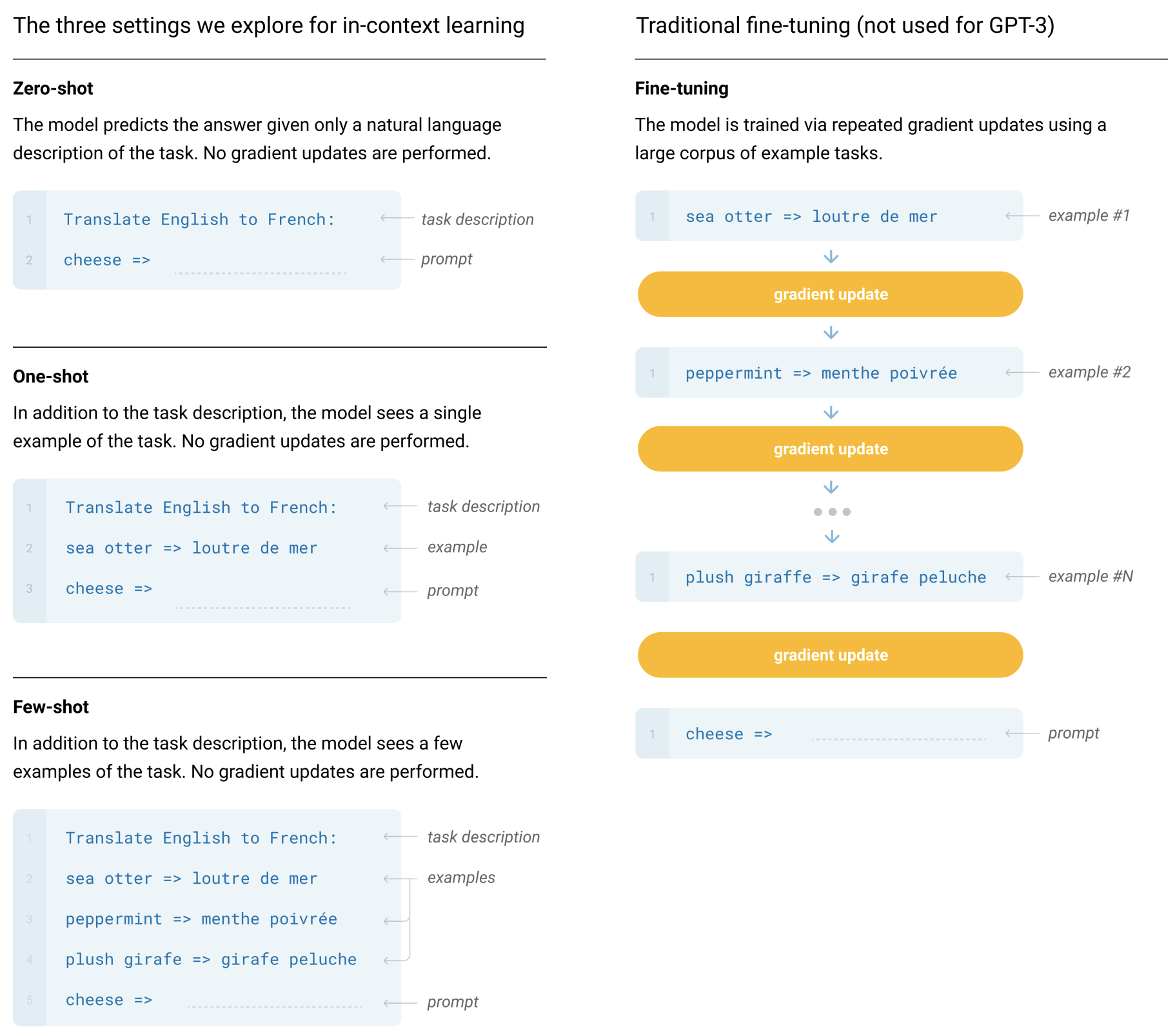
출처: Madotoo et al., 2020
위의 그림과 같이 전통적인 Fine-tuning 방법론의 경우, 반복적인 Gradient 업데이트를 통해 특정 태스크에 대해 학습했습니다. 그러나 최근 Zero-shot, One-shot, Few-shot과 같은 ICL이 등장하면서, 태스크마다 모델을 Fine-tuning 할 필요 없이 LLM이 대부분의 작업에서 좋은 성능을 가질 수 있게 되었습니다.
ICL은 Fine-tuning이 사실상 불가능한 LLM이 다양한 종류의 작업을 수행하게 만들어 주기에 매우 강력해 보이지만, 장점만 있는 것은 아닙니다.
매번 미리 예제를 입력해 주어야 하므로 계산 비용, 메모리 비용, 저장 비용 등이 발생하게 된다는 점, 사람이 시킬 수 있는 작업의 종류와 그것을 표현하는 자연어의 쌍이 무한히 존재하지 않는다는 점이 여전히 문제로 남아있습니다. 또한 최근 한 연구에서는 일부러 틀린 레이블(Incorrect Label)을 예제로 넣어주더라도 문제를 잘 해결하기 때문에 ICL의 결과를 온전히 신뢰하기 어렵다는 의견이 나오기도 했습니다.
PEFT(Parameter Efficient Fine-tuning) 는 이러한 ICL의 단점을 보완하는 대안적인 패러다임 중 하나입니다. 아주 적은 양의 파라미터만 학습하여 기존과 언어모델과 비슷한 성능으로 새로운 문제를 풀자는 것이 이 방법의 주요 목표입니다. 언어모델처럼 매우 많은 수의 파라미터를 쓰는 모델이 사실은 적은 수의 파라미터를 튜닝하더라도 비슷한 성능을 낼 수 있다는 선행연구들이 있었고, 이러한 연구를 기반으로 PEFT를 위한 다양한 방법론들이 제안되고 있습니다.
2. PEFT(Parameter Efficient Fine-tuning) 기법들
PEFT 기법들은 LLM의 성능을 유지하면서 파라미터의 수를 줄이는 것을 목표로 합니다.
성능을 유지하면서 모델의 크기를 줄인다?
양립할 수 없는 이야기처럼 보이지만, 이 글을 끝까지 읽게 된다면 이것이 단순히 요행을 바라는 이야기가 아니라는 것을 알 수 있을 것입니다. 다양한 PEFT 기법들이 LLM의 파라미터를 대부분 보존하고 일부만 학습시키거나, 전체를 보존하고 일부를 추가하여 학습을 진행하는 방식으로 목표를 달성했기 때문입니다. 아래에서는 일부 파라미터만 학습시키는 방식과 프롬프트를 튜닝하는 방식부터, Adapter, LoRA를 거쳐 QLoRA까지 현재(2023.10.09.) 기준으로 최신 PEFT 기술의 발전 양상을 돌아보고자 합니다.
2.1 일부 파라미터만 학습하는 방법
이 방법은 다른 요소를 추가하지 않고 LLM의 특정 레이어나 파라미터만 선택적으로 학습시키는 방법입니다. Transformer 구조인 LLM의 출력 레이어의 일부만 학습시키거나 신경망 가중치에서 Bias 파라미터만 학습시키는 방법 등이 있습니다.
(1) Transformer의 출력 레이어의 일부만 학습시키기
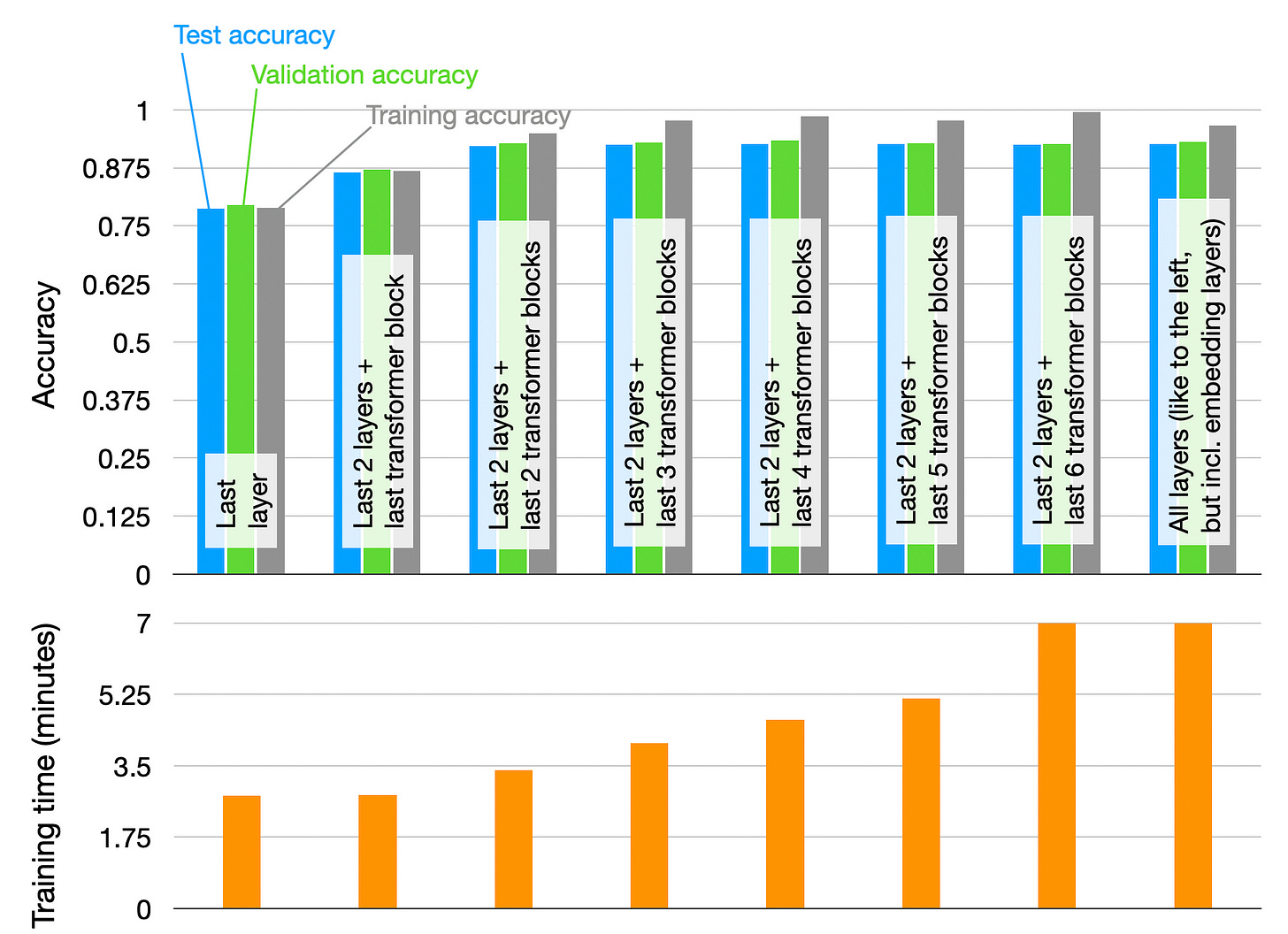
출처: Raschika, 2023
위 그림은 Transformer 구조의 마지막 레이어, 그리고 출력에 가까운 레이어부터 Transformer 블록을 하나씩 늘려서 학습시킬 때 도달하는 성능과 필요한 학습 시간을 보여줍니다. 마지막 2개의 출력 레이어와 마지막 2개의 Transformer 블럭을 학습시키는 경우 이후부터는 Test Accuracy와 Validation Accuracy가 크게 변하지 않으면서 학습 시간은 계속 증가하는 것을 알 수 있습니다. 이를 통해 학습 레이어의 수를 늘리는 것이 성능의 선형적인 향상을 보장하지 않는다는 것을 확인할 수 있습니다.
(2) Bias 파라미터만 학습시키기
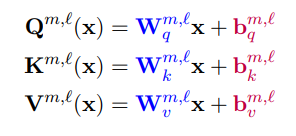
출처: Zaken et al., 2021
Zaken et al.(2021)에서는 미세조정에서 학습이 필요한 가중치(Weight, 파란색)와 편향(Bias, 붉은색) 중 편향만 학습시켜도 소량에서 중간 규모의 학습 데이터를 사용할 때 전체 모델을 미세조정하는 것과 비슷하거나 더 나은 결과를 얻을 수 있음을 확인할 수 있었습니다.
2.2 Prompt-tuning
Prompt-tuning은 LLM 자체를 미세조정하는 기술로, 주어진 입력 프롬프트에 대해 원하는 답변을 생성하는 LLM을 학습시키는 것이 목표입니다. Prompt-tuning을 통해 학습되는 데이터는 입력 프롬프트와 해당 프롬프트에 대해 사용자가 원하는 출력을 포함하는 특수 데이터셋입니다. 이를 통해 모델의 동작을 최적화하고 향후 유사한 프롬프트를 처리하는 능력을 향상하고자 합니다.
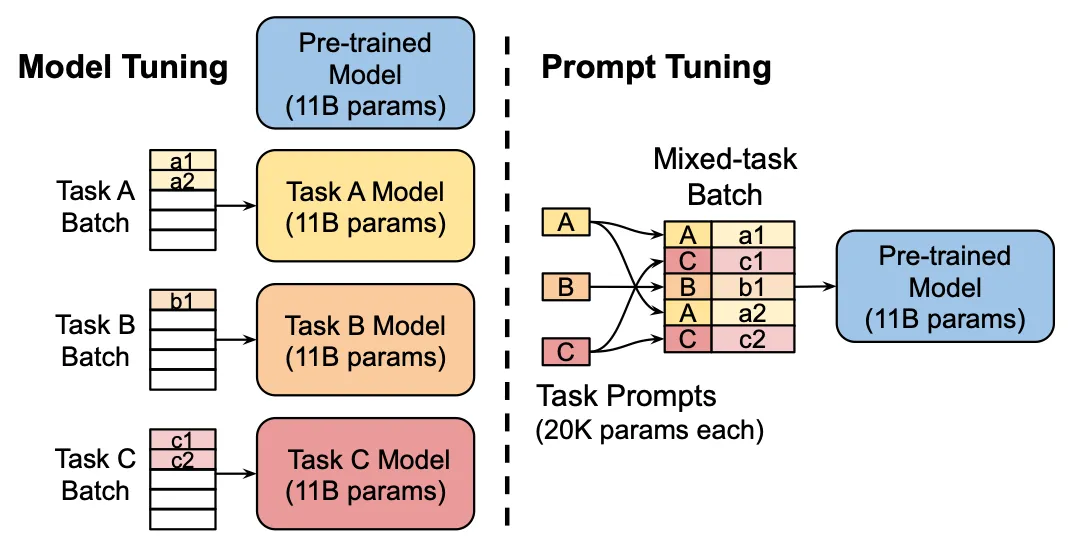
출처: Lester et al., 2021
위의 그림을 한번 살펴봅시다. 원래의 LLM 미세조정이 Task A, Task B, Task C
에 해당하는 데이터셋을 이용하여 학습하는 것으로 모델의 가중치를 각각 변경시키는 것이었다면, 프롬프트 튜닝은 사전 학습된 모델의 가중치를 변경하지 않고 모델에 입력되는 프롬프트에 해당하는 가중치만을 학습합니다. 모델 가중치보다 프롬프트 가중치가 훨씬 작기 때문에 전체 미세조정보다 프롬프트 튜닝의 학습 시간이 빠르다는 장점이 있습니다.
2.3 Adapter
트랜스포머(Transformer) 기반의 모델은 대체로 수백만 또는 수십억 개의 파라미터와 큰 저장공간을 요구하는 매우 복잡한 신경망 구조입니다. LLM이 멀티태스크를 수행하는 과정에서, 각 태스크에 대해 모델을 완전히 미세조정하기 위해서는 각각의 태스크에 대해 학습된 모델의 복사본을 모두 저장해야 합니다. 이에 따라 특히 저장공간이 제한된 환경에서는 반복적/병렬적인 학습이 불가능하다는 문제가 있습니다.
Adapter 는 이 문제를 완화합니다. 그 방법은 다음과 같습니다.
1) 기존에 이미 학습이 완료된 Pre-trained Model의 사이사이에 학습 가능한 Feed-forward Network를 삽입함으로써, 모델 크기와 Bottleneck Size에 따라 필요한 스토리지 공간을 혁신적으로 줄였다.
2) 기존에 할당된 매개변수 내에서 여러 태스크의 정보를 인코딩하는 방법을 학습함으로써, 어댑터를 겹쳐 쌓거나 동적으로 교체할 수 있도록 구성 요소를 모듈화할 수 있게 되었다.
3) 일부 파라미터만을 학습했음에도 미세조정한 모델과 성능 측면에서 큰 차이가 없다는 것을 증명하여, 전체 미세조정이 불가능한 상황에서 사용할 수 있는 경량화된 대안임을 확인하였다.
즉, 기존 LLM을 미세조정하기 위해서는 LLM의 매개변수 전체를 불러서 로 학습시켜야 했다면, Adapter는 를 불러와서 모두 학습시키는 것이 아니라 LLM의 파라미터는 고정하고, Adapter 레이어의 파라미터 만을 학습시켜서 으로 계산하여 계산량을 줄이는 데 성공한 것입니다.
2.4 LoRA(Low-Rank Adaptation)
위에서 소개한 방법들은 LLM의 가중치를 유지하면서 작은 모듈이나 입력 벡터를 학습하는 방식으로 이점을 추구했지만, 이러한 방법들은 경험적인 근거에 의존하는 경우가 많았습니다. LoRA(Low-Rank Adaptation)은 이보다 자명한 근거를 바탕으로 설계되었으며, 위의 방법론들보다 제약사항이 적고 성능은 오히려 더 좋았습니다.
LoRA의 개념을 간단하게 설명하자면, 고정된 가중치(Weight)를 갖는 Pre-trained Model에 학습이 가능한 Rank Decomposition 행렬을 삽입하는 것입니다. 학습이 가능한 Rank Decompostion 행렬을 삽입한다는 것은 무슨 의미일까요? 이해를 돕기 위해 아래의 간단한 예시를 통해 설명해보도록 하겠습니다.
각 행의 합이 10이 되도록 하는 정수 행렬을 구한다고 생각해 보자.
행렬은 5행짜리(5 x n 행렬)이다.
1) 5 x 5 행렬에는 무수히 많은 해가 있을 것이다.
2) 5 x 10 행렬에는 더 많은 해가 있을 것이다.
3) 5 x 1 행렬에도 해가 있을 것이다.
4) 5 x 0 행렬에는 해가 없을 것이다.이 주어진 문제를 푼다고 할 때, 정방형인 5 x 5 행렬은 물론 더 큰 5 x 10 행렬에서도 해를 구할 수 있을 것입니다. 그러나 가장 작은 행렬에서 답을 찾는다면 5 x 1 행렬에서도 해를 찾는 것이 가능합니다. 이해하기 어려우시다고요? 요약하면, 더 큰 크기의 행렬도 답이 될 수 있으나 필요한 최소 열의 개수만으로 이루어진 행렬로 답을 대신할 수도 있다는 의미입니다.
언어모델을 미세조정을 하는 것은 당연히 ‘합이 10이 되도록 하는 정수 행렬을 구하는 것’보다야 훨씬 복잡한 문제지만, LoRA의 핵심 아이디어는 이를 비슷한 관점으로 바라보는 것입니다.
미세조정이 끝나 원하는 문제를 풀 수 있게 된 신경망의 가중치를 처럼 큰 행렬 하나라고 생각해 봅시다. 이 행렬은 미세조정 전의 LLM 가중치인 와 미세조정하면서 변화한 차이인 의 합으로 생각할 수 있을 것입니다. 간단히 보자면 를 를 같은 차원의 행렬로 생각할 수도 있지만, 우리의 목표는 를 LLM보다 적은 파라미터로 표현하는 것입니다.
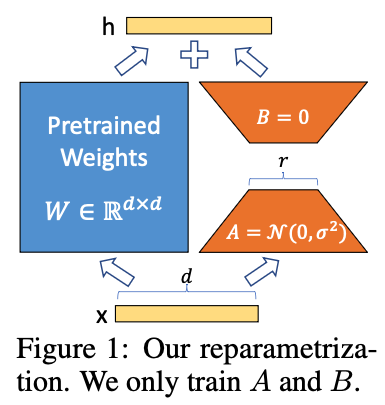
따라서 LoRA는 를 곱해서 같은 차원이 되는 두 개의 더 작은 행렬 로 표현하여 이를 달성하고자 합니다. 만약 이 방식을 사용하지 않는다면 를 로 계산하겠지만, 이를 차원을 가지는 와 차원을 가지는 로 표현함으로써 파라미터 수를 크게 줄일 수 있습니다.
이처럼 레이어 중간중간마다 존재하는 Hidden States 에 값을 더해줄 수 있는 파라미터를 추가해 모델의 출력값을 원하는 타깃 레이블에 맞게 조정하는 것이 LoRA의 핵심 개념입니다. 적은 양의 파라미터로 모델을 튜닝하는 방법론이기 때문에 적은 수의 GPU로 빠르게 튜닝할 수 있으며, 이런 원리로 LoRA는 학습할 파라미터 수를 LLM을 그냥 미세조정할 때에 비해 0.01% 수준까지 줄일 수 있습니다. 두 개의 작은 행렬 곱을 학습하는 것으로 말입니다.
코드로 표현하면 다음과 같습니다.
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling # 행렬을 합치는 부분
self.merged = True실제로 Huggingface의 PEFT 에서 제공하고 있는 LoRA의 GPU 메모리 점유량 테스트에서 볼 수 있듯이 LoRA만 사용하는 경우에도 필요한 메모리가 1/4 수준으로 현저하게 줄어드는 것을 확인할 수 있습니다.
2.5 QLoRA
LoRA도 엔지니어링 측면에서 큰 모델의 학습을 크게 효율적으로 바꿔주었지만, 최근 Quantization(양자화)을 통해 모델을 더 경량화하려는 방법론이 제안됐습니다. 이것이 바로 지난 5월에 공개한 QLoRA입니다.
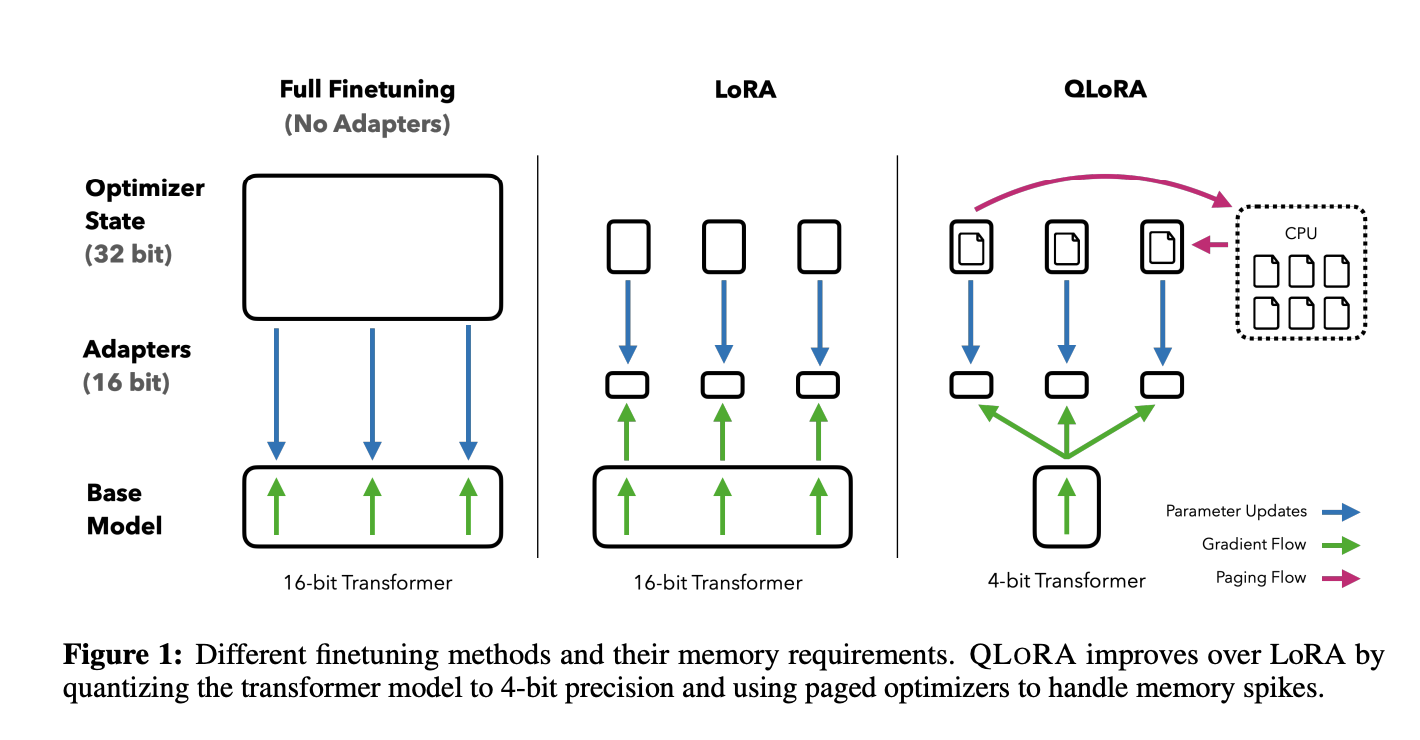
QLoRA는 4비트로 양자화된 사전 학습된 모델을 압축합니다. LLM의 매개변수 개수가 동결되고, 상대적으로 적은 수의 학습 가능한 매개변수들이 하위 Adapter의 형태로 모델에 추가되는 구조입니다. 다음 두 가지 아이디어가 QLoRA의 핵심입니다.
1) 기존의 전체 미세조정과 LoRA가 16비트의 모델을 사용하였다면 4비트로 베이스 모델을 압축
2) 모델 가중치를 저장하기 위한 저장 데이터 유형(4비트 NormalFloat)과 계산을 수행하는 데 사용하는 계산 데이터 유형(16비트 BrainFloat)을 구분하여 저장하고 데이터 유형에서 계산 데이터 유형으로 가중치를 역양자화하여 전달
HuggingFace의 Transformers 라이브러리를 통해 다음의 코드로 간단하게 4비트로 모델을 양자화할 수 있습니다.
from transformers import AutoModelForCausalLM
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)QLoRA 논문에서는 이 방식을 통해 48G의 단일 GPU에서 단 24시간만의 미세조정만으로도 ChatGPT 성능 수준의 99.3%에 도달한 Guanaco라는 모델을 공개하여 이 방법론이 성능 저하 없이 메모리를 절약할 수 있는 방법임을 입증했습니다.
3. 결론
세상은 빠르게 변화하고 있습니다. 특히 LLM의 학습 부분은 하루가 다르게 새로운 방법론들이 제안되고 있는데요. 오픈소스 LLM에 대한 관심이 커짐에 따라 LoRA와 같은 PEFT 방법론 외에도 엔지니어링 측면에서 큰 모델들의 학습을 효율화하려는 움직임이 점차 커지고 있습니다. PEFT가 아니더라도 CPU Offloading, Attention 최적화, Quantization 등의 형태로 다양한 연구가 제안되고 있는 상황입니다.
다만 PEFT 방법론이 현재 학계에서 가장 많이 주목받고 있기에 이 글에서는 해당 방법론을 위주로 알아봤습니다. 이 글이 개인 단위의 LLM 학습에 지대한 관심을 가지게 되어 이제 막 PEFT의 세계에 발을 내디딘 여러분에게 좋은 출발점이 되기를 바랍니다🙏

NLP에 관한 더 많은 내용이 궁금하다면 https://tumblbug.com/deepdaivvol2 에서 매거진을 후원해주세요 🙏
