
오늘은 전에 다루기로 했었던 클러스터링 팩터, IO ACCESS 와 하드디스크에서 읽는 방법 , 버퍼캐시에 저장되는 과정 및 찾는 과정에 대해 다뤄보고자 한다.
😲데이터베이스 데이터 블럭 이해
먼저 전 시간에 다루었던 문제에 답을 달아보자
Q1) 그러면 백만개의 Record를 가지는 두개의 테이블의 검색속도는 동일할까?
앞에서 언급했던 IO 에서 기본단위는 데이터 블럭이며 이는 레코드의 갯수와 더불어 컬럼의 갯수가 많다면 그만큼 데이터 블럭을 많이 보내야 하므로 컬럼의 수가 많은 테이블이 검색속도가 더 느릴 것이다.
Q2) 백만개의 Record를 가지고 컬럼 크기와 값도 서로 동일한 두개의 테이블이 있을때 검색 속도는 동일할까?
이제는 컬럼과 레코드의 숫자가 같지만 또 생각해 봐야 할 점이 하이워터 마크(High Water Mark)이다.
이는 사용자가 테이블에서 DML 작업을 하게 되면서 논리적인 테이블 이외에 추가적으로 쌓이는 공간으로 어떤 테이블에서 DML 작업을 얼만큼 하냐에 따라서 IO가 많아질 것이다.
두번째로는 클러스터링 팩터(Clustering Factor) 이다. 사용자가 자주 검색하는 비슷한 값들이 얼마나 서로 모여 있냐에 따라서 엑세스 하는 블록 건수가 달라진다.
CF(클러스터링 팩터) 값이 테이블의 블락크기만큼 이면 효율이 좋은거고 레코드 크기만큼 이면 인덱스의 효과를 못보고 있는 것이다.
이때에는 인덱스의 정렬과 테이블의 정렬이 다른 경우인데 테이블의 정렬을 인덱스의 정렬에 맞춰주면 좋지만 다른 인덱스의 조건에 영향이 갈 수 있기 때문에 데이터를 바라볼때 단일 조건이 아닌 다양한 조건 검색을 염두에 해 두고 구조를 설계해야 한다.
정답이 무조건 있는 것은 아니지만 대부분의 경우 해당 테이블의 10~15% 정도를 가져오는 것이 유리하고 걱정하지 않아도 되는 것이 Optimizer 가 손익분기점을 보고 인덱스를 사용할지 풀스캔을 할지 결정하기 때문이다.
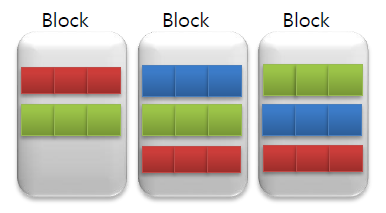
위의 사진에서 사용자가 빨간색의 데이터를 조회하는 경우 3개의 블럭을 보내야 하지만 파랑색 데이터를 조회하는 경우에는 2개의 블럭만 보내면 된다. 이 처럼 사용자가 자주 사용하는 데이터가 얼만큼 잘 모여있는지에 따라 검색속도를 결정한다.
하드 디스크에서 데이터 읽기

먼저 데이터베이스 IO Access를 말하기 전에 하드디스크에서 어떻게 데이터를 읽는지에 대해 알아보자 스핀들과 헤드가 움직이면서 데이터를 Access 하는데 이런 하드 디스크의 움직임이 Access 움직임을 좌우한다.
따라서 자주 Access 해야 되는 블럭을 이동해야 하는 랜덤 IO (인덱스 조회) 의 경우 하드 디스크의 수행 속도가 느려 질 수 있다.
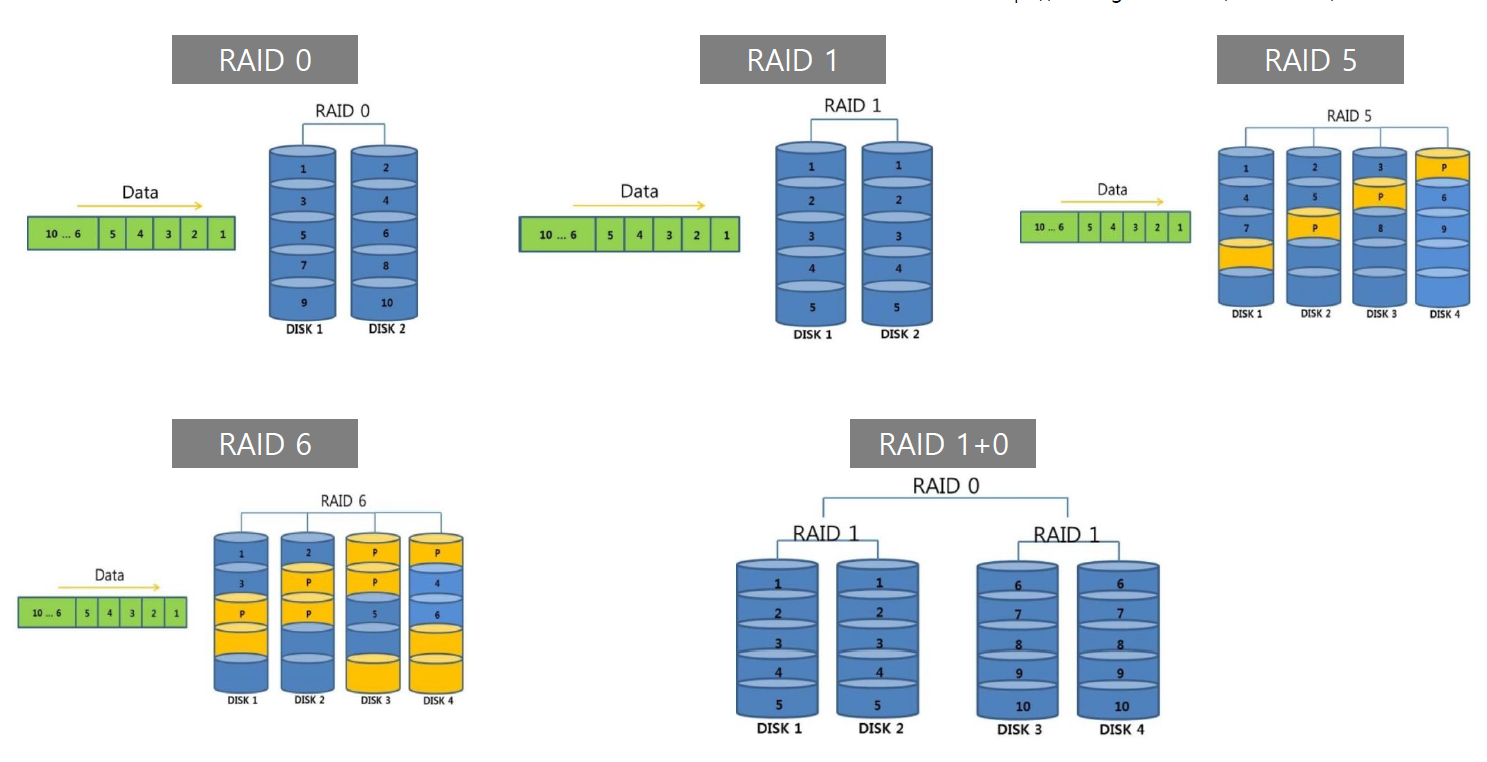
이런 하드 디스크에서 IO 하는 과정을 줄이기 위해 SSD 쪽에서도 많은 변화가 있었다.
우선적으로 동시적으로 접근하기 위해
기존의 데이터를 stripping , 즉 나누어서 저장하는 방식(raid 0) 을 생각해 내었다.
하지만 raid 0 에서 나누어서 저장하다가 하나의 데이터가 고장나서 사용못하게 되는 경우를 방지하기 위해 mirroring 즉 복제하여 저장하는 방식을 고안하였다.
하지만 단점으로 사용자가 DB용량을 10g 을 원했다면 20g 을 사용한다는 단점이 있다.
raid5 는 기존의 데이터 하나가 고장났을때 고치기 위한 패러티 비트를 사용해 복원하는 기술을 말한다. 하지만 패리티 비트를 하나 사용하는데 쓰기 작업을 할때 문제가 있어
패리티 비트 2개를 사용한 방식을 raid6 라고 한다.
이후 raid10 이라는 복제된 disk drive를 stripping 하는 구조를 제일 많이 사용한다.
다행히 추후 Flash Storage의 등장으로 절박함이 느끼지 않을 정도로 하드디스크의 문제를 개선하였다.
🚀데이터베이스 IO Access
이제 데이터를 읽는 방법에 대해서 알아보자
Sequential Access (순차 Scan)
기억장치에서 파일의 데이터를 순서대로 데이터를 순차적으로 검색하는 방법이다. 어떻게 보면 단순히 데이터를 읽어서 필요 없는 것이 아닌가?
라고 생각할 수 있는데 DB_FILE_MULTIBLOCK_READ_COUNT 라는 Multi 블럭을 IO단위로 설정 할 수 있다. 따라서 대용량의 데이터와 순차적인 데이터를 읽는 경우에는 훨씬 유용하다.
Random Access (임의 Access)
특정 데이터를 찾을 때 순차적으로 읽는 것이 아닌 원하는 레코드만을 직접 에세스 하는 방식이다.
따라서 특정데이터를 찾기 위해서 키와 Rowid로 이루어진 인덱스를 이용하여 빠르게 이동하는 방식을 말한다.
(추가) B트리 구조
추가적으로 주로 인덱스는 B 트리 인덱스로 주로 만드는데 구조는 아래와 같다.
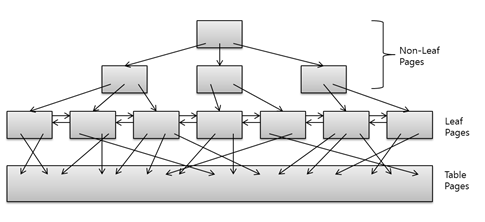
root , Branch , leaf Block으로 이루어져 있으며 리프 블록에 인덱스 키값과 ROWID를 가지고 있다. 그리고 Branch는 Leaf Block들을 관리하기 위해 데이터값들을 가지고 있어 해당 데이터가 어떤 리프테이블에 들어가있는지를 나타낸다. 데이터를 조회하게 되면 lower key값부터 upper key까지 검색을 하게 된다. 따라서 인덱스를 잘 사용하고 싶다면 = (동등 연산) 와 범위연산을 사용해야 한다.
자세한 부연설명 : https://d2.naver.com/helloworld/1155
랜덤 IO 증가량에 따른 성능 변화
만약 랜덤IO가 10배에 해당하는 블럭을 가져 오는 것과 풀스캔을 할 때 10배에 해당하는 블럭을 가져올 때 각자의 수행속도는 어떻게 증가할까? (숫자는 임의 값 입니다 :))
테이블 풀스캔은 1건을 Access 하거나 백만건을 Access하거나 모든 Block을 Access해야 하므로 Record 건수에 따른 수행시간의 변화가 거의 없는 것을 볼 수 있다.
하지만 인덱스를 경유한 랜덤 IO는 Access해야 하는 Record가 증가함에 따라 Block Access가 증가하면서 수행시간이 급격하게 느려지게 되는 것을 볼 수 있다.
Instance와 RAC을 이해해보자
INstance 와 추가 개념 설명
저번 시간에 말했던 것처럼 Instance 란 백그라운드 프로세스와 SGA 메모리 영역을 말한다.
따라서 instanc가 시작되면 SGA가 영역에 할당되고 백그라운드 프로세스가 돌아가게 된다.
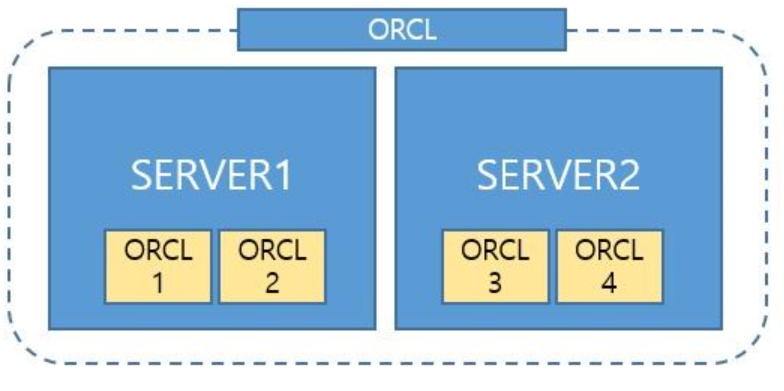
SID 는 이런 instance의 고유명을 말한다.
SERVICE_NAMES 는 1개 혹은 여러개의 인스턴스가 합쳐져 db에서 제공하는 서비스명을 말한다.
이때 SERVICE_NAMES 데이터 베이스 명과 데이터베이스 도메인으로 이루어져 있는 GLOBAL_DBNAME으로 짓게 되는데
이 때 DB_NAME 은 우리가 익히 하는 data와 리두파일을 저장하는 데이터베이스 의 이름이며
도메인도 우리가 웹사이트에 칠 때 익히 아는 도메인 주소라고 생각하면 쉽다.
위의 사진은 4개의 인스턴스를 구성하고 있고 4개의 SID를 가지고 있으며 2개의 인스턴스로 서비스를 제공할 수 있는 service_names 가 2개 있는 것이다.
RAC (Real Application Cluster) 이란?
일반적으로 db에 조회를 하게 될 때 싱글 서버로 구성한다고 생각해보자.
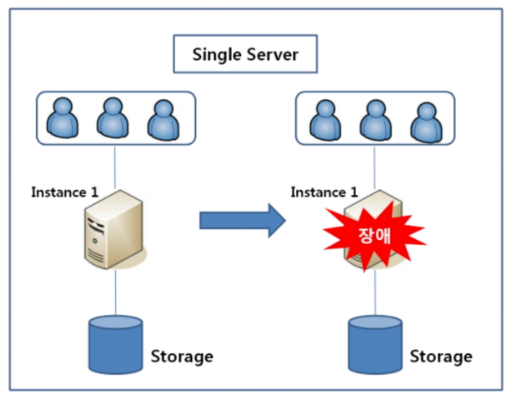
이런 경우 서버 장애가 발생하였을 때 Storage에 저장된 데이터를 사용할 수 없다는 치명적인 단점이 존재한다.
따라서 우리가 위에서 하드 디스크에서 mirroring 을 사용한 것처럼 서버 2개를 두고 장애를 대비하는 방법을 HA(High Availablitiy) 라고 한다.
HA (High Availablitiy)
하나는 서비스를 제공하고 나머지 하나는 Stand by 상태에서 대기하다가 기존 서버가 장애가 발생했을시 사용하게 된다.
문제점
우선적으로 2개의 서버를 가동하다 보니 비용이 많이 들 것이며 서버 장애가 발생했을 시 기존에 작업을 한 내용을 동기화를 하지 못해 데이터가 날라간 상태이므로 동기화를 못하게 된다.
OPS (Oracle Parllel Server)
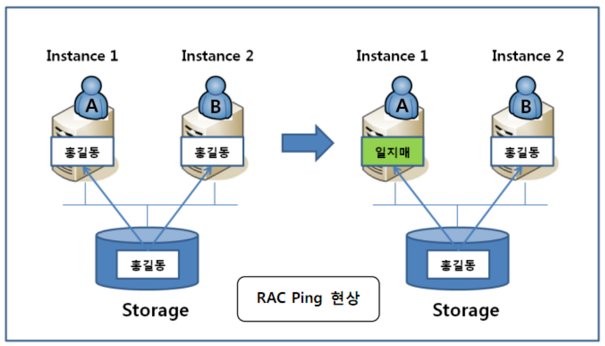
하나의 storage에 두개의 instance가 연결되어 있는 상태이므로, 하나의 인스턴스가 장애가 발생하더라도 문제 없이 데이터를 조회 변경할 수 있다.
문제점 : Rac Ping
위의 사진처럼 다른 인스턴스가 변경된 사항을 다른 인스턴스가 가져와야 하는 상황이라면 해당 데이터가 데이터베이스에 쓰여지는 것을 기다려야 하는 상황이 발생하여 성능 저하가 발생하고 이런 현상을 Rac Ping 이라고 한다.
RAC (Real Application Cluster)
따라서 HA의 단점과 OPS의 단점이 존재하는 와중에 해당 문제를 개선하기 위해 RAC 이 나오게 되었다.
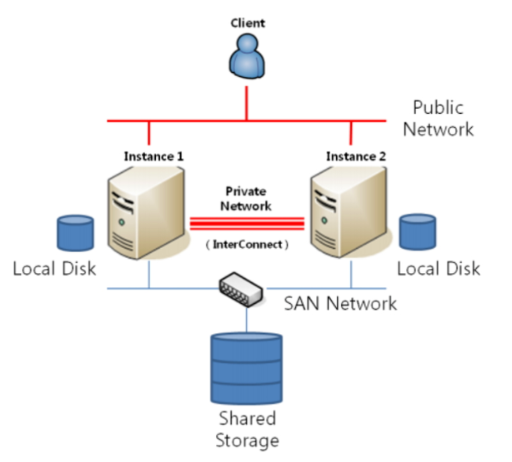
위의 사진처럼 인스턴스간에 연결되어 있는 InterConnect 라는 망이 존재하게 되는데 이는 변경사항을 db에 저장하지 않고 바로 옆의 인스턴스가 해당사항을 조회 할 수 있는 기능을 말하며 Cache Fusion 이라고 한다. 따라서 기존의 Rac Ping 문제를 개선하여 성능을 올렸다고 볼 수 있다.
data dictionary에 대해 이해해보자
버퍼 캐시로 들어가기 전에 저번에 간략하게 넘어간 data dictionary를 설명하고자 한다.
데이터 딕셔너리는 저번에 언급한 테이블, 오브젝트 , 인덱스 정보를 저장하는 것 이외에 Wait 이벤트 정보도 가지고 있다.
Wait Event 정보란?
오라클의 wait Event는 성능 및 운영 관리를 위한 필수조건으로
프로세스가 cpu, memory io등 모든 자원을 에세스 하고 단계뼐로 wait Event를 발생시켜 어디서 문제가 발생하였는지에 대해 알 수 있다.
대표적으로 db file Sequential Read 가 있으며 이는 Single block Access시에 주로 발생하는 이벤트 이며 1100개 정도 넘어가는 이벤트를 외우기 보다는 그 상황에 익숙해 지는 것이 중요한 것 같다 :0
이제 다시 data dictionary의 큰 유형으로는 다음과 같다.
user_XXX Views
현재 사용자가 가지고 있는 View에 대한 정보를 제공한다.
ALL_XXX Views
자기 자신의 뷰와 추가적으로 제공하는 View에 대해 알 수 있다.
DBA_XXX Views
dba 권한을 가진 사람만 볼 수 있는 View 를 말하며 대표적으로 sys, system이 있다.
하나 예를 들어 DUAL 테이블은 sys테이블이지만 모든 사용자에게 권한을 주어 all_tables 에서 조회 가능하다.
V$XXX Views
DB 전반에 걸쳐 여러 요소들의 정보를 제공하는데 예를 들어 V$ session 은 현재 클라이언트 정보를 어디서 가져오고 어디 서버에 연결되어 있는가와 V$ SQL 은 어떤 쿼리문이 실행중인가와 같은 정보를 알 수 있다.
사실 V$ 에서 가져오는 정보들은 X$ XX Tables에서 가져오는 정보이며 X$ 는 Dictionary View에 대한 백 정보를 제공하며 DB 모니터링 시스템을 구현할 때 X$ 시스템에 주로 접근해서 가져오게 된다.
Buffer Cache 대해 이해해보자
Buffer Cache 구조
이제 오라클에서 한정된 데이터 내에서 메모리를 잘 사용하기 위해 어떻게 버퍼 캐시를 이용하고 있는지에 대해 알아보자.
서버 프로세스가 데이터 Access 시 최초에 Storage 에 접근하게 된다.
해당 BLock이 Buffer Cache 로드 되면 해당 block에 Access시 버퍼 캐시에 Access하게 되므로 Storage IO Access 양을 줄일 수 있게 되는 것이다.
버퍼 캐시은 다음과 같은 사진으로 이루어져 있다.
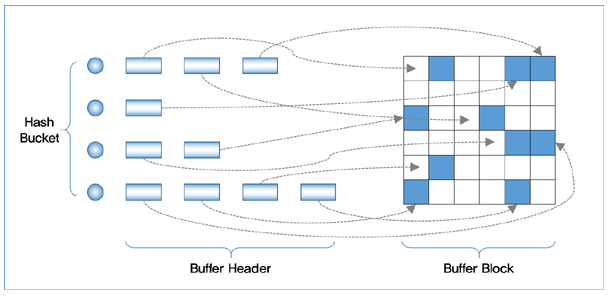
버퍼 캐시에 어떤 블럭이 존재 하는지를 찾기 위해서 해시 구조와 LRU를 사용한다.
먼저 해당 블럭에 대한 메타 정보를 담고 있는 data dictionary에서 DBA(database address) + Class 정보를 가져 오게 된다. 이후 해쉬 함수를 통해 해시 버켓을 찾아 버퍼 해더의 연결리스트 부분을 돌면서 자신이 원하는 블럭의 위치가 담겨 있는 해더값을 찾게 된다.
- 이 때 자신이 원하는 정보가 담겨져 있을 경우 Buffer Block 에 바로 찾아가 데이터를 가져오고 해당 데이터 주소를 버퍼 해더 앞 부분에 넣게 되는 것이고
- 만약 해당 데이터가 없다면 이는 버퍼 캐시에 존재 하지 않은 것으로 DBA 정보를 통해서 Disk 위치에 접근해 데이터를 가져오고 버퍼 해더가 LRU 구조를 가지고 있기 때문에 맨 앞에 해당 블럭에 대한 주소가 올라가게 된다.
Buffer Cache Hit Ratio 의 함정
Buffer Cache Hit Ratio 란 시스템이 얼마나 Disk IO 를 줄이고 Buffer Cache를 잘 사용하고 있는지에 대해 확률을 나타낸 것이다.
Logical Reads : Buffer Cache Block 의 에세스 수
Physical Reads : Disk Block 에세스 수
를 말하며 예를 들어 버퍼에서 100번 읽고 Disk에서 10번 가져오게 된다면 해당 Hit Ratio는 90퍼센트가 되는 것이다.
이 처럼 확률이 높게 나온다면 버퍼를 잘 사용한다고 말할 수 있을까?
만약 수백 , 수천개의 SQL중에서 1% 의 SQL들만이 호출 빈도가 전체 SQL 호출 빈도에 대부분을 차지 하게 된다면?
Access Block의 수는 작지만 호출 빈도수가 높은 경우 혹은 둘다 높은 경우에는 Logical Reads 는 증가하게 되지만 이를 제외한 다른 SQL들은 Buffer Cache 공간을 차지할 경우가 적지만 앞의 다른 SQL 때문에 Hit Ratio 가 높게 나올 수 있다.
따라서 Hit Ratio 는 불균일한 Load가 발생했을 시 정확한 문제 인식을 하기 어렵기 때문에
퍼센트가 아닌 메모리 Access , 디스크 Access 의 양을 기준으로 성능을 평가하는 것이 중요하다.
Buffer Cache 내 블록 유형
Free Block
아직 데이터가 할당되지 않은 블럭이었거나 Pinned Block 이었지만 다른 데이터를 받지 않은 상태이므로 재사용이 가능한 블럭을 말한다.
Pinned Block
데이터가 할당되고 나서 수정되지 않고 사용자 세션에 의해 사용되고 있는 버퍼를 말하며 이후 aging 을 하면서 점차 사용을 하지 않게 되는 경우 Free Block으로 돌아가게 되어 재사용이 가능하다.
Dirty Block
데이터가 할당된 상태에서 데이터가 수정되었지만 디스크상에 Write 되지 못한 Block이라고 한다.
재사용이 불가능 상태이지만 이후 데이터 파일로 내리게 된다면 재사용이 가능하다.
버퍼 캐시에 적재된 block의 상태 및 object의 정보를 확인하기 위해서는 v$BH 테이블에서 #BLOCK 과 STATUS 상태를 보고 어떤 상태인지, 블럭 크기보고 얼만큼 차지하고 있는지 파악할 수 있다.
Database Buffer Pools
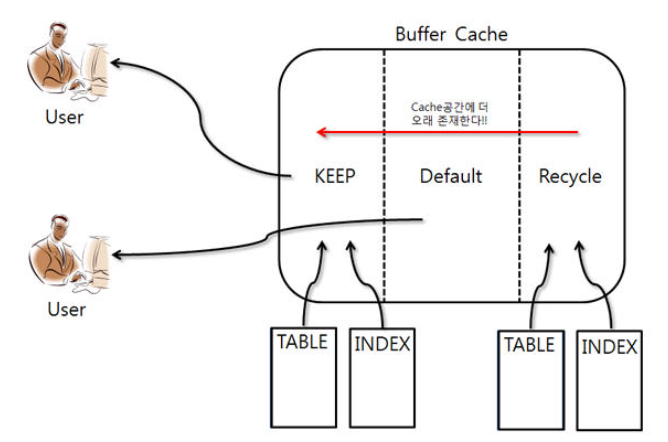
이제 버퍼 블록에 대해 알아봤으니 버퍼 캐시 공간을 나누는 방법을 알아보자.
우선 대용량 데이터를 전달하기 위한 Non Default Buffer Pools 가 있다.
이는 대용량 데이터, 통계 데이터를 Access 해야 하는 경우 Block Size가 큰것이 유리하기 때문에 기존에 버퍼 풀을 8K 로 잡아둔 것으로 부족할 수 있어 임의로 크기를 설정해준 Pool로 이해 하면 될 것이다.
(ex : 16K 32K )
다음으로 Kepp Buffer Cache 이다. Table/Index 등 Object를 Keep Buffer에 등록하면 Cache에 내려오지 않고 머무리게 되어 Hit Ratio를 높일 때 사용한다.
Default Buffer Cache 는 DB_BLOCK_SIZE 에 정의된 block Size로 블로깅 할당된 Buffer Cache 로서 별도의 옵션이 없다면 테이블과 인덱스와 같은 오브젝트는 이 캐시에 저장된다.
Recycle buffer Cache 는 비교적 Access가 적은 Obeject가 올라오게 되고 트랜잭션 이후 삭제되는 공간으로 거의 사용하지 않는 공간으로 이해하면 된다.
Non Default Buffer Pools을 사용하기 보다는 Direct IO를 할 수 있다는 것, 이렇게 나누어서 사용할 수 있다는 정도로 이해하면 좋을 것 같다.
만약에 Keep Buffer 에 Customer 테이블을 등록하고 싶다면
ALTER TABLE CUSTOMER STORAGE ( BUFFER_POOL kEEP )
와 같이 작성하면 된다.
Buffer Cache 크기에 관하여
위에서 쭉 작성하면서 Buffer 캐시의 크기가 커지면 그와 동시에 HIt ratio 도 증가하고 빠르게 데이터를 가져올 수 있기 때문에 크면 클수록 좋지 않을까? 라고 생각하였다.
Buffer Cache에 Access 작업은 높은 비용을 소모
Buffer Cache를 사용하면 SQL 수행 성능을 크게 향상 시킬 수 있으나 접근하기 위한 메모리의 Latch 나 Lock 과 같은 비용을 소모하게 된다.
Latch는 영어로 후쿠를 건다. 즉 해당 해쉬 버켓과 연결리스트를 읽는 동안 해당 데이터를 약하게 잠군다 라고 생각하면 될거 같다. 아마 쓰기 작업은 막고 읽기 작업은 같이 하는 경우를 말하는 것 같다.
만일 대량의 Latch와 Buffer busy 가 소모되어 공유 메모리를 사용할 수 없는 임계점이 되면 시스템의 안정성을 위협할 수 있다.
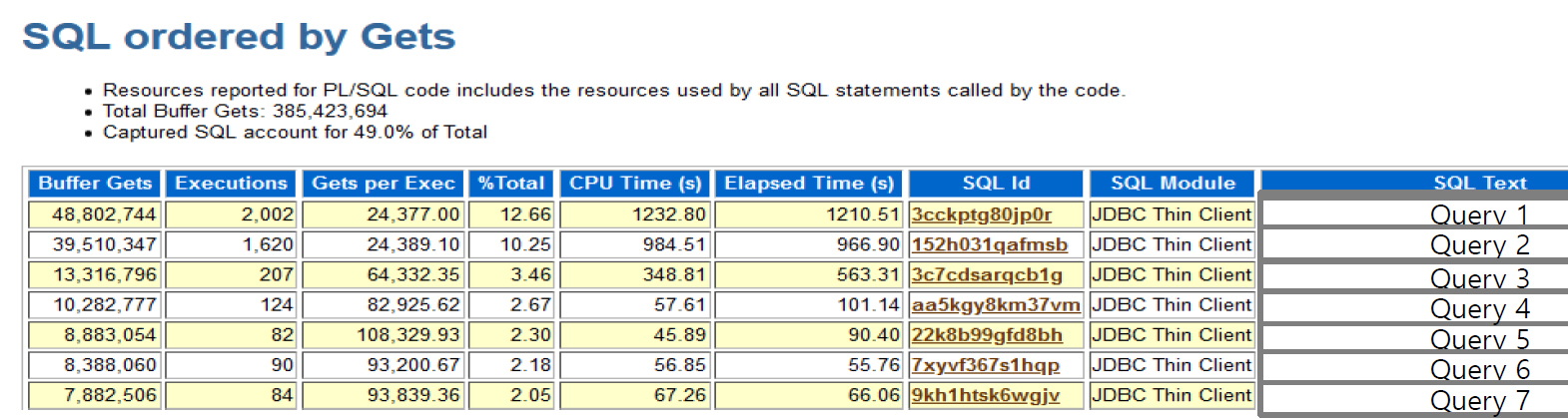
위와 같은 예시에서 Query 1 번 예시를 보자.
해당 데이터는 1시간 동안 48802744 번 요청이 되었고 해당 요청당 24377의 블럭을 요구한다. 따라서 24k * 8K(데이터 블럭 최소 단위) 300M 정도를 한 번 요청할 때마다 메모리에 접근해야 한다는 것이다.
가능한 이유가 Buffer Cache 공간을 늘리게 됨에 따라 무거운 데이터가 메모리에 올라갈 수 있게 되었고 해당 데이터가 쓰이는 동안 다른 쿼리문은 수행할 수 없는 상태가 된다는 것이다.
따라서 Buffer Cache의 공간을 넓히기 보다는 해당 쿼리의 Latch, Lock 시간을 줄이거나 쿼리 개선이 우선시 되야할 것이다.
적절한 Buffer Cache를 사용하기 위한 Advice
오라클 콘솔창에
SELECT * FROM V$DB_CACHE_ADVICE;
를 검색하거나 AWR 의 Buffer Pool Advisory를 통해 도움을 받을 수 있다.
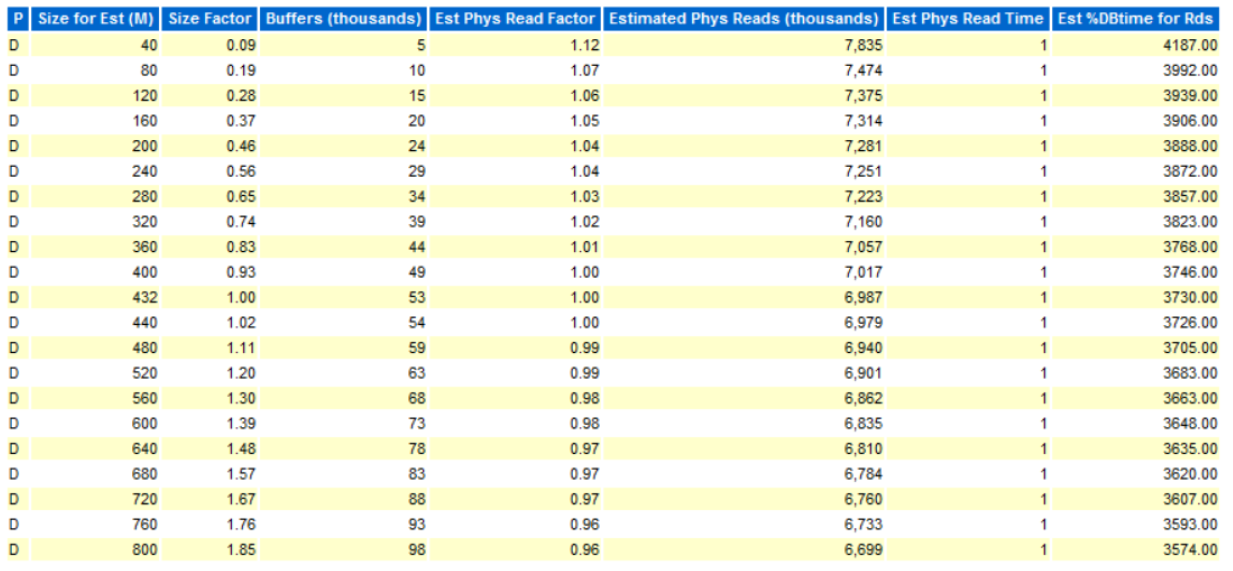
위의 사진처럼 Size Factor 가 1이 현재 적용되어 있는 버퍼 캐시의 크기이며 옆의 Size가 각 사이즈별 역량을 나타내고 있다.
주의 깊게 볼 컬럼은 Estimated Phys Reads 라는 컬럼이며 이는 각 해당 사이즈별 Disk IO를 하는 추측을 보여주고 있다. 해당 사진에서 크기를 0.09배 한것과 1.85배 한것을 비교해보면 메모리가 커짐에 따라 기하급수적으로 IO가 적어지지 않는다는 것을 알 수 있다.
이런 방법 이외에 수동으로 크기 설정, ASMM(Automatic Shared Memory Management = SGA)으로 크기 설정, AMM(Automatic Memory Management = SGA + PGA)으로 크기 설정 하는 방법이 있으며 이는 추후 Shared Memory에 대해 작성할 때 다루고자 한다.
결론
클러스터링 팩터, IO ACCESS 와 하드디스크에서 읽는 방법 , 버퍼캐시에 저장되는 과정 및 찾는 과정에 대해 알아보았고 다음을 오라클 마지막편으로 앞에서 한 기본 내용을 정리해보며 강의 리뷰를 하며 마무리하고자 한다.😲
