
저번 시간에는 오라클 기본 동작을 알아보기 앞서 왜 IO가 오래걸리는 지에 대해 알아보았다.
이번에는 오라클의 아키텍쳐를 보면서 기본적으로 어떻게 돌아가는지 파악하고 IO ACCESS 에 대해 알아보자
1. 오라클 아키텍쳐
Oracle Process
우선적으로 오라클은 프로세스, 메모리, 데이터베이스 파일 로 이루어져 있다.
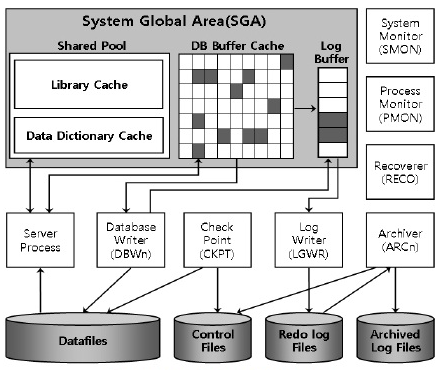
먼저 메모리를 어떻게 사용하는지에 대해 알아보자
일반적으로 프로세스가 PCB를 구성하고 있고 그중에서 프로세스가 공유하는 부분을 SHARED AREA 라고 하였는데 사진에서 보이는 SGA(System Global Area)는 데이터베이스에서 공유하는 영역이다. 데이터를 읽고 쓰고 변경사항을 저장하는데 많이 사용한다.
SGA
SGA에서 크게 자리를 잡고 있는 Shared pool 이 있는데 Library Cache는 실행계획이나 캐시가 올라가게 된다. Data Dictionary Cashe는 테이블,인덱스,함수등의 메타정보를 저장하는 공간으로 사용된다.
그림에서 나오진 않았지만 오라클 연동 하는 백앤드가 자바라면 자바 명령을 해석하기 위한 공간인
JAVA POOL, 그리고 대용량 데이터를 저장 혹은 전송을 하기 위한 공간인 LARGE POOL 이 존재하며 SHARED POOL + LARGE POOL , JAVA POOL 을 합쳐서 Variable Size 라고 말한다.
DB Buffer Cache에는 하드 디스크가 데이터를 한 번 읽었을 때 버퍼 캐시(Data Block)를 올려두는 공간이다. 최근에 사용한 데이터 블럭을 사용할 확률이 높다는 가정하에 하는 기법 LRU를 사용한다.
Buffer 어느 위치에 데이터가 저장되어 있는지 찾는 방법은 무엇일까?
hit_ratio 가 높은 시스템은 잘 구현된 시스템이라고 말할 수 있을까?
더 자세히 알고 싶다면 LRU 및 해시함수, 평균의 함정에 대해 다음편을 참고하면 될 거 같다 :0
로그 버퍼 혹은 리두로그 버퍼
로그 버퍼 혹은 리두로그 버퍼는 변경사항을 쌓아두는 버퍼라고 생각하면 쉽다. select를 제외한 DML 쿼리로 변경사항이 생길 때 마다 하드 디스크에 접근하여 수정사항을 업데이트하게 되면 그만큼 IO가 많이 발생하여 비효율적이기 때문이다.
따라서 buffer cache에 변경사항이 생기면 해당 변경된 내용을 Redo Log Buffer에 저장하게 된다. 이 후 사용자가 Commit을 하거나 버퍼가 1/3이 차게 된 경우 Online Log File 에 write 하게 되고 이후 Online Log File이 일정 수준 차게 되면 Archaive Log File 에 옮겨 가면서 저장하게 된다.
이는 우리가 트랜잭션에서 말하는 ACID D(Durablity) 지속성과 관련이 깊다. 한 번 수행된 쿼리에 대해서는 영원해야 한다는 것이 장애가 발생했을 때에도 트랜잭션 내용이 살아 있어야 하기 때문이다.
장애복구를 하기 위해 해당 변경사항을 저장하는 용도로 사용한다. 사진에서 보이는 것과 같이 LGWR라는 것과 연결이 되어있는데 이는 백그라운드 프로세스로 버퍼에 저장되어있는 모든 변화를 메모리에 기록하는 역할이다.
언두 버퍼
언두 버퍼는 트랜잭션으로 인해 변경 된 전의 데이터를 저장하는 버퍼이다. 이는 트랜잭션을 수행 하면서 전의 데이터를 출력하는 일이 발생한다. 데이터가 변경되면 먼저 SGA 버퍼 캐시에 데이터가 변경되기 때문이다. 특이한 점으로는 언두 로그는 리두로그와 달리 1/3 차는 특정 checkpoint에만 디스크에 기록하고 커밋시에는 기록하지 않는다.
추가적으로 해당 DB의 트랜잭션의 수준이 Read- Commited 이라면 변경 되기 전의 데이터를 가져오는데 사용된다.
여기서 의문이 들 수 있는게 서비스가 거대해 지면서 같은 데이터베이스를 공유하는 SGA가 여러대가 존재하는 경우 하나의 SGA의 메모리에 변경 사항을 저장하고 그 변경사항을 다른 SGA에서 변경사항을 볼 수 없다. 이런 변경사항을 공유하기 위해 오라클이 어떤 노력을 했고 SID, RAC 개념을 이후 시리즈에서 다뤄볼 예정이다.
서버 프로세스는 SGA에 먼저 접근하여 DB buffer안에 자신이 원하는 데이터 값들이 있는지 찾아보고 존재 하지 않으면 Datafiles에 접근하여 데이터를 가져와 Buffer에 저장한다.
데이터베이스 파일
데이터베이스 파일은 사용자 데이터가 저장되는 Datafile 와 DML같은 데이터 변경 사항을 실시간 기록하는 Redo Log File , 오라클 Structure 주요 변경 사항을 기록하는 Control File 로 구성되어 있다.
오라클에서 일반적으로 Background Process 와 SGA 메모리 영역을 인스턴스라고 부르며 오라클을 실행하기 위한 기초적이며 필수적인 공간으로 이해하며 되며 Database는 데이터를 저장하는 물리적 영역으로 이해하면 된다.
이렇게 오라클이 복잡한 구조를 가지게 된 이유는 하드 디스크의 발전보다 RAM의 발전이 더디게 되어 어떻게 하면 메모리 자원할당을 효율적으로 할 수 있는가 ? 혹은 DISK IO를 최대한으로 줄일 방법을 고려했다고 볼 수 있다.
User Process
이제 오라클의 프로세를 이해하고 나서 유저 프로세스와 1:1 매칭되는 PGA(Program Global Area) 에 대해 이해해보자
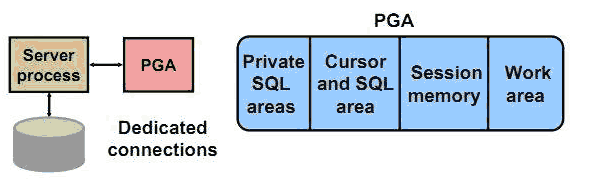
PGA는 서버 프로세스가 독단적으로 사용하는 공간으로 위의 사진처럼 4가지로 나타낼 수 있는데
그중에서 Work area 에는 Sort Area 와 Hash Area 를 저장한다.
이는 서로 다른 테이블을 Join 혹은 정렬 할 때 사용하는 공간으로 간단하게 해당 프로세스가 메모리에 올라가 있을 때 빠르게 데이터를 가져오기 위해 Join 테이블 일부, 정렬 데이터를 올려두는구나 라고 이해하면 될 것 같다.
세션 메모리는 우리가 익히 알고 있는 그 세션이 맞으며 필요한 데이터를 전달해 주기 위해 유저 프로세스의 세션정보를 저장하는 공간이다.
Prviate Sql areas는 Bind 변수를 저장하는 공간으로 사용하는 공간을 말한다. 이는 우리가 SQL문을 작성할 때 정적인 쿼리문을 작성하는 것 보다 사용자에게 입력받은 변수를 쿼리문에 넣는 경우가 더 많은데 이 때 사용하는 변수를 저장하는 공간을 말한다.
요약
데이터 검색 (select) 를 하게 된다면 위에서 정의한 용어를 기준으로 Server Process가 DataFile 로 데이터베이스 파일에서 Data File을 읽어와 DB Buffer Cashe 에 데이터 블럭을 저장하고 PGA를 통해서 오라클 Client에게 보여주는 방식이다.
2.최적의 저장구조를 위한 고려 사항
dbms에서 성능을 결정 하는 것에는 cpu , memory , i/o 중에서 개선해야 한다면 어떤 것이 중요할까?
CPU와 Memory 는 더 좋은 장비를 사면 해결되지만 한계점이 존재하며 IO해결을 통한 성능을 높이는 것이 가장 중요하다.
IO를 줄이기 위해서 데이터를 저장하는 방식 과 이를 가져오는 검색 방식 을 고려해볼 필요가 있다.
먼저 데이터를 저장하는 방식에 있어서 임의의 공간에 바로 저장하는 방법을 생각해 보자.
정리하지 않고 임의의 메모리에 넣게 된다면 검색시에는 시간이 더 걸리지만
저장 할 시에는 빠르게 완료될 것이고
만약 약속된 공간에 정확히 보관하게 된다면 데이터를 검색할 때는 빠르지만 저장할 시에는 오래 걸린다는 것을 알 수 있다.
다음으로 데이터를 검색 하는 방식 이다. 예를 들어 책에서 찾고자 하는 내용을 찾을 때 목차를 통해서 찾는 것과 처음 페이지 혹은 중간페이지 부터 찾는 방법이 있는데 이렇게 보면 목차를 통해서 찾는 것이 가장 빨라 보인다.
하지만 인덱스를 통한 ramdom access가 좋아보이지만 rdbms에서 table을 생성하거나 인덱스를 생성하는 것을 인스턴스를 생성한다. 라고 한다.
따라서 성능을 높이기 위해 복합 인덱스를 사용하면 그만큼 인스턴스를 생성해야 하며 DML 즉 update 나 insert 시에 해당 index 테이블도 처리해야 하기 때문에 원하는 성능이 나오지 않을 수 있다.
3. 데이터베이스 블록의 이해
위에서 인덱스를 사용한 access를 Random access라고 하였는데 이를 이해하기 전에
데이터베이스 Block 에 대해 알아보고자 한다.
Block 은 데이터베이스 데이터 검색과 저장의 가장 기본 단위를 말하며 시스템 내부에서 사용하는 단위 혹은 오라클 자체적으로 8k , 16k 를 사용한다.
즉 우리가 리눅스에서 메모장에 한글자 작성하고 1kb를 잡아먹는 것처럼 하나의 스키마를 조회 하더라고 데이터 block은 8k 의 공간을 차지하게 된다.
즉 레코드 결과 값이 10개 컬럼이 10개 라고 했을 때 10개씩 혹은 50개씩 IO 작업을 한다고 생각하면 된다.
Q1) 그러면 백만개의 Record를 가지는 두개의 테이블의 검색속도는 동일할까?
Q2) 백만개의 Record를 가지고 컬럼 크기와 값도 서로 동일한 두개의 테이블이 있을때 검색 속도는 동일할까?
정답은 다음 블로그에서 확인 하면 될 것 같다. 😀
이렇듯 정산/마감/통계 생성같은 대용량 데이터를 저장하는 batch에서는 대량의 데이터를 일괄 처리하는 throughput 이 중요할 것이고 OLTP(On-Line Transaction Processing) 에서는 사용자가 원하는 데이터를 주기 위해 인덱스를 통한 빠른 접근이 중요할 것이다.
요약
오라클의 아키텍쳐에 대해 가볍게 맛보고 IO를 높이기 위한 방법에 대해 고려해보고 저장하는 방식과 읽는 방식에 대해 고민하는 시간을 가져보았다. 결론적으로 어떤것이 좋다는 것을 나타내지는 않았지만 깊게 생각하는 시간이었으면 좋겠다 :)
다음에는 알아보고 하드디스크에서 IO 및 데이터 손실을 막기 위해 어떤 방식을 사용하는지 그리고 SID,RAC 개념 및 BUFFER CASHE에 대해 에 대해 알아보자
