Paper : https://arxiv.org/pdf/2310.07704
Github : https://github.com/apple/ml-ferret?utm_source=pytorchkr&ref=pytorchkr
0. Abstract
Ferret
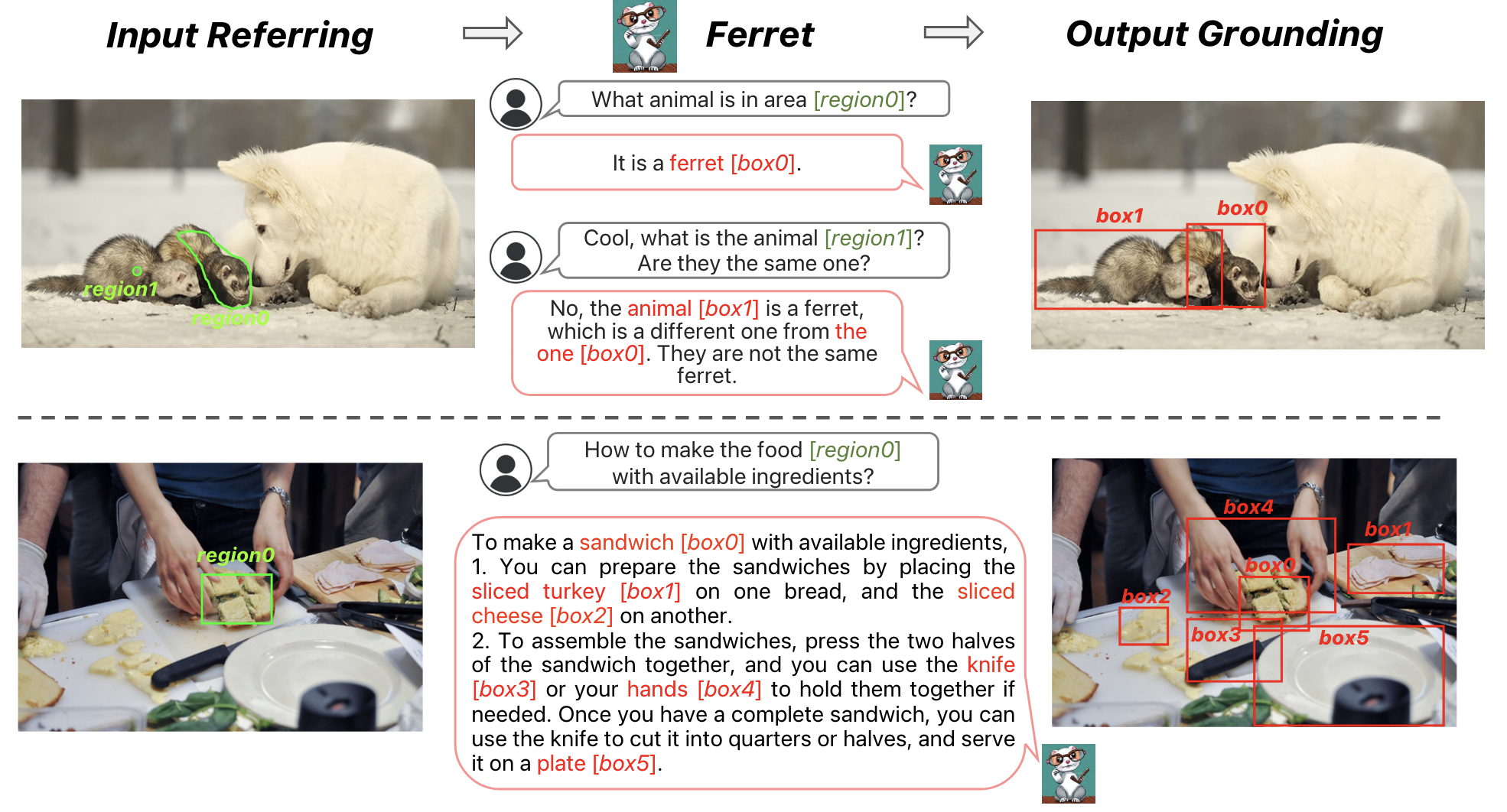
이미지 내에서 어떤 모양의 영역이든 text로 참조하는 대상을 정확하게 지목할 수 있는 mLLM 모델
-
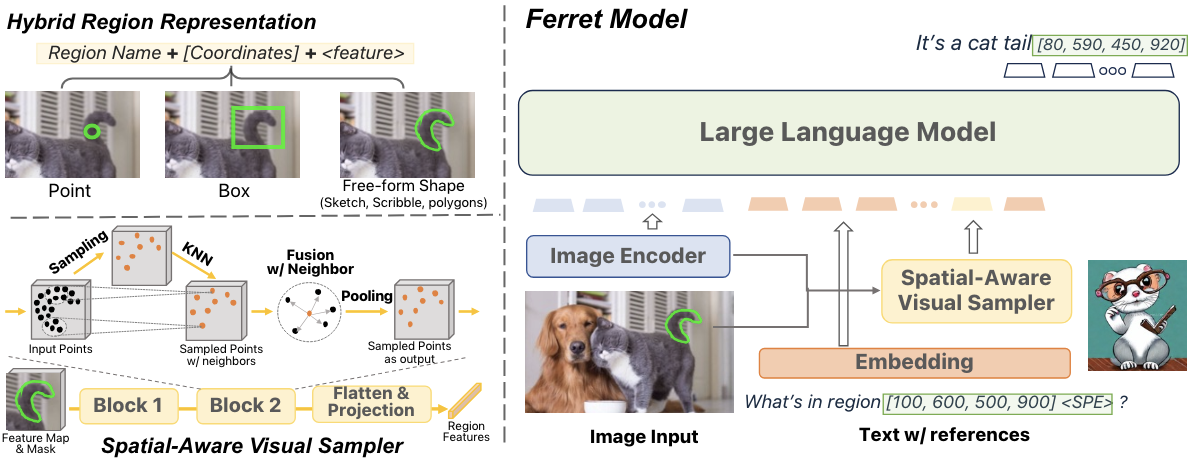
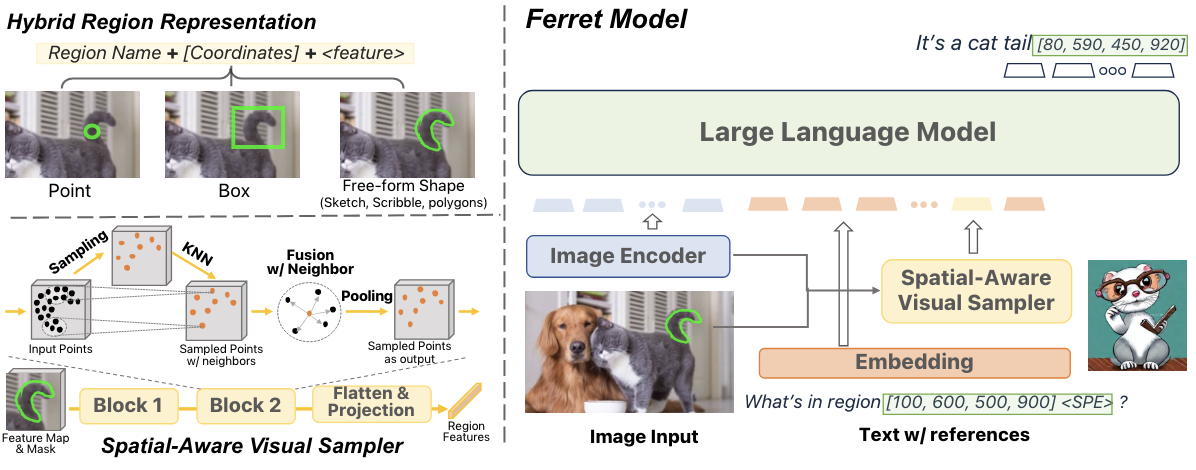
Hybrid region representation : 불연속적인 좌표와 연속적인 feature를 이용해서 이미지의 영역을 표현함
- Spatial-aware visual sampler : 변하기 쉬운 영역도 연속적인 feature를 뽑아낼 수 있기 때문에, 어떤 모양의 이미지도 다룰 수 있게됨
( points, bounding boxes, free-form shapes 등을 input으로 받을 수 있음)
- Spatial-aware visual sampler : 변하기 쉬운 영역도 연속적인 feature를 뽑아낼 수 있기 때문에, 어떤 모양의 이미지도 다룰 수 있게됨
-
GRIT Dataset : referand-ground instruction이 포함된 자체 데이터셋을 이용해서 Ferret 모델을 tuning함
-
Referring, grounding tasks, region-based mLLM, localization-demanded multimodal chatting에서 뛰어난 성능을 보여줌
- image detail을 묘사하는 것과 object hallucination에 대해 평가함
1. Introduction
Referring
모델이 다양한 방식으로 묘사된 영역(region)을 가리킬 수 있는 능력
- Referring in Any Free-Form Shape : 이미지 내 특정 영역을 가리켜 참조함
Grounding
모델이 텍스트에서 언급된 내용을 바탕으로 정확하게 시각적인 위치를 파악할 수 있는 능력
- Grounding of text : 모델이 텍스트에서 지시하는 부분이 실제 이미지에 어디에 해당하는지 이해하고 표현함
이 2가지를 수행하기 위해 mLLM 모델은 기본적으로 공간 정보와 의미에 대한 이해가 필요함
- Spatial-aware visual sampler를 이용해서 모든 영역에 대한 visual feature를 획득함
- 이미지의 feature map과 binary 형태의 region 정보를 받아 sampling하고 sampling된 포인트의 특징을 결합해서 최종적으로 visual feature를 얻은 후, 텍스트로 참조하여 사용함
2. Related Work
- mLLM
- Referring, Grounding
- Unifying grounding, VL understanding
3. Method
Hybrid Region Representation
이산 좌표와 연속적인 visual feature를 결합한 표현 방식
- region을 표현하기 위해 2D binary mask 생성하고, Spatial-aware visual sampler를 이용해서 visual feature를 추출함
- Points : 좌표와 고정된 반지름 원으로 표현됨
- Boxes, Free-form shapes : corner 좌표와 정의된 region에서 추출된 feature로 표현됨

Architecture
Ferret 모델은 3가지 요소로 구성되어있음
- Image Encoder : image embedding을 추출하는 부분
- Spatial-aware visual sampler : regional continous feature를 추출하는 부분
- LLM : image, text, region feature를 결합하는 부분
Input
Image encoder와 LLM을 이용해서 image와 text를 image embedding과 text embedding, token으로 변환해서 처리함
-
image 처리 : input image가 들어오면, CLIP-ViT-L/14 모델을 사용해서 image embedding(Z ∈ R H×W×C)를 추출함
-
text 처리 : input text가 들어오면, LLM의 tokenizer를 이용해서 token화한 후에 text embedding(T ∈ R L×D)을 생성함
-
referred region 처리 : 좌표와 특수 token으로 표현함
(ex. a cat [100, 50, 200,300] ⟨SPE⟩)
Spatial-aware visual sampler
Image feature map(Z)와 2D binary mask(M)을 사용해서 region의 countinous visual feature를 추출함
Sampling, Gathering, Pooling 과정을 거치면서 dense feature space를 생성함
-
Sampling : point 알고리즘을 이용해서, point를 sampling함
-
Gathering : PointMLP와 같이 sampled point와 neighbor point를 융합함
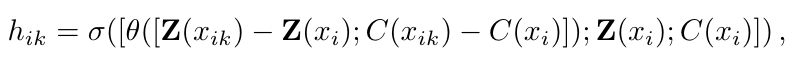
-
Pooling : Max pooling을 이용해서 Gathering 단계에서 융합된 k neighbor feature를 하나의 sampled point의 feature representation로 합칩
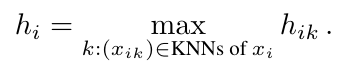
LLM
Vicuna LLM을 이용해서 추출된 feature에 대한 image embedding을 text embedding dimension에 맞게 < SPE > token으로 변환함
- Vicuna LLM : LLaMA 모델 위에 특정 지시에 따라 작동하는 Decoder(projection layer)를 가지고 있는 모델
이 과정을 Ferret 모델은 text 입력에 따라 이미지 내 어떤 것이 어디에 있는지에 대한 이해력을 갖게됨
(이미지에서 referring된 region 또는 물체를 정확하게 식별하고 해당 지역의 위치를 예측하거나 추론할 수 있음)
GRIT Dataset
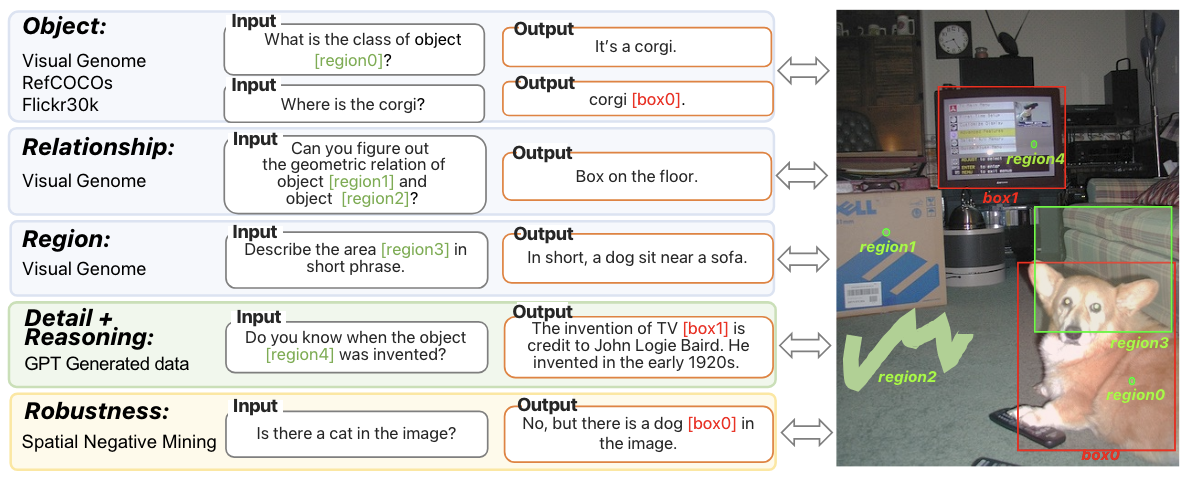
단일 개체, 개체 간의 관계, region 설명에 대한 데이터를 수집하고, 해당 데이터에서 SAM을 이용해 free-form shape 데이터를 얻음
-
Instruction tuning data : ChatGPT/GPT4를 이용해 장면에 대한 text instruction data
- LLaVA-158k 데이터에 open-vocabulary 객체 감지기인 GLIPv2를 적용해서 얻음
-
Negative sample mining : 유사한 속성의 negative entity가 없는 경우와 개체가 위치에 없는 경우 수행함

5. Experiments
- Traffic Light Detection : 혼잡한 장면 속에서도 신호등을 정확하게 식별함
- Object Hallucination Benchmark : 여러 metric을 활용해서 정확도, 정밀도, 재현율 등을 평가함
- Referring : Ferret은 GPT-4V와 달리 작은 영역을 정확하게 이해함
- Grounding : Ferret은 GPT-4V와 달리 복잡하게 구성된 시각적인 이미지 속에서 텍스트 좌표와 region을 이용해서 위치를 제대로 확인할 수 있음
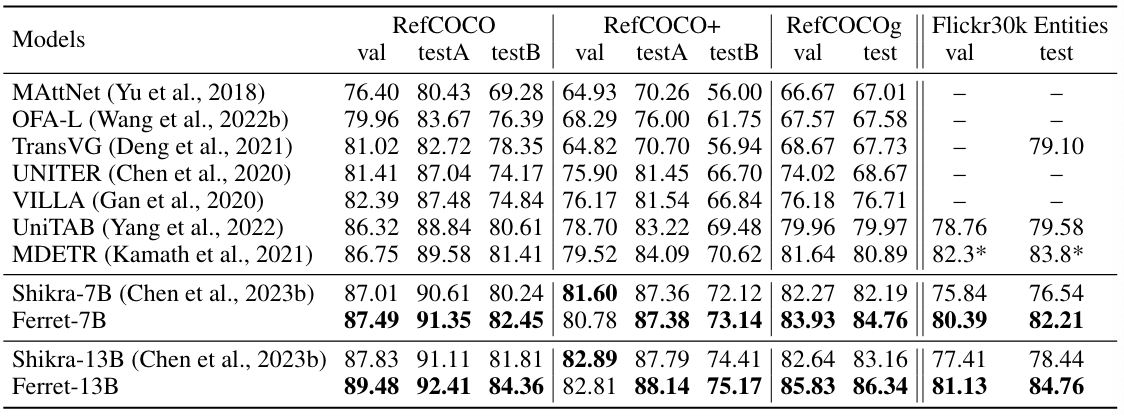

Limitation
다른 LLM 모델들과 같이 여전히 예상치 못한 hallucination이 발생할 수 있음
연구에 적용할 수 있는 부분
- 작은 영역과 복잡한 이미지 속에서 위치를 식별할 수 있으므로, UTG 구성 시 UI intent 요소를 제대로 잡을 수 있음
