배경지식
- 행렬의 내적
- 확률의 범위
딥러닝이란
딥러닝에 대해 살펴보겠다. 인공지능은 크게 머신러닝(Machine Learning)과 딥러닝(Deep Learning)으로 분류된다. 정확히는 머신러닝의 하위 분야로 딥러닝이 있다.
머신러닝은 인공지능의 하위 집합으로, 많은 양의 데이터를 제공하여 명시적으로 프로그래밍하지 않고 신경망과 딥 러닝을 사용하여 시스템이 자율적으로 학습하고 개선할 수 있게 해줍니다.
- Google Cloud
쉽게 말하면 인간이 하나하나 계산하고 정의해서 문제를 해결하는 것이 아니라 기계가 알아서 학습하는 게 머신러닝이다. 정확히 말하면 문제 해결법을 수학적으로 정의한다. 그런 뒤 컴퓨터가 반복 연산을 하며 수식을 푸는 것이다.
딥러닝은 머신러닝 분야 중, 인공신경망을 이용해 문제를 해결하는 것이다. 인공 신경망은 다양하고 복잡한 구조로 발전했다. 최근 핫한 ChatGPT, AlphaGo, HyperClovaX 등이 모두 딥러닝을 이용했다.
용어 정의
머신러닝: 많은 양의 데이터를 제공하여 명시적으로 프로그래밍하지 않고 시스템이 자율적으로 학습하는 알고리즘딥러닝: 머신러닝의 하위 분야로, 인공신경망을 이용해 학습하는 알고리즘모델: 알고리즘 또는 미리 정의된 일련의 단계를 사용하여 태스크를 수행하도록 훈련된 컴퓨터 파일 (Amazon AWS)
딥러닝으로 이진 분류
이진 분류
이진(binary) 분류는 2종류의 카테고리를 가진 데이터를 분류하는 작업이다.
- 사진을 보고
개와고양이분류하기 - 색을 보고
레몬와사과분류하기
말 그대로 1번 아니면 2번으로 분류하는 작업이 이진 분류이다.
분류 문제의 레이블
예를 들어 오렌지와 자몽을 구분하는 문제를 푼다고 해보자. 그럼 데이터는 아래와 같이 구성되어 있다.
| 크기 (cm) | 파란 정도 (rgb) | 분류 |
|---|---|---|
| 3.91 | 3 | 오렌지 |
| 4.47 | 4 | 오렌지 |
| 4.78 | 2 | 오렌지 |
| 7.63 | 24 | 자몽 |
| 7.77 | 15 | 자몽 |
| 8.29 | 42 | 자몽 |
| ... |
데이터 출처: joshmcadams/oranges-vs-grapefruit
이 때 오렌지, 자몽 대신 모델이 계산할 수 있는 값으로 전달해주어야 한다. 분류 문제에서 레이블(label)이란 학습된 모델이 출력했으면 하는 기댓값을 의미한다. 학습의 관점에서 보면 정답 값이라고 볼 수 있다. 문제에 따라 다를 수 있지만 표준적으로는 0부터 1, 2, 3... 으로 레이블을 지정해준다. 위 문제의 경우 {오렌지:0, 자몽:1}로 레이블을 지정할 수 있다. 그럼 최종적으로 데이터는 아래와 같이 정리된다.
| 크기 | 파란색 정도 | 레이블 | 분류 |
|---|---|---|---|
| 3.91 | 3 | 0 | 오렌지 |
| 4.47 | 4 | 0 | 오렌지 |
| 4.78 | 2 | 0 | 오렌지 |
| 7.63 | 24 | 1 | 자몽 |
| 7.77 | 15 | 1 | 자몽 |
| 8.29 | 42 | 1 | 자몽 |
인공신경망
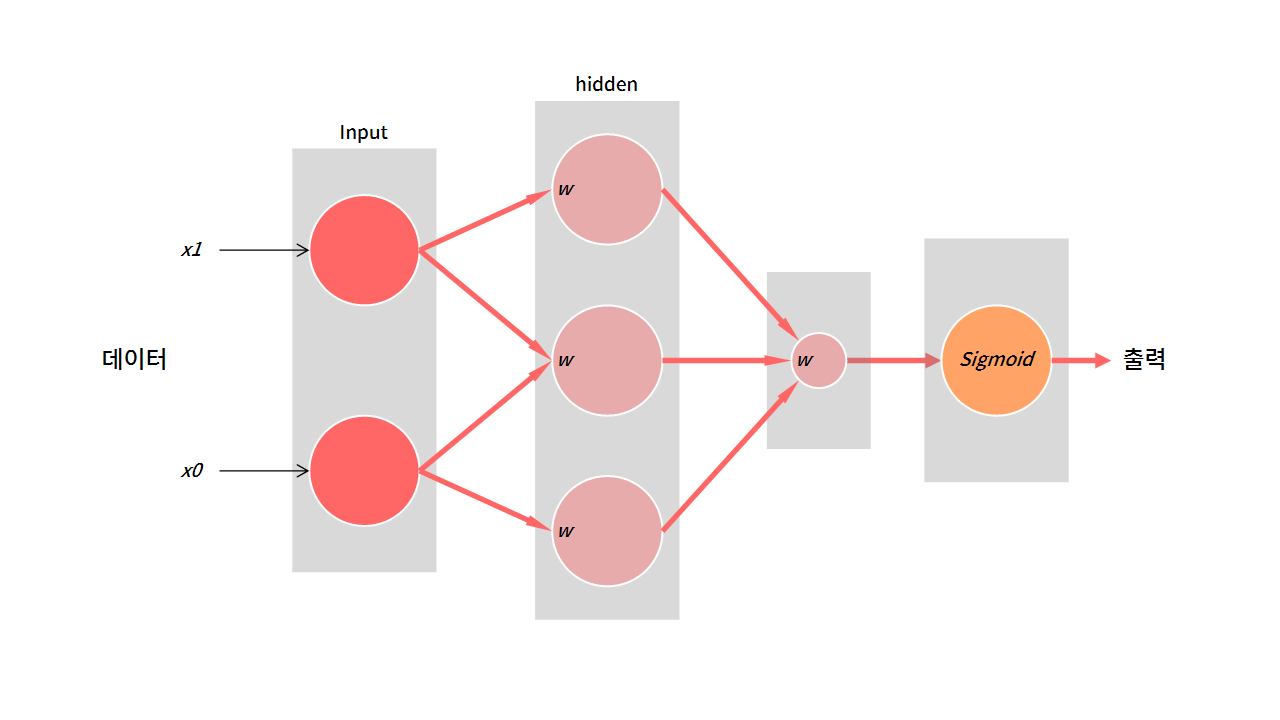
입력층 → (은닉층) → 출력층 → 결과
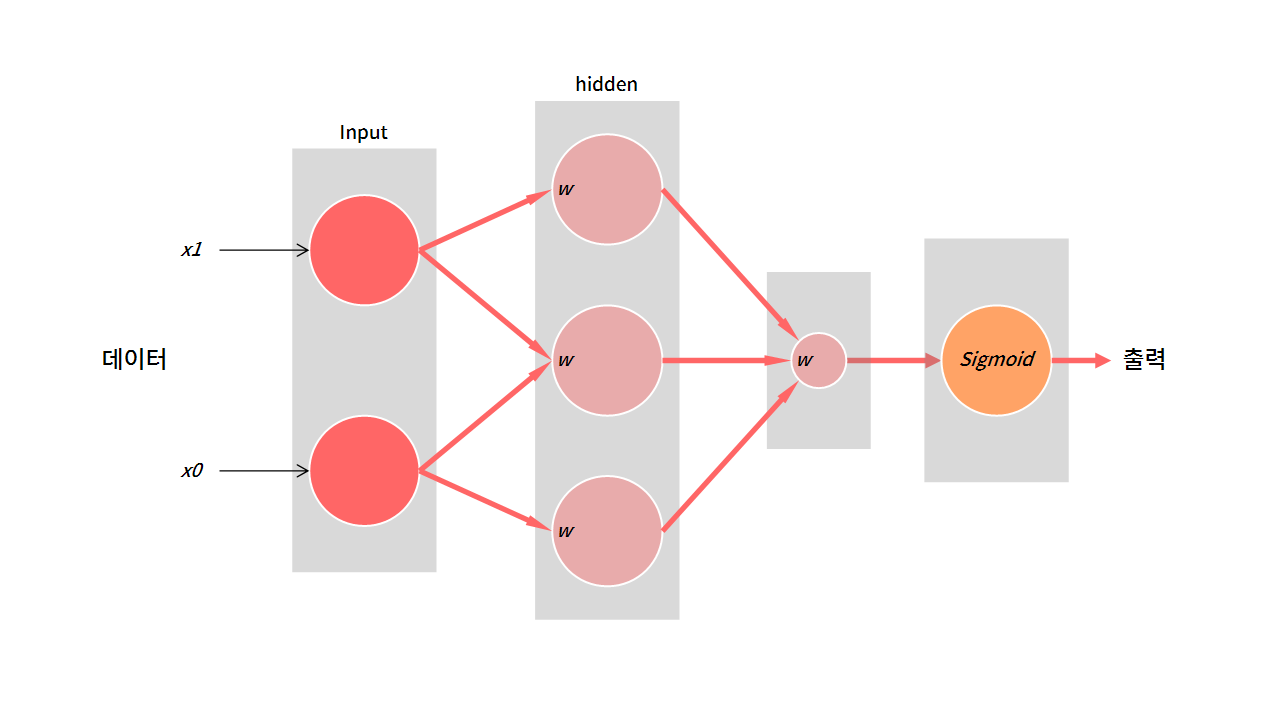
분류 문제를 푸는 기본적인 인공신경망의 구조다. 데이터를 입력받아 데이터에 특정한 연산을 수행한다. 그리고 그 값을 그림의 동그라미(노드)에 잠시 저장해둔다. 마지막에는 미리 정의해둔 함수를 거쳐 값을 출력하게 된다. 이 때 각 단계(회색 배경)를 층(layer)라고 한다.
연산 과정
가장 기본이 되는 모델은 은닉층에서 행렬의 내적을 계산한다.
출력 = 함수(입력 데이터 • 가중치 • 가중치 ... )
여기서 행렬의 크기를 이해해야 층(layer)을 자유롭게 쌓을 수 있다. 이거 지금 안 보면 후회한다.
데이터 개수를 N으로 일반화하면 아래와 같이 적을 수 있다.
| ID | 입력 | 출력 (logit) |
|---|---|---|
| 1 | [ ] | [ ] |
| 2 | [ ] | [ ] |
| 3 | [ ] | [ ] |
| ... | ||
| N | [ ] | [ ] |
- 데이터의 개수:
N - 데이터 특징의 개수:
d - 입력 크기:
N x d - 출력 크기:
N x 1
입력을 넣어 원하는 출력을 얻기 위해서는 중간중간 행렬의 크기가 어떻게 계산될지 잘 생각해야 한다.
위 그림에서 입력 데이터 • 가중치 연산을 정리해보면,
| Layer | 입력 행렬 | 가중치 행렬 | 출력 행렬 |
|---|---|---|---|
| hidden 1 | N x 2 | 2 x 3 | N x 3 |
| hidden 2 | N x 3 | 3 x 1 | N x 1 |
| sigmoid | N x 1 | - | N x 1 |
참고로, m x n과 n x k의 내적은 m x k을 결과값으로 가진다.
은닉층
가중치와의 내적을 통해 데이터가 N x 2 → N x 3 → N x 1로 변환된다. 모델을 통해 얻고자하는 결과는 확률 값이다. 따라서, N x 1의 형태로 각 데이터에 대하여 하나의 값이 나와야한다.
출력층
마지막에는 sigmoid 층을 거쳐 값이 출력된다고 했다.
| ID | 크기 | 파란색 정도 | 레이블 |
|---|---|---|---|
| 1 | 3.91 | 3 | 0 |
| 2 | 7.63 | 24 | 1 |
만약 위 데이터를 인공신경망에 보낸다고 하자.
| ID | 입력[크기, 파란정도] | 계산 결과 | 레이블 |
|---|---|---|---|
| 1 | [ 3.91, 3.0 ] | [ 2.31 ] | 0 |
| 2 | [ 7.63, 24.0 ] | [ -1.20 ] | 1 |
복잡한 계산을 거치고 나면 이쁘게 0이나 1로 출력되는 게 아닌 실수로 출력된다. 이 값은 logit이다.
logits
먼저, odds는 승산이라고 부른다. 실패 대비 성공 확률이다.
logit은 odds에 log를 취한 값으로 -∞ ~ ∞의 범위를 가진다. 이 값을 0 ~ 1 범위로 변환하면 확률이 된다. 이때 sigmoid를 사용한다.
sigmoid
sigmoid를 사용하면 logit을 0 ~ 1의 확률로 변환할 수 있다.
그 이유는 logit과 sigmoid가 역함수 관계이기 때문이다. 그리고 logit과 sigmoid의 관계를 N개의 레이블에 대해 일반화시킨 함수가 softmax이다. 자세히 다루기에는 이야기가 길어지니 생략하겠다.
정리하면,
logit: -∞ ~ ∞ 범위를 가지는 값. (유사 확률)sigmoid: logit을 0 ~ 1 범위의 확률값으로 변환. 이진(binary) 분류에서 사용.
Pytorch 모델 구현
코드는 아직 이해 못해도 괜찮다. 아래 출력 결과를 보자.
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self._hidden = nn.Sequential(
nn.Linear(2, 3, bias=False),
nn.Linear(3, 1, bias=False),
)
self._sigmoid = nn.Sigmoid()
def forward(self, x):
out = self._hidden(x)
out = self._sigmoid(out)
return out----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 30, 3] 6
Linear-2 [-1, 30, 1] 3
Sigmoid-3 [-1, 30, 1] 0
================================================================
Total params: 9
Trainable params: 9
Non-trainable params: 0
----------------------------------------------------------------예측한대로 잘 반환한다. Output Shape에서 -1은 batch size로 아직은 무시해도 된다. 가중치(Param)의 개수도 예측과 일치한다.
정리
딥러닝은머신러닝의 하위 개념으로인공신경망을 사용한다.인공신경망은입력층→ (은닉층) →출력층을 가진다.- 분류 문제에서는 정답에 대하여
label을 지정해야 한다. label은 일반적으로 { 0, 1, 2 ... }로 지정한다.- 은닉층에서
행렬의 내적이 발생하므로 크기를 잘 예측해야 한다. m x n과n x k의 내적은m x k이다.- 이진 분류에서
logit이sigmoid를 거치면확률이 된다.
