
WHERE 조건절 필터링
IS NULL
NULL 값을 가지고 있는 데이터들을 출력
SELECT CustomerName, ContactName, Address
FROM Customers
WHERE Address IS NULL위 테이블 기준으로 리턴 되는 행이 없음
IS NOT NULL
NULL 이 아닌 컬럼을 가지고 있는 행들을 필터링 해서 출력
SELECT CustomerName, ContactName, Address
FROM Customers
WHERE Address IS NOT NULL위 테이블 기준으로 모든 행이 리턴 됨
LIKE
특정 패턴을 입력하면 해당 패턴에 해당되는 문자열을 필터링, Wildcard와 같이 붙혀서 사용 가능하다. → _언더바 1개는 하나의 문자이고, __ 두개라면 2개의 문자, %는 여러 개의문자

WHERE name = '홍길동';
-- a라는 문자로 끝나는 문자열
-- a로 시작하는 문자열
-- or라는 문자가 어디에 붙어도 모두 출력 가능
-- 첫글자가 있고 그 다음에는 반드시 r 문자가 붙어야 하고, 그 뒤에는 어떤 문자열이 와도 상관 없다
WHERE name LIKE '정_'; -- 2개가 붙어있으면 뒤에 글자가 어떤 글자가 와도 상관 없음 정으로 시작하는 3글자인 사람들이 모두 출력
WHERE name LIKE '정%' -- 정이라는 글자 뒤에 어떤 문자가 와도 상관 없음 (갯수 제한 X)IN
여러가지 값을 걸러내고 싶을 때 사용, 직접 값을 넣어도 가능하고 또 셀렉트 쿼리문을 넣어서도 사용 가능하다. SQL 하나의 값으로 다른 테이블을 필터링 해주고 싶을 때 사용한다. 해당 값을 들고 있는 ROW 만 출력이 된다.
WHERE name IN ('홍길일', '홍길이');NOT IN
값을 들고 있는 않은 ROW 만 출력이 된다
WHERE name NOT IN ('홍길동','2');NULL 조건을 따로 필터링 하고 싶다면 IS NULL 을 사용해야 한다.
그룹화, 정렬
그룹화
같은 값를 가진 행끼리 하나의 그룹으로 뭉치는 기능, 데이터 분석에서 학샘 기능 중 하나이다.
GROUP BY
SELECT 열, 집계함수
FROM 테이블
[WHERE 필터 조건]
GROUP BY 열- ⭐ GROUP BY 절은 FROM, WHERE절 뒤에 위치
- GROUP BY 절에는 어떤 열을 기준으로 그룹화할 지 명시
- WHERE 절 실행 후에 GROUP BY가 실행
- ⭐ FROM → WHERE → GROUP BY → SELECT 실행 순서를 가지고 있다.
- WHERE 조건이 없다면 FROM → GROUP BY → SELECT 순서
HAVING
GROUP BY 절에 의해 생성된 그룹 중 원하는 조건에 부합하는 그룹만 선택하는 구문
SELECT address, count(*)
FROM students
GROUP BY address
HAVING count(*) >= 2; -- 그루핑한 결과로 필터링 해주고 싶을 때 사용- GROUP BY 연산 후 HAVING 절에 의해 필터링
- WHERE → GROUP BY → HAVING → SELECT 순으로 실행 된다.
- GROUP BY 없이 바로 HAVING 을 실행하게 된다면 에러 발생
SELECT address, count(*)
FROM students
HAVING count(*) >= 2;10:36:33 SELECT address, count() FROM students HAVING count() >= 2 LIMIT 0, 1000 Error Code: 1140. In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'test_db.students.address'; this is incompatible with sql_mode=only_full_group_by 0.000 sec
집계가 되고 있기 때문에 하나의 컬럼 만으로 출력이 불가하다. 두개가 매칭이 안되기 때문에 쿼리 실행 오류가 발생한다. address 라는 컬럼이 기준점이 되지만 GROUP BY가 빠져있어서 오류가 발생한다. 기준점이 되는 컬럼이 빠져있었기 때문에 오류 발생
SELECT count(*)
FROM students
HAVING count(*) >= 2;아무런 기준점 없이 전체 데이터에 대해서 HAVING 절을 준다면 집계에 대한 결과로 필터링이 된다. 위 코드는 아무런 의미 없는 코드이다. 전체 테이블에 대해서 카운팅 되고 있기 때문이다.
ORDER BY
특정 기준에 따라 정렬하는 구문으로 출력되기 직전에 특정 열을 가지고 정렬을 해준다.
SELECT 열, 집계함수
FROM 테이블
[WHERE 필터 조건]
GROUP BY 열
HAVING 그룹 필터 조건
ORDER BY 열 [ASC | DESC]- WHERE -> GROUP BY -> HAVING -> ORDER BY 순으로 실행된다.
- 어떤 열을 기준으로 정렬할 지 명시
- 별도로 옵션을 명시하지 않으면 기본 값은 ASC
(ASE : 오름차순, DESC : 내림차순)
LIMIT
결과의 개수를 제한할 수 있고, ORDER BY 와 조합하여 많이 사용하지만, ORDER BY 가 없이도 사용할 수 있다.
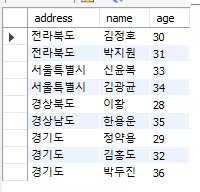
SELECT address, name, age
FROM students
ORDER BY address desc
LIMIT 3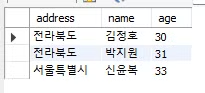
OFFSET
인덱스, 3라고 하면 4번째 row 부터 출력된다.
SELECT address, name, age
FROM students
ORDER BY address desc
LIMIT 3 OFFSET 3;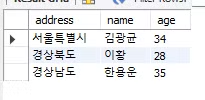
실습 풀이
-- 29세 이상인 학생들을 '주소' 로 그룹핑하고 학생 수가 3명 이상인 그룹만 출력해주세요. 단, 출력할 때 학생 수가 적은 순서대로 정렬해주세요.
SELECT address, count(*) AS cnt
FROM students
WHERE age >= 29
GROUP BY address
HAVING cnt >= 3
ORDER BY cnt DESC;JOIN, UNION
JOIN
하나의 테이블에 원하는 데이터가 없어 두 개 이상의 테이블을 엮어야 원하는 결과가 나오는 경우 사용하는 것으로 관계형 데이터베이스에서 필수로 사용되는 기능이다.
- 컬럼이 가로로 길어짐
FROM절에서 특정 테이블을 붙여준다.ON뒤에 공통 컬럼(두 데이블 모두 가지고 있는 값)을 붙여주어야 한다.
FROM students AS t1 JOIN classes AS t2 ON t1.name = t2.name;UNION
컬럼을 뒤에 붙혀주는 게 아닌, row 를 늘려주는 방법, 각각의 쿼리의 결과가 row로 출력되는데 그 결과를 한번에 출력할 수 있도록 합쳐주는 것이다.
- row(행의 개수)가 길어진다.
- 컬럼의 정보가 같아야 한다.
name, age 를 출력해주는 쿼리문이라면 각각의 결과를 한번에 출력해줄 수 있도록 처리한다. - 특정 쿼리에 대한 결과를 합쳐준다.
- SQL 각각의 조회 결과를 합치는 것
⭐ INNER JOIN
두 데이블을 연결할 때 가장 많이 사용하는 것으로 보통 JOIN 이라고 하면 INNER JOIN 을 의미하며, 교집합을 해준다. → 일치한 ROW 만 출력
- 테이블을 연결하기 위한
key가 있어야 한다. 테이블의 컬럼 값으로 JOIN 해줄 수 있다. - ⭐ 값이 둘 다 있으면 교집합 ROW만 출력된다. → 둘 중 하나의 테이블에 없다면 출력되지 않는다.
SELECT *
FROM students AS A
INNER JOIN classes AS B
ON A.name = B.name;- INNER JOIN 전, 후로 명시한 두 개의 테이블을 JOIN한다는 의미
- ON 구문에는 어떤 열을 기준으로 INNER JOIN을 수행할 지 조건 작성
- A테이블의name 열과 B 테이블의 name 열을 기준으로 INNER JOIN 을 수행
- 겹치는 값이 있다면 중복되어서 나타난다.
FULL OUTER JOIN
한쪽 테이블에만 있는 데이터라도 CLASS_TABLE 에만 있는 데이터라도 모두 출력된다. 합집합이다. A라는 테이블에만 있는 정보가 출력되면 NULL 값이 들어가서 출력된다.
SELECT *
FROM students AS A
FULL OUTER JOIN classes AS B
ON A.name = B.name;| name | age | address | name-2 | class_name |
|---|---|---|---|---|
| NULL | NULL | NULL | 이황 | 알고리즘 |
| NULL | NULL | NULL | 이황 | 데이터베이스 |
| 정약용 | 29 | 경기도 | 정약용 | 데이터베이스 |
| 김정호 | 30 | 전라북도 | 김정호 | 자료구조 |
| 박지원 | 31 | 전라북도 | 박지원 | 데이터베이스 |
| 김홍도 | 32 | 경기도 | 김홍도 | 알고리즘 |
| 신윤복 | 33 | 서울특별시 | 신윤복 | 알고리즘 |
| 신윤복 | 33 | 서울특별시 | 신윤복 | 자료구조 |
| 김광균 | 34 | 서울특별시 | 김광균 | 알고리즘 |
| 김광균 | 34 | 서울특별시 | 김광균 | 자료구조 |
| 김광균 | 34 | 서울특별시 | 김광균 | 데이터베이스 |
| 한용운 | 35 | 경상남도 | NULL | NULL |
| 박두진 | 36 | 경기도 | NULL | NULL |
“한용운”, “박두진” 학생은 classes 테이블에 없지만 student에는 있기 때문에 FULL OUTER JOIN의 결과에 나타났던 것, “한용운”, “박두진” 학생의 수강 정보는 알 수 없기 때문에 NULL로 채워져 있다.
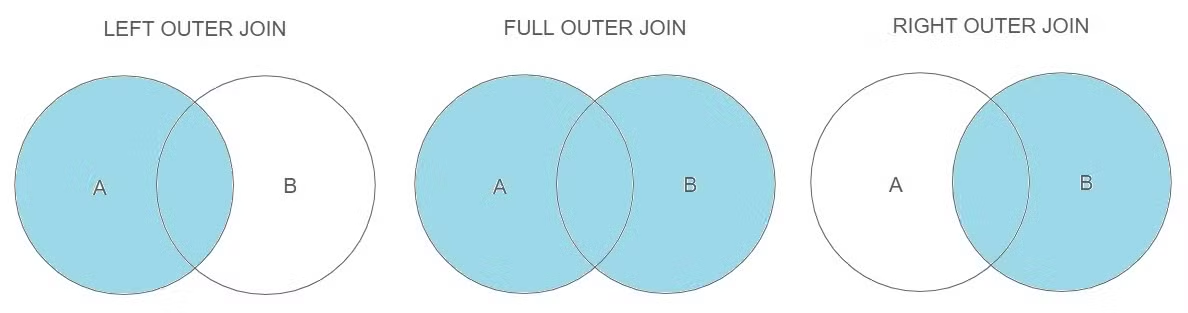
OUTER JOIN은 종류에 관계없이 두 테이블을 조인할 때 1개의 테이블에만 데이터가 있어도 결과가 나온다는 점은 같다.
- A테이블에는 있지만 B테이블에는 없는 케이스 : B부분이 NULL 값, 왼쪽에 있는 정보 전체 출력 →
A LEFT OUTER JOIN B - B테이블에는 있지만 A테이블에는 없는 케이스 : A부분이 NULL 값, 오른쪽에 있는 정보 전체 출력 →
A RIGHT OUTER JOIN B - 교집합 값이 아니기 때문에 NULL 값으로 출력되는 것이다.
LEFT OUTER JOIN
SELECT [열 목록]
FROM [LEFT 테이블] LEFT OUTER JOIN [RIGHT 테이블]
ON [조인 조건]
[WHERE 검색 조건]왼쪽 테이블의 모든 값이 출력되는 조인, 왼쪽 테이블의 의미는 “LEFT OUTER JOIN” 구문을 기준으로 왼쪽에 적은 테이블명이다.
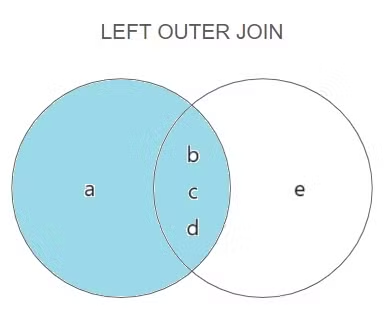
교집합이 없기 때문에 정보가 부족한 부분은 NULL로 채워진다.
| name | age | address | name-2 | class_name |
|---|---|---|---|---|
| 김광균 | 34 | 서울특별시 | 김광균 | 자료구조 |
| 김광균 | 34 | 서울특별시 | 김광균 | 데이터베이스 |
| 한용운 | 35 | 경상남도 | NULL | NULL |
| 박두진 | 36 | 경기도 | NULL | NULL |
RIGHT OUTER JOIN
SELECT [열 목록]
FROM [LEFT 테이블] RIGHT OUTER JOIN [RIGHT 테이블]
ON [조인 조건]
[WHERE 검색 조건]오른쪽 테이블의 모든 값이 출력되는 조인, 오른쪽 테이블의 의미는 “RIGHT OUTER JOIN” 구문을 기준으로 오른쪽에 적은 테이블명이다.
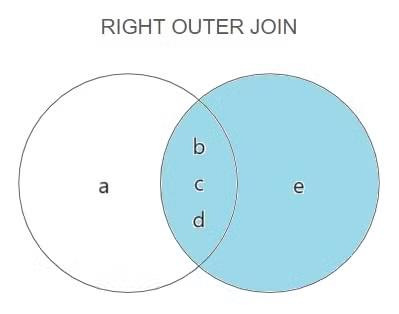
교집합이 없기 때문에 정보가 부족한 부분은 NULL로 채워진다.
| name | age | address | name-2 | class_name |
|---|---|---|---|---|
| NULL | NULL | NULL | 이황 | 알고리즘 |
| NULL | NULL | NULL | 이황 | 데이터베이스 |
| 김광균 | 34 | 서울특별시 | 김광균 | 자료구조 |
| 김광균 | 34 | 서울특별시 | 김광균 | 데이터베이스 |
UNION
테이블 사이에 관계성이(1:1, 1:N, …) 없어도 사용할 수 있다. 두 개의 SQL 실행 결과를 하나로 이어붙이는 형태, 중복된 ROW 는 하나만 출력된다.
[SQL 1]
UNION
[SQL 2]- 각각의 SQL 문에서 어떤 테이블을 조회하던 전혀 상관 없다.
- 대신, 출력의 결과가 하나로 나올 것이기 때문에 필드(열)의 개수, 이름과 타입를 맞춰주어야 한다.
SELECT name , age FROM students WHERE age < 30
UNION
SELECT name, age FROM students WHERE age < 32;30세 미만의 값은 중복이 되고 있다. UNION을 사용하여 결과를 합쳐준다면 중복된 값은 제거되어서 출력된다.
| 정약용 | 29 |
|---|---|
| 김정호 | 30 |
| 박지원 | 31 |
UNION ALL
UNION은 결과에 중복된 데이터가 있을 경우 제거했지만 UNION ALL은 중복 제거 없이 모두 보여준다.
[SQL 1]
UNION ALL
[SQL 2];SELECT name , age FROM students WHERE age < 30
UNION ALL
SELECT name, age FROM students WHERE age < 32;| 정약용 | 29 |
|---|---|
| 정약용 | 29 |
| 김정호 | 30 |
| 박지원 | 31 |
이론적으로 UNION 과 UNION ALL 를 비교 했을 때 UNION은 중복 처리를 진행하기 때문에 UNION ALL의 성능이 더 좋다.
SELECT name , address FROM students WHERE age < 30
UNION ALL
SELECT name, age FROM students WHERE age < 32;위 코드와 같이 다른 컬럼의 값을 넣어도 실행은 되지만 문법적, 의미적으로 맞지 않고, 규칙에도 맞지 않기 때문에 위와 같이 작성하면 안된다. 데이터의 무결성이 깨질 수 있다.
서브 쿼리
하나의 메인 SQL 문에 포함된 또 다른 SQL문을 의미한다. SELECT, FORM 을 하나씩만 있는 쿼리를 작성했었는데, 서브 쿼리라는 것은 SELECT 문이 여러 개인 것이다.
SELECT, FROM, WHERE 절에서 각각 서브 쿼리를 작성할 수 있다.
스칼라 서브 쿼리 - SELECT 절에서 사용하는 서브 쿼리
SELECT -- SELECT 절 안에 SELECT 가 들어가 있다.
name,
age,
(SELECT AVG(age) FROM students) AS avg_age -- 서브 쿼리의 결과가 1개만 나오게 되는데 결과는 모든 ROW에 다 똑같이 나오게 된다.
FROM students
WHERE age < 30같은 값이 여러 개의 ROW 로 출력된다.
만약 각각의 값에 따라서 다른 값을 넣고 싶다면 해당 부분도 서브 쿼리로 출력할 수 있다. → 예시) 나이에 따라서 출력 값을 다르게 하고 싶을 때
SELECT name, address, (SELECT
CASE
WHEN (age < 30) THEN '20대'
ELSE '30대'
END AS '나이'
FROM students b
WHERE b.name = a.name -- 쿼리에서 하나의 값을 리턴받을 수 있도록 조건 추가
)
FROM students a;서브쿼리에서 나오는 결과는 행이 여러개인데, 조건문 WHERE 이 없다면 오류가 발생한다. → Subquery returns more than 1 row
- 하나의 ROW만 리턴되어야 한다.
CASE WHEN THNE ELSE END - SQL문 안에서 조건문 작성
SELECT
CASE
WHEN(조건A) THEN A
WHEN(조건A) THEN A
ELSE C
END AS 원하는 컬럼명
FROM TABLE
;SELECT name, address, CASE
WHEN (age < 30) THEN '20대'
ELSE '30대'
END AS '나이'
FROM students;FROM 절에서 사용하는 서브 쿼리
SELECT *
FROM
(
SELECT name, class_name
FROM classes
WHERE class_name IN ('데이터베이스', '알고리즘')
) as c위와 같이 작성하면 C라는 가상의 테이블을 만드는 효과가 난다. 서브 쿼리의 결과를 C라는 테이블의 별칭을 준 것이다. → 서브 쿼리안에서 나온 결과 ROW를 하나의 가상의 테이블처럼 사용할 수 있도록 만든 것이다. SELECT c.*
AS c 뒤에 JOIN 도 사용할 수 있다.
SELECT *
FROM
(
SELECT name, class_name
FROM classes
WHERE class_name IN ('데이터베이스', '알고리즘')
) as c INNER JOIN students AS s -- C컬럼 안에도 NAME 이 있기 때문에 조인해서 사용할 수 있다.결과는 데이터베이스, 알고리즘을 듣는 모든 학생의 정보가 출력될 것이다. NAME 이라는 값을 기준으로 해서 age, address 도 사용할 수 있다.
SELECT *
FROM(
SELECT name, class_name
FROM classes
WHERE class_name IN ('데이터베이스', '알고리즘')
) AS c INNER JOIN students AS s ON c.name = s.name -- 각각의 컬럼을 기준으로 join 시켜줄 수 있다.students 안에 서브쿼리가 또 들어갈 수도 있다. 하지만, 공통 분모가 있어야 가능하다. 위에 코드는 name 이라는 공통 분모가 존재했기 때문에 join이 가능했다.
WHERE 절에서 사용하는 서브 쿼리
SELECT name, age, address
FROM students
WHERE name IN (
SELECT name
FROM classes
WHERE class_name IN ('데이터베이스', '알고리즘') -- 조건으로 필터링 해줄 수 있다.
)조건절 IN 뒤에서 자주 사용된다.
WHERE name IN (알고리즘을 듣는 학생 목록 , , , ,) 출력
