
Amazon Rekognition
Rekognition은 머신 러닝을 이용하여 사람, 텍스트, 이미지 혹은 동영상 장면을 인식한다. 안면 분석이나 안면 검색을 통해 사용자를 인증하거나 사람들의 수를 셀 수 있는 것이다. 이를 이용하면 익숙한 얼굴에 대해 데이터베이스를 생성하거나 유명인과 얼굴을 비교할 수 있다.
Rekognition 사용 사례
- 라벨링
- 컨텐츠 조정
- 텍스트 감지
- 안면 감지 및 분석(성별, 나이의 범위, 감정(
=emotions)) - 안면 검색과 인증
- 유명인 인식
- 경로 추적
시험에서는 Rekognition에 대한 내용이 개괄적으로만 나온다
Amazon Transcribe
Transcribe는 음성을 텍스트로 자동 변환해준다. 오디오를 전달하면 자동으로 텍스트로 변환되는 것이다. 그리고 자동 음성 인식인 ASR이라는 딥러닝 프로세스를 사용하여 음성을 텍스트로 매우 빠르고 정확하게 변환한다.
Transcribe에서 알아둬야 하는 기능
Transcribe에서 몇 가지 기능은 알아둬야 한다.
- 개인 식별 정보(PII)를 자동으로 제거할 수 있다.
- “Redaction”을 사용해서 할 수 있음
- 누군가의 나이, 이름, 주민등록번호가 있는 경우 자동으로 제거할 수 있음
- 다국어 오디오에 대한 자동 언어 식별 기능을 사용할 수 있다.
- 프랑스어, 영어, 스페인어가 섞여 있어도 Transcribe는 모두 인식할 수 있을 정도
Transcribe의 사용 사례
- 고객 서비스 통화를 받아쓰기 해서 자동으로 자막을 만듦
- 미디어 자산에 대한 메타 데이터를 생성하여, 검색 가능한 아카이브를 만듦
Amazon Polly
Polly는 Transcribe와 반대 개념으로 딥러닝을 사용하여 텍스트를 음성으로 변환해준다(=TTS). 이를 통해 대화하는 애플리케이션을 만들 수 있다.
Amazon Translate
Translate는 자연스럽고 정확한 번역을 제공한다. Translate를 이용하면 전 세계의 사용자들을 위해 웹사이트나 애플리케이션의 방대한 텍스트를 쉽고 효과적으로 번역하여 컨텐츠를 현지화할 수 있다.
Amazon Lex & Connect
Amazon Lex
Lex는 Amazon의 Alexa 기기에도 들어가는 기술로써, 자동 음성 인식, ASR을 통한 음성을 텍스트로 변환, 자연어 이해 기능을 통해 텍스트나 발신자의 의도를 파악할 수 있다. 즉, 문장을 이해하는 것이다.
Lex는 챗봇이나 콜센터봇을 구축하는 기술이다.
Amazon Connect
Connect는 가상 고객 센터로 전화를 받고, 고객 응대 흐름을 생성한다. 클라우드 기반이며 다른 고객 관계 시스템이나 관리 시스템인 CRM 시스템, AWS 서비스 등과 통합될 수 있다.
Connect의 장점은 선불 결제가 없고, 기존 고객 센터 솔루션보다 80% 가량 저렴하다는 것이다.
스마트 고객 센터 구축 예시

- Amazon Connect에 있는 전화번호에 약속을 정하려고 하는 전화가 옴
- Lex는 해당 전화에 대한 모든 정보를 스트리밍 하며 전화 통화의 의도를 파악
- 파악한 정보에 맞는 람다 함수를 호출
- 람다는 해당 미팅 일정을 CRM에 기록하는 코드를 작성
Lex는 ASR, 그리고 Connect는 고객 센터를 위한 서비스이다.
Amazon Comprehend
Comprehend는 사물을 이해하는 것을 목적으로 하며 자연어 처리(NLP: Natural Language Processing)를 목적으로 한다. 즉, 읽어 들인 여러 데이터에 대해 그 의미를 파악하는 역할을 한다.
Comprehend는 완전 관리형 서버리스 서비스로 머신 러닝을 이용하여 텍스트에서 인사이트와 관계를 찾아낸다.
Comprehend를 이용하면 할 수 있는 일
- 텍스트의 언어
- 주요 문구, 장소, 사람, 브랜드 혹은 이벤트를 추출
- 분석하고 있는 텍스트가 긍정적인지 부정적인지 이해할 수 있도록 감정 분석 수행
- 토큰화와 음성 중 일부를 사용하여 텍스트 분석
- 텍스트 파일 모음을 주제별로 구성하고 주제를 찾아낼 수 있음
Comprehend 사용 사례
- 고객 상호 작용 분석
- 이메일을 보내는 고객이 많다고 했을 때 지원 서비스를 기반으로 하여 해당 고객 경험이 긍정적이었는지 부정적이었는지 파악하고자 함
- 이 경우 Comprehend를 이용해서 해당 특성을 추출하면 비즈니스 인사이트를 도출해서 분석을 통해 비즈니스를 개선할 수 있음
- Comprehend가 파악할 주제별로 기사 그룹을 지정
- 방대한 기사를 하나씩 입력하지 않고 하나의 그룹으로 지정해서 Comprehend에 입력하면 그 결과로 주제별로 그룹을 묶을 수도 있음
Amazon SageMaker
SageMaker는 완전 관리형 서비스로 개발자나 데이터 과학자가 이를 이용하여 머신 러닝 모델을 구축할 수 있다.
지금까지 살펴본 다른 모든 서비스와는 다른 고차원의 머신 러닝 서비스로 실제 개발자나 조직 내 데이터 과학자가 이를 이용하여 머신 러닝 모델을 생성할 때 사용하기 때문에 더 발전된 서비스이자 이용이 복잡하다고 볼 수 있다.
SageMaker를 통해 전체 프로세스 즉, 라벨링, 모델 구축, 학습, 조정, 적용을 할 수 있다.
Amazon Forecast
Forecast는 예측을 지원하는 간단한 서비스로 완전 관리형 서비스이며 머신 러닝을 이용하기 때문에 정확한 예측을 제공한다.
Forecast 원리
Forecast 원리는 다음과 같다.
- 먼저 과거 시계열 데이터를 불러온다.
- 제품 사양이나 가격, 할인 웹사이트 트래픽, 점포 위치 등 모델을 개선할 수 있는 모든 데이터를 가져오도록 한다.
- 가져온 데이터를 S3에 업로드하고 Forecast 서비스를 실행해서 예측 모델을 생성하도록 한다.
- 만든 예측 모델을 사용해서 실제로 예측을 한다.
Forecast 사용 사례
- 예측과 관련된 모든 것
- 제품 수요 계획
- 재무 계획
- 리소스 계획
- …
시험에 예측이 보이면 Amazon Forecast를 생각하자.
Amazon Kendra
Kendra는 머신 러닝을 이용한 완전 관리형 문서 검색 서비스로 문서 내에서 답변을 추출할 수 있도록 지원한다.
이때 문서에는 텍스트, PDF, HTML, PPT, Word, FAQ 등이 있다. 이와 같은 문서는 여러 데이터 소스에서 찾아볼 수 있고, Kendra가 내부적으로 구축된 지식 인덱스를 통해 이들을 인덱싱한다.
최종 사용자는 구글처럼 자연어 검색 기능으로 사용하거나, 일반 검색에서 활용할 수 있다. 사용자 상호작용과 피드백을 통한 학습으로 검색 결과를 우선적으로 나타낸다(=증분식 학습).
끝으로 데이터의 중요도나 최신성, 이 외에도 사용자 지정 필터를 이용해서 검색 결과를 조정할 때에도 활용할 수 있다.
시험에서 검색 서비스에 대한 내용이 나오면 Kendra를 생각하자
Amazon Personalize
Personalize는 완전 머신 러닝 기반 서비스이며 이를 통해 실시간으로 맞춤형 추천을 하는 앱을 구축할 수 있다.
이때 추천에는 개인화된 제품 추천이나 재순위화, 맞춤형 다이렉트 마케팅이 있다.
- 사용자 검색 기록이나 구매기록, 관심사 등을 토대로 동일한 범주의 제품이나 전혀 다른 범주의 제품을 보여줌
Personalize 사용 사례 및 예시
사용 사례
- 소매점이나 미디어, 엔터테인먼트 등
예시
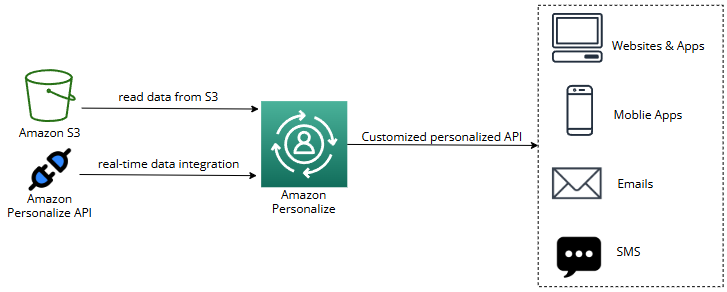
- AWS 내 Personalize로 가서 S3로부터 입력 데이터를 읽어 들인다
- 사용자 상호작용 등의 데이터
- Amazon Personalize API를 이용하면 Amazon Personalize 서비스에 실시간 데이터를 통합할 수도 있다
- 이 데이터는 이제 Customized personalized API로 보내지며 웹사이트, 애플리케이션, 모바일 애플리케이션 등으로 가거나 개인화 결과를 SMS나 이메일로 전송할 수도 있다
시험에선 머신 러닝 서비스를 이용하여 추천이나 개인화 추천을 구축한다는 말이 나오면 Amazon Personalize를 생각하자
Amazon Textract
Textract는 이름처럼 텍스트를 추출한다. 즉, 텍스트, 손글씨 또는 스캔을 한 문서의 데이터를 추출하는 것이다.
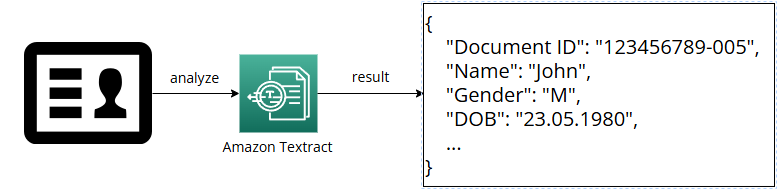
- 좌측에 면허증이 있고, 해당 면허증을 Amazon Textract에 업로드하면 자동으로 분석되어 결과가 데이터 파일로 제공된다.
- 생일, 문서 ID 등을 추출할 수 있게 되는 것
- 필요한 모든 데이터를 추출할 수 있음
- 폼과 테이블에서도 가능
- PDF와 이미지 등도 읽을 수 있음
Textract 사용 사례
- 금융 서비스
- 송장이나 재무 보고서를 처리
- 건강 보험
- 의료 기록과 보험 청구에 사용
- 공공 기관
- 세금 양식, 신분증 및 여권 등에 사용
AWS Machine Learning 요약
- Rekognition
- 얼굴 탐지 및 라벨링, 유명인 인식을 수행할 수 있음
- Transcribe
- 오디오를 텍스트로 전환하는 기능
- 자막을 얻을 수 있음
- Polly
- 텍스트로 오디오를 얻을 수 있음
- TTS
- Translate
- 번역을 할 수 있음
- Lex
- 챗봇과 같은 대화형 봇을 구축
- Connect
- 클라우드 고객 센터
- Comprehend
- 자연어 처리를 하는 방법
- SageMaker
- 개발자와 데이터 과학자를 위한 완전한 기능의 머신 러닝 서비스
- 기능이 많은 대신 복잡함
- Forecast
- 정확한 예측
- Kendra
- 머신 러닝 기반의 문서 검색 엔진
- Personalize
- 고객을 위한 실시간 맞춤형 추천 제공
- Textract
- 텍스트와 데이터를 탐지하고 다양한 문서에서 이를 추출하는데 사용
