![]()
paper: https://arxiv.org/abs/2004.13637
Blender: 지난 2년동안 Facebook AI Research(FAIR)에서 발표한 많은 작업을 융합한 것
Introduction
- 개성, 공감, 지식과 같은 데이터셋에 Fine-tuning한 모델은 챗봇이 더 사람다운 대화를 하도록 한다.(심지어 데이터가 적을지라도)
- decoding 전략을 잘 사용하고 retrieve-and-refine 모델을 통해 지식에 대해 반복적이고 어눌하며 구체적이지 않은 답변을 피할 수 있다.
1. Model
1-1. Retriever
.png)
We employ the poly-encoder architecture of (Humeau et al., 2019). Poly-encoders encode global features of the context using multiple representations (n codes, where n is a hyperparameter), which are attended to by each possible candidate response
Idea
- 입력으로 대화 context가 주어지면, candidate response군에서 가장 높은 점수의 응답을 출력하는, Multi-Sentence Scoring을 Poly-Encoder를 통해 수행하여 다음 next dialogue utterance를 선택
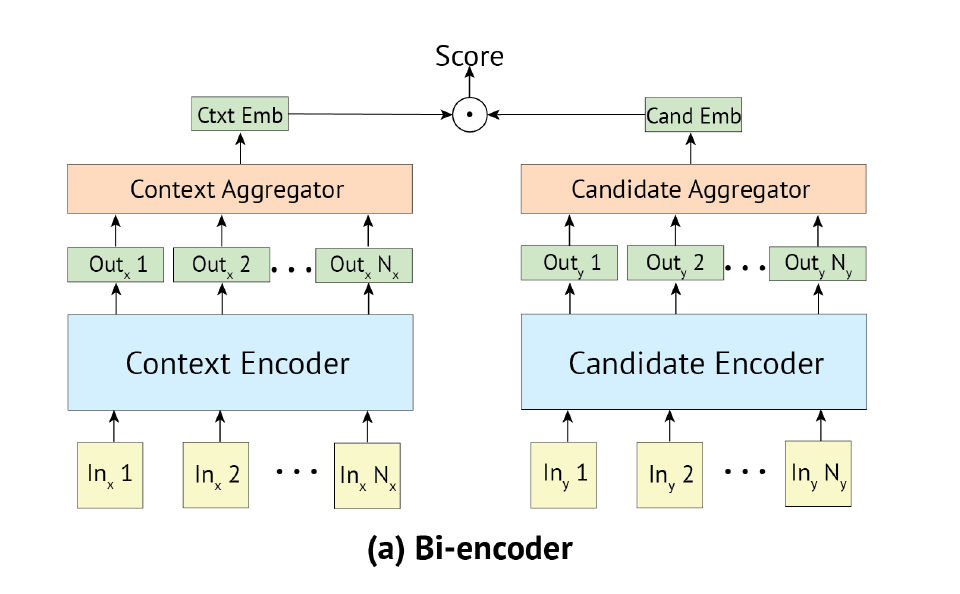
Bi-Encoder
input과 candidate들 각각에 self-attention이 진행되고 top layer에서 나온 ouput을 dot product로 similarity를 학습
- T1과 T2는 pre-trained BERT
- input과 candidate들에 각각 self-attention이 진행된다.
- 각각 self-attention을 통해 hidden state가 나왔으면 이를 reduce 시킨다 reduce 시키는 방법은 세가지가 있다
- 첫번째 special 토큰의 representation을 사용
- 두번째 weighted sum
- 세번째 m길이 만큼만 weighted sum ⇒ 논문에서 사용
- 그 후 각각의 context aggregation에 대한 similarity를 구한다(dot product)
- cross entropy loss
- context와 candidate를 인코딩하는 인코더가 분리되어, candidate representation은 캐싱되기 때문에 inference가 빠르다는 장점이 있다
Cross-Encoder
- 임베딩 입력은 토큰 임베딩 + 세그먼트 임베딩 + 위치 임베딩의 조합
- 입력과 레이블을 concat하여 self attention을 수행
- full bi-directional attention between the input and the label
- 첫번째 토큰에 해당하는 임베딩에 리니어 프로젝션을 수행하여 scalar로 변환
- 후보 레이블은 입력 컨텍스트와 연결해 인코딩하기 때문에 Bi-Encoder보다 높은 정확도를 제공
- Bi-encoder처럼 candidate representation을 캐싱하지 않기 때문에 inference가 매우 느려서 서비스에 이용하기엔 적합하지 않을 수 있다.
.png)
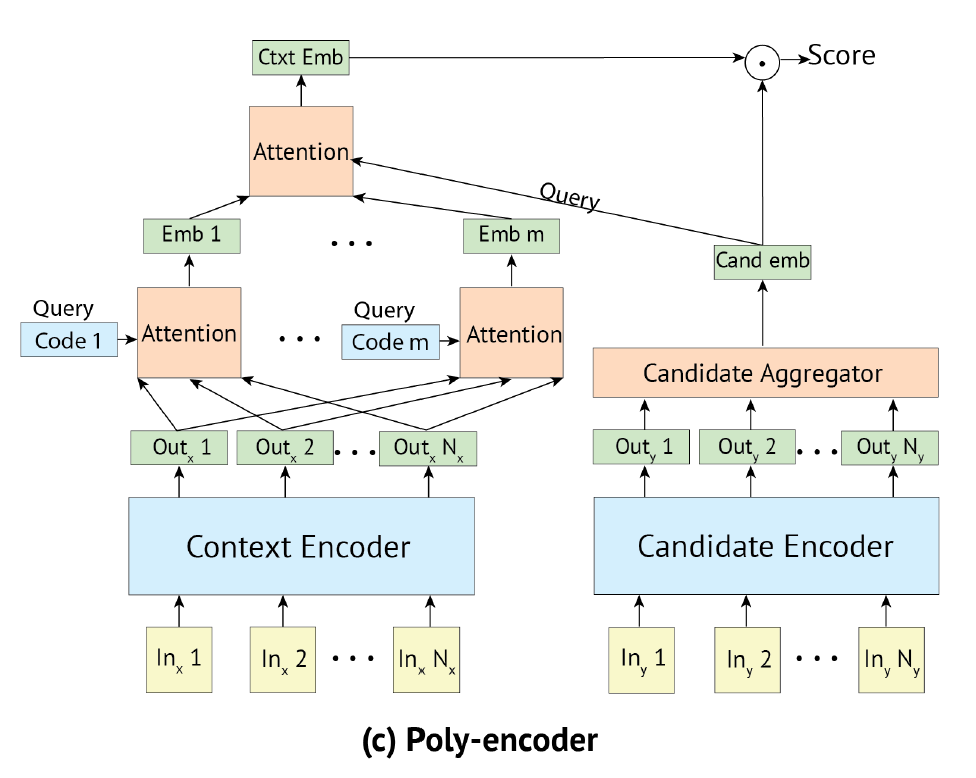
Poly-Encoder
We consider the tasks of sentence selection in dialogue and article search in IR.
- input context embedding과 condidate label embedding 사이에 similarity score를 계산
- paper: Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring(Humeau et al., 2019)
- Bi-Encoder와 Cross-Encoder 장점을 혼합
- inference단에서 Cross-Encoder보다는 빠르지고 Bi-Encoder보다는 나은 accuracy를 갖는다
- Reddit 데이터로 pretrain 진행
- ConvAI2 데이터로 fine-tunning 진행
- 두가지의 Poly-Encoder 사이즈를 고려: 256M, 622M
- 둘다 길이는 64 code 이다
Pre-training
- 174 million examples of Reddit
- 150 million of examples of Wikipedia and the Toronto Books Corpus
- BERT-base: 12개 Encoder block, 12 Attention head, 768 hidden size
- 32 GPUs for 14 days.
Fine-tunning
- ConvAI2 데이터로 fine-tunning 진행
- 입력 컨텍스트간의 셀프 어텐션(BERT embedding)
- 3가지의 attention을 수행
- 입력 컨텍스트의 토큰 임베딩 사이의 어텐션
- 코드(쿼리)와 이전 셀프 어텐션의 출력 사이의 어텐션을 수행함으로써 m개를 인코딩
- 후보 임베딩이 m개의 인코딩 피쳐에게 attend
- 최종 컨텍스트 임베딩과 후보 임베딩간의 dot-product로 similarity 학습
- minimize the Cross-Entropy loss function
- m code(=query)와 이전 self-attention 출력(key) 사이에 dot-product attention을 수행
- 여기서 m < N(N 입력의 길이)
- m인 학습해야할 코드의 개수는 하이퍼파라미터
- 각 코드 는 이전 layer의 셀프 어텐션의 출력값에 모두 attend
- m 코드는 랜덤하게 초기화
- 어텐션 weight를 통해 다시 이전 셀프 어텐션 출력으로 value를 가져온다, 각 output에 value를 얻어 weighted sum ⇒
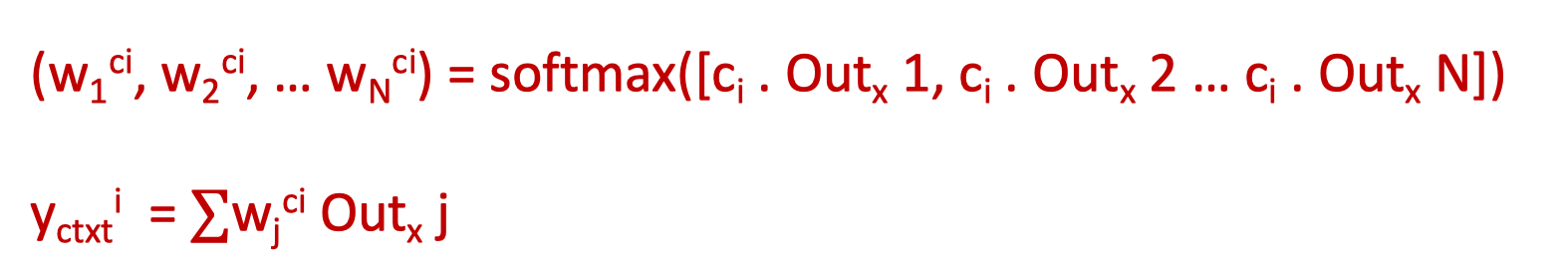
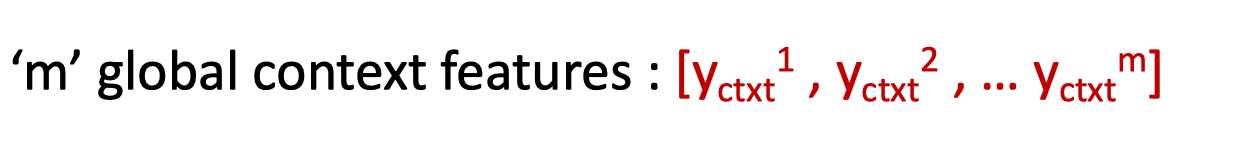
- 이 입력 context의 global feature들과 후보 레이블의 임베딩 간의 어텐션
- 여기서 후보 레이블이 query, context가 key가 된다, 즉 candidate에서 context로 attend
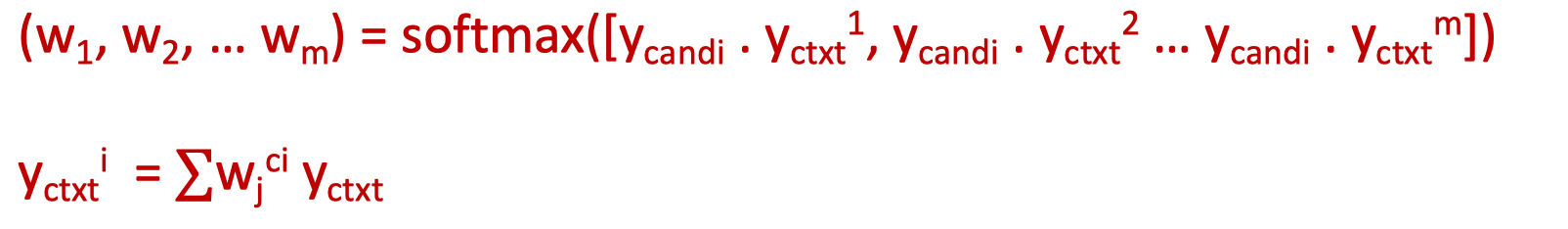
- 여기서 y{candi}는 aggregation된 embedding 벡터, y{ctx}^i는 input context에 대한 각 토큰별 embedding 벡터다

1-2. Generator
We employ a standard Seq2Seq Transformer architecture to generate responses rather than retrieve them from a fixed set.
standard seq2seq Transformer + BPE 토크나이저 사용
매우 큰 세개의 모델 사이즈를 고려: 90M, 2.7B, 9.4B
- cf) Meena는 2.7B
- 2.7B 모델은 2 encoder layer, 24 decoder layer, 2560 임베딩 차수, 32개 attention head로 대략 Meena와 비슷하다
- 9.4B 모델은 4 encoder layer, 32 decoder layer, 4096 임베딩 차수, 32개 attention head
1-3. Retrieve and Refine
One approach to try to alleviate these problems is to combine a retrieval step before generation, referred to as a retrieve and refine model (Weston et al., 2018). We consider two variants for the retrieval step: dialogue retrieval and knowledge retrieval.
.png)
앞서 언급한 Retriever와 Generator를 결합한 구조
외부 데이터에 대해서 답변을 못하는 문제를 해결하기 위해 retrieve and refine 모델(Weston et al., 2018)이라고하는 생성 전에 retrieval 스텝을 결합하는 것
⇒ 이렇게 함으로써 생성 모델이 적절한 경우 검색 결과에서 단어 나 구를 복사하는 법을 배울 수 있다는 것을 기대한다
Dialogue retrieval
- input context + [SEP] + 검색된 next utterance
- 검색된 next utterance를 그대로 출력하는 대신 Generator를 통해 응답을 생성하도록 한다
- expectation
- only Retrieve보다 더 자연스러운 문장을 생성하여 응답하겠지
- only Generator보다 검색된 next utterance는 사람이 작성한 gold response이므로 더 명확한 단어, 표현을 Retriever를 통해 배우겠지
Knowledge Retrieval
- Wizard of Wikipedia task에서 제안된 IR system을 이용해(TF-IDF) input context와 가장 적합한 knowlege candidate를 가져온 후 가장 적합한 best를 generator에 전달
- IR에서 Input Context로 지식 후보 문서들을 검색한다(예를들어 wiki 아티클들)(7개)
- Input Context와 후보 문서들을 Poly-Encoder에 넣어 best 문서를 pick 한다
- 이 best 문서는 생성모델에 입력으로 들어가고 생성모델은 응답을 생성한다
- Dialogue는 Generator의 입력 구조가 input context + sep + 검색 reponse인 반면에 지식 검색에서는 best knowledge candidate만 쓰는 이유는 fine-tuning data가 지식-응답간에 관계가 많아서 그렇다. 왜냐면 입력에 gold knowledge만 사용하기 때문이다
2. Training Objectives
2-1. Ranking for Retrieval
검색모델을 학습하기 위해, 은 정답 응답이고 나머지는 샘플링된 negatives인 로짓인 의 cross-entropy loss를 최소화 합니다. batches of 512
2-2. Likelihood Training for Generation
standard maximum likelihood estimation (MLE) 방법을 사용합니다.
Given a dataset , minimize:
.png)
where is a gold input context and is a gold next-utterance, and is -th token of .
2-3. α-blending for Retrieve and Refine(Dialogue retrieval)
- gold label과 검색된 대화 utterance간에 관련성이 반드시 명확하지 않기 때문에, 학습 모델은 자주 단순히 검색된 utterance를 무시하는 것을 선택을한다. 검색된 utterance 사용을 보장하기 위해, 알파 타임은 gold response 대신에 검색된 response로 교체된다.
2-4. Unlikelihood training for generation
우리의 언어모델이 실제 사람이 사용한 데이터셋의 분포와 비교하여 더 많이 사용하는 것들에 대해 확률 분포를 낮춤으로써 적절한 횟수의 사용을 하도록 하는게 목표 (실험)
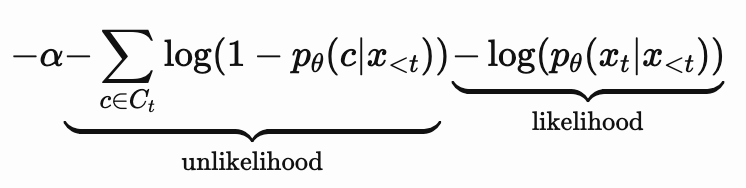
- 는 우리 언어 모델이고 는 선행토큰
- : negative candidates
- unlikelihood의 log안에 괄호를 최대화하여 c의 확률 분포를 낮추는게 목표
- (using the same tokens more frequently than a human), and token distribution mismatch (using specific tokens that have low frequency too rarely compared to humans).
- The authors defined the set of bad candidates as the tokens that were generated more frequently by the model than by humans. To measure these frequencies they kept a running count of the distribution of the tokens generated by the model and they compared it to the distribution of the gold responses.
3. Decoding
- Beam search
- Top-k sampling: model distribution을 사용하여 각 step i마다 가장 적합한 단어가 sampling
- Minimum length: 응답 생성 시에 최소 길이를 강제로 지정, 말을 길게하라고 강제하면 구체적이게 답변할 수 있다 (실험)(실험2)
- Predictive length: 답변마다 필요한 길이를 예측(10, 20, 30...)하고 이를 최소 길이로 설정하여 답변 생성
4. Training data
Pretraining
PushShift에서 2019 년 7 월까지 획득 한 Reddit의 1.5B 학습 예제를 포함하여 comment
다음 조건 중 하나라도 충족되면 의견과 모든 후속 아동 의견을 삭제합니다.
-
The author is a known bot.
-
It comes from a known non-English subreddit.
-
The comment is marked as removed / deleted.
-
It is longer than 2048 characters and does not contain spaces.
-
It is longer than 128 BPE tokens.
-
It is shorter than 5 characters.
-
It contains a URL.
-
It starts with a non-ASCII character.
-
It is further than depth 7 in the thread.
최종 데이터셋은 1.5B comment들, 즉 총 56.8B label BPE token 그리고 88.8B context 토큰을 가진다
Fine-tunning
- ConvAI2 데이터 세트 (Zhang et al., 2018)는 성격에 중점
- Empathetic Dialogues (Rashkin et al., 2019)는 공감에 중점
- Wizard of Wikipedia (Dinan et al., 2019c)는 지식에 중점
- 마지막으로 Blended Skill Talk (Smith et al., 2020)는 이러한 기술을 혼합하는 데 중점을 둔 데이터 세트
- BST 태스크라 함은 위에 4개 테스크에 대해 페르소나를 기준으로 학습된 것을 말한다
.png)
5. Evaluation Methods
ACUTE-Eval
사람이 평가해보았을 때, 대화 시스템에서 참여도(engageness)와 인간성(humanness)에 초점을 가지고 평가
사람 평가자는 2개의 대화 쌍을 보고 아래를 기준으로 평가해야 된다
- 참여도 질문 : "오래 대화하기 위해 누구와 이야기하고 싶습니까?"
- 인간성 질문 :“어떤 스피커가 더 인간적으로 들리는가?”
평가를 하는 annotator의 bias를 줄일 수 있다, 이전 대화와 대조되는 응답에 대한 문제를 해결 할 수있다
- cf) Meena는 말이되는지, 구체적인지를 평가
Self-Chat ACUTE-Eval
사람이 전체 대화를 봇이랑 진행한 후 ACUTE-Eval을 진행하는 대신 봇끼리 self-chat을 통해 대화를 진행한 후 사람에게 평가 진행. resource(사람)를 아끼고 parameter tunning 할 때 반복적으로 사용할 수 있다
6. Result & Analysis
Automatic Evaluations
.png)
Self-Chat Evaluations
Generator Decoding choices
- 최소 길이를 제한 vs 길이를 predictal가 최적화
.png)
.png)
- Meena:Top-k sampling vs Blender: beam search
Likelihood vs. Unlikelihood
- likelihood 모델에 비해 약간의 이득을 보이나 통계적으로 유의하지는 않다
.png)
Comparison to Meena
- Meena보다 참여도와, 인간다움에서 월등히 뛰어난 결과를 보인다

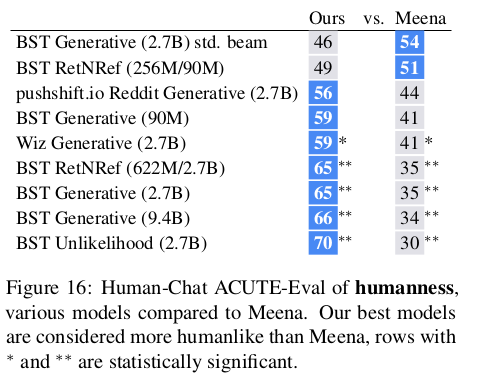
Model vs. Human-human Chat Comparisons

Response Length
.png)

