백엔드 코드 리뷰 - Reactjs, Nodejs, Python을 이용하여 대학생 자취 지역 추천 서비스 만들기
백엔드에서 복습해본 핵심 키워드
https://github.com/znehraks/unibangcity-backend
디렉토리 구조
child_process:{spawn}을 이용한 nodejs와 python 연동
- nodejs와 python을 연동하기위해 child_process 라이브러리를 이용했다.
- 디버깅 시 고생했던 점은 인코딩 문제, 파일 경로 문제, ERR_HTTP_HEADERS_SENT 해결 이슈이다.
index.js
require("dotenv").config();
const express = require("express");
const bodyParser = require("body-parser").json();
const cors = require("cors");
//nodejs에서 python 파일을 실행하기 위한 라이브러리에서 spawn함수를 사용한다.
const spawn = require("child_process").spawn;
const app = express();
const connection = require("./connection");
const corsOptions = {
origin: "https://unibangcity.netlify.app/",
credentials: true,
};
app.use(cors(corsOptions));
app.post("/recommendation", bodyParser, (req, res) => {
//python 파일 실행후 나온 출력결과물을 할당하기 위한 변수
let data = "";
let jsonToSend = {};
try {
//child_process 실행의 결과를 result에 받는다.
//spawn의 첫 번째 변수는 자식프로세스에서 실행할 파일의 종류
//(여기선 파이썬 파일이므로 python이다. 리눅스 환경에서는 python3로 표기해야할 경우도 있다.)
//spawn의 두 번째 변수(배열)의 첫 번째 원소는 실행할 파일의 경로
//spawn의 두 번째 변수(배열)의 두 번째 원소부터는 실행할 파일로 전달해줄 파라미터들이다.
const result = spawn("python", [
"./python_code/cal_weight.py",
//Q1Answer는 대학교 이름
//cal_weight.py 파일에 sys.argv[1]로 전달된다. 밑에도 순서대로 sys.argv[n]
req.body.Q1Answer,
//univ_lon는 대학교 주소의 경도
req.body.univ_lon,
//univ_lat는 대학교 주소의 위도
req.body.univ_lat,
//Q2Answer는 검색을 원하는 최대 반경거리
req.body.Q2Answer,
//Q3Answer는 1순위 중요 요소
req.body.Q3Answer,
//Q4Answer는 2순위 중요 요소
req.body.Q4Answer,
//Q5Answer는 3순위 중요 요소
req.body.Q5Answer,
]);
//결과가 정상적으로 출력된 data를 받아왔을 때 실행되는 함수이다.
//콜백함수의 파라미터는 실행된 python 파일에서 넘어온 출력결과물(dataToSend)이다.
result.stdout.on("data", (dataToSend) => {
console.log(dataToSend.toString("utf8"));
console.log("stdout");
//위에서 선언한 data에 dataToSend을 더해준다(추가해준다).
data += dataToSend;
//클라이언트로 보내줄 jsonToSend의 속성을 추가해준다.
//stdout.on이 실행됐다는 것은 의도한대로 진행이 된 것이므로 success에 true를,
//data항목에 받아온 출력결과물을 담아준다.
jsonToSend["success"] = true;
jsonToSend["data"] = data;
});
//결과에서 에러가 발생할 경우 실행되는 함수이다.
//콜백함수의 파라미터는 실행된 python 파일에서 넘어온 출력결과물(dataToSend)이다.
//이 경우에는 dataToSend가 의도한 결과물이 아닐 것이다.
result.stderr.on("data", (dataToSend) => {
console.log("stderr");
//클라이언트에 의도한대로 진행이 안됐음을 알려야 하므로, json파일을 다음과 같이 설정했다.
jsonToSend["success"] = false;
jsonToSend["err_code"] = -1;
jsonToSend["err_msg"] = "불러오기에 실패했습니다. 다시 시도해주세요!";
jsonToSend["err_content"] = dataToSend.toString("utf8");
//디버깅 전에 각 result.stderr, stdout 함수들마다 res.json 응답을 생성했었는데,
//ERR_HTTP_HEADERS_SENT 에러가 발생해서 응답은 result.on에서 한번 보내는 것으로 디버깅했다.
return;
});
//child_process의 실행이 끝났을 때 실행되는 함수이다.
//콜백함수의 파라미터로 code를 반환하는데, 이는 code가 0일때는 정상적으로 에러 없이 마무리 된 것이고, stderr가 발생하면 code가 2로 반환된다.
result.on("close", (code) => {
console.log("close");
if (code !== 0) {
console.log(`child process close all stdio with code ${code}`);
}
//code가 0이라면 클라이언트에 json을 보낸다.
res.json(jsonToSend);
return;
});
} catch (e) {
console.log("error");
console.log(e);
return;
}
});
//추천받은 결과를 로그와 비슷한 용도로 DB에 저장하는 api이다.
//추후 이 추천받은 결과들을 바탕으로 새로운 서비스를 제공할 예정이다.
app.post("/recommendation/create", bodyParser, (req, res) => {
console.log(req.body);
const sql = `INSERT INTO recommendation_result( univ_name, univ_lat, univ_lon, scrapper_code, rank01_T, rank02_T, rank03_T, rank04_T, rank05_T, avg_T) VALUES('${req.body.univ_name}', ${req.body.univ_lat}, ${req.body.univ_lon}, '${req.body.scrapper_code}', '${req.body.rank01_T}', '${req.body.rank02_T}', '${req.body.rank03_T}', '${req.body.rank04_T}', '${req.body.rank05_T}', '${req.body.avg_T}')`;
connection.query(sql, (err, data, fields) => {
if (err) {
console.log("save Error");
console.log(data);
res.send({
success: false,
err_msg: "오류가 발생했습니다",
err_code: -3,
err_content: err.toString("utf8"),
data: data,
});
return;
}
console.log("save Success");
res.send({ success: true });
return;
});
});
app.listen(process.env.PORT, () => {
console.log(`listening on PORT: ${process.env.PORT}`);
});cal_weight.py
아래와 같이 클라이언트에서 보낸 항목들
- 선택된 대학교 명(univ_name)
- 선택된 대학교의 경도(univ_lon)
- 선택된 대학교의 위도(univ_lat)
- 검색을 원하는 최대 반경 거리(limit_dist)
- 1순위 중요 요소(first_weight)
- 2순위 중요 요소(second_weight)
- 3순위 중요 요소(third_weight)
을 이용하여 가중치 계산을 통해 자취방 추천 지역군 상위 5개 지역군과 세부 정보를 출력한다.
#/backend/python_code/cal_weight.py
import io
import sys
from calculate.cal_prev_module import cal_prev
from scrapper.get_residence_address_module import get_residence_address
from scrapper.find_rooms_module import find_rooms
from calculate.cal_T1_module import cal_T1
from calculate.cal_T2_module import cal_T2
from calculate.cal_T3_module import cal_T3
from calculate.cal_T4_module import cal_T4
from calculate.cal_T5_module import cal_T5
from calculate.cal_final_weight_module import cal_final_weight
from calculate.filter_top5_module import filter_top5
#출력의 인코딩을 utf-8로 설정한다
sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.detach(), encoding='utf-8')
#spawn함수에서 배열의 2번째 인자부터 보낸 것이 파라미터이므로
#순서대로 변수에 할당한다.
#index.js에서 req.body로 전해진 파라미터들
univ_name = sys.argv[1]
univ_lon = float(sys.argv[2])
univ_lat = float(sys.argv[3])
limit_dist = float(sys.argv[4])
first_weight = sys.argv[5]
second_weight = sys.argv[6]
third_weight = sys.argv[7]
#계산된 가중치
w1, w2, w3, w4, w5 = cal_prev(first_weight, second_weight, third_weight)
#디버깅 시 어디에서 에러가 생겼는지 파악하기 위해 아래와 같이 설계함
try:
refined_residence = get_residence_address(univ_lat, univ_lon)
except:
print("refined_residence Error")
try:
T1 = cal_T1(refined_residence, univ_lon, univ_lat, limit_dist)
except:
print("T1 Error")
try:
T2 = cal_T2(T1)
except:
print("T2 Error")
try:
T3 = cal_T3(T1)
except:
print("T3 Error")
try:
T4 = cal_T4(T1)
except:
print("T4 Error")
try:
T5 = cal_T5(T1)
except:
print("T5 Error")
try:
total = cal_final_weight(T1, T2, T3, T4, T5, w1, w2, w3, w4, w5,
first_weight,
second_weight,
third_weight)
except:
print("total Error")
try:
top5 = filter_top5(total)
except:
print("filter_top5 Error")
try:
top5_with_rooms = find_rooms(top5)
except:
print("find_rooms Error")
#이 출력문이 최종 결과로서 index에 dataToSend로 전해진다.
print(top5_with_rooms)
cal_prev_module.py
1순위, 2순위, 3순위로 선택된 중요 요소를 기반으로 전체 요소의 가중치를 계산하는 모듈이다
- 1순위가 학교와의 거리(T1), 2순위가 역세권(T2), 3순위가 가성비(T3)라면 weights 딕셔너리에서 첫 번째 요소(T1)의 내부 요소들에 0.5(50%)를 곱하고, 두 번째 요소(T2)의 내부 요소들에 0.3(30%)을 곱하고, 세 번째 요소(T3)의 내부 요소들에 0.2(20%)를 곱해서 최종 w1~w5의 가중치를 반환 한다.
- 1,2,3순위의 가중치를 50%,30%,20%로 정한 이유는 여러 번 테스트 해 본 결과 가장 성능이 좋았기에 정했다.
#/backend/python_code/calculate/cal_final_weight_module.py
def cal_prev(Q3Answer, Q4Answer, Q5Answer):
weights = [
{"code": "T1", "w1": 50, "w2": 10, "w3": 5, "w4": 20, "w5": 15},
{"code": "T2", "w1": 15, "w2": 50, "w3": 5, "w4": 20, "w5": 10},
{"code": "T3", "w1": 5, "w2": 5, "w3": 65, "w4": 20, "w5": 5},
{"code": "T4", "w1": 20, "w2": 10, "w3": 10, "w4": 50, "w5": 10},
{"code": "T5", "w1": 15, "w2": 10, "w3": 5, "w4": 20, "w5": 50}, ]
default_Q3_weight = 0.5
default_Q4_weight = 0.3
default_Q5_weight = 0.2
sum_w1 = 0
sum_w2 = 0
sum_w3 = 0
sum_w4 = 0
sum_w5 = 0
for i in weights:
if i["code"] == Q3Answer:
sum_w1 += default_Q3_weight * i["w1"]
sum_w2 += default_Q3_weight * i["w2"]
sum_w3 += default_Q3_weight * i["w3"]
sum_w4 += default_Q3_weight * i["w4"]
sum_w5 += default_Q3_weight * i["w5"]
elif i["code"] == Q4Answer:
sum_w1 += default_Q4_weight * i["w1"]
sum_w2 += default_Q4_weight * i["w2"]
sum_w3 += default_Q4_weight * i["w3"]
sum_w4 += default_Q4_weight * i["w4"]
sum_w5 += default_Q4_weight * i["w5"]
elif i["code"] == Q5Answer:
sum_w1 += default_Q5_weight * i["w1"]
sum_w2 += default_Q5_weight * i["w2"]
sum_w3 += default_Q5_weight * i["w3"]
sum_w4 += default_Q5_weight * i["w4"]
sum_w5 += default_Q5_weight * i["w5"]
return (sum_w1, sum_w2, sum_w3, sum_w4, sum_w5)
scrapper_module.py
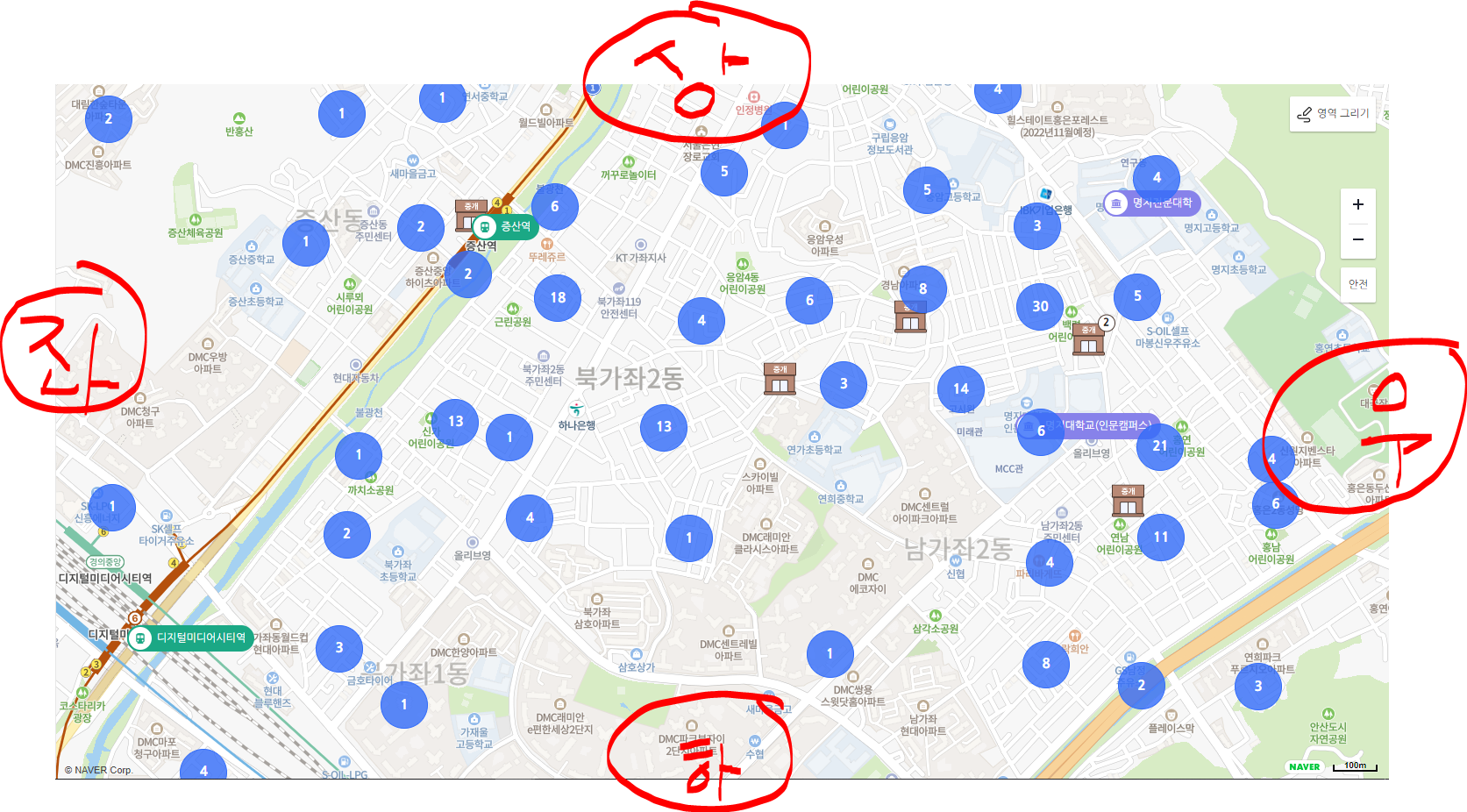
dabang_scrapper: 다방api에서 매물군들이 존재하는 지도에서 주소정보를 받아온다.
- 지도의 상하좌우 좌표를 파라미터로 정해주면 그 안에 존재하는 매물군의 정보를 얻는다.
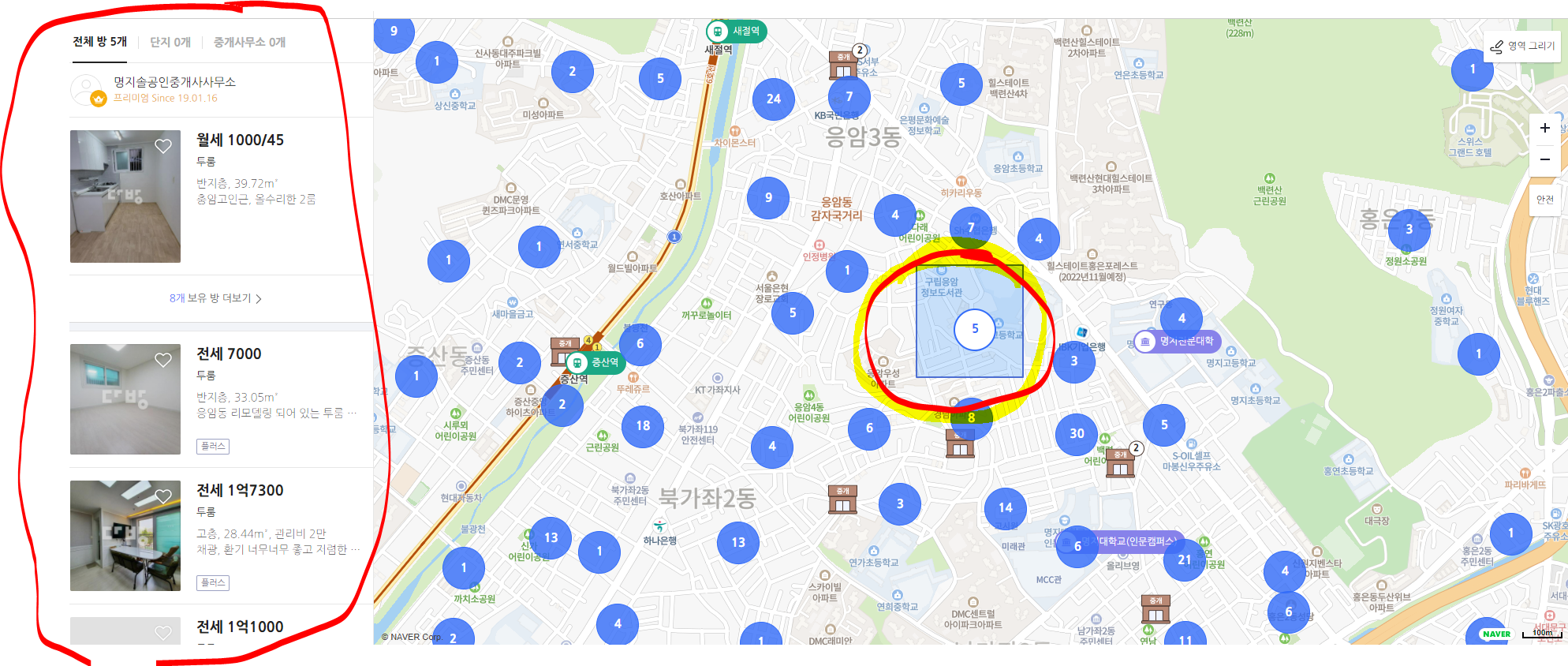
dabang_item_scrapper: 다방api에서 선택된 매물군의 세부 정보를 받아온다.
- 매물군 동그라미 한 개에 속한 각 매물들의 세부정보를 얻는다.
#/backend/python_code/scrapper/scrapper_module.py
#다방 api의 url이며, 올바른 위치에 매개변수를 넣어준다.
def dabang_scrapper(left_lon, btm_lat, right_lon, top_lat):
url = f"https://www.dabangapp.com/api/3/marker/multi-room?api_version=3.0.1&call_type=web&filters=%7B%22multi_room_type%22%3A%5B0%2C1%2C2%5D%2C%22selling_type%22%3A%5B0%2C1%2C2%5D%2C%22deposit_range%22%3A%5B0%2C999999%5D%2C%22price_range%22%3A%5B0%2C999999%5D%2C%22trade_range%22%3A%5B0%2C999999%5D%2C%22maintenance_cost_range%22%3A%5B0%2C999999%5D%2C%22room_size%22%3A%5B0%2C999999%5D%2C%22supply_space_range%22%3A%5B0%2C999999%5D%2C%22room_floor_multi%22%3A%5B1%2C2%2C3%2C4%2C5%2C6%2C7%2C-1%2C0%5D%2C%22division%22%3Afalse%2C%22duplex%22%3Afalse%2C%22room_type%22%3A%5B1%2C2%5D%2C%22use_approval_date_range%22%3A%5B0%2C999999%5D%2C%22parking_average_range%22%3A%5B0%2C999999%5D%2C%22household_num_range%22%3A%5B0%2C999999%5D%2C%22parking%22%3Afalse%2C%22animal%22%3Afalse%2C%22short_lease%22%3Afalse%2C%22full_option%22%3Afalse%2C%22built_in%22%3Afalse%2C%22elevator%22%3Afalse%2C%22balcony%22%3Afalse%2C%22loan%22%3Afalse%2C%22safety%22%3Afalse%2C%22pano%22%3Afalse%2C%22deal_type%22%3A%5B0%2C1%5D%7D&location=%5B%5B{left_lon}%2C{btm_lat}%5D%2C%5B{right_lon}%2C{top_lat}%5D%5D&version=1&zoom=15"
#캡챠를 피하기위해 header를 설정해준다.
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Referer': 'https://m.dabangapp.com/'}
#임포트한 requests 라이브러리를 이용하여 위의 url로 부터 결과를 얻는다.
res = requests.get(url, headers=header)
#json으로 변환하여 리턴한다.
site_json = json.loads(res.text)
return site_json
#해당 지도에서 동그라미 속 매물 정보를 얻어온다.(일단은 1페이지만 얻어온다)
def dabang_item_scrapper(code, page):
url = f"https://m.dabangapp.com/api/3/room/list/multi-room/region?api_version=3.0.1&call_type=web&code={code}&filters=%7B%22multi_room_type%22%3A%5B0%2C1%2C2%5D%2C%22selling_type%22%3A%5B0%2C1%2C2%5D%2C%22deposit_range%22%3A%5B0%2C999999%5D%2C%22price_range%22%3A%5B0%2C999999%5D%2C%22trade_range%22%3A%5B0%2C999999%5D%2C%22maintenance_cost_range%22%3A%5B0%2C999999%5D%2C%22room_size%22%3A%5B0%2C999999%5D%2C%22supply_space_range%22%3A%5B0%2C999999%5D%2C%22room_floor_multi%22%3A%5B1%2C2%2C3%2C4%2C5%2C6%2C7%2C-1%2C0%5D%2C%22division%22%3Afalse%2C%22duplex%22%3Afalse%2C%22room_type%22%3A%5B1%2C2%5D%2C%22use_approval_date_range%22%3A%5B0%2C999999%5D%2C%22parking_average_range%22%3A%5B0%2C999999%5D%2C%22household_num_range%22%3A%5B0%2C999999%5D%2C%22parking%22%3Afalse%2C%22animal%22%3Afalse%2C%22short_lease%22%3Afalse%2C%22full_option%22%3Afalse%2C%22built_in%22%3Afalse%2C%22elevator%22%3Afalse%2C%22balcony%22%3Afalse%2C%22loan%22%3Afalse%2C%22safety%22%3Afalse%2C%22pano%22%3Afalse%2C%22deal_type%22%3A%5B0%2C1%5D%7D&page={page}&version=1&zoom=15"
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Referer': 'https://m.dabangapp.com/'}
res = requests.get(url, headers=header)
site_json = json.loads(res.text)
rooms = site_json["rooms"]
#방 고유 아이디
rooms_id = []
#방 타입(원룸/투룸/쓰리룸 이상/오피스텔 등)
rooms_type = []
#방 위도
rooms_lat = []
#방 경도
rooms_lon = []
#방 가격(월세보증금3000만원에 월세50만원 이면 3000/50, 전세보증금 2억5000만원이면 2억5000으로 표기)
rooms_price_title = []
#방 판매 형식(월세/전세/매매 등)
rooms_selling_type = []
#방 대표 사진 url
rooms_img_url_01 = []
#방 특성(몇 제곱미터인지, 미등기 건물 여부, 안전/보안 등 세부정보)
rooms_desc = []
#방 특성(몇 제곱미터인지, 미등기 건물 여부, 안전/보안 등 세부정보2)
rooms_desc2 = []
#방 해시태그
rooms_hash_tags = []
#방 해시태그 개수(파생변수 클라이언트에서 가공하기 쉽도록 추가함)
rooms_hash_tags_count = []
for i in rooms:
rooms_id.append(i["id"])
rooms_type.append(i["room_type"])
rooms_lat.append(float(i["location"][1]))
rooms_lon.append(float(i["location"][0]))
rooms_price_title.append(i["price_title"])
rooms_selling_type.append(i["selling_type"])
rooms_img_url_01.append(i["img_url"])
rooms_desc.append(i["room_desc"])
rooms_desc2.append(i["room_desc2"])
hash_tags_count = len(i["hash_tags"])
rooms_hash_tags_count.append(hash_tags_count)
for index, j in enumerate(i["hash_tags"]):
rooms_hash_tags.append(j)
return rooms_id, rooms_type, rooms_lat, rooms_lon, rooms_price_title, rooms_selling_type, rooms_img_url_01, rooms_desc, rooms_desc2, rooms_hash_tags_count, rooms_hash_tagsget_residence_address_module.py
대학교 주소(위도,경도)로 매물군을 얻어옴
#/backend/python_code/calculate/get_residence_address_module.py
from scrapper.scrapper_module import dabang_scrapper
#위에서 설명한 dabang_scrapper 함수를 이용하여 선택된 지도 내에 매물 동그라미들을 받아옴
def get_residence_address(address_lat, address_lon):
left_lon = address_lon - 0.0412
btm_lat = address_lat - 0.0159
right_lon = address_lon + 0.0412
top_lat = address_lat + 0.0159
site_json = dabang_scrapper(left_lon,
btm_lat,
right_lon,
top_lat)
items = site_json["regions"]
refined_items = []
for i in items:
refined_items.append({
"code": i["code"],
"count": i["count"],
"lat": i["center"][1],
"lon": i["center"][0]
})
return refined_items
cal_T1_module.py
위에서 찾아낸 매물 동그라미 각각과 학교와의 거리(T1)에 등 수를 매겨서 가중치를 책정함
#/backend/python_code/calculate/get_residence_address_module.py
from operator import itemgetter
from haversine import haversine
# 나온 매물 리스트들 좌표로 각각의 lgeo를 인덱스로 하여
# 그 lego의 lat, lon을 이용한 거리이용 가중치를 모두 구함
# 학교 좌표와 해당 매물과의 거리를 모두 구하여(맨하탄거리) 1위부터 꼴찌까지 가중치를 구함(이전에, Q2의 최대거리에서 필터링하여 해당 거리를 벗어나는 좌표에 있는 항목은 이 단계에서 걸러냄)
def cal_T1(refined_residence, univ_lon, univ_lat, limit_dist):
limit_dist = float(limit_dist)
# 직선거리로 이루어진 배열 생성 후 저장
loc = []
# abs(i["lat"]-univ_lat)+abs(i["lon"]-univ_lon)
for i in refined_residence:
loc.append({"code": i["code"], "dist": haversine(
(i["lat"], i["lon"]), (univ_lat, univ_lon), unit='m'), "lat": i["lat"], "lon": i["lon"],
"count": i["count"]})
# 가까운 순으로 정렬
sorted_loc = sorted(
loc, key=itemgetter('dist'))
# limit_dist를 벗어나는 매물 제거
sorted_loc_filtered = []
for index, i in enumerate(sorted_loc):
if sorted_loc[index]["dist"] <= limit_dist:
sorted_loc_filtered.append(i)
else:
break
# 직선거리로 서열을 매겨 총 개수로 나눈 후 100점 만점(1위) 부터 0점까지(꼴찌) 1위부터 높은 점수로 배열함
# ex.총 매물이 50일 경우, 1위가 100점, 2위가 98점, 3위가 96점 ... 50위가 0점 (동률에 대한 고려는 추후에 함)
res = []
len_sorted_loc_filtered = len(sorted_loc_filtered)
# print(len_sorted_taxicab_geom)
for index, i in enumerate(sorted_loc_filtered):
res.append({"code": i["code"],
"count": i["count"], "dist": i["dist"], "lat": i["lat"], "lon": i["lon"],
"T1_weight": 100*(1/len_sorted_loc_filtered)*(len_sorted_loc_filtered-index)})
return res
# 각 매물에서 해당 구에 속한 지하철역중 가장 가까운 것의 거리를 가중치로 매겨서 그것 역시 1위부터 꼴찌까지 가중치로 매김
cal_T2_module.py
위에서 찾아낸 매물 동그라미 각각과 지하철 역과의 거리(T2)에 등 수를 매겨서 가중치를 책정함
#/backend/python_code/calculate/get_residence_address_module.py
import csv
from operator import itemgetter
cwd = "python_code/data/"
def cal_T2(refined_residence):
# 각각의 매물이 어느 지하철역이랑 가깝고(1개) 얼마나 가까운지 맨하탄거리로 표시
# 지하철csv 불러옴
subway = open(f'{cwd}subway_refined.csv',
'r', encoding='utf8')
subway_r = csv.reader(subway)
subway_r_list = list(subway_r)
# 중간결과를 담을 subway_list 생성
subway_list = []
# 매물리스트를 outer에 지하철리스트를 inner에 두고 각 매물에서 모든 지하철역과의 거리를 계산하여
# 가장 가까운 지하철 역과 그 역과의 거리를 구함
for index_r, i in enumerate(refined_residence):
# 임시로 매물과 모든역과의 거리를 계산할 리스트
temp = []
for index_s, j in enumerate(subway_r_list):
if(index_s == 0):
continue
temp.append(abs(i["lat"] - float(j[7])) +
abs(i["lon"] - float(j[8])))
if(index_s == len(subway_r_list)-1):
subway_list.append({"code": i["code"], "nearest": temp.index(
min(temp))+1, "subway_dist": min(temp)})
subway.close()
# 거리가 가까운 순으로 정렬함
sorted_subway_list = sorted(
subway_list, key=itemgetter('subway_dist'))
# 최종결과를 담을 리스트 생성
res = []
len_sorted_subway_list = len(sorted_subway_list)
# T2최종 가중치 추산을 위한 계산작업
for index, i in enumerate(sorted_subway_list):
res.append({"code": i["code"], "nearest": i["nearest"], "subway_dist": i["subway_dist"],
"T2_weight": 100*(1/len_sorted_subway_list)*(len_sorted_subway_list-index)})
return res
# 맨하탄거리로 서열을 매겨 총 개수로 나눈 후 100점 만점(1위) 부터 0점까지(꼴찌) 1위부터 높은 점수로 배열함
# ex.총 매물이 50일 경우, 1위가 100점, 2위가 98점, 3위가 96점 ... 50위가 0점 (동률에 대한 고려는 추후에 함)
cal_T3_module.py
위에서 찾아낸 매물 동그라미 각각이 속한 구별 물가(T3)에 등 수를 매겨서 가중치를 책정함
#/backend/python_code/calculate/get_residence_address_module.py
import csv
from operator import itemgetter
cwd = "python_code/data/"
# 구 별 물가로 가중치 구함(위도,경도 값으로 해당 점이 어느 구에 속하는지 판별 후, 그 구의 범죄율 가중치로 정함)
def cal_T3(refined_residence):
# 물가 csv 불러옴
price = open(f'{cwd}price_refined.csv', 'r', encoding='utf8')
price_r = csv.reader(price)
price_r_list = list(price_r)
# 중간결과 담을 리스트
price_list = []
# 매물리스트를 outer에 지하철리스트를 inner에 두고 각 매물에서 모든 구 와의 거리를 계산하여
# 가장 가까운 구와 그 구와의 거리를 구함
for index_r, i in enumerate(refined_residence):
# 임시로 구와 모든매물과의 거리를 계산할 리스트
temp = []
for index_p, j in enumerate(price_r_list):
if(index_p == 0):
continue
temp.append(abs(i["lat"] - float(j[5])) +
abs(i["lon"] - float(j[6])))
if(index_p == len(price_r_list)-1):
price_list.append({"code": i["code"], "nearest": temp.index(
min(temp))+1, "gu_dist": min(temp)})
price.close()
# 거리가 가까운 순으로 정렬함
sorted_price_list = sorted(
price_list, key=itemgetter('gu_dist'))
# 최종결과를 담을 리스트 생성
res = []
len_sorted_price_list = len(sorted_price_list)
# T3최종 가중치 추산을 위한 계산작업
for index, i in enumerate(sorted_price_list):
res.append({"code": i["code"], "nearest": i["nearest"], "gu_dist": i["gu_dist"],
"T3_weight": int(price_r_list[int(i["nearest"])][4])})
return res
cal_T4_module.py
위에서 찾아낸 매물 동그라미 각각이 속한 구별 범죄율을 역순으로 안전지수로 환산한 값(T4)에 등 수를 매겨서 가중치를 책정함
#/backend/python_code/calculate/get_residence_address_module.py
import csv
from operator import itemgetter
cwd = "python_code/data/"
def cal_T4(refined_residence):
# 범죄율 csv 불러옴
crime = open(f'{cwd}crime_refined.csv', 'r', encoding='utf8')
crime_r = csv.reader(crime)
crime_r_list = list(crime_r)
# 중간결과 담을 리스트
crime_list = []
# 매물리스트를 outer에 지하철리스트를 inner에 두고 각 매물에서 모든 구 와의 거리를 계산하여
# 가장 가까운 구와 그 구와의 거리를 구함
for index_r, i in enumerate(refined_residence):
# 임시로 구와 모든매물과의 거리를 계산할 리스트
temp = []
for index_c, j in enumerate(crime_r_list):
if(index_c == 0):
continue
temp.append(abs(i["lat"] - float(j[3])) +
abs(i["lon"] - float(j[4])))
if(index_c == len(crime_r_list)-1):
crime_list.append({"code": i["code"], "nearest": temp.index(
min(temp))+1, "gu_dist": min(temp)})
crime.close()
# 거리가 가까운 순으로 정렬함
sorted_crime_list = sorted(
crime_list, key=itemgetter('gu_dist'))
# 최종결과를 담을 리스트 생성
res = []
len_sorted_crime_list = len(sorted_crime_list)
# T4최종 가중치 추산을 위한 계산작업
for index, i in enumerate(sorted_crime_list):
res.append({"code": i["code"], "nearest": i["nearest"], "gu_dist": i["gu_dist"],
"T4_weight": int(crime_r_list[int(i["nearest"])][1])})
return res
cal_T5_module.py
위에서 찾아낸 매물 동그라미 각각이 가지고 있는 매물의 수(T5)에 등 수를 매겨서 가중치를 책정함
#/backend/python_code/calculate/get_residence_address_module.py
from operator import itemgetter
cwd = "python_code/data/"
# 매물 수로 가중치를 구함(나온 refined_items의 count가 많은 것 순으로 높은 점수를 매겨서 등수 별로 순차적인 가중치를 정함
# 예. 매물이 총 50개이면 1위 100점, 2위 98점, 3위 96점 ... 50위 0점)
def cal_T5(refined_residence):
sorted_count_list = sorted(
refined_residence, key=itemgetter('count'), reverse=True)
# 최종결과를 담을 리스트 생성
res = []
len_sorted_count_list = len(sorted_count_list)
# T4최종 가중치 추산을 위한 계산작업
for index, i in enumerate(sorted_count_list):
res.append({"code": i["code"], "count": i["count"],
"T5_weight": 100*(1/len_sorted_count_list)*(len_sorted_count_list-index)})
return res
cal_final_weight_module.py
위의 단계를 거친 가중치 값들을 이용하여 최종 등 수를 산정하고, 등 수를 매길 때, 1,2,3순위 중요요소가 평균 미달인 후보군과 매물 수가 현저히 부족하여 5개보다 미달인 지역에서의 기준에 미달하는 1위 후보도 제외한다.
#/backend/python_code/calculate/get_residence_address_module.py
from operator import itemgetter
# 모든 매물의 점수에 가중치를 곱하여 환산한 최종 값을 구한다.
def cal_final_weight(T1, T2, T3, T4, T5, w1, w2, w3, w4, w5,
first_weight,
second_weight,
third_weight):
# lgeo 별로 lgeo 순으로 정렬,
sorted_T1 = sorted(T1, key=itemgetter('code'))
sorted_T2 = sorted(T2, key=itemgetter('code'))
sorted_T3 = sorted(T3, key=itemgetter('code'))
sorted_T4 = sorted(T4, key=itemgetter('code'))
sorted_T5 = sorted(T5, key=itemgetter('code'))
# T1,T2,T3,T4,T5 모두 더함
res = []
for i in range(0, len(sorted_T1)):
res.append({
"code": sorted_T1[i]["code"],
"T1": round(sorted_T1[i]["T1_weight"]*float(w1)/100),
"T2": round(sorted_T2[i]["T2_weight"]*float(w2)/100),
"T3": round(sorted_T3[i]["T3_weight"]*float(w3)/100),
"T4": round(sorted_T4[i]["T4_weight"]*float(w4)/100),
"T5": round(sorted_T5[i]["T5_weight"]*float(w5)/100),
"total_weight": round(sorted_T1[i]["T1_weight"]*float(w1)/100 +
sorted_T2[i]["T2_weight"]*float(w2)/100 +
sorted_T3[i]["T3_weight"]*float(w3)/100 +
sorted_T4[i]["T4_weight"]*float(w4)/100 +
sorted_T5[i]["T5_weight"]*float(w5)/100),
"lat": sorted_T1[i]["lat"],
"lon": sorted_T1[i]["lon"],
})
# total 내림차순으로 sorting함
avgs = [sum(i["T1"] for i in res)/len(res),
sum(i["T2"]
for i in res)/len(res),
sum(i["T3"]
for i in res)/len(res),
sum(i["T4"]
for i in res)/len(res),
sum(i["T5"] for i in res)/len(res),
sum(i["total_weight"] for i in res)/len(res), ]
res_2 = []
res_sorted = sorted(res, key=itemgetter('total_weight'), reverse=True)
rank = 0
for index, i in enumerate(res_sorted):
if(i[first_weight] >= avgs[int(str(first_weight).split("T")[1])-1] or i[second_weight] >= avgs[int(str(second_weight).split("T")[1])-1] or i[third_weight] >= avgs[int(str(third_weight).split("T")[1])-1] or i["total_weight"] >= avgs[5]):
rank += 1
res_2.append({
"rank": rank,
"code": i["code"],
"T1": i["T1"],
"T2": i["T2"],
"T3": i["T3"],
"T4": i["T4"],
"T5": i["T5"],
"total_weight": i["total_weight"],
"거리": i["T1"],
"역세권": i["T2"],
"가성비": i["T3"],
"안전": i["T4"],
"매물": i["T5"],
"총점": i["total_weight"],
"lat": i["lat"],
"lon": i["lon"],
"T1_avg": avgs[0],
"T2_avg": avgs[1],
"T3_avg": avgs[2],
"T4_avg": avgs[3],
"T5_avg": avgs[4],
"total_weight_avg": avgs[5],
"평균 거리": avgs[0],
"평균 역세권": avgs[1],
"평균 가성비": avgs[2],
"평균 안전": avgs[3],
"평균 매물": avgs[4],
"평균 총점": avgs[5],
"rooms_id": [],
"rooms_type": [],
"rooms_location_lat": [],
"rooms_location_lon": [],
"rooms_hash_tags_count": [],
"rooms_hash_tags": [],
"rooms_desc": [],
"rooms_desc2": [],
"rooms_img_url_01": [],
"rooms_price_title": [],
"rooms_selling_type": [],
})
else:
continue
return res_2
filter_top5_module.py
위의 단계를 거친 가중치 값들을 이용하여 상위 5개 동그라미(매물군)을 추출한다
#/backend/python_code/calculate/get_residence_address_module.py
# TOP5 골라서 이 주변 정보들 가져옴
def filter_top5(total):
# 5개 추려서 위도, 경도 가져옴
top5 = []
for index, i in enumerate(total):
if index == 5:
break
top5.append(i)
# 그 위도,경도로 주변 근린시설 정보까지 조합하여 반환
return top5
find_rooms_module.py
가져온 정보 중 클라이언트로 전송할 정보만을 추출한다.
#/backend/python_code/calculate/get_residence_address_module.py
from scrapper.scrapper_module import dabang_item_scrapper
def find_rooms(top5):
for i in top5:
rooms_id, rooms_type, rooms_lat, rooms_lon, rooms_price_title, rooms_selling_type, rooms_img_url_01, rooms_desc, rooms_desc2, rooms_hash_tags_count, rooms_hash_tags = dabang_item_scrapper(
i["code"], 1)
i["rooms_id"] = rooms_id
i["rooms_type"] = rooms_type
i["rooms_location_lat"] = rooms_lat
i["rooms_location_lon"] = rooms_lon
i["rooms_price_title"] = rooms_price_title
i["rooms_selling_type"] = rooms_selling_type
i["rooms_img_url_01"] = rooms_img_url_01
i["rooms_desc"] = rooms_desc
i["rooms_desc2"] = rooms_desc2
i["rooms_hash_tags_count"] = rooms_hash_tags_count
i["rooms_hash_tags"] = rooms_hash_tags
return top5
위의 과정을 거친 결과물을 print 로 출력하게 되면 그 결과가 index.js에서 result.stdout의 콜백함수 속 dataToSend 파라미터로 전송된다.
코더가 아닌 프로그래머를 지향하는 개발자