#everythingisarackapp 이란 말을 들어보았는가? 루비 세계에서 모든 것이 rack app이라 할 정도로 rack은 굉장히 중요한 의미를 가진다.
rack이란 무엇일까?
간단히 말하자면 rack은 일종의 인터페이스이다. 우리의 rack app은 이 인터페이스를 구현한 것이라 볼 수 있다.
먼저 rack이 풀고자 하는 문제를 살펴보자.
rack이 풀고자 하는 문제
(출처: https://www.akshaykhot.com/definitive-guide-to-rack/)
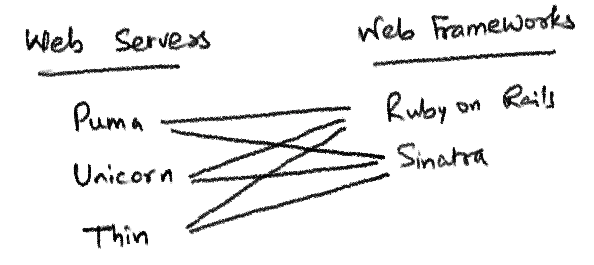
루비 세계에는 여러 웹 서버와 여러 웹 프레임워크가 있다. 프레임워크를 변경하는 일은 드물겠지만, 여러 이유로 인해 웹서버를 변경하는 일이 생길 수도 있을 것이다. 예를 들자면 unicorn의 slow client 대응 능력의 한계로 puma로 변경하기로 결정하는 일이 생길 수도 있는 것이다(물론 unicorn-nginx 조합으로 풀 수 있는 문제일 것이다).
일반적으로, 브라우저에서 리퀘스트를 보내면 웹서버를 거쳐 우리의 레일즈 앱으로 들어오게 된다. 이때 웹서버와 레일즈는 어떻게 통신하는 것일까? 위 이미지 처럼 unicorn-rails 조합이라면 A의 방식으로 통신하고 puma-rails 조합이라면 B의 방식으로 통신하는 식일까? puma-sinatra 조합이라면 또 다른 방식으로 통신하는가?
직접 간단한 앱을 작성하여 여러 웹서버와 통신해보도록 하자.
rack-test 폴더를 만들고 그 안에 config.ru 파일을 만들자. (참고: ru 파일 역시 일반적인 루비 파일과 같다. ru는 rackup의 약자이다)
# config.ru
class App
def call(env)
headers = { 'Content-Type' => 'text/html' }
response = ['<h1>hello Rack</h1>']
[200, headers, response]
end
end
run App.new
run메서드는call메서드에 응답하는 루비 object를 argument로 받아 이 object에 대해 call 메서드를 호출한다. 왜call메서드를 호출하는지는 차차 살펴볼 것이다.
puma
puma gem을 설치하고 rack-test 폴더 안에서 puma command를 사용하여 puma를 기동시켜 보자.
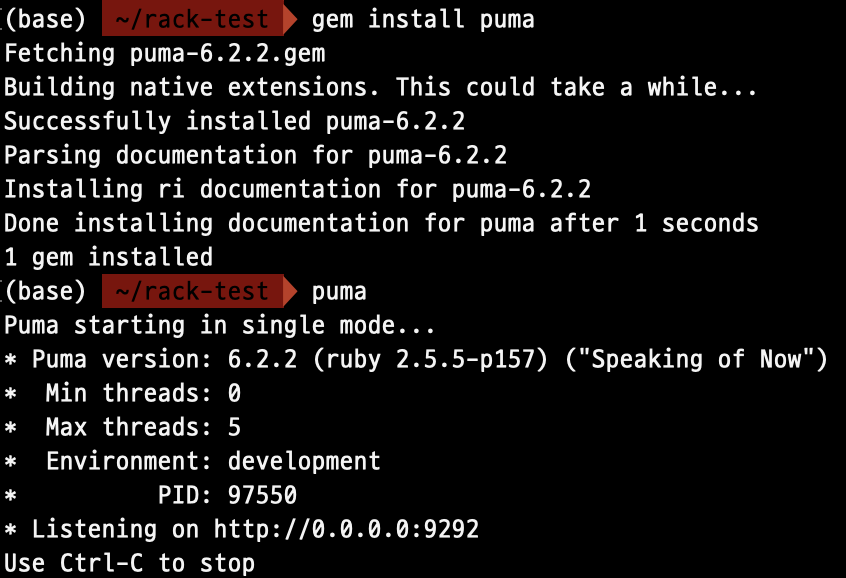
puma를 비롯한 웹서버들은 기본적으로 config.ru 파일을 찾아 웹 애플리케이션을 기동시킨다.
브라우저 주소창에 http://localhost:9292 를 입력해보면 위에서 작성한 코드의 response body를 볼 수 있을 것이다.
다른 웹서버
이번엔 unicorn을 설치 후 기동시켜보자. 그 후 http://localhost:8080 을 방문해보자.
gem install unicorn
unicorn내친 김에 thin도 설치 해보고 http://localhost:3000 를 방문해보자.
gem install thin
thin start놀랍게도 어떠한 웹서버를 사용하더라도 우리는 같은 화면을 보게 될 것이다. 심지어 우리는 우리 앱(config.ru에 정의했던)의 코드 한 줄도 수정하지 않았다.
인터페이스를 사용하여 OCP를 지키듯, 우리의 앱과 웹서버도 코드 한 줄의 변경 없이 작동하고 있는 것이다.
OCP 확인하러 가기
Rack Interface
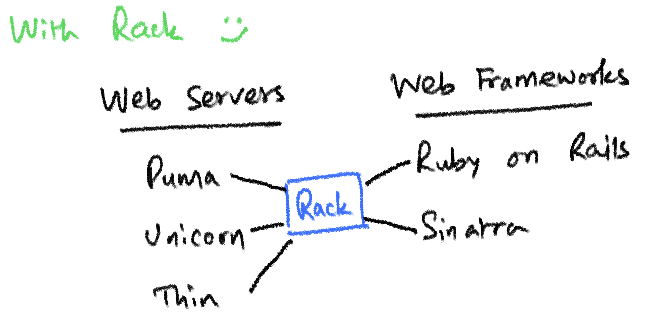
위와 같은 결과가 나온 이유는, 1. 우리의 앱이 rack interface를 구현했기 때문이고, 2. 우리가 사용한 웹서버들이 rack-compliant(rack 준수, 혹은 rack 호환) 웹서버이기 때문이다.
우리 앱 코드를 보면 세 가지 특징이 있다.
1. `call` 메서드를 정의했다.
2. `env` 변수를 인자로 받는다.
3. 세 가지 값이 담긴 배열을 리턴한다([status code, headers, response])위 세 가지 배열의 값 중 하나인 response는
#each메서드에 응답하여 string을 반환하는 객체이다. 보통은 배열일 것이다. 우리 코드에서도 response는 배열의 형태인 것을 볼 수 있다.
만약 어떠한 코드가 이 세가지 조건을 모두 충족한다면, 그 코드는 rack interface를 구현한 것이다. 즉 rack 호환되는 웹서버라면 어떠한 것과도 통신이 된다는 의미이다.
여기서 env는 hash이며, HTTP request의 모든 정보를 담고 있다. 예를 들면 아래와 같다.
env = {
'REQUEST_METHOD' => 'GET',
'PATH_INFO' => '/hello',
'HTTP_HOST' => 'myapp.com',
# ...
}이를 통해 rack 호환 웹서버들이 하는 여러가지 일 중 아주 중요한 한 가지를 알 수 있다.
바로 HTTP request를 env hash 형태로 변환하고, 이 env를 인자로 하여 @app.call(env)를 호출하는 일이다.
실제로 위의 puma, unicorn 등의 웹서버들이 @app.call(env) 를 호출하기 때문에 rack 호환 웹서버로 불리는 것이다.
정리하자면, 우리는 rack 호환 웹서버를 사용했고, 우리가 작성한 앱은 rack interface를 충실히 구현했기에 통신이 원활히 이루워졌다는 것을 알 수 있다.
그렇다면 레일즈는 어떨까? 레일즈도 rack interface를 구현한 것일까? 당연하겠지만, 물론 구현했다. rails 애플리케이션이 있다면 config.ru 파일을 봐보자. 아래와 같은 코드를 볼 수 있을 것이다(config.ru파일은 루트 폴더 밑에 있다)
# This file is used by Rack-based servers to start the application.
require_relative 'config/environment'
run Rails.application
...Rails.application은 #call 메서드를 갖고 있으며 이는 Rails::Application이 상속받은 Rails::Engine 클래스에 정의되어 있다.
module Rails
class Engine < Railtie
# Define the Rack API for this engine.
def call(env)
env.merge!(env_config)
if env['SCRIPT_NAME']
env.merge! "ROUTES_#{routes.object_id}_SCRIPT_NAME" => env['SCRIPT_NAME'].dup
end
app.call(env)
end
end
end결론
즉, rack이 풀고자 하는 문제는 여러 rack-compliant 웹서버와 rack interface를 구현한 앱이 각자의 코드 변경없이 통신할 수 있게 하는 것이다.
puma-rails 조합에서 unicorn-rails 조합으로 바뀐다고 일일이 코드를 변경할 필요가 없다.
자바 인터페이스 구현과 같이, 우리의 앱은 웹서버가 무엇인지 알 필요 없다. 웹서버 역시 우리의 앱이 어떤 프레임워크로 구현되어 있는지 알 필요 없다. 그저 서로 rack 프로토콜을 준수하고 있다면, 통신할 수 있는 것이다.
(출처: https://www.akshaykhot.com/definitive-guide-to-rack/)
Rack Middleware
계속해서 말해왔지만, 위에서 우리가 만든 앱은 rack 앱이다. rack interface를 구현했기 때문이다.
이렇듯 우리는 쉽고 간편하게 애플리케이션을 만들 수 있다. 만약 내가 원하는 '부가 기능'이 있다면, 그 기능을 직접 우리의 (상대적으로)거대한 레일즈 앱에 꾸역꾸역 붙여넣는 것보다, rack interface를 구현한 작고 재사용 가능한 애플리케이션을 뚝딱 만들어 레일즈 앱에 붙이는 방식으로 작업한다면 더욱 효율적일 것이다.
참고로 이는 OOP 원칙 중 SRP를 지키는 방법이 될 수도 있을 것이다.
SRP 확인하러 가기
Logger Middleware
위에서 작성했던 코드를 조금 수정해보자. 이제 우리 앱은 무언가 계산을 하는 앱이 되었다. 즉 우리 앱의 핵심기능은 '계산' 이다.
# calculator.rb
class Calculator
def call(env)
do_calc_something
[200, {"Content-Type" => "text/plain"}, ["Hello World!"]]
end
end# config.ru
require_relative 'calculator'
run Calculator.new당연한 말이지만, 우리의 계산기 앱은 rack app이다. env hash를 인자로 받는 #call 메서드를 정의했고, 해당 메서드에서 3가지 값을 담은 배열을 리턴하기 때문이다.
이제 우리의 앱에 로깅 기능을 추가하고 싶다고 하자. 아래와 같이 될 것이다.
# calculator.rb
class Calculator
def call(env)
puts "calculator begin" # 추가된 부분
do_calc_something
puts "calculator end" # 추가된 부분
[200, {"Content-Type" => "text/plain"}, ["Hello World!"]]
end
end앞서 말했지만, 이는 SRP를 위반한다. 우리의 앱은 계산기이다. 그런데 로깅 기능 역시 수행하고 있다. 지금이야 코드가 간단하니 한 눈에 알아볼 수 있지만, 코드가 길어지기 시작한다면 코드가 뒤섞여 디버깅 하기 힘들어질 것이다.
즉, 기능을 분리해야 한다.
자바 진영에서는 AOP를 통해 관심사를 분리해내는 것으로 알고 있다. 루비 진영, 특히 레일즈에서는 이러한 미들웨어를 사용하여 관심사 분리를 하는 것일까? 마땅히 Rails AOP 관련 글이나 가이드가 없어서 잘 모르겠다.
이제 rack interface를 구현한 작은 로깅용 rack app을 만들어보자.
# app.rb
class Logger
def initialize(app)
@app = app
end
def call(env)
puts "calculator begin"
status, headers, body = @app.call(env)
puts "calculator end"
[status, headers, body]
end
end
class Calculator
def call(env)
do_calc_something
[200, {"Content-Type" => "text/plain"}, ["Hello World!"]]
end
end# confg.ru
require_relative 'app'
run Logger.new(
Calculator.new
)이렇듯 미들웨어 체이닝을 통해 각 관심사, 혹은 기능을 분리해냈다. SRP가 지켜진 것이다.
이와 같이 미들웨어를 사용하면 다양한 부가기능을 우리의 레일즈 앱에 붙일 수 있게 된다.
다른 포스트에서도 얘기할 예정이지만, 브라우저로부터 request가 들어오면 먼저 웹서버에서 받고, HTTP를 env hash 형태로 변환 후 @app.call(env) 를 호출하면, 여러 미들웨어를 거쳐, 미들웨어 체이닝을 통해 우리 앱으로 전달되게 된다.
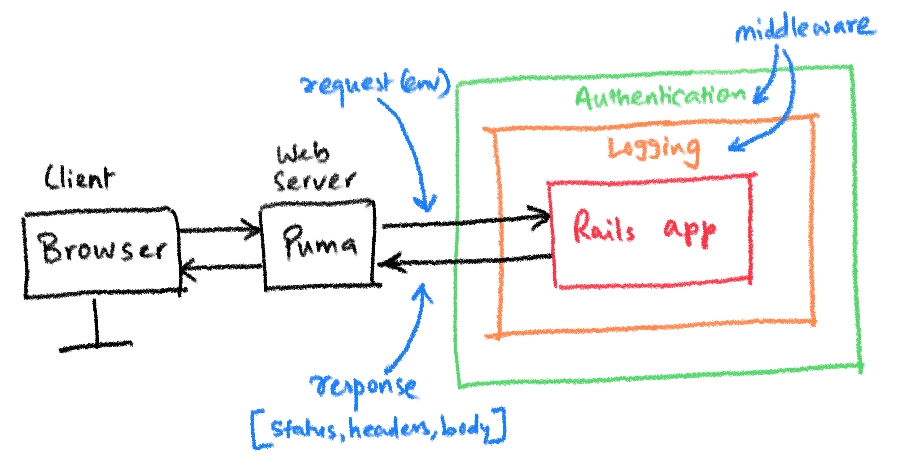
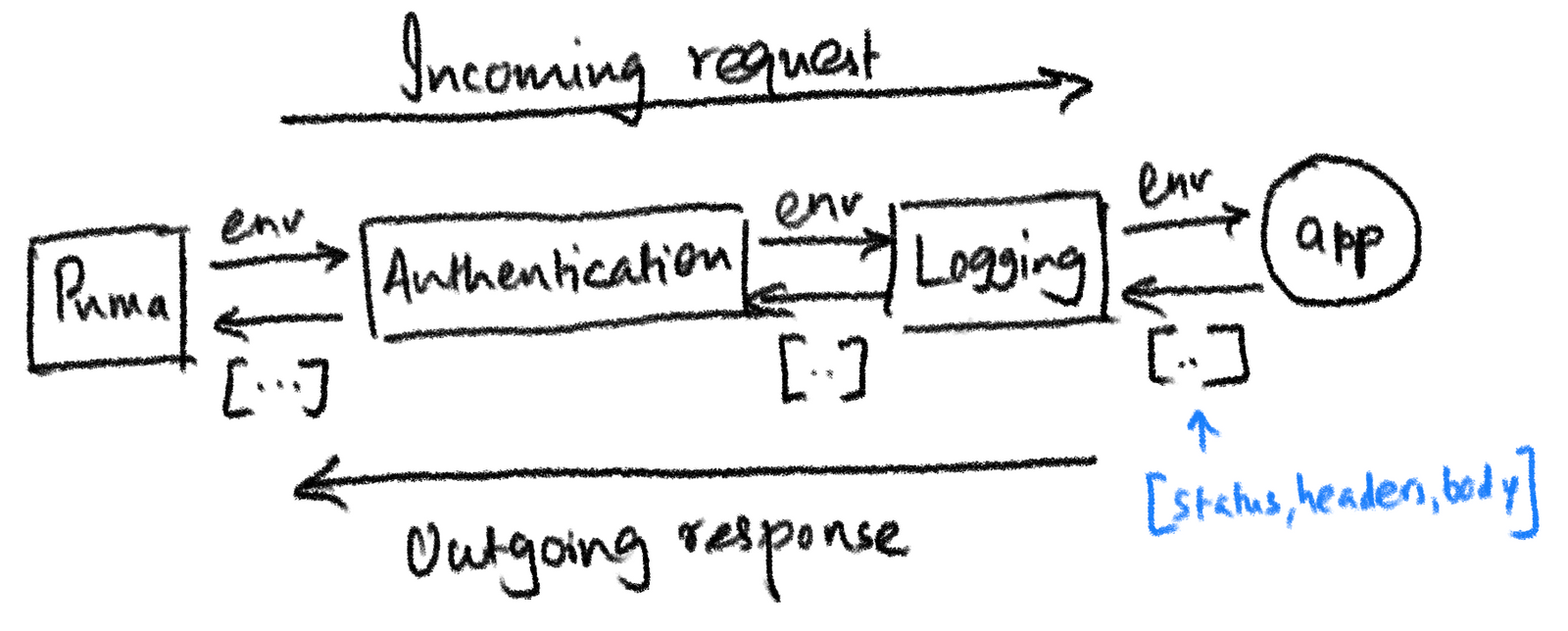
(출처: https://www.akshaykhot.com/definitive-guide-to-rack/)
레일즈에서도 많은 미들웨어를 사용하고 있다. 확인하고 싶다면 아래 커맨드를 사용하여 확인해보면 된다.
$ bin/rails middleware
use Rack::Sendfile
use ActionDispatch::Executor
use ActiveSupport::Cache::Strategy::LocalCache::Middleware
use Rack::Runtime
use Rack::MethodOverride
use ActionDispatch::RequestId
use ActionDispatch::RemoteIp
use Rails::Rack::Logger
use ActionDispatch::ShowExceptions
use ActionDispatch::DebugExceptions
use ActionDispatch::Callbacks
use ActionDispatch::Cookies
use ActionDispatch::Session::CookieStore
use ActionDispatch::Flash
use ActionDispatch::ContentSecurityPolicy::Middleware
use Rack::Head
use Rack::ConditionalGet
use Rack::ETag
use Rack::TempfileReaper
run MyApp::Application.routes마무리
routes.rb 파일에 get '/posts' => 'posts#index' 라는 route가 있다고 해보자. 레일즈 개발자라면 너무나도 쉽게 GET /posts 요청이 들어오면 PostsController의 index action으로 가겠구나 라는 것을 알 수 있다.
레일즈 코드를 따라가다 보면 최종적으로 PostsController.action(:index) 가 호출되는 것을 볼 수 있다(자세한 건 나중에 포스팅할 예정이다).
ActionController 코드를 보면 이 action메서드를 볼 수 있다.
class ActionController::Base
def self.action(name)
->(env) {
request = ActionDispatch::Request.new(env)
response = ActionDispatch::Response.new(request)
controller = self.new(request, response)
controller.process_action(name)
response.to_a
}
end
...
end이 action 클래스 메서드는 lambda를 리턴한다. 이 lambda는 인자로 env hash를 받고, 배열을 리턴한다. 또한 lambda는 #call 메서드에 응답한다.
즉 컨트롤러도 작은 rack app인 것이라 볼 수 있다.
이 글의 맨 첫 줄에서 말했던 #everythingisarackapp 이 문구가 이제는 수긍이 갈 것이다.
참고자료
https://www.akshaykhot.com/definitive-guide-to-rack/
https://blog.skylight.io/the-lifecycle-of-a-request/
https://andrewberls.com/blog/post/rails-from-request-to-response-part-2--routing
