Syllabus
- Introduction
- Data-Centric AI vs. Model-Centric AI
Label Errors- Dataset Creation and Curation
- Data-centric Evaluation of ML Models
- Class Imbalance, Outliers, and Distribution Shift
- Growing or Compressing Datasets
- Interpretability in Data-Centric ML
- Encoding Human Priors: Data Augmentation and Prompt Engineering
- Data Privacy and Security
Introduction
page: https://dcai.csail.mit.edu/lectures/label-errors/
Youtube: https://www.youtube.com/watch?time_continue=1&v=AzU-G1Vww3c&embeds_euri=https%3A%2F%2Fdcai.csail.mit.edu%2F&feature=emb_logo
Lab: https://github.com/dcai-course/dcai-lab/blob/master/label_errors/Lab%20-%20Label%20Errors.ipynb
What we've learnt?
- Model-Centric AI Vs. Data-Centric AI
- Model-Centric AI: 정제된 데이터셋을 가지고 최고의 모델 성능을 내기 위해 다양한 모델 기반 기술들 사용
- Data-Centric AI: How to systematically engineer data to build better AI system
- Data-centric pipline:
- Step 1: Explore the data, fix fundamental issues, and transform it to be ML appropriate. (데이터가 있으면, 일단 탐색해보고 ML에 맞게 변형을 한다!)
- Step 2: Train a baseline ML model on the properly formatted dataset. (변형된 데이터를 가지고 일단 ML 실험을 돌려봐)
- Step 3: Utilize this model to help you improve the dataset (모델을 개선하기 전에 data-centric ai 기술을 적용해서 여러 실험을 돌려봐라!)
- Step 4: Try different modeling techniques to improve the model on the improved dataset and obtain the best model. (3단계에서 개선된 데이터셋을 가지고 이제는 모델링 기술들을 적용해서 실험해봐라!)
신신당부: 절대 2단계에서 4단계로 뛰어넘지 말고, 좋은 시스템 구축을 위해서 3-4단계를 반복해라!
What we are going to learn?
-
Confident Learning:
- 1) identify label issues/errors/
- 2) characterize label noise
- 3) learn with noisy labels automatically
open-source: Cleanlab
What is Confident Learning?
Examples of Label issues in ImageNet

- 1) Multi-label images (blue): 하나의 이미지에 1개 이상의 라벨이 붙어있는 경우
- 2) Ontological issues (green): (예측) is-a (정답) / (정답) has-a (예측) 관계
- 3) Label errors (red): 라벨 자체가 다른 라벨과 더 잘맞아서 다른 예측을 한 경우 (== 예측이 정답보다 더 합리적)
- ImageNet의 training set에서 label error 있는 데이터 찾음.
- Amazon Reviews, MNIST, and Quickdraw datasets

- ImageNet의 training set에서 label error 있는 데이터 찾음.
Confident Learning (CL)
- Goal: (한마디로! 라벨 잘못된 애들 찾기!)
- characterize label noise
- find label errors
- learn with noisy labels
- find ontological issues
How does Confident Learning Work?
The Principles of Confident Learning
- Pruning noisy data (<-> fixing label errors or modifying the loss function)
- Counting to estimate noise (<-> jointly learning noise rates during training)
- Ranking examples to train confidence (<-> weighting by exact probabilites)
: SVM과 같은 의사결정 모델 결과에 기반해서 훈련 중에 사용할 데이터 순위를 매긴다.- Theoretical Findings in Confident Learning
=> paper: https://arxiv.org/pdf/1911.00068.pdf
sorry 요..
- Theoretical Findings in Confident Learning
CL methods (코드에서 보면 더 이해 쉬움)
- objective: 예측 (noisy) 라벨과 ground truth (latent) 라벨 간의 joint distrubution을 예측
- input:
- 1) out-of-sample predicted probabilities (matrix size: # of examples by # of classes)
- 2) noisy labels (vector length: number of examples)
- train Framework
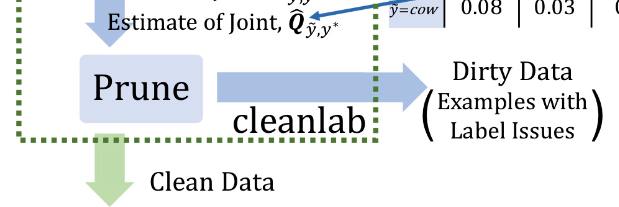
- 1) Estimate the joint distribution of given, noisy labels and latent (unknown) uncorrupted labels to fully characterize class-conditional label noise.
- 2) Find and prune noisy examples with label issues.
- 3) Train with errors removed, re-weighting examples by the estimated latent prior.
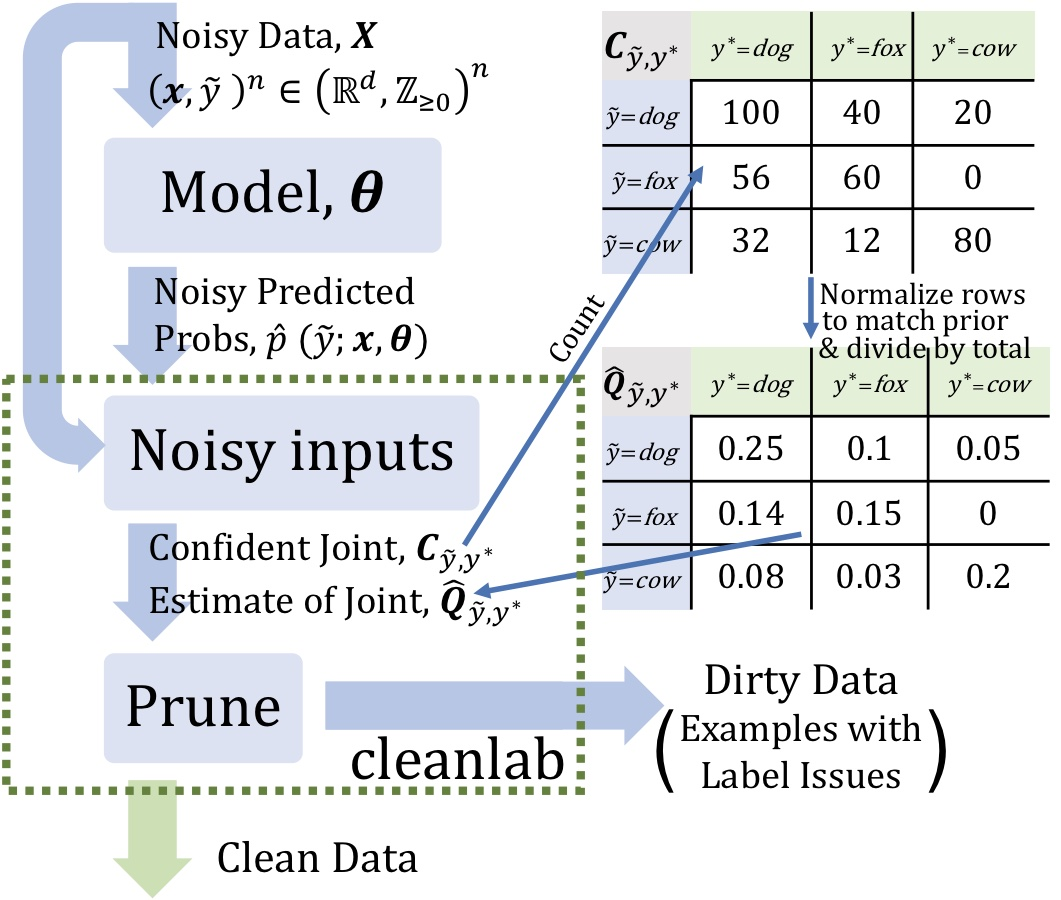
Out-of-sample predicted probabilities?
- Predicted probabilities: 정확한 라벨을 가진 데이터로 훈련된 모델들의 probabilistic estimation을 뜻함. 보통 우리는 multi-class classification을 한다고 하면 가장 높은 확률값을 가진 라벨을 예측값으로 선택!
- Out-of-sample: training 할 때 없었던 데이터들에 대한 probabilistic prediction. (ex. test set)
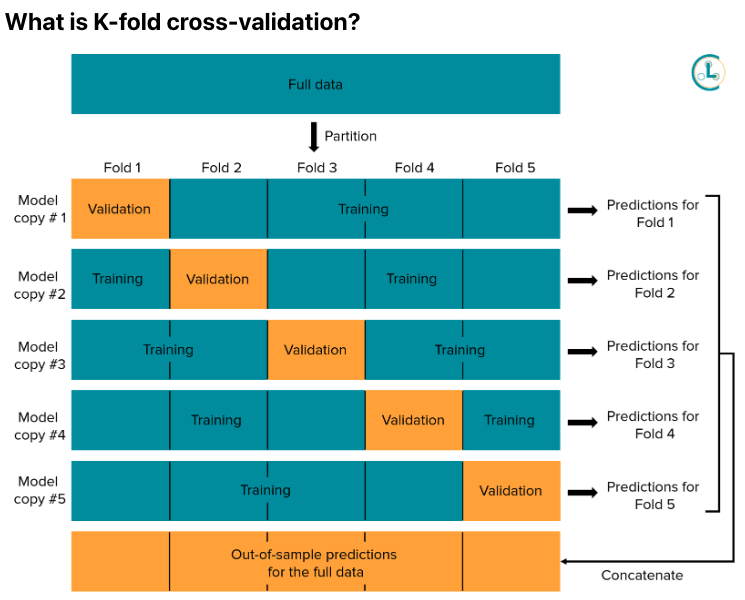
- K-fold cross-validation 이용해서 out-of-sample predicted probabilities for every datapoint 생성할 수 있음!
Practical Applications of Confident Learning
-
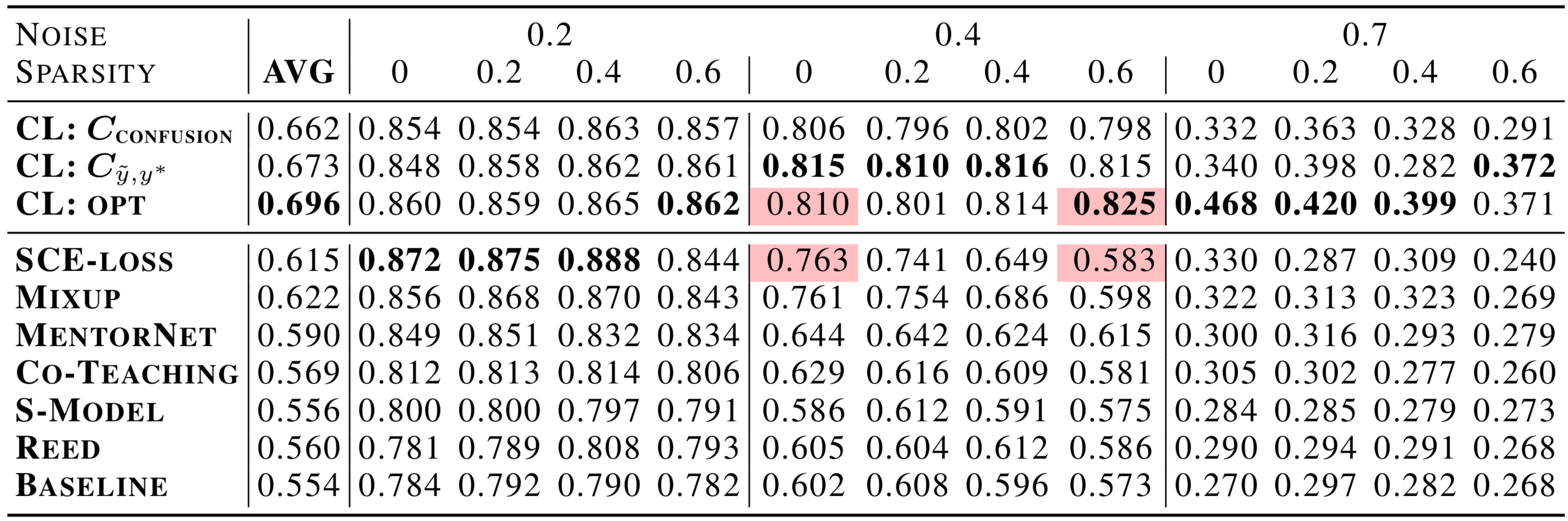
CL Improves State-of-the-Art in Learning with Noisy Labels by over 10% on average and by over 30% in high noise and high sparsity regimes
-
Training on ImageNet cleaned with CL Improves ResNet Test Accuracy
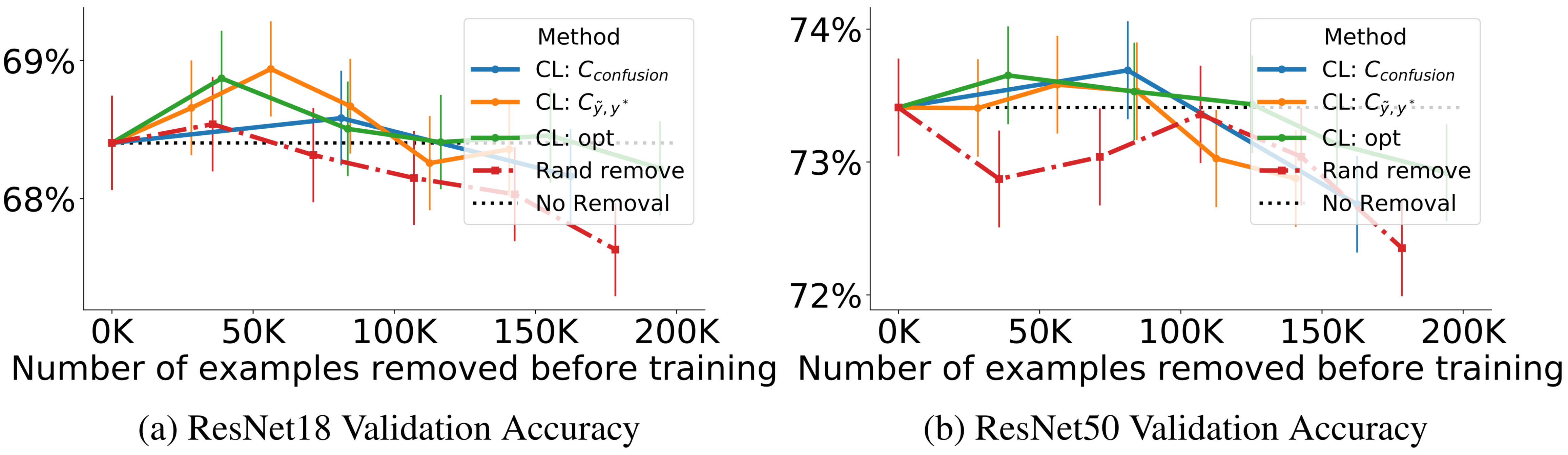
-
Good Characterization of Label Noise in CIFAR with Added Label Noise

-
Automatic Discovery of Onotological (Class-Naming) Issues in ImageNet

Conclusion
Benefits of Confident Learning
- 다양한 label issue를 탐지하여 모델은 cleaned dataset으로 학습될 수 있게 하여 성능을 높음
- Confident learning의 가장 큰 장점! 하이퍼파라미터가 필요가 없음! Cross-validation 사용해서 out-of-sample의 predicted probabilites도 바로 구할 수 있음.
- multi-class dataset에서도 굿! (multi-label dataset에도 확장할 수 있음)
- error를 확률 순서대로 쭉 나열해서 가장 그럴싸한 에러들 찾는 거 가능
- iterative하게 구하는게 아니라서 속도가 빠름. ImageNet 다 찾는데 3분밖에 안걸림
- theoretically하게 입증된 것임.
- randomly uniform label noise 있다고 가정하지 않음. 이런 가정은 practice에 맞지 않은 경우가 있음.
- 어떤 모델도 다 사용가능하고, predicted probabilities and noisy labels 이거 두개만 있으면 됌!
- noisy한 라벨에 대해서 ground truth라벨이 필요하지 않음!!!
- open-source도 있음 (cleanlab)
Future work:
- understanding of uncertainty estimation in dataset labels
- methods to clean training and test sets
- approaches to identify ontological and label issues in datasets
Lab
Setting
-
Goal: to train a model to classify the grade for each student based on the other features. (+하이퍼파라미터 튜닝이 초점이 아니고 데이터 자체를 개선하는 것!)
-
Task
- [Task 1] Establish a baseline XGBoost model accuracy on the original data
- [Task 2] Automatically mislabeled 데이터 찾기
- 1) Computing out-of-sample predicted probabilities (표본 외 예측 확률 계산)
- 2) Estimating the number of label errors using confident learning
- 3) Ranking errors, using the number of label errors as a cutoff in identifying issues
- [Task 3] Remove the bad data
- [Task 4] 정제된 데이터를 가지고 똑같은 XGBoost 모델 다시 돌려서 성능 확인
-
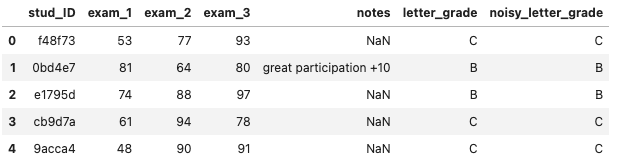
Dataset
- Features: 3과목 점수, written note
- label: 20% incorrect하게 설정해 놓음(
noisy_letter_grade). ground truth label (letter_grade)은 evaluation 때만 사용하고 training 땐 사용 안함!
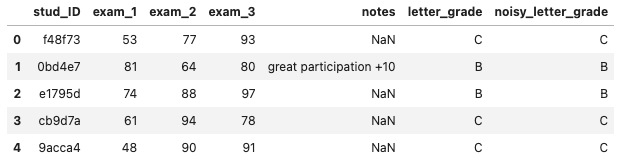
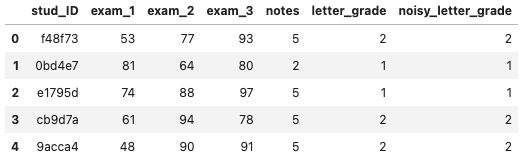
- encoding
Code
- getting out-of-sample predicted probabilities

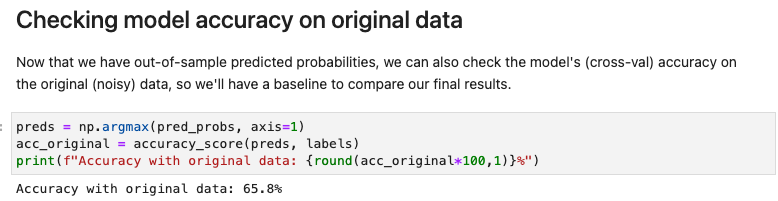
- Finding label issues automatically
: label issue counting 해야 함.
- a) computing class thresholds
각 class별 threshold는 각 class별 모델의 confidence가 된다. 실제 정답을 맞춘 data point들의 predicted probability 이용해서 주로 어느 정도의 확률로 정답을 맞추는지 평균을 구해야한다! (예를 들어!, cow 라벨이 가장 높게 나왔는데 확률값이 0.4밖에 안됌. train된 애들은 보통 0.5이상인데)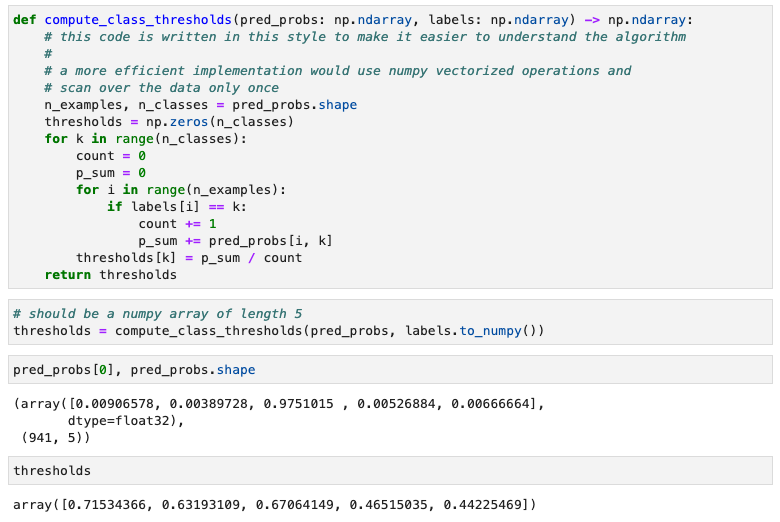
- b) constructing the confident joint
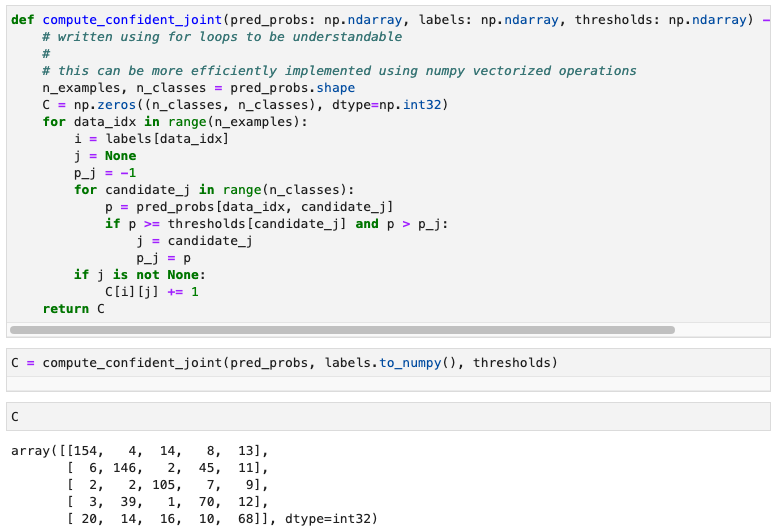
- c) count the number of label issues

numpy.trace() : Return the sum along diagonals of the array.
=> 여기선 true positive!
num_label_issues는 총 틀린 애들 갯수
- filter out label issues
- a) compute the model's self-confidence
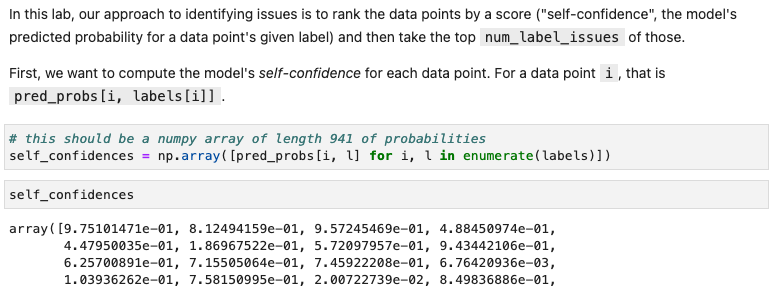
- b) Rank the indices of the data points

- c) compute the indices of label issues
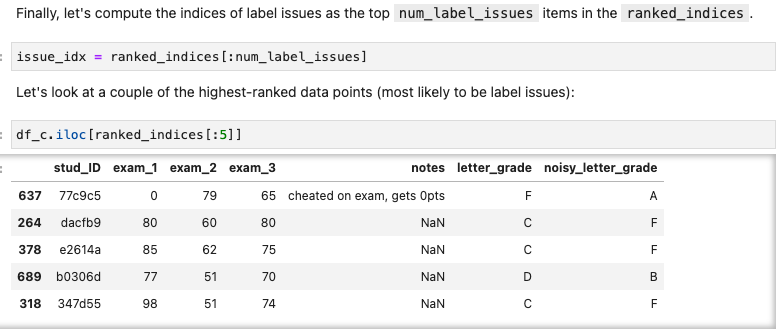
- d) 결과
본 lab 방식대로 했을 때 전체 오류의 77퍼센트를 잡을 수 있었음

- Train a More Robust Model
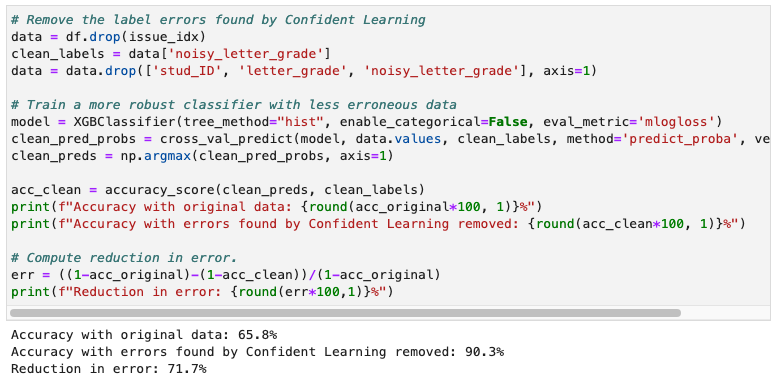
- error-rate를 70퍼센트 가량 감소시켰다는 뜻! 짱신긔~!
reduction in error
오류의 비례 감소는 독립 변수 x를 아는 것으로부터 종속 변수 y를 예측하는 정확도의 이득입니다. 통계 모델의 적합도 측정이며 여러 상관 계수에 대한 수학적 기초를 형성합니다.
- open source - cleanlab
한방에 해결!

Review
- 좋은 점
- 왜 그렇게 우리가 모델 검증을 할 때 많은 baseline을 해봐야하는 지 더 몸소 체험하며 알았다!!!!! 더하여 다른 데이터셋으로도 실험을 해보는 것이 중요한 것도 알았다.
1) 데이터셋에 오류가 많아 성능 자체가 낮다면 다른 모델들로도 다 실험을 해서 평균적으로 성능이 낮다는 것을 확인 시켜주는 게 필요
2) 해당 모델이 실험에 쓰인 데이터셋에만 특화되어 있어서 다른 데이터셋에는 작동을 잘 못할 수 있으니 실험 이외의 benchmark 데이터셋으로도 실험해보면 우리 모델이 더 robust하다는 걸 알 수 있음. 데이터 자체가 안좋은데 거기에만 overfitting 되어있으면 망하는 거구만~~~
- 왜 그렇게 우리가 모델 검증을 할 때 많은 baseline을 해봐야하는 지 더 몸소 체험하며 알았다!!!!! 더하여 다른 데이터셋으로도 실험을 해보는 것이 중요한 것도 알았다.
- 스스로에게 아쉬운 점
- 첫번째 class 처럼 가볍게 할 수 있을 줄 알고, 3개까지는 해봐야지 했는데..... 여기서 논문을 읽어야 더 도움이 되는 걸 알아버렸다... 하지만 시간이 한정되어서 가볍게 훑고가는 식밖에 안되었다! 하지만! 나의 목표는 전체 9개 클래스를 다 훑는 거기 때문에 스피디하게 가보겠다.
- 스터디원들에게 궁금한 점
이러한 내용이 도움이 되는 것 같나요? 그렇다면 계속하고, 아니라면 논문 읽기로 바꾸겠습니다!

4개의 댓글

데이터를 직접 구축한 경험들이 있었는데 성능이 잘 나오지 않을 때마다 '아 어노테이션을 다시 해야 되나 ?'라는 생각만 했던 것 같습니다 오늘 소개해주신 Data-Centric AI라는 접근법을 통해 noisy data를 처리해봐야겠어요 ! 감사합니다 ㅎㅎ

confident learning이라는 새로운 기술을 알게 되어 정말 흥미로웠습니다 ~! data가 정말 중요하군요 !! 앞으로의 발표도 기대가됩니다 ㅎㅎ

ChatGPT said:
Label errors can significantly impact the performance of AI models, especially when training data contains inconsistencies or mislabeled inputs. Interestingly, the concept of confident learning and data precision is also mirrored in tools like those at https://wordsofrizz.com/, where AI is used to generate context-aware pickup lines with high relevancy and accuracy. Just as confident learning filters out noise in data, these AI-generated lines aim to deliver charm without the cringe.
cleanlab이라는 오픈소스에 대해서 새롭게 알고 지금까지 와는 다른 방향으로 생각을 전환해볼 수 있는 신선하고 좋은 기회였습니다!! 뒤의 강의들도 기대되네요 !!! 파이팅