Reference: [재작성] https://ratsgo.github.io/speechbook/docs/fe/mfcc
어떻게 MFCC를 만드는 가!
- Mel-Frequency Cepstral Coefficients(MFCC):
음성 인식이랑 관련없는 정보는 버리고 중요한 특질만 남겨놓은 액기스 feature! (액기스 일본말인가..?) - Framework
- 1) audio signal 입력 받음
- 2) 짧은 구간 (대부분 25ms)로 촵촵촵 나눠버림 => 이렇게 쪼개진 애들이 Frame!
- 3) 각 Frame에 푸리에 변환 (DFT)를 실시해서 각 frame마다 frequency 정보 추출 => 그 결과가 Spectrum!
- 4) Mel Filter Bank 필터 적용: 사람 말소리 잘할 수 있는 주파수 영역대만 집중할 수 있게 그 외에 애들은 저리가! (상대적으로 덜 촘촘히 분석)하게 하는 필터. => 이게 Mel Spectrum
- 5) mel spectrum에 로그를 취하고 Log-mel Spectrum!
- 6) log-mel spectrm에 inverse fourier transform (IDFT) 적용해서 주파수 -> time domain으로 변경
- 7) 짜잔! MFCC 나왔습니다~

질문: 그럼 audio signal에서 fourier 두번한거면 기존 signal은 time domain이란 건가... 그냥 raw를 바로 주파수로 바꾸는건가...?
MFCC는 인간 말소리를 인식하기 위해서 필요한 중요한 feautre임. 음성학, 음운론 전문가들이 도메인 지식을 활용해 공식화한 것. 오랜 시간동안 발전을 거듭해 위의 framework 탄생하였고 성능 또한 검증! 최근에는 뉴럴네트워크에 의한 피처 추출도 점점 관심을 받고 있지만, 로그 멜 스펙트럼이나 MFCC는 음성 인식 분야에서 아직까지 널리 쓰이고 있는 피처입니다.
(_감사합니당..!)
MFCC 구현 python implement
1. Raw Wave Signal
ref: https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
아 내가 정성스럽게 녹음했는데!! 못올려!!! 업로드가 안돼!!! 우씨!!
# m4a wav로 변환
# 안녕하세요, 성균관대 디세일 연구실 최고입니다.
from pydub import AudioSegment
m4a_file = '/home/dsail/daeun/_SKKU/ASRstudy2024/Asr.m4a' https://getsamplefiles.com/sample-audio-files/m4a
wav_filename = '/home/dsail/daeun/_SKKU/ASRstudy2024/Asr.wav'
sound = AudioSegment.from_file(m4a_file, format='m4a')
file_handle = sound.export(wav_filename, format='wav')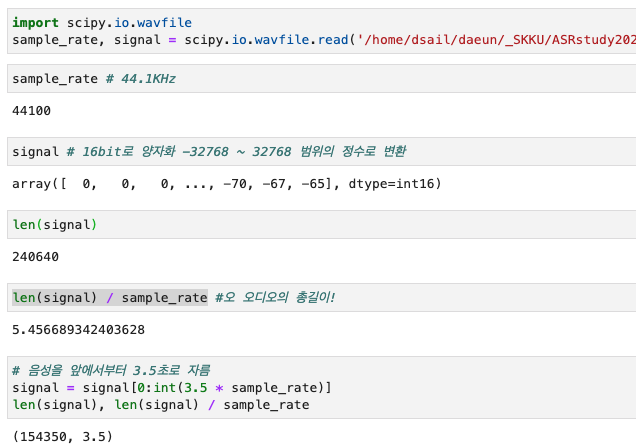
2. Preemphasis
-
high frequency energe 올려주는 전처리 과정
-
수식:
- t번째 시점의 raw signal x_t를 이전 단계의 raw signal에 preemphasis coefficient 랑 곱해줌. (는 보통 0,95, 0.97)
-
효과
-
사람 말소리 spectrum을 보면 보통 고주파보단 저주파가 우세. so, 고주파 성분 에너지 올려주면 음성 인식 모델 성능 개선할 수 있다함 => 상대적으로 에너지가 적은 고주파 성분을 강화함으로써 raw 음성 신호가 전체 주파수 영역대에서 비교적 고른 에너지 분포를 갖도록 함.
질문: (저주파가 우세하면... 저주파를 봐야하는거 아냐..? 컴퓨터가 알아듣기 쉬울려면 고주파도 있어야하는거야..??? 고른 에너지를 갖고있는게 중요한가? 한쪽에 치우쳐서 골고루 인식 못하나..?)
고주파 자체가 에너지가 낮다 => 소리가 작다 => 그럼 asr 인식하기 어렵다, 그래서 얘도 잘 들리게 균형을 맞춰주려고 하는거 아닐까?? -
푸리에 변환시 발생할 수 있는 numerical problem 예방. (idk..)
-
Signal-to-Noise Ratio(SNR) 개선. (idk..)

-
3.Framing
- 푸리에 변환하기 전에 아주 짧은 시간 단위로 잘게 쪼개기
- 음성신호가 너무 길면 너무 빨라서 (non-stationary) 주파수 정보 캐치하기가 어렵고, 주파수 정보가 뭉뚱그려져 버림. 그래서 stationary하다고 느낄만큼 잘게잘게 쪼개버리자!!
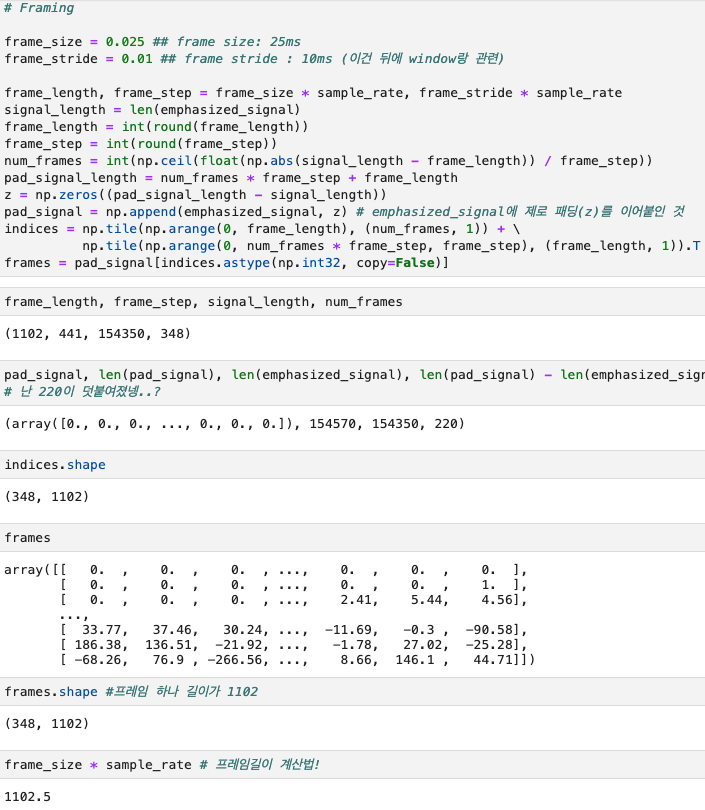
Windowing
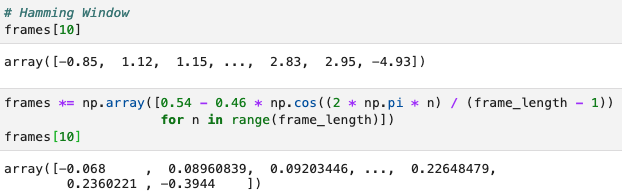
- Windowing: 각 프레임에 특정 함수 적용해 경계 스무딩 (e.g. Hamming Window)

- 프레임 중간에 있는 값들은 1 곱해서 유지, 양 끝은 0에 가까운 값 곱해서 축소
- Windowing 하는 이유
- square wave:
- rectangualr window로 framing한 애들을 양 끝에 신호가 갑자기 죽는 (???) 상황이 발생하는데, 이 상태에서 푸리에 변환하면 불필요한 high frequency 가 남아버림.
- 그래서 양 끝 쪽을 smoothing 시켜줌
=> 그래서 앞에서 windowing을 하는구나 fadein out

- square wave:
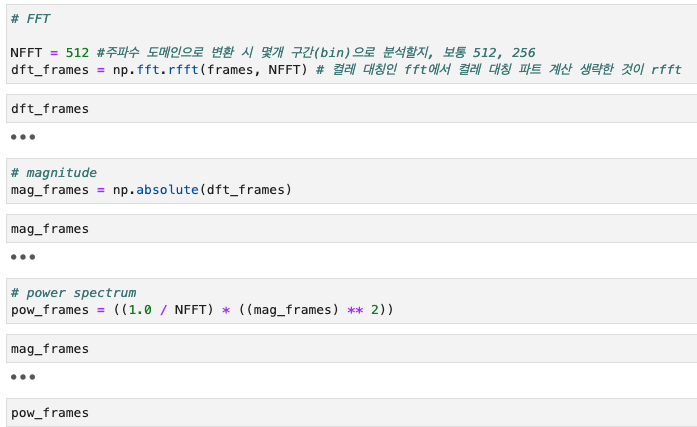
Fourier Transform
- 푸리에 변환: Time domain 음성 신호 -> Frequency domain 음성신호 변환
- 이산 신호에 대한 푸리에 변환 (Discrete 푸리에)

Magnitude
- k번째 주파수 bin의 이산 푸리에 결과:
- j: 허수 (제곱하면 -1)
- 진폭(magnitude): 주파수 성분 크기
- 위상(phase): 해당 주파수의 (복소평면상 단위원상) 위치

뭔 말인지 모르겠음.
어쨌든, 이를 통해 "MFCC를 구할 때는 음성 인식에 불필요한 위상 정보는 없애고 진폭 정보만을 남깁니다." 라고 함.
Power Spectrum
- 진폭을 구하든 파워를 구하든 복소수 형태인 이산 푸리에 변환 결과는 모두 실수(real number)로 바뀝니다
Filter Banks
-
filter banks: 사람말 잘 알아들을 수 있는 저주파수 영역대 세밀하게 관찰
-
멜 스케일(Mel Scale) 필터
-
주파수(f, 헤르츠/Hz) <=> 멜(m, 멜/mel) 변환
"수식5, 코드9는 보기만 해도 머리가 아픈데요. 일단은 그렇구나 하고 바로 다음으로 넘어갑시다." (정말 반가운 소리입니다!)

쉬운 설명!
fbank가 필터인데,얘를 기존의 pow_frame에 내적해버리는 거임!
- fbank[0]: 저주파 영역대 세밀하게
- fbank[39] : 고주파 영역대 세밀하게
0번은 나머지는 다 0이고 앞에만 1, 39는 나머지 다 0이고 뒤에만 숫자있음. 그럼 저 숫자 써있는 곳만 보고 나머지는 무시한다는 거임! 어디를 살펴볼지 가중치!!

- numerical stability:
필터 뱅크 수행 결과가 0인 곳에 작은 숫자를 더해줘서 numerical problem을 예방
filter_banks = np.dot(pow_frames, fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks)Log-Mel Spectrum
- 사람의 소리 인식은 로그(log) 스케일에 가깝다.
- which means, 사람이 두 배 큰 소리라고 인식하려면 실제로는 에너지가 100배 큰 소리여야 함.
filter_banks = 20 * np.log10(filter_banks) # dB
# 차원수: num_frames × nfilt 348 * 40Mel-frequency Cepstral Coefficients(MFCCs)
- 로그 멜 스펙트럼에 역푸리에 변환(Inverse Fourier Transform)을 수행해 변수 간 상관관계를 해소
- Because...
- feature 내 correlation 존재. 왜냐하면 주변 에너지 한데 모아 보기 때문..?
=> 헤르츠 기준 특정 주파수 영역대 에너지 정보가, mel (or log) spectrum의 여러 차원에 영향을 준다.
=> 앗 그렇다면 mfcc가 변수 간 independence 가정하고 모델링하는 Gaussian Mixture Model 입력으로 쓰인 댔는데, 이거는 치명적인걸!
- feature 내 correlation 존재. 왜냐하면 주변 에너지 한데 모아 보기 때문..?
상관관계 너무 복잡하면 독립성 유지시키려고 나이브베이지안 하는거임. 근데 푸리에변환하면 amplitude, frequency, time domain 사이에 종속성이 생기게 되어버림!!그래서 역푸리에 해가지고 새롭게 나온 값은 가지고 오지만 domain은 독립적으로 만든다!!
역푸리에 변환을 하면 가로축이 time,
amplitude값 자체를 독립적으로!
대표값을 다시 역변환 하면 frequency 포함했지만 변환
고유값 추출 특성 자체를 추출할 수 있어서 푸리에변환 같은거 가넝한것이다 오오오오~~
from scipy.fftpack import dct
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1 : (num_ceps + 1)] # Keep 2-13- 이 행렬 가운데 2-13번째 열벡터들 만 뽑아서 최종적인 MFCCs 피처로 사용
- 이외 주파수 영역대 정보들은 만들 때마다 워낙 빠르게 바뀌어 시스템 성능 향상에 도움 X.
"멜 스펙트럼 혹은 로그 멜 스펙트럼 대비 MFCCs는 구축 과정에서 버리는 정보가 지나치게 많습니다. 이 때문인지 최근 딥러닝 기반 모델들에서는 MFCCs보다는 멜 스펙트럼 혹은 로그 멜 스펙트럼 등이 더 널리 쓰이는 듯 합니다."
Post Processing
- MFCCs 입력는 음성 인식 시스템 성능 향상 위한 후처리
- Lift (MFCCs에 적용)
(nframes, ncoeff) = mfcc.shape cep_lifter = 22 n = np.arange(ncoeff) lift = 1 + (cep_lifter / 2) * np.sin(np.pi * n / cep_lifter) mfcc *= lift - Mean Normalization (mel or log-mel 스펙트럼에 적용)
filter_banks -= (np.mean(filter_banks, axis=0) + 1e-8) - 등
- Lift (MFCCs에 적용)
후기
우와!!!! 진짜 꼼꼼하게 봐서 쏙쏙 이해된다!! 좋다!!!
