2018 RailsConf에서 Vaidehi Joshi가 발표한 레일즈 router 관련 영상이 굉장히 유익하여 이를 늦게나마 정리해보고자 한다. 국내에는 레일즈 router를 어떻게 사용하는지에 대한 글은 좀 있으나, 어떻게 동작하는지 그 원리에 대한 블로그 글은 찾아보기 힘들다. 해당 영상 번역이 이러한 원리를 이해하는데에 도움이 되었으면 한다. 해당 영상에선 자막을 제공하니 자막과 함께 해당 영상을 시청하길 권장하나, 만약 영어 영상이 부담된다면 여기 정리한 글을 봐도 충분할 것이다.
참고로 지금과 같이 인용 표시에 적혀있는 말은 영상에서 나온 것이 아닌 저자(나)가 하는 말이다. 또한 완벽한 번역이 아니며 중간중간 의역도 들어가 있으니 감안해서 보길 바란다.
Rails Router는 어떻게 동작하는가?
router가 어떻게 작동하는지 알기 위한 가장 첫 번째 스텝은, router가 어디서 작동하는지를 아는 것 부터이다. 즉, 앱의 life cycle 내에서 router가 어디에서 작동하는지 알아야 한다.
웹서버에서
@app.call(env)형식으로 우리의 rack app을 호출한다. 레일즈 엔진은 미들웨어 스택을 rack 애플리케이션으로 빌드하는데 이 것이 바로@app이다.
아래 명령어를 통해 미들웨어 스택을 확인해보자.
-> bin/rails middleware
use Webpacker::DevServerProxy
use Rack::MiniProfiler
use ActionDispatch::HostAuthorization
use Rack::Sendfile
use ActionDispatch::Static
use ActionDispatch::Executor
...
use Rack::ConditionalGet
use Rack::ETag
use Rack::TempfileReaper
use Warden::Manager
use ActionDispatch::Cookies
use ActionDispatch::Session::CookieStore
use Bullet::Rack
use OmniAuth::Builder
run MyApp::Application.routes // 중요!우리의 앱은 위에서 아래의 순서로 해당 미들웨어들을 실행한다.
미들웨어란 무엇인가? 미들웨어는 또 다른 rack app을 인수로 받는 rack app이다.
다른 rack app으로 초기화되지 않는 standalone rack app은 흔히 rack endpoint라 한다.
MyApp::Application.routes
MyApp::Application.routes가 미들웨어 스택의 마지막이기에 우리는 .routes 메서드가 무엇을 리턴하는지 알아봐야 한다.
lib/rails/engine.rb 파일 안에 routes 메서드의 정의가 있다.
def routes
# ...
@routes
endroutes 메서드는 우리의 모든 routes의 인스턴스를 리턴한다(원문: this routes method returns an instance of all of our routes.)
이제 우리는 (request life cycle내에서) request가 미들웨어 스택을 거쳐 라우터로 전달된다는 것을 알았다.
다음의 질문은, 라우터가 어떻게 request를 라우팅하는가? 이다.
get 'recipes/:id', to: 'recipes@show'
post 'articles(.:format)', to: 'articles#create'
# more routes라우터로 들어오는 request는 어떤 방식으로 이 중 올바른 경로로 보내지는 것인가?
우리가 떠올려 볼 만한 naive한 솔루션으로는, 올바른 경로를 찾을 때 까지 routes의 모든 경로를 하나씩 확인해 보는 것이다.
즉, 루프를 작성해서 하나하나 iterate 하며 이 경로가 맞는지 확인하는 것이다.
if request_path =~ /^\articles$/
# go to articles#index
elsif request_path =~ /^\recipes$/
# go to recipes#index
elsif ...
...
else
...
end이는 좋지 않은 접근법이다. 경로가 많다면, 이에 따라 if문 역시 길어질 수 있기 때문이다.
또 다른 문제로는, routes 파일이 커짐에 따라 확장이 잘 되지 않는다는 점이다.
n 개의 routes가 있다고 해보자. 이는 linear time으로 실행된다(즉, O(n)). 최악의 경우, 존재하지도 않는 경로를 찾기 위해 routes 파일의 모든 경로를 확인하고 결국에는 빈 손으로 끝날 수도 있다.
우체국 사례와 비교해보면 이 초기 솔루션이 얼마나 비효율적인지 알게 될 것이다.
우체국이 편지를 받을 때 마다 긴 주소 리스트를 일일이 훑어보며, 편지에 적혀있는 주소랑 일치하는지 확인한다고 상상해보라.
이는 효율적이지 않을 것이며, 속도도 느릴 것이다.
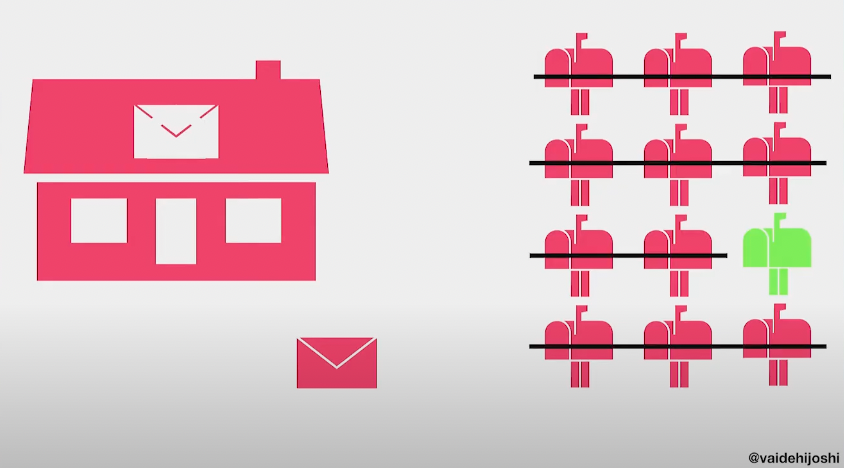
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
우리가 원하는 것은, 우리가 찾고 있는 경로를 최대한 좁히는 것이다. 주소 리스트 전체를 iterating 하는 대신, 즉 우리의 모든 경로를 죄다 살펴보는 대신, 일치할지도 않을 것들을 찾는 데 시간을 쓰지 않도록 최대한 찾을 경로들의 범위를 좁히는 것이다.
이를 위해 레일즈에서는 Jouney라는 라이브러리를 사용한다. Journey는 routing 엔진이며 기존에는 독립적인 라이브러리였으나 Rails4에서 Rails에 머지되었다.
where does Journey fit in?
routes 메서드를 호출하면 routes 인스턴스를 리턴했던 것을 기억하는가?, 이 인스턴스는 RouteSet 객체이다.
@routes ||= ActionDispatch::Routing::RouteSet.newroute set이란 또 무엇인가?
route_set의 정의를 확인해보면(이제 우리는 action_dispatch 내부에 들어와 있다), set 안에 Journey.Routes를 가지고 있는 것을 확인할 수 있다.
# action_dispatch/routing/route_set.rb
@set ||= Journey.Routes.new드디어 처음으로 Journey의 코드를 살짝 엿보게 되었다. 하지만, 우리는 앞으로 Jouney의 코드 자체를 일일이 분석하기 보다는, 이 엔진이 무엇을 하는지에 대한 일반적인 개념에 초점을 맞출 것이다. 해당 영상을 다 보고 난 후, Journey의 코드를 살펴보게 된다면, 어디서부터 시작해야 하는지, 그리고 어떻게 작동하는지 더 잘 이해할 수 있을 것이다.
Journey는 그래프라는 computer science 컨셉을 사용한다. 그래프는 일종의 data structure이다.
그래프는 노드와 노드들을 연결하는 엣지나 링크로 이루어져있다.

(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
위의 우체국 예제로 다시 돌아가보자. 우체국의 이상적인 시스템을 생각해 보았을 때, 어떤 우체국도 아무 우체통에 무작위로 편지를 넣는 것은 아닐 것이다. 어떻게 작동하는지에 대한 일종의 시스템과 순서가 있을 것이다.

(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
구체적으로는, 우체국에서 사용하는 '우편물을 어디로 보낼 지 결정하는 알고리즘'은 주소의 가장 넓은 부분부터 시작하는 것이다. 위 그림에선 USA부터 시작하는 식이다. 그런 다음 zip c0de, 주, 도시 및 street, 그리고 실제 집 주소 등으로 범위를 좁힌다.
레일즈 router도 마찬가지이다. 불필요한 검색을 피하기 위해 주소의 범위를 좁히고 찾는 아이디어는 Journey에서 찾을 수 있다.
Journey는 그래프 데이터 구조를 사용하여 router가 request를 어떻게, 그리고 어디로 보낼지 판단하는 것을 도와준다.
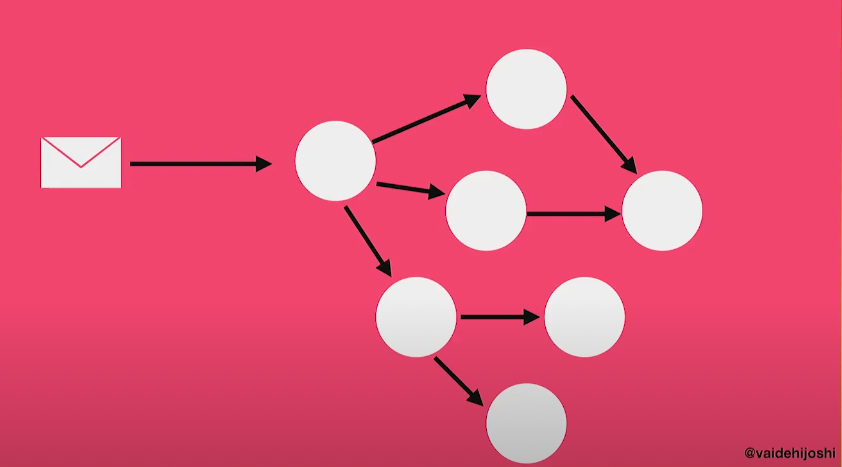
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
Journey가 request를 봤을 때, 첫 번째로 해야 할 일은 이 request가 routes 파일에서 실제로 어디로 가야하는지 알아내는 것이다. 이것이 Journey가 검색을 시작할 때 필요한 것이다.
Rails.application.routes.draw do
root 'welcome#home'
resources :articles
resources :recipes
resources :comments
end예를 들어, /recipes/:id와 같은 request가 있을 때, 궁긍적으로 하고자 하는 것은 id로 특정 레시피를 찾을 수 있는 컨트롤러로 해당 request를 보내는 것이다. 하지만 위 routes 파일에서 root나 articles, comment 등의 경로를 고려하는 것은 어리석다. 왜냐면 우리는 우리가 찾고자 하는 경로가 거기에 존재할 가능성이 전혀 없다는 것을 알기 때문이다.
당신과 나는 routes 파일을 보고 직관적으로 이를 알 수 있다. 우리는 직관적으로 검색할 필요가 없는 엄청난 수의 경로의 범위를 좁히고 제거할 수 있다.

(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
다시 우리의 코드로 돌아와서, 처음의 naive한 구현처럼 모든 경로를 다 iterate 하는 대신, 우체국이 하는 것과 유사한 것을 한다면 어떨까?


(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
우리가 정말로 해야 할 일은 request가 들어올 때, 주소를 현명하게 보고 이를 country, state, city, street 주소로 점차 범위를 좁히는 것이다.
하지만 우선적으로는, request가 들어올 때 이를 읽을 필요가 있다. 즉 request 편지에 무엇이 적혀있는지 이해해야 한다.
우리는 직관적으로 request와 reoutes 파일을 보고 어느 컨트롤러 액션으로 가야 된다라는 것을 알 수 있다. 우리의 코드도 이와 같이 동작하게 하려면 가장 먼저 요청 경로(예를 들어 /recipes/:id)를 '읽어야' 하는 것이다.
