
[자료구조(Data Structures)]
데이터 구조는 데이터를 액세스, 저장 및 구성하는 특정 방법이있는 데이터 모음
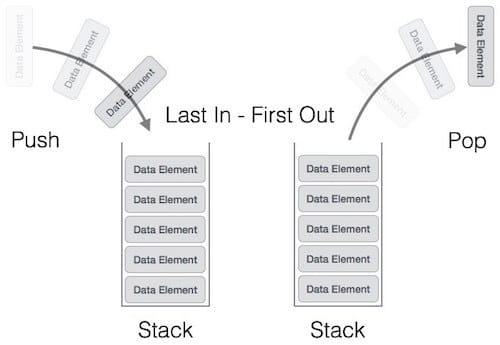
1. Stack
-
한 쪽 끝에서만 자료를 넣거나 뺄 수 있는 선형 구조(LIFO - Last In First Out)으로 되어 있다.
-
사용 사례 : 재귀알고리즘(재귀적으로 함수를 호출해야 하는 경우에 임시 데이터를 스택에 넣어준다.
), 웹 브라우저 방문기록, 실행취소, 역순 문자열 만들기, 수식의 괄호검사, 후위 표기법 검사 -
Stack 주요 연산
-
S.top() : 스택의 가장 윗 데이터를 반환한다. 만약 스택이 비었다면 이 연산은 정의불가 상태이다.
-
S.pop() : 스택의 가장 윗 데이터를 삭제한다. 스택이 비었다면 연산 정의불가 상태이다.
-
S.push() : 스택의 가장 윗 데이터로 top이 가리키는 자리 위에(top = top + 1) 메모리를 생성, 데이터 x를 넣는다.
-
S.isempty() : 스택이 비었다면 1을 반환하고,그렇지 않다면 0을 반환한다.
-
S.peek() : 스택의 가장 위에 있는 항목을 반환한다.
-
S.search(Object) : Object의 위치를 반환한다. 없으면 -1을 반환한다.
-
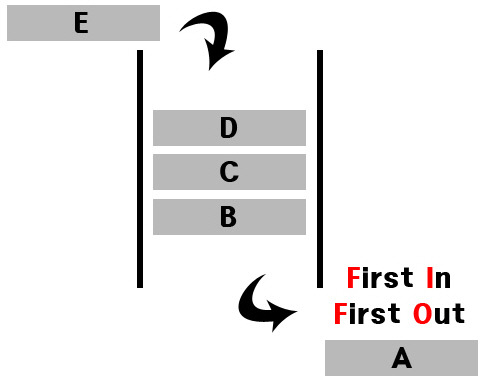
2. Queue
-
한 방향에서 입력이 이뤄지고, 그 반대편 방향에서 출력이 이루어지는 선입선출(FIFO) 자료구조이다.
-
사용 사례 : 너비 우선 탐색(BFS, Breadth-First Search)구현, 캐시(Cache) 구현, 우선순위가 같은 작업 예약(인쇄 대기열), 선입선출이 필요한 대기열(티켓 카운터), 콜센터 고객 대기시간, 윈도 시스템의 메시지 처리기, 프로세스 관리
-
Queue에서 사용하는 용어
-
head : dequeue 하였을 시 출력이 되는 부분 (유의어: front, first 등)
-
tail : enqueue 하였을 시 입력이 되는 부분 (유의어: rear, back, last 등)
-
-
Queue 주요 연산
-
Q.push()
-
Q.shift()
-
enqueue : data를 queue의 맨 뒤에 입력
-
dequeue : head에 있는 data를 출력 및 삭제
-
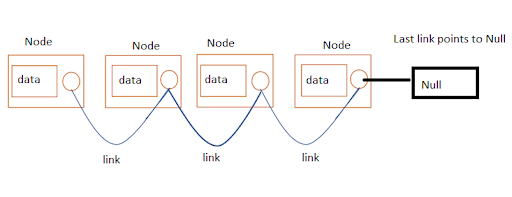
3. Linked List
-
각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조이다.
-
일련의 원소를 배열처럼 차례대로 저장하지만, 원소들이 메모리상에 연속적으로 위치하지 않는다는 점이 다르다.
-
사용 사례 : Playlist, Train, 웹브라우저페이지
-
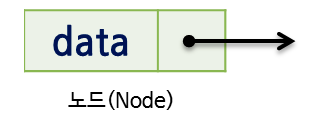
노드(Node)
- 연결 리스트에서 각 원소는 원소 자신과 다음 원소를 가리키는 포인터가 포함된 노드(Node)로 구성된다.
-
Linked List에서 사용하는 용어
-
list.head (type: object) : head를 제거할 때 쉽게 사용할 수 있다.
-
list.tail (type: object)
-
-
Linked List에서 사용하는 주요 연산
-
addToTail() : 가장 끝에 노드를 붙일 때 사용한다.
-
removeHead() : 가장 앞(head)를 삭제할 때 사용할 메소드이다.
-
contains() : 구현된 객체에서 node.value 가 존재 하는지 확인한다.
-
isEmpty(): 데이터가 하나도 없다면 true를, 그 외엔 false를 반환한다.
-
size(): 데이터 개수를 반환한다. 배열의 length 프로퍼티와 비슷하다.
-
insert(위치, 데이터): 해당 위치에 데이터를 삽입한다.
-
indexOf(데이터): 해당 데이터의 인덱스를 반환한다. 존재하지 않을 경우 결과 값은 -1이다.
-
4. Graph
-
상하위의 개념이 없이 각각의 node와 그 node들 간의 간선(edge)을 하나로 모아 놓은 자료구조이다.
-
Graph에서 자주 사용하는 용어
-
노드(node) : 위치라는 개념. (vertex 라고도 부름)
-
간선(edge) : 위치 간의 관계. 즉, 노드를 연결하는 선 (link, branch 라고도 부름)
-
인접 노드(adjacent vertex) : 간선에 의 해 직접 연결된 노드
-
노드의 차수(degree) : 무방향 그래프에서 하나의 노드에 인접한 정점의 수
-
진입 차수(in-degree) : 방향 그래프에서 외부에서 오는 간선의 수 (내차수 라고도 부름)
-
진출 차수(out-degree) : 방향 그래프에서 외부로 향하는 간선의 수 (외차수 라고도 부름)
-
사이클(cycle) : 단순 경로의 시작 정점과 종료 정점이 동일한 경우
-
단순 경로(simple path) : 경로 중에서 반복되는 정점이 없는 경우
-
경로 길이(path length) : 경로를 구성하는 데 사용된 간선의 수
-
방향 그래프(Directed graph) : 방향성을 띄고 있는 그래프
-
무방향 그래프(Undirected graph) : 방향성을 띄고 있지 않은 그래프
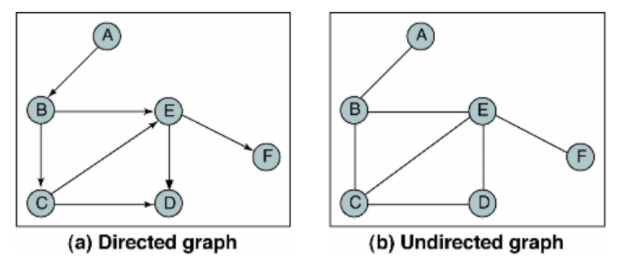
-
-
Graph를 코드로 표현하는 방법
-
이차원 배열(Adjacency Matrix) : 공간은 많이 차지하지만 간단하다.
-
연결 리스트(Adjacency List) : 공간은 적게 차지하지만 복잡하다.
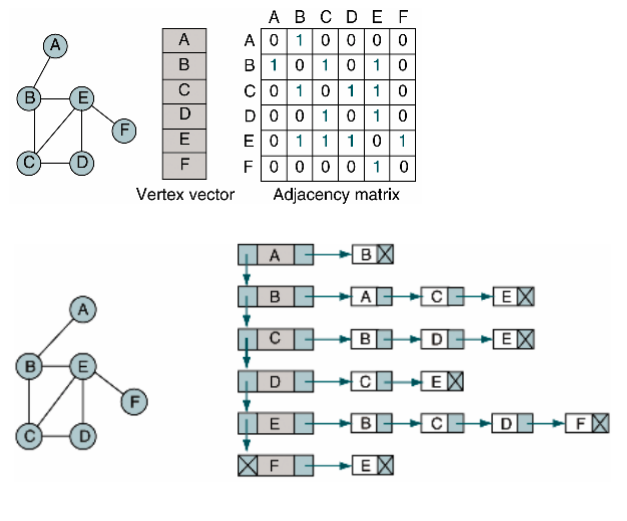
-
5. Tree
-
나무를 뒤집어 놓은 것처럼 하나의 시작 노드(root)로부터 시작되어 자식 노들(child node)들이 가지를 치듯 뻗어 나가는 구조이다.
-
Tree에서 자주 사용하는 용어
-
branch(edge) : 노드와 노드 사이를 이어주는 것
-
경로(path) : Root부터 마지막 노드까지 가는 길
-
높이(height) : 부모노드에서 자식노드 사이의 edge 개수
-
Root node : A가 뿌리를 내리는 첫번째 노드가 됩니다.
-
Child node : A가 뿌리를 내리면서 B-I 는 모두 누군가의 Child node가 됩니다.
-
Parent node : A처럼 뿌리를 내리는 B-D는 모두 누군가의 Parent node가 됩니다.
-
Sub-tree : B-D처럼 뿌리를 내린 부분은 조그만 sub-tree라고 할 수도 있습니다.
-
Leaf node : H, I처럼 마지막 level에 존재하는 node가 leaf node가 됩니다. 나무의 끝에 있는 것이 나뭇잎인걸 생각하면 이해에 도움이 됩니다.
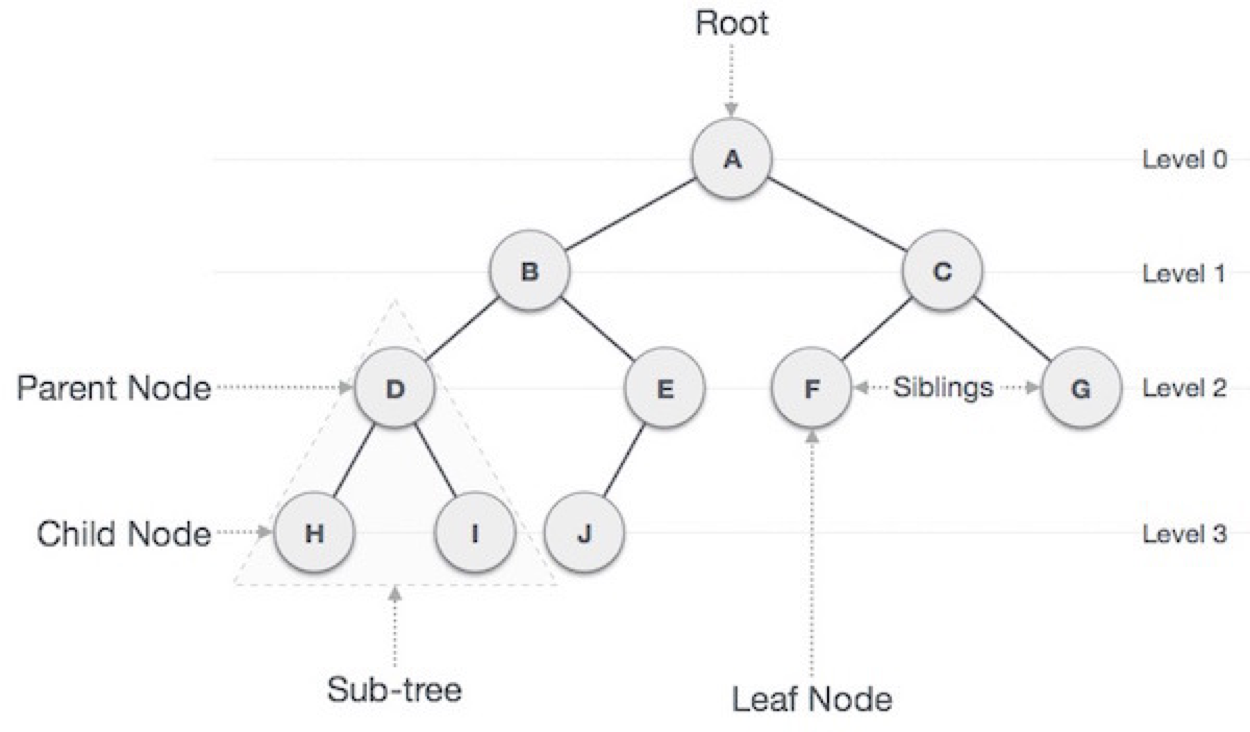
-
-
대표적으로 이진트리(Binary Search Tree)가 있다.
-
이진트리는 최대 두 개의 자식 노드를 가지는 트리 자료 구조이다.
-
루트 노트를 기준으로 루트 노트보다 작은 값은 왼쪽 하위노드로, 루트 노트보다 큰 값은 오른쪽 하위노드로 설정하는 방식이다.
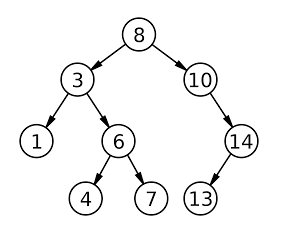
-
6. HashTable
-
어떤 특정 값을 받으면 그 값을 해시 함수에 통과시켜 나온 인덱스(index)에 저장하는 자료구조이다.
-
해시 테이블의 아이디어는 직접 주소 테이블(Direct Address Table)이라는 자료구조에서 부터 출발했다. 직접 주소 테이블은 공간 효율성이 좋지않다.
-
적은 리소스로 많은 데이터를 효율적으로 관리하기에 효율적이다.
-
HashTable에서 자주 사용하는 용어
- 해시함수(hash function) : 데이터의 효율적 관리를 목적으로 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수
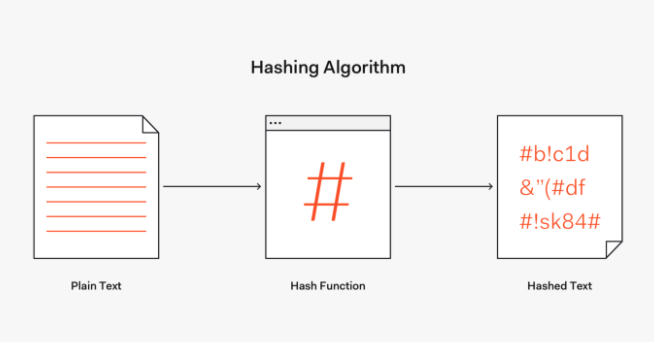
-
Bucket : 해싱된 값이 저장되는 곳.
-
키(key) : 매핑 전 원래 데이터의 값
-
해시값(hash value) : 매핑 후 데이터의 값
-
해싱(hashing) : 매핑하는 과정 자체
-
해시충돌(collision) : 해시함수가 서로 다른 두 개의 키에 대해 동일한 해시값을 내는 것
- 충돌 해결하기 : 개방 주소법(Open Address), 분리 연결법(Separate Chaining)
-
HashTable에서 사용하는 주요 연산
-
insert(key, value) - 주어진 키와 값을 저장합니다. 이미 해당 키가 저장되어 있다면 값을 덮어씌웁니다.
-
retrieve(key) - 주어진 키에 해당하는 값을 반환합니다. 없다면 undefined를 반환합니다.
-
remove(key) - 주어진 키에 해당하는 값을 삭제하고 값을 반환합니다. 없다면 undefined를 반환합니다.
-
_resize(newLimit) - 해시 테이블의 스토리지 배열을 newLimit으로 리사이징하는 함수입니다. 리사이징 후 저장되어 있던 값을 전부 다시 해싱을 해주어야 합니다. 구현 후 HashTable 내부에서 사용하시면 됩니다.
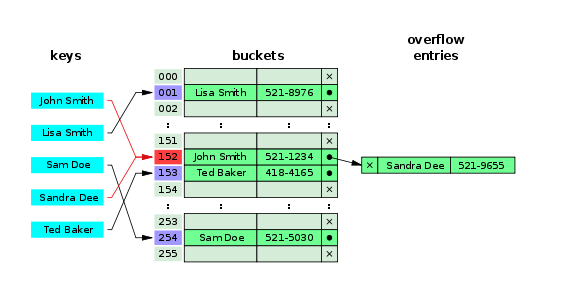
-
