![]()
paper: (Zhang 2019) DialoGPT: Large-scale generative pre-training for conversational response generation
github: https://github.com/microsoft/DialoGPT
We present a large, tunable neural conversational response generation model, DIALOGPT(dialogue generative pre-trained transformer). Trained on 147M conversation-like exchanges extracted from Reddit comment chains over a period spanning from 2005 through 2017, DialoGPT extends the Hugging Face PyTorch transformer to attain a performance close to human both in terms of automatic and human evaluation in single-turn dialogue settings.
- DIALOGPT(Dialogue Generative Pre-trained Transformer)라는 크고 조정가능한 neural conversational response generation model을 소개합니다. 2005년부터 2017년 기간동안 Reddit comment chain에 추출한 1억4천7백만 대화형 코멘트에 학습된 DialoGPT는 automatic과(PPL같은) 싱글턴 대화 환경에서 human evaluation을 사람과 비슷한 성능을 얻는 것이 목표입니다.
Introduction
DIALOGPT extends GPT-2 to address the challenges of conversational neural response generation. Neural response generation is a subcategory of text-generation that shares the objective of generating natural-looking text (distinct from any training instance) that is relevant to the prompt.
- DIALOGPT는 conversational neural response generation을 다루기 위해 GPT-2를 확장합니다. neural response generation은 자연스럽게 보이는 텍스트를 생성한다는 목표를 공유하는 text-generation의 하위분야입니다.
Like GPT-2, DIALOGPT is formulated as an autoregressive (AR) language model, and uses the multi-layer transformer as model architecture. Unlike GPT-2, however, DIALOGPT is trained on large-scale dialogue pairs/sessions extracted from Reddit discussion chains. Our assumption is that this should enable DIALOGPT to capture the joint distribution of in conversational flow with finer granularity.
- GPT-2와 같이 DIALOGPT는 autoregressive(AR) language model이며 모델 구성으로 multi-layer transformer를 사용합니다. 그러나 GPT-2와 다르게 Reddit discussion chain에서 추출된 대규모 대화 pair/sesion에서 학습됩니다. 논문에서 의도는 이 대규모 대화 pairs/session이 DIALOGPT가 대화 플로우에서 에대한 joint distribution를 캡쳐할 수 있게 하고자 한다는 겁니다.
Dataset
The dataset is extracted from comment chains scraped from Reddit spanning from 2005 till 2017. Reddit discussions can be naturally expanded as tree-structured reply chains, since a thread replying to one thread forms the root node of subsequent threads. We extract each path from the root node to the leaf node as a training instance containing multiple turns of dialogue.
- 데이터셋은 2005년부터 2017년에 걸쳐 Reddit에서 스크랩된 comment chian에서 추출됩니다.
Reddit discussion은 스레드에 대한 응답 스레드는 하위 스레드의 루트 노드를 형성하기 때문에 자연스럽게 tree-structured한 응답 체인으로 펼쳐질 수 있습니다. 논문에서 root node에서 leaf node까지의 각각의 path(하위 스레드)를 대화의 멀티턴을 가진 학습 인스턴스로 사용합니다.
아래 기준에 해당하는 데이터를 필터링합니다.
(1) URL이 있는 source나 target
(2) 3개 이상의 단어 반복이 target에 포함된 경우
(3) 응답이 가장 자주 사용하는 top 50 단어에 적어도 하나 이상 포함하지 않은 경우(예를 들면 the, of, a)(이는 영어가 아닐 수도 있기 때문)
(4) 응답에 "[" 또는 "]"이 포함 된 경우 (이는 markup 언어 일 수도 있기 때문)
(5) source와 target 시퀀스가 합쳐서 200 단어보다 긴 경우
(6) target이 offensive language를 포함한 경우 (대용량 blcoklist에 매칭하는 방법으로 필터링)
(7) 하위 레딧에 많은 수가 offensive한 내용을 포함할 가능성이 많다고 인식되는 경우
(8) 단조로운 문장 적극적으로 배제 (1,000번 이상 본 tri-gram의 90%가 포함된 응답)
필터링 후 데이터 세트는 총 18억 개의 단어로 147,116,725개의 대화 인스턴스로 구성됩니다.
3. Method
3.1 Model architecture
GPT-2를 따라 multi-turn dialogue 를 하나의 text로 간주합니다. 따라서 multi-turn dialogue session인 은 로 볼 수 있고 이는 사실 (여기서 는 ) 조건부 확률을 product한 것입니다. 결과적으로을 최적화하는 것은 모든 source-target 페어를 최적화하는 것 입니다.
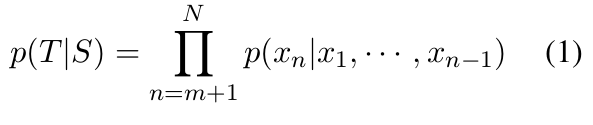
3.2 Mutual Information Maximization
As discussed in the introduction, we surmise that this formulation leads to generic responses being generated, since it only selects for targets given sources, not the converse. To remedy this, we replace it with Maximum Mutual Information (MMI) as the objective function. In MMI, parameters are chosen to maximize (pairwise) mutual information between the source S and the target T:
- 공식 (1)처럼 일반적인 likelihood는 I don't know, I'm OK와 같이 어정쩡한 응답을 생성하게 한다고 추측합니다. 왜냐면 이 공식은 target에서 source가 아닌 source에서 target에 대해서만 선택하기 때문입니다. 오픈 도메인 텍스트 생성 모델의 bland하고 uninformative함을 해결하기 위해, objective function 을 maximum mutual information(MMI) scoring function으로 대체합니다. MMI에서 파라미터는 공식 (2)처럼 source S와 target T간에 상호 정보(mutual information)를 최대화하도록 학습됩니다.
// a hyperparameter λ that controls how much to penalize generic responses
MMI employs a pre-trained backward model to predict source sentences from given responses, i.e., . We first generate a set of hypotheses using top-K sampling. Then we use the probability of to re-rank all hypotheses. Intuitively, maximizing backward model likelihood penalizes the bland hypotheses, as frequent and repetitive hypotheses can be associated with many possible queries, thus yielding a lower probability for any specific query.
- MMI는 pre-trained backward model(pre-trained language model)을 활용하여 주어진 응답에 대해 source sentence를 예측합니다. (ex. ) 먼저 top-K 샘플링을 사용하여 hypotheses 셋을 생성합니다.() 그리고 모든 hypotheses를 re-rank하기 위해 조건부 확률을 사용합니다. 직관적으로 backward model(pre-trained model) likelihood를 최대화하는 것은() bland hypotheses에 불이익을 줍니다(penalize) 왜냐면 bland한 hypotheses는 많은 source query이 가능하기 때문에 모든 쿼리에 대해 확률 값이 낮아지기 때문입니다, 따라서 특정 쿼리에 대해 높은 확률 값을 가지지 않게 됩니다. (실험 4.4 참고)
4. Result
117M, 345M, 762M의 파라미터를 가진 3개의 다른 모델을 학습했으며 이는 GPT-2와 동일합니다.

4.2 DSTC-7 Dialogue Generation Challenge
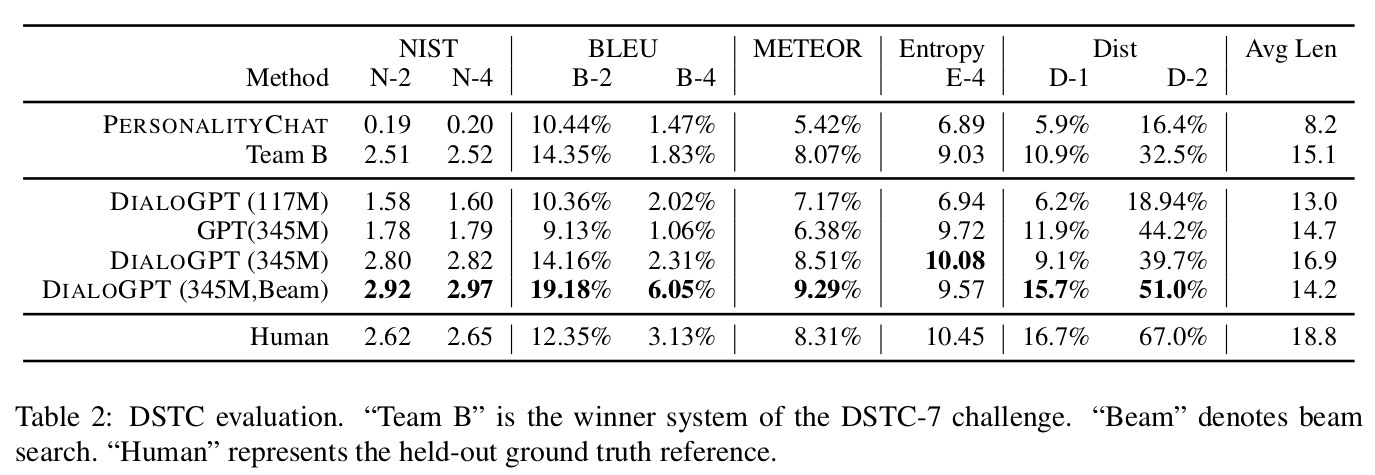
DSTC(Dialog System Technology Challenges) 7 track은 Reddit의 대화 스레드를 포함된 end-to-end conversational modelling task로, 구체적이거나 미리 정의된 목표(예 : 비행 예약 또는 식당에서 테이블 예약)가 없다는 점에서 일반적으로 생각되는 목표 지향(goal-oriented), 작업 지향(task-oriented) 혹은 task-completion dialog와 다른 task 입니다. 논문의 모델은 DSTC 학습 셋에서 어떠한 학습도 하지 않았음에도 불구하고 BLEU, METEOR 그리고 NIST를 포함하여 345M 파라미터 + beam search인 DIALOGPT 모델은 대부분의 메트릭에서 가장 높은 스코어를 달성했습니다. Beam search(beam widht가 10인)는 BLEU와 DIST score를 상당히 향상시키며, NIST와 METEOR에도 미세한 향상을 보임을 알 수 있습니다.
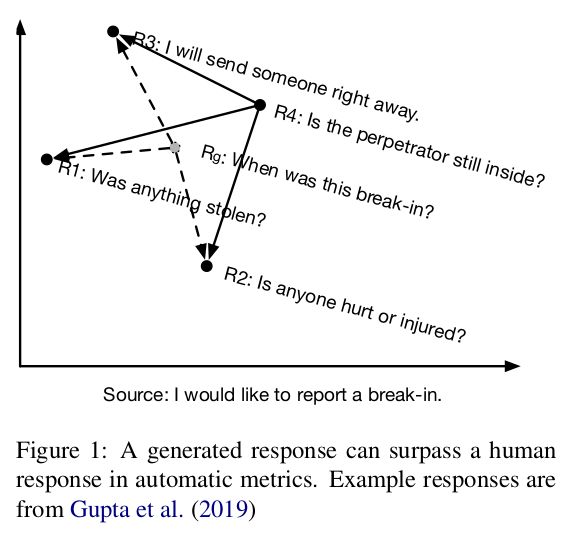
DIALOGPT의 점수는 인간의 점수보다 높지만 이는 인간보다 더 "사실적"이라는 뜻이라기 보다는 모델의 응답이 하나의 질문에 여러개의 답변이 있는 대화의 one-to-many 특성에 따라 가능한 모든 응답의 평균값(기하학적으로 중앙에 위치한)에 위치하는 경향을 보임으로써 테스트 셋의 인스턴스와 거리적으로 가깝다는 의미입니다.
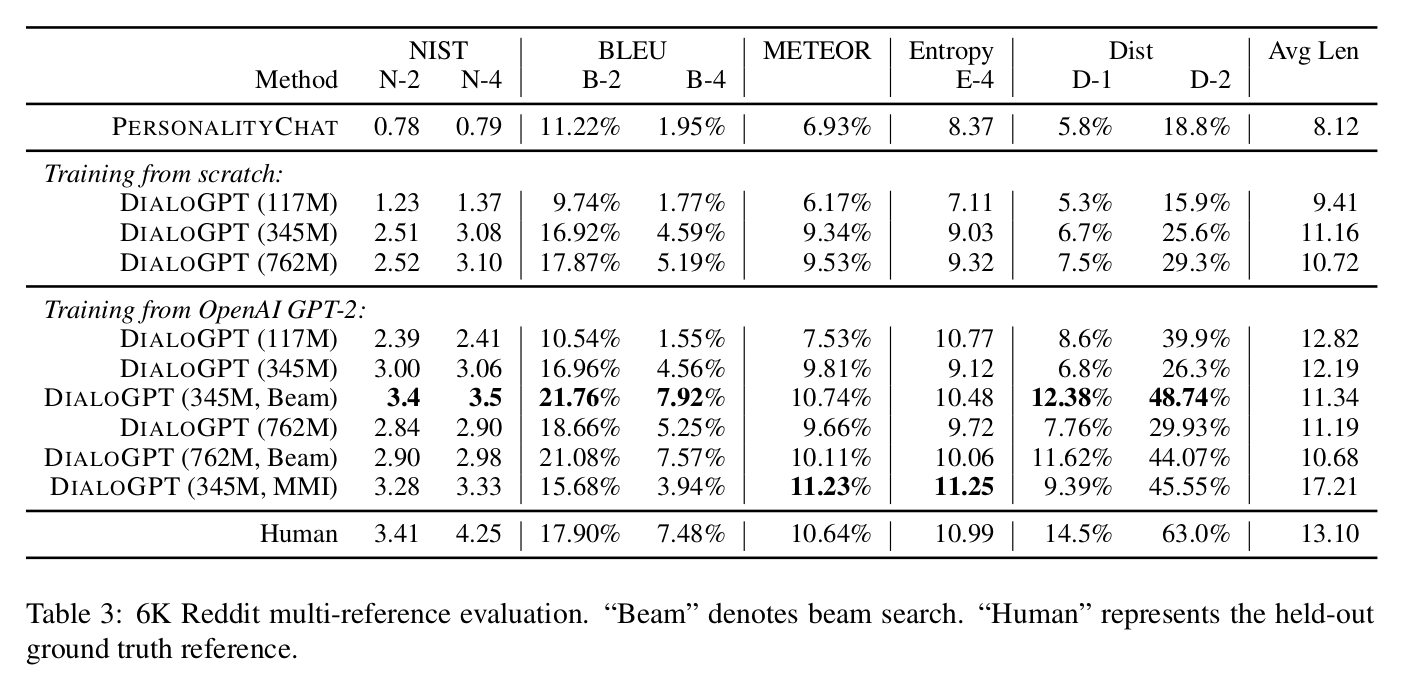
4.3 A New Reddit Multi-reference Dataset
6천개의 테스트셋에서 아래 2가지 세팅으로 DIALOGPT를 추가 평가합니다.
- 처음부터 DIALOPT로 학습하는 방법
- GPT-2로 pre-train하고 DIALOPT로 fine-tune하는 방법
Comparing training from scratch to fine-tuning from the pre-trained GPT-2 model, when applying to smaller model, using GPT-2 model gives larger performance gains. Again, the best system DIALOGPT (345M, w/ beam search) scores higher on BLEU than humans. Larger models trained from scratch (345M and 762M) perform comparably to one finetuned on GPT-2.
- 처음부터 DIALOGPT로 학습하는 것과 pre-trained GPT-2 모델에서 학습하고 DIALOPT fine-tuning하는 방법에 비교하여, 작은 모델에서는 GPT-2 모델을 사용하는 것이 더 높은 성능을 냅니다. 다시한번, DIALOGPT(345M, w/ beam search)는 BLEU score에서 사람보다 높은 점수를 냅니다. 처음부터 훈련 된 더 큰 모델(345M와 762M)은 GPT-2에서 fine-tune된 것과 비슷한 성능을 냅니다
4.4 Re-ranking The Response Using MMI
top-k 샘플링(k=10)으로 GPT-2 medium model에서 fine-tuning한 345M model을 사용한 결과(backward model도 GPT-2 medium model, 345M) Greedy 기법에 비교하여 NIST, METOR와 Entropy 그리고 Dist score에서 더 높은 결과가 나왔고 BLEU은 좀 낮은 결과가 나왔습니다. 결과적으로 MMI-reranking 기법이 더 다양한 응답을 생성한다는 걸 알 수 있습니다.
4.5 Generation Examples
표 4와 표 5는 top-K 샘플링하여 생성된 샘플 대화입니다. Reddit 데이터로 학습한 모델은 어느정도 commonsense한 question을 해결하는 걸 볼 수 있습니다.(표4) 모델은 multi-turn을 더 잘 처리하는 능력이 RNN보다 낫고 context에 관련하여 더 일관성을 보입니다.(표5)


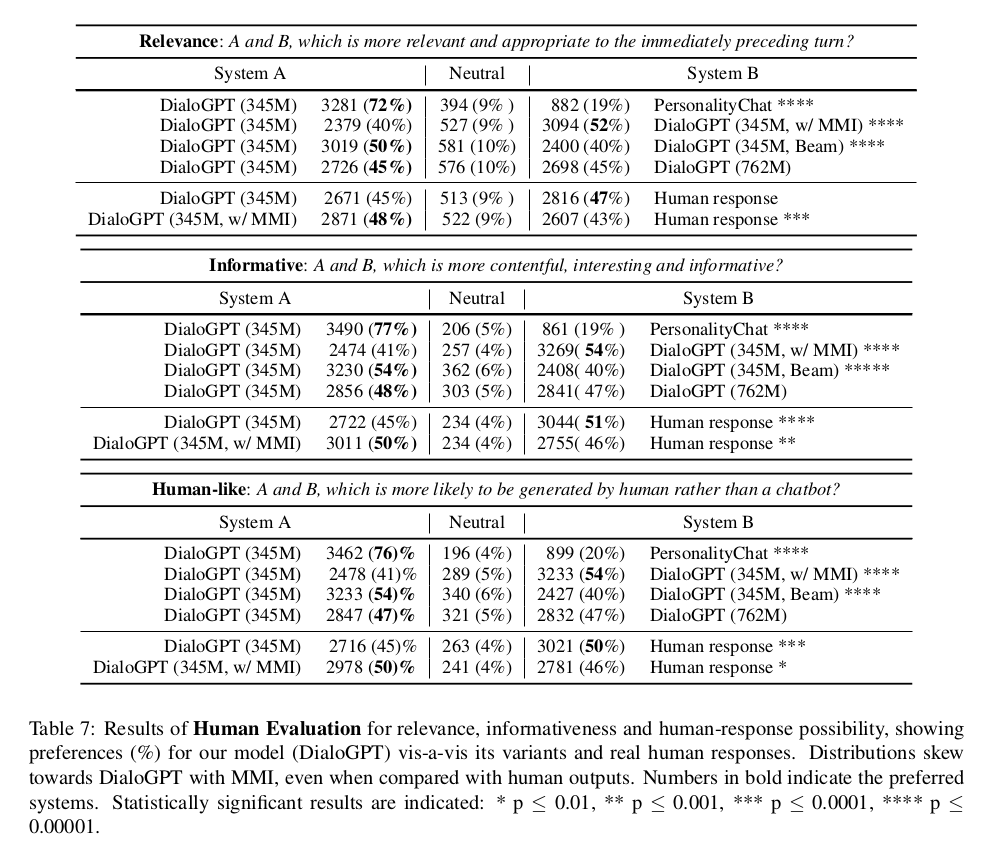
4.6 Human Evaluation
crowd-sourcing을 통하여 Reddit의 6k개의 test dataset에서 2,000개를 랜덤으로 샘플하여 평가를 진행합니다. 시스템은 쌍을 이루고 각 시스템 출력의 쌍이 3명의 평가자에게 무작위로 제시되며 이들은 이 쌍들을 3-point Likert 유사 척도를 사용하여 관령성, 정보성 그리고 얼마나 사람같은지에 대해 순위를 매깁니다. 관련성, 정보성, 인간 유사성에 대한 전반적인 평가 선호도는 표 7에 나타납니다. PersonalityChat보다 DialoGPT에 높은 선호도가 관찰되었습니다. 표 7은 또한 "vanilla" DialoGPT medium model이 이미 인간 응답 성능에 근접함을 제시합니다. 또한, 평가자들은 human response보다 MMI 변형을 더 선호하는 것 같다는걸 발견했습니다. 아마도 이는 많은 true human response들이 불규칙하고, 개개인마다 다르며, 아마 평가자들에게는 생소한 인터넷 용어와 관련된것 때문에 그런것으로 보입니다. (4.2 참고)