Speech (ASR/TTS)
1.[Speech] Automatic Speech Recognition Overview

Reference: [재작성] https://ratsgo.github.io/speechbook/docs/introduction Problem Setting 자동 음성 인식(Automatic Speech Recognition)이란 음성 신호(acoustic signal
2.[Speech] Acoustic Phonetics

Reference: [재작성] https://ratsgo.github.io/speechbook/docs/phonetics/acoustic Wave 웨이브(wave, 파동)이란 반복적으로 진동(oscillate)하는 신호(singal)를 의미합니다. 하나의 웨이브인 단
3.[Speech] Feature Extraction- Fourier Transform
Reference: [재작성] https://ratsgo.github.io/speechbook/docs/fe Fourier Transform Discrete Fourier Transform 푸리에 변환(Fourier Transform)이란 시간(time)에 대한 함수
4.[Speech] Feature Extraction - MFCCs
Reference: [재작성] https://ratsgo.github.io/speechbook/docs/fe/mfcc 어떻게 MFCC를 만드는 가! Mel-Frequency Cepstral Coefficients(MFCC): 음성 인식이랑 관련없는 정보는 버리고 중요
5.[Speech] Korean Phonology
Reference: [재구성] https://ratsgo.github.io/speechbook/docs/phonetics/phonology/cnv 이건 너무 많아서... 어찌 정리할까 고민이 되었지만! 지금하는 연구에서 언어장애 환자들의 특징을 좀 카테고리화 해볼 수
6.[ASR]SincNet: Speaker Recognition From Raw waveform with SincNet
paper:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8639585&tag=1code:관련 자료: https://velog.io/@gyfla1512/ASR-Study-Paper.-SPEAKER
7.[ASR] Baum-Welch algorithm
Reference: https://velog.io/@pass120/ASR-basic-Baum-Welch-algorithmhttps://ratsgo.github.io/speechbook/docs/am/baumwelch은닉마코브모델 학습에 사용되는 알고리
8.[ASR] 은닉마코프모델(Hidden Markov Models)
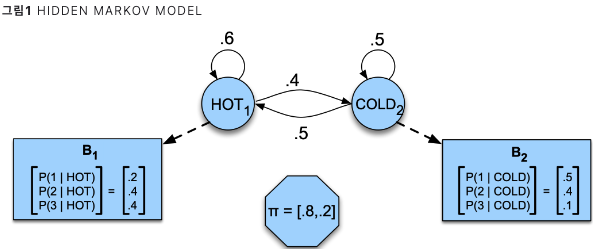
https://ratsgo.github.io/speechbook/docs/am/hmm (재작성)https://hyungjung-lee.github.io/ai-ml/hidden-markov-chain/https://ratsgo.github.io
9.[ASR]wav2vec: Unsupervised Pre-training for Speech Recognition (2019)
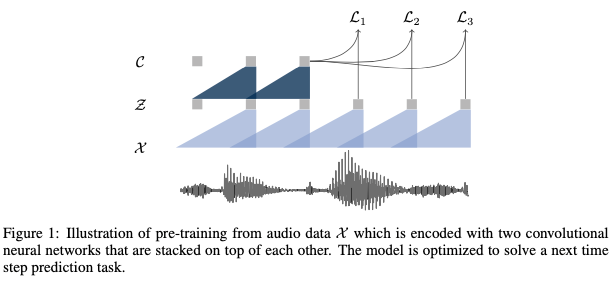
paper: https://arxiv.org/pdf/1904.05862.pdfcode: https://github.com/facebookresearch/fairseq참고 blog: https://asidefine.tistory.com/240C
10.[ASR]PASE: Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks & PASE+
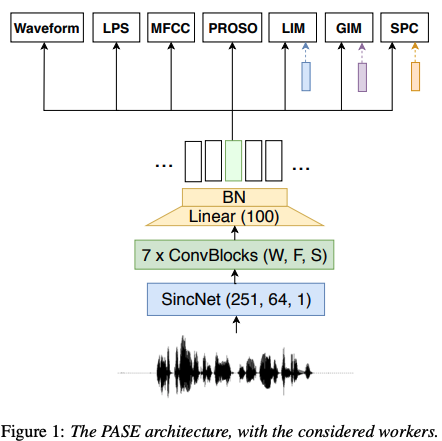
paper: PASE, PASE + > code: https://github.com/santi-pdp/pase > Reference: https://ratsgo.github.io/speechbook/docs/neuralfe/pase PASE 1. Introductio
11.[ASR] Gaussian Mixture Model
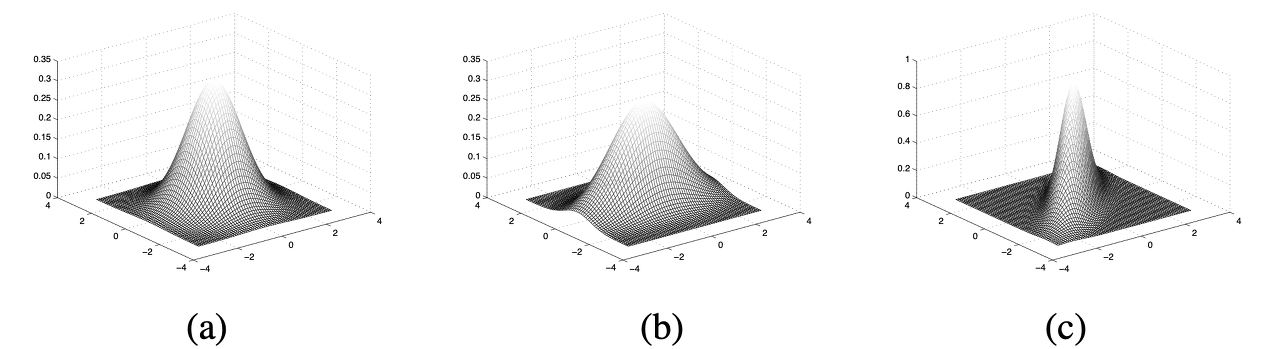
https://ratsgo.github.io/speechbook/docs/am/gmm 보고 다시 재정리ref: https://hyunlee103.tistory.com/56HMM은 likelihood, decoding, learning 3단계로 구성이
12.[ASR]Listen, Attend and Spell (2015)
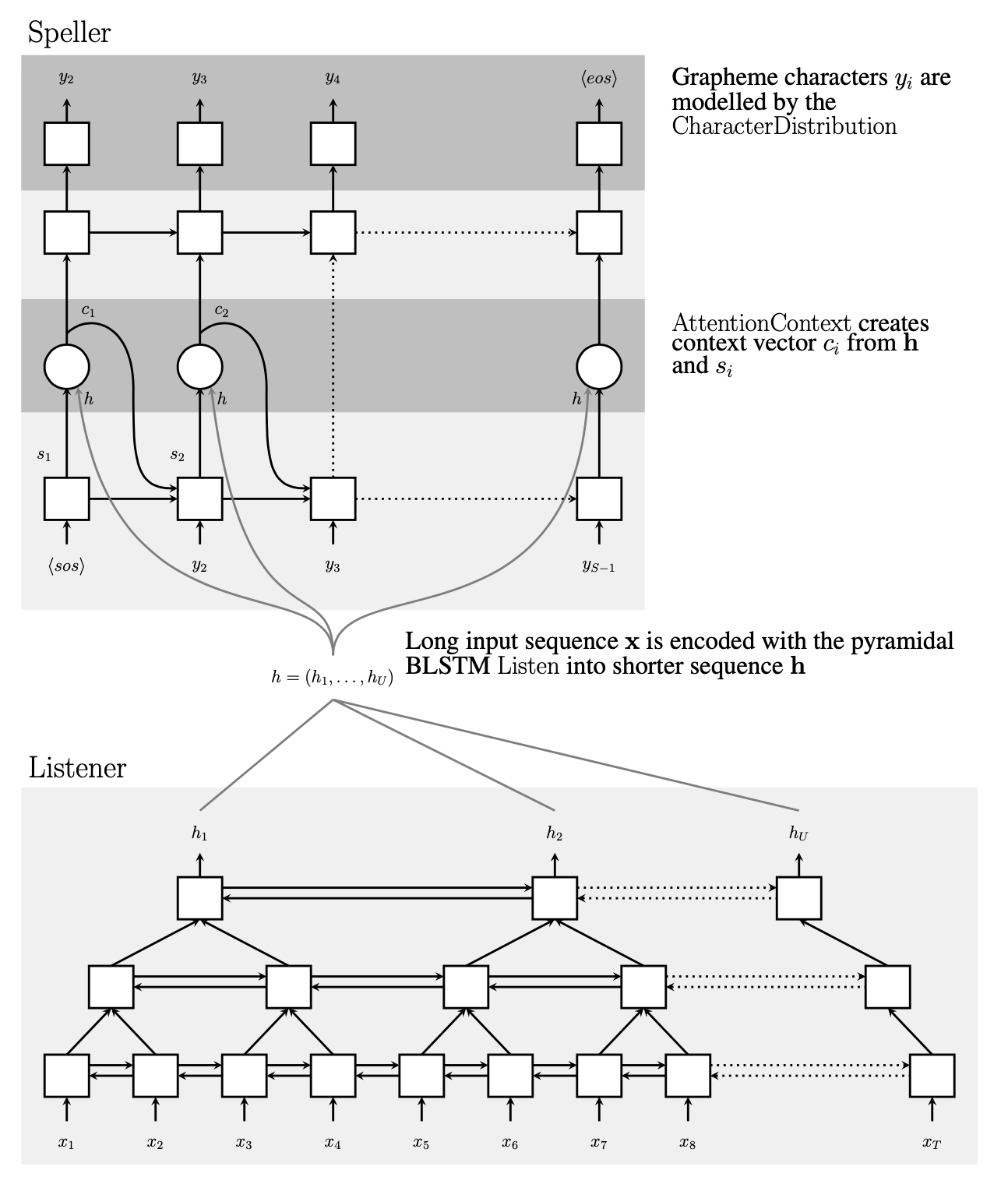
https://hyungjung-lee.github.io/ai-ml/listen-attend-and-spell/LAS는 HMM 기반 기존 음성 인식 시스템과 달리 END-to-end연산. 거의 최초! 오Speller, listenerhidden state로 연
13.[ASR] Speech Model Pre-training for End-to-End Spoken Language Understanding
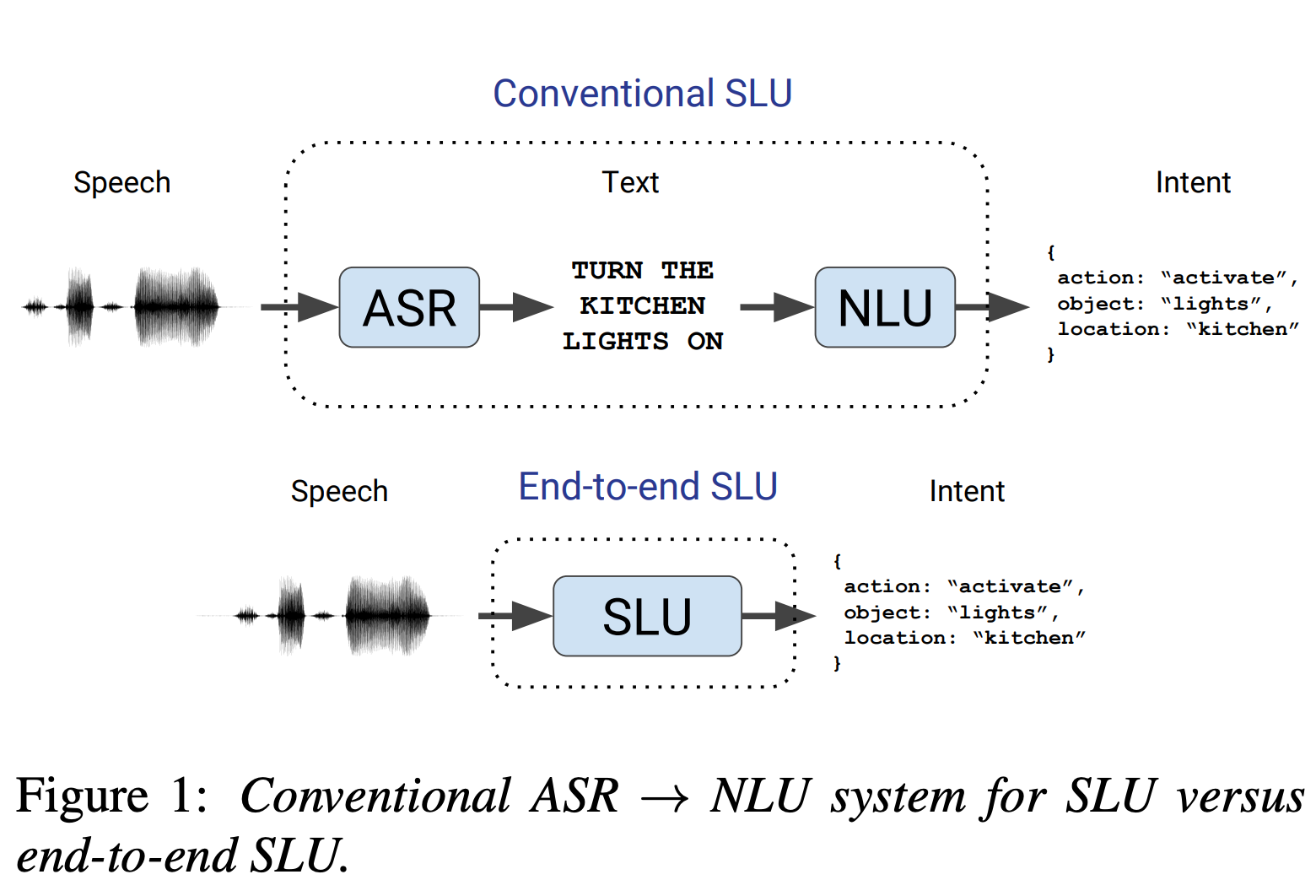
ref: https://hyungjung-lee.github.io/ai-ml/end-to-end-slu/Spoken Language Understanding
14.[TTS] Viterbi Algorithm
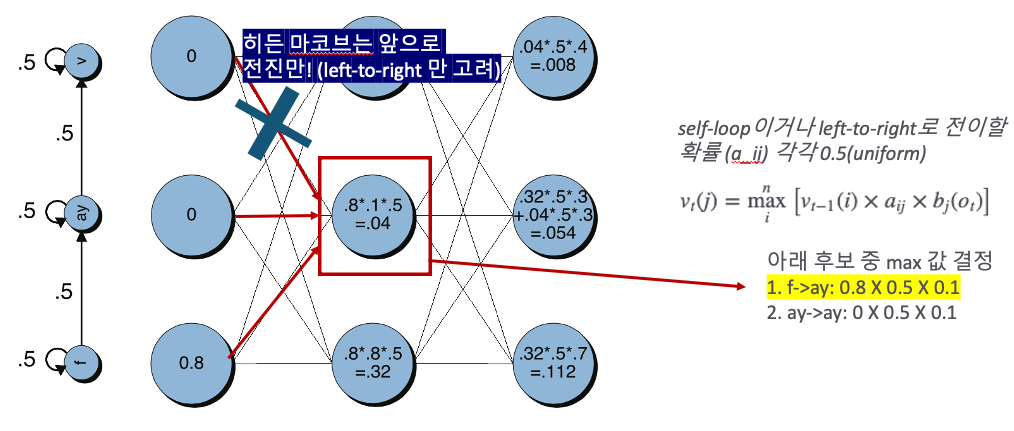
https://ratsgo.github.io/speechbook/docs/decoding/viterbi음성 인식 모델이 디코딩한 결과를 평가WER은 모델 예측 결과와 정답 사이의 단어 수준 편집거리(edit distance)를 수치화.예측과 정답이 같을 수록
15.[TTS] Tacotron1, Tacotron2
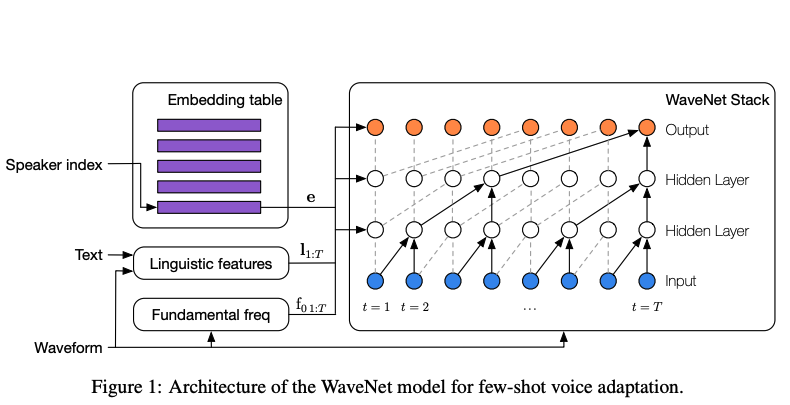
Tacotron: Towards End-to-End Speech Synthesis > paper: https://arxiv.org/pdf/1703.10135 > audio sample: https://google.github.io/tacotron/publication