Today's Topic: Data-Centric AI vs. Model-Centric AI
Syllabus
- Introduction
Data-Centric AI vs. Model-Centric AI- Label Errors
- Dataset Creation and Curation
- Data-centric Evaluation of ML Models
- Class Imbalance, Outliers, and Distribution Shift
- Growing or Compressing Datasets
- Interpretability in Data-Centric ML
- Encoding Human Priors: Data Augmentation and Prompt Engineering
- Data Privacy and Security
Introduction
page: https://dcai.csail.mit.edu/lectures/data-centric-model-centric/
Youtube: https://www.youtube.com/watch?time_continue=2461&v=ayzOzZGHZy4&embeds_euri=https%3A%2F%2Fdcai.csail.mit.edu%2F&feature=emb_logo
Lab: https://github.com/dcai-course/dcai-lab/blob/master/data_centric_model_centric/Lab%20-%20Data-Centric%20AI%20vs%20Model-Centric%20AI.ipynb
What we've known?
- Model-Centric AI : 정제된 데이터셋을 가지고 최고의 모델 성능을 내기 위해 다양한 모델 기반 기술들 사용
- models (NN, DT etc)
- trainig techniques (regularization, optimization, loss fuctions, etc)
- model/hyperparameter selection
- 한계점
- 회사나 고객들은 당신들이 어떤 기술을 적용했는지 do not care!
- Data are not fixed! (데이터 수정해도 되고, 추가해도 노 프라블럼)
- “garbage in, garbage out”
- 대부분의 데이터 messy 하고, 오염되어 있음.
- 모델을 좀좀따리 개선하는 것보다 데이터를 고치는 것이 훨씬 더 도움이 된다!는 걸 모두 알지만, 이런 과정을 수작업으로 하기엔 데이터가 조금이라도 많아지면 귀찮고, 돈도 많이 든다.
What we are going to learn?
- How to systematically engineer data to build better AI system
=>Data-Centric AI
Data-Centric AI
Goal
AI method를 사용해서 systematically하게 real-world dataset에 있을 수 있는 문제들을 진단하고, 치료!
Approach
어떤 데이터가 easy data인지, mislabeled data인지 훈련된 모델 이용하여 추정
- Curriculum Learning: 데이터를 파악하고, 모델 성능 개선을 위해 파악한 정보를 활용해서 'easy data'를 우선적으로 사용해서 모델 학습
- Confident Learning: 데이터를 modify해서 'mislabeled data' 제거한 필터링된 데이터셋 사용해서 학습
A practical recipe for supervised Machine Learning
A data-centric AI pipline
- Step 1: Explore the data, fix fundamental issues, and transform it to be ML appropriate. (데이터가 있으면, 일단 탐색해보고 ML에 맞게 변형을 한다!)
- Step 2: Train a baseline ML model on the properly formatted dataset. (변형된 데이터를 가지고 일단 ML 실험을 돌려봐)
- Step 3: Utilize this model to help you improve the dataset (모델을 개선하기 전에 data-centric ai 기술을 적용해서 여러 실험을 돌려봐라!)
- Step 4: Try different modeling techniques to improve the model on the improved dataset and obtain the best model. (3단계에서 개선된 데이터셋을 가지고 이제는 모델링 기술들을 적용해서 실험해봐라!)
신신당부: 절대 2단계에서 4단계로 뛰어넘지 말고, 좋은 시스템 구축을 위해서 3-4단계를 반복해라!
Examples of data-centric AI
- Outlier detection and removal (handling abnormal examples in dataset)
- Error detection and correction (handling incorrect values/labels in dataset)
- Establishing consensus (determining truth from many crowdsourced annotations)
- Data augmentation (adding examples to data to encode prior knowledge)
- Feature engineering and selection (manipulating how data are represented)
- Active learning (selecting the most informative data to label next)
- Curriculum learning (ordering the examples in dataset from easiest to hardest)
Why we need data-centric AI
-
막대한 비용
- bad data로 인해 미국에서는 매년 약 3조 달러 비용이 발생.
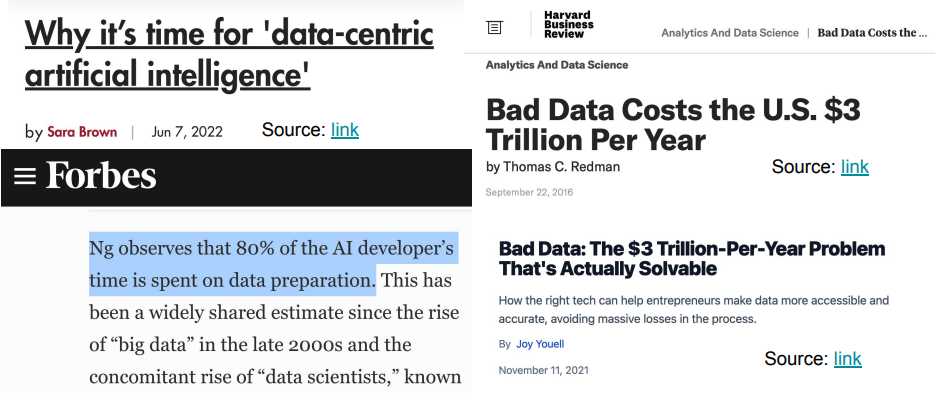
- 데이터가 커짐에 따라서 알고리즘 사용하지 않고서는 데이터 품질 보장하기 힘들다.
- ChatGPT의 경우 이런 단점 보완하려고 엄청난 노동력에 의존하긴 했지만 그래도 완전히 극복할 수 있을까?
- bad data로 인해 미국에서는 매년 약 3조 달러 비용이 발생.
-
최근 주목받는 Data-centric AI 연구
- noisy한 데이터를 어떻게 다룰지 다양한 방법 제안 (HL MM발표: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision)
- dataset을 change할 수 있는 간단한 방법들을 적용한 모델들이, 모델 자체만을 개선시킨 방법들 보다 좋은 성능을 거둔 연구들 다수 확인

-
유명 ML 모델들의 성공 비결!
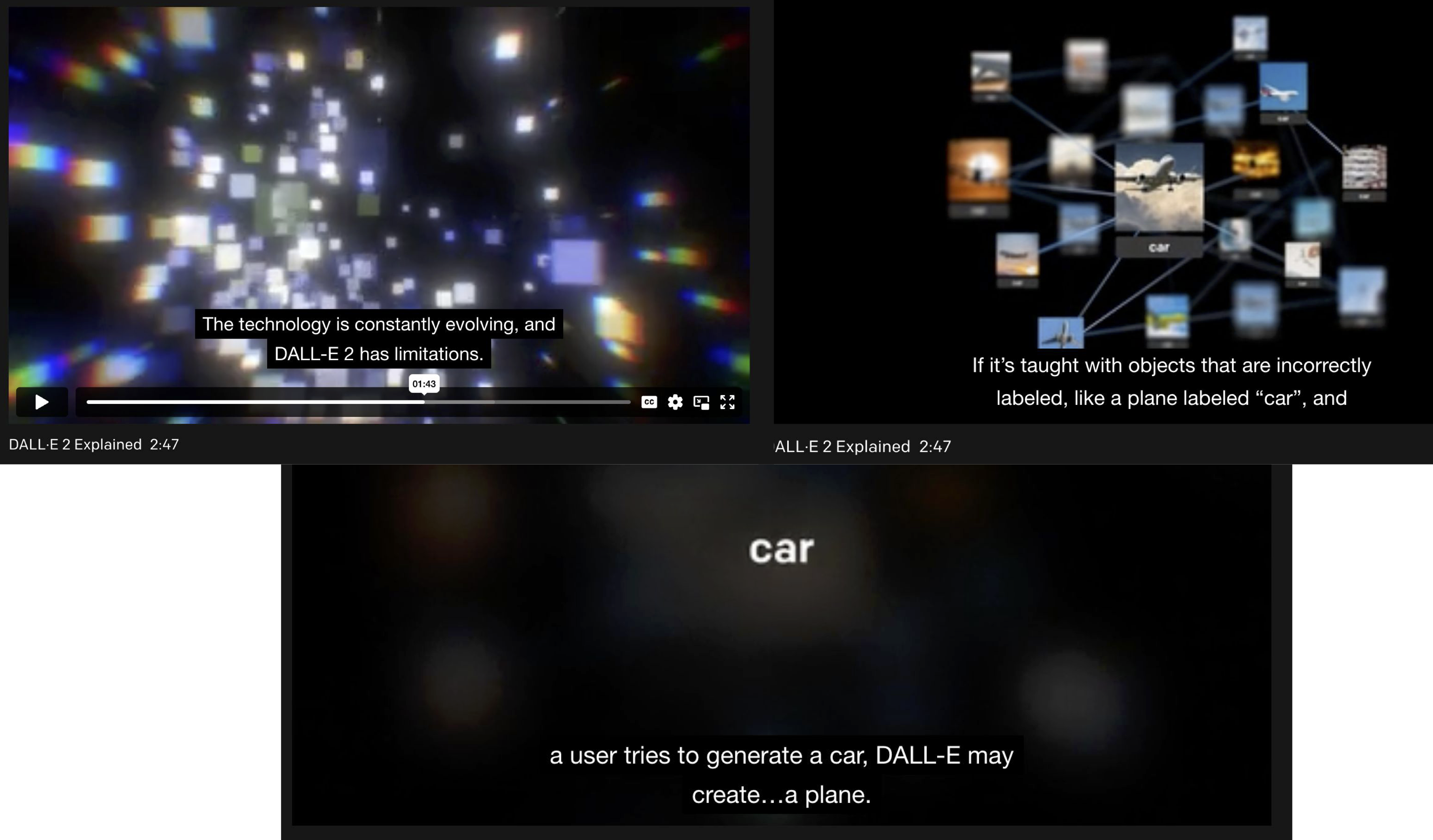
- OpenAI: "data & label error가 ML 모델들(Dall-E, GPT-3, ChatGPT) 발전에 가장 큰 문제점이다"
ref: Dall-E 2 데모 영상 https://openai.com/product/dall-e-2
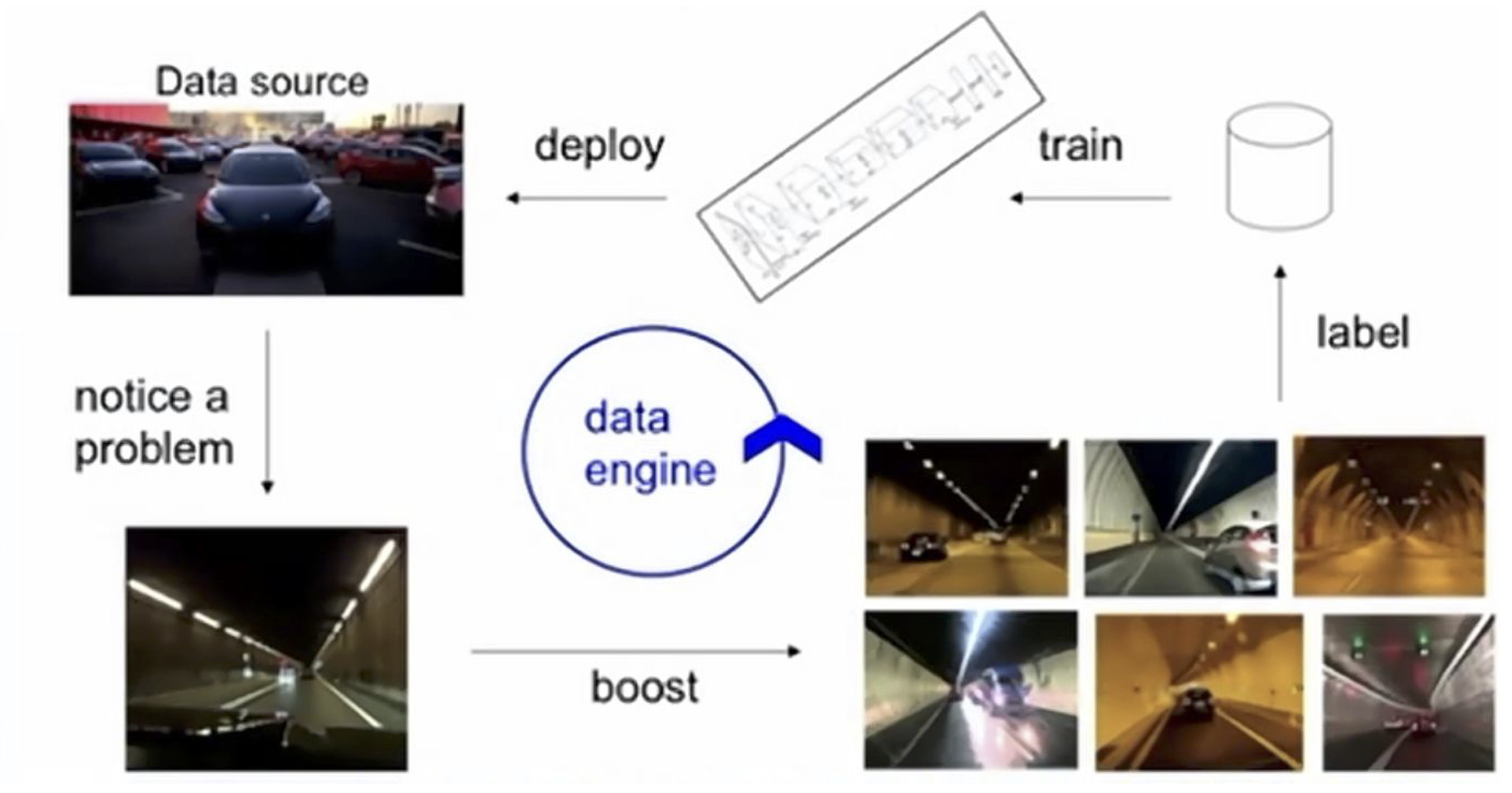
- 테슬라: "Data Engine 단계가 진보된 자율주행 시스템 개발 성공의 가장 큰 비결"
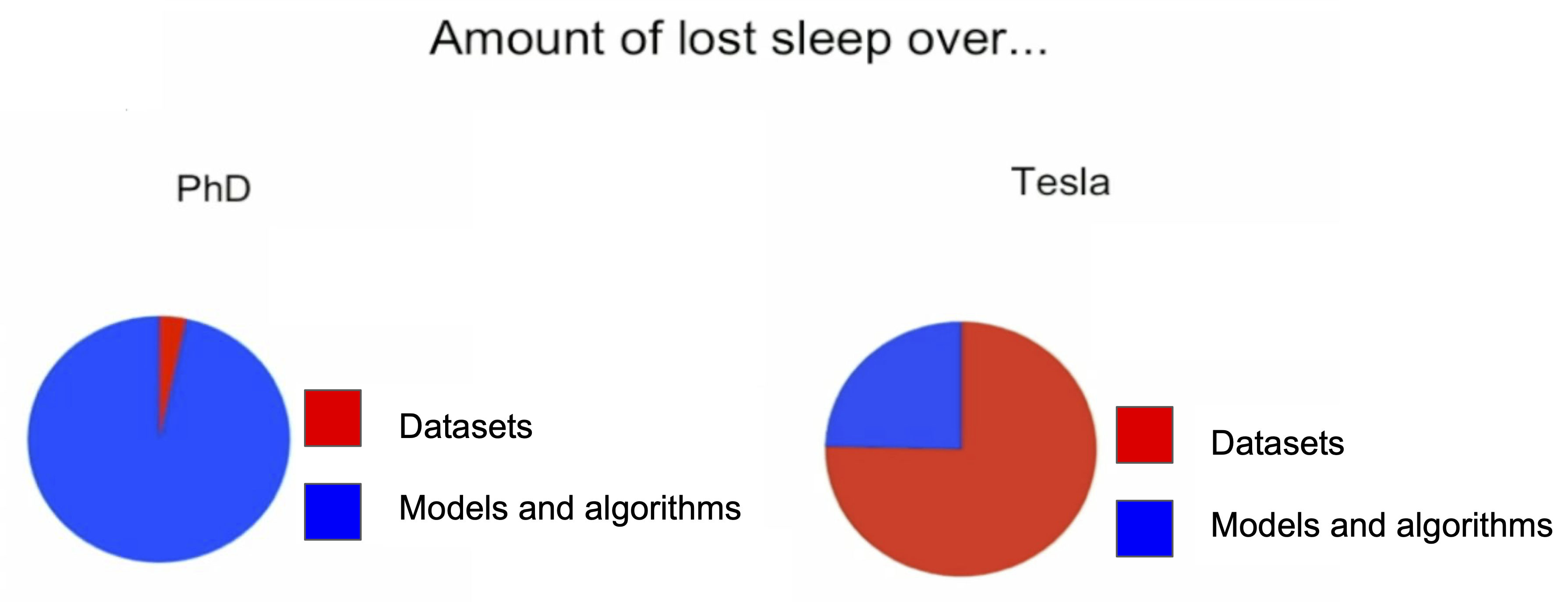
- OpenAI: "data & label error가 ML 모델들(Dall-E, GPT-3, ChatGPT) 발전에 가장 큰 문제점이다"
Lab
-
Goal: Build a classifier for product reviews (restricted to the magazine category)
Excellent! I look forward to every issue. I had no idea just how much I didn't know. The letters from the subscribers are educational, too.
Label: ⭐️⭐️⭐️⭐️⭐️ (good)
My son waited and waited, it took the 6 weeks to get delivered that they said it would but when it got here he was so dissapointed, it only took him a few minutes to read it.
Label: ⭐️ (bad) -
Task:
- 1) We'll work with a dataset that has some issues
- 2) We'll see how we can squeeze only so much performance out of the model by being clever about model choice, searching for better hyperparameters, etc.
- 3) we'll take a look at the data (as any good data scientist should), develop an understanding of the issues
- 4) use simple approaches to improve the data.
- 5) Finally, we'll see how improving the data can improve results.
-
실습
- A data-centric AI pipline
- Step 1: Explore the data, fix fundamental issues, and transform it to be ML appropriate. (데이터가 있으면, 일단 탐색해보고 ML에 맞게 변형을 한다!)
- Step 2: Train a baseline ML model on the properly formatted dataset. (변형된 데이터를 가지고 일단 ML 실험을 돌려봐)
- Step 3: Utilize this model to help you improve the dataset (모델을 개선하기 전에 data-centric ai 기술을 적용해서 여러 실험을 돌려봐라!)
- Step 4: Try different modeling techniques to improve the model on the improved dataset and obtain the best model. (3단계에서 개선된 데이터셋을 가지고 이제는 모델링 기술들을 적용해서 실험해봐라!)
신신당부: 절대 2단계에서 4단계로 뛰어넘지 말고, 좋은 시스템 구축을 위해서 3-4단계를 반복해> 라!
- No Data-centric AI version
- Step 1: 데이터 그냥 load (데이터 이슈 확인 X)
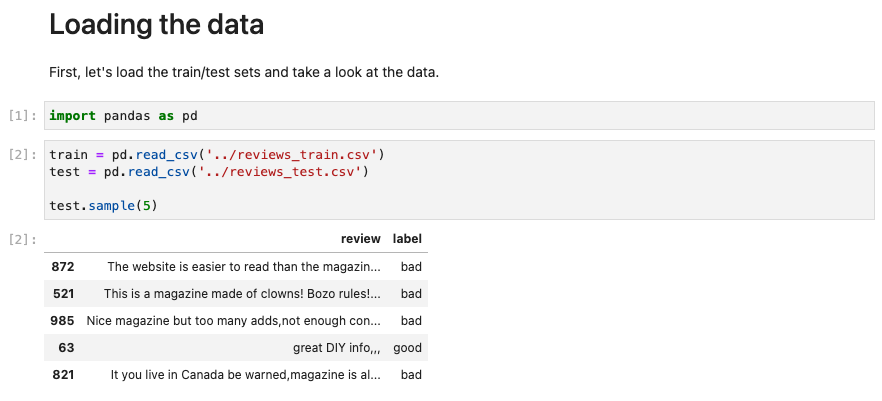
- Step 2: 일반 baseline 모델 실험 (77% 가량 나옴!)
- Step 4: 85% 정도로 8프로 성능 개선 (Step3 건너띔)

- Step 1: 데이터 그냥 load (데이터 이슈 확인 X)
- Data-Centric AI version
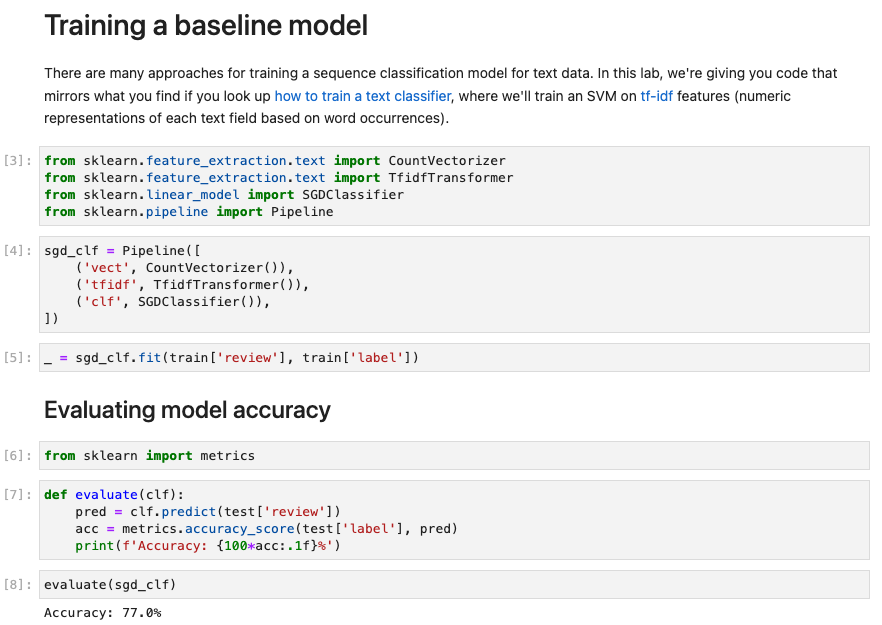
- Step1: 데이터 확인 후 issue 쳌쳌 (HTML에서 그냥 긁어온 애들은 상태가 별로 안좋아보임)
- Step 2: 위에서 함
- Step 3: Data-centric AI 기술 적용 (여기서는
Outlier detection and removal방식 적용해서 HTML 형식 애들 filtering 해줌)
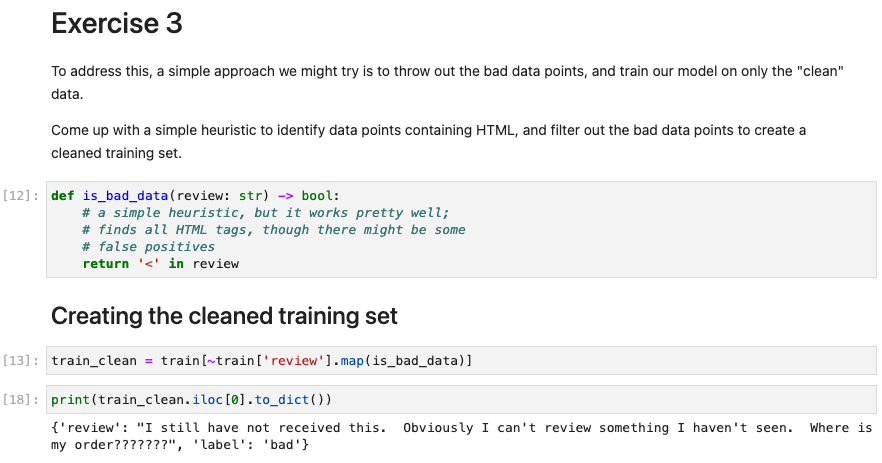
- Step 4: improved된 dataset으로 ML 실험 다시! (97%로 약 20%로 성능 향상!)
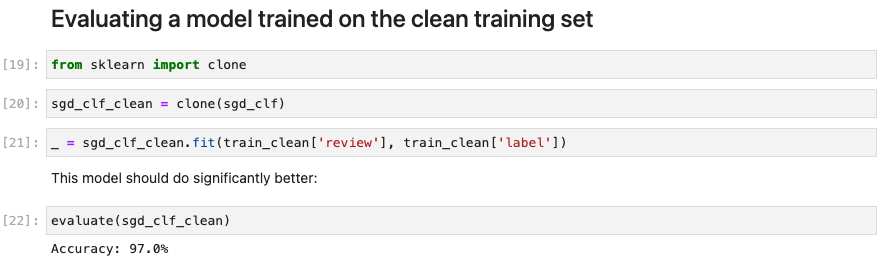
- Step1: 데이터 확인 후 issue 쳌쳌 (HTML에서 그냥 긁어온 애들은 상태가 별로 안좋아보임)
Review
-
좋은 점:
- Model-centric AI에 매몰되어있던 Ph.D 학생에게 새로운 시선을 안겨줘서 감사함.
- 가장 기본이 되는 것인데도, 이를 소홀히 했던 것에 반성.
- 정말 간단한 방법으로 성능 개선 효과를 즉각적으로 올릴 수 있다는 것이 신선.
- 내 연구를 할 때에도 데이터 전처리 시 정제만 했지 데이터 개선을 하려고 생각을 못한 것 같음!!! 또한, 모델 구조가 영향을 미치는 것만 확인하지 데이터가 모델에 어떻게 얼마나 영향을 미치는지 덜 확인하는 편. step3 과정을 철저히 하는 것이 필요하겠음!
-
아쉬운 점:
- 없음!
