여기는 전문적인 내용이 아니라,
제가 보고 있는 인강의 내용을 정리하는 곳이에요
실무 팁을 원하시는 분들은 그냥 가볍게 훑어만 주세요
(udemy, frank kane, elasticsearhc7 )
- @frank kane, ur lecture is wonderful :) just in case if u see this lol.
alias
처음 elasticsearch를 공부할 때 인덱스를 매번 만들어야하는지 궁금했어요
(join이 안된다고 하니까..)
그런데 리눅스의 alias처럼 별칭을 사용하는 방법이 있었습니다.
방법도 거의 똑같아요 ㅎ
- 예시 : apache-20200101, apache-20200102 +
POST /_aliases
{
"actions": [
{"add": {"alias":"logs_current", "index": "logs_2020_02"}},
{"remove": {"alias":"logs_current", "index": "logs_2020_01"}},
{"add": {"alias":"logs_last_3_months", "index": "logs_2020_02"}},
{"remove": {"alias":"logs_last_3_months", "index": "logs_2020_01"}},
}lifecycle
index lifecycle management(ilm) 라고 하는데 생명 주기를 나타냅니다.
각각 설정을 해서 세부적으로 관리할 수 있어요
저장 공간은 무한하지 않으니까요ㅎㅎ
- hot warm cool delete
예를 들어서,
1. hot의 데이터 용량이 50gb를 넘거나/ 30일이 넘으면 delete로
2. delete에서 90일이 넘으면 삭제
라는 시나리오가 있으면 아래와 같이 진행되는거죠
PUT _ilm/policy/datastream_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50GB",
"max_age":"30d"
}
}
},
"delete" {
"min_age": "90d",
"actions":{
"delete":{}
}
}
}
}
}
PUT _tempate/datastream_template
{
"index_patterns": ["datastream-*"],
"settings":{
"number_of_shards" : 1,
"number_of_replicas" : 1,
"index.lifecycle.name" : "datastream_policy",
"index.lifecycle.rollover_alias" : "datastream",clustering hardware
요약하면 아래와 같아요
정답은 없다. 하지만 개인적 추천은 있다.
- cpu 보다 ram이 더 중요하다.
- 32GB 정도 쓰고, 8GB 이하는 많이 힘들다.
- 1/2(32GB)는 elasticsearhc
- 1/2(32GB)는 OS/Disk : 루씬 돌아야하니까ㅎ
heap sizing
default는 1GB라서 연습용으로는 적당하지만, 실무에서는 많이 힘드러요
- 32기가 java 설정하면 포인터가 터진다고 합니다.
export ES_HEAP_SIZE=16g
monitoring
모니터링은 xpack 중 일부인데, 일부 기능은 유료라고 해요
7.X 부터는 기본 탑재되어 있고요.
무료 부분은 기본적인 elastic 상태를 kibana에서 볼 수 있습니다.
- node가 1개면 상태가 yellow로 뜹니다.
- documents, data, memory,shard 등을 ui로 볼 수 있어요
status green 만들기
이제까지는 node가 1개 뿐이었으니, 다 yellow였다.
하지만 green 이 보고 싶다. (좀 변태같지만)
그래서 node1 node2 node3를 만들었다. 방법은
- cp /etc/elasticsearch /etc/elasticsearch-node2
- cp /etc/elasticsearch /etc/elasticsearch-node3
총 3개의 elasticsearh에 yml을 수정.
(각각)node.name : node1 , node2, node3
(각각)http.port : 9200 , 9201, 9202
(공통) node.cluster : ["node1", "node2", "node2"]
그리고 실행을 하니, green이 나왔다. 기분 좋다
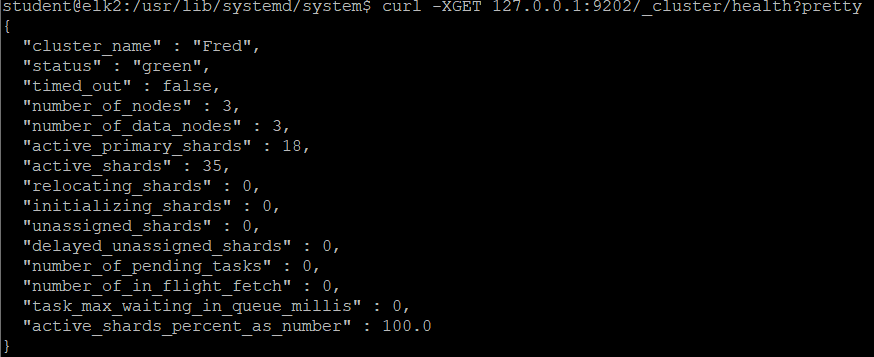
이제 node 하나를 내린다.
sudo systemctl stop elasticsearch-node1
- yellow로 변한다.
- uassigned_shards, number_of_pending_shards에 숫자가 올라갔다.
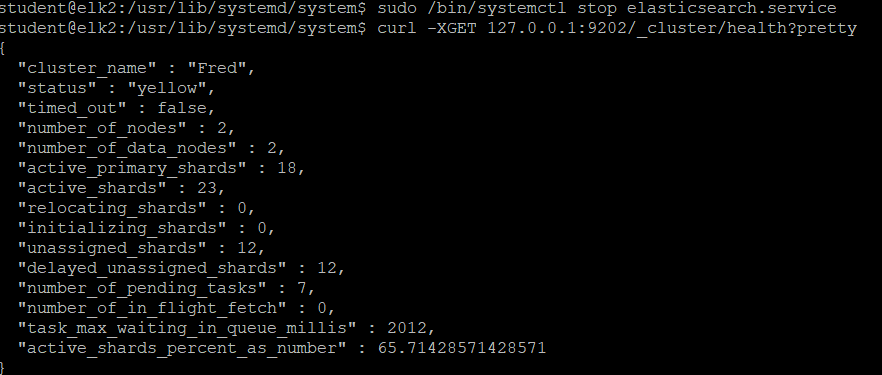
2초 뒤에 다시 _cluster/health 명령어를 입력, 숫자가 줄어든다.

5초 뒤에 다시 입력하니, 없어졌다.

진짜 자동으로 하는구나. 그래서 node 3개를 놓으라고 하는구나.
이제 이해했다. 의미 없지만 안심이 된다.
다시 올리면 green이 될지도 궁금하다.
sudo systemctl start elasticsearch-node1
근데 안된다. status는 green으로 돌아왔는데
node가 아직 2개로 나온다. 또 clusteruuid가 _na로 나온다 ㅜㅜ
근데 Frank(AWS 엔지니어 출신) 형아가
이건 로컬에 node3개 넣어서 오류나는거지
현업에서는 내가 보증한다. 올렸다 내렸다 하면 된다.
여기는 가끔 elasticsearch 폴더 전체를 복사해서 예시로 들다 보니 오류 난다.
라고 했다. 그런 가보다. 안되가지고 머리 싸매고 있었는데, 이렇게 말해주니 안심이 된다.

너무 웃기고 잘 적어주셔서 회사 동료분이 공유해주셨어요
재밋어용