how does the router read?
라우터는 어떻게 읽을까? 우리는 그것을 가르쳐야 한다.
Journey는 당신과 내가 읽는 것과 비슷한 방식으로 request를 읽는다. 사실 Journey가 읽는 방식은 컴파일러가 코드를 읽는 방식과 같다.
the cow jumped over the moon.우리가 위와 같은 문장을 읽을 때, 우리의 mind가 실제로 하고 있는 것은 이 일련의 문자들과 capitalization, punctuation, spaces 등을 보고, 일관성 있는 글자들로 나눈다. 우리의 mind는 그 글자들을 가지고 일종의 문법을 따르는 문장으로 만들어 이 문장이 우리에게 어떠한 의미를 갖도록 한다. 문자열을 의미있는 조각으로 분해하고 문법을 따르도록 문장으로 엮어내는 능력은 Journey가 할 수 있어야 하는 것이다. 즉 Journey는 당신과 내가 인간으로서 아주 쉽게 해내고 있는 이 일련의 작업을 복제해내야 하는 것이다.

(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
이것이 Journey가 매번 들어오는 request 주소, 즉 URL 문자열을 갖고 하는 작업이다.
물론 Journey가 이를 읽으려면 글자가 무엇인지, 문법이 무엇인지 알아야 한다. 그러고 나서 그것들을 그룹화해서 이 request 봉투에 무엇이 있는지 이해할 수 있어야 한다. 이를 위해 Journey는 토큰화라는 프로세스를 수행해야 한다.
tokenization
토큰화는 하나의 expression을 최소한의 의미있는 부분으로 나누는 작업이다. 이 개별 조각들은 토큰이라 불린다.

(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
이를 위해 Journey는 Journey scanner 라는 클래스의 도움을 받는다. Journey scanner는 루비의 StringScanner 클래스를 상속받은 클래스이다. 이 스캐너는 어떠한 string도 받을 수 있고, 토큰으로 만들기 위한 일련의 룰을 따른다. 여기서 우리가 제공할 input은 당연하게도 request URL이다.

(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
위와 같이 콘솔에 들어가 직접 스캐너가 작동하는 것을 볼 수 있다.

(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
스캐너 인스턴스에서 next_token를 호출해보면 실제로 request URL인 /recipes/:id를 각각의 개별적인 토큰으로 분할한 것을 볼 수 있다.
Journey의 스캐너는 slashes, string literals, 좌우 괄호 등의 토큰을 인식한다. Journey는 이처럼 우리의 문자열을 구성하는 각 단어들을 인식해내는 게 중요하고, 스캐너가 이를 도와주고 있다.
각 토큰으로 나누고 인식하는 것은 Journey가 해야할 일의 절반일 뿐이다. 왜냐하면 단어들은 따라야 할 문법적인 규칙이 없는 한 의미가 없기 때문이다. 넥스트 스텝은 우리가 그 단어들에 무슨 일이 일어나고 있는지 파악하고 이해하는 것이다.
Journey는 우리와 같다. 문법을 따라야 한다. 이를 위해 Journey는 parser라고 불리는 또 다른 클래스의 도움을 받아야 한다.
parser의 일은 토큰화된 조각들을 가져와서 그것을 이해하는 것이다. parser는 syntax tree라고 불리는 또 다른 computer science 개념을 활용하여 이를 수행한다.
syntax tree
syntax tree가 매우 어렵게 들릴 수도 있지만, 여기에서는 이 맥락에서 그들이 왜 중요한지에 대해서만 다룰 예정이다.
당신은 초등학교 시절 문장을 diagram화 했던 것을 기억할지도 모른다. 문법을 이해하고 배우기 위해 문장의 각 부분들을 구별해야 했을 것이다.
당신은 아마도 문장을 가지고 문장의 각 부분들과 그것이 어떻게 구성되어있는지를 알기 위해 문장안의 단어들을 tree 형태로 구성해본 적이 있을 것이다.
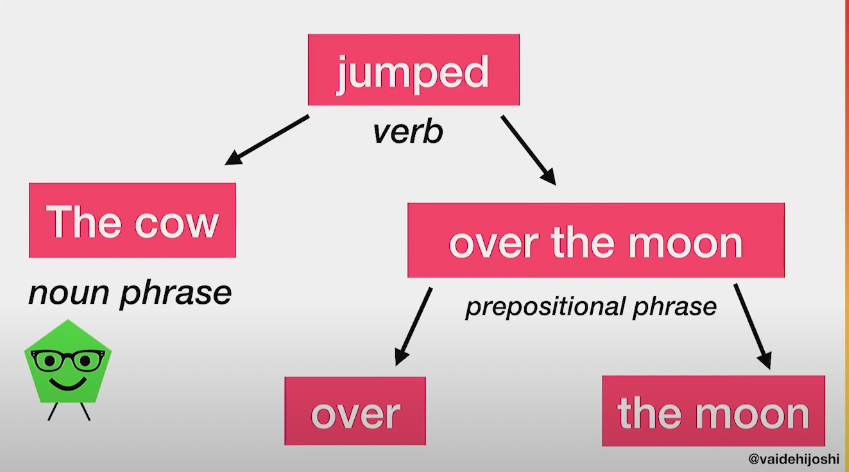
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
이것이 바로 syntax tree이다. 즉 문장 구조의 illustration 버전이다.
parser는 Journey를 위해 이와 비슷한 종류의 syntax tree를 만들고, Joureny가 문법을 이해하도록 돕는다.
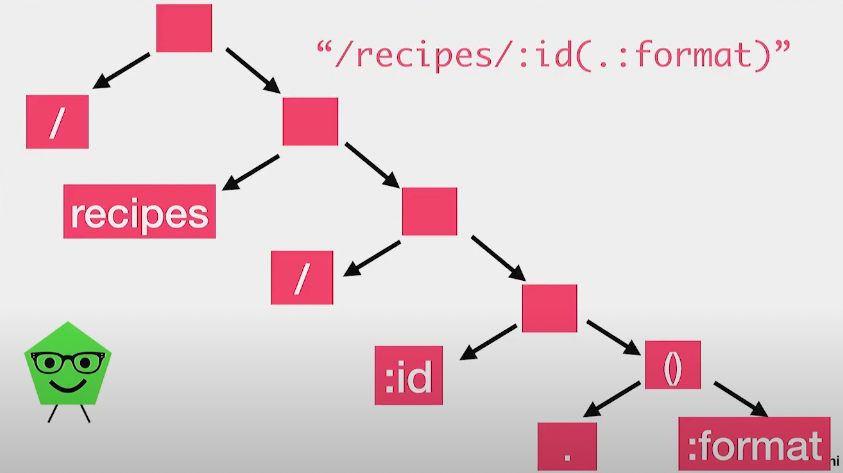
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
recipes controller의 show action에 해당하는 경로에 대해 Journey(Journey의 parser)가 생성하는 syntax tree의 예이다.
routes.rb파일에 정의된 모든 경로에 대해 Journey의 parser는 이와 같은 syntax tree를 만든다.
역시나 콘솔에서 확인해 볼 수 있다.

(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
intermediate step
이제 우리는 여러개의 tree를 갖게 되었지만, 여전히 우리의 모든 경로를 하나로 합칠 필요가 남아있다. 이 문제를 해결하기 위해 하나의 단일 시스템이 필요하다.
그래프를 기억하는가? 여기가 바로 그래프가 필요한 시점이다. Journey는 request를 route하기 위해 그래프를 사용하며, 이 그래프는 syntax tree로 구성되어 있다.
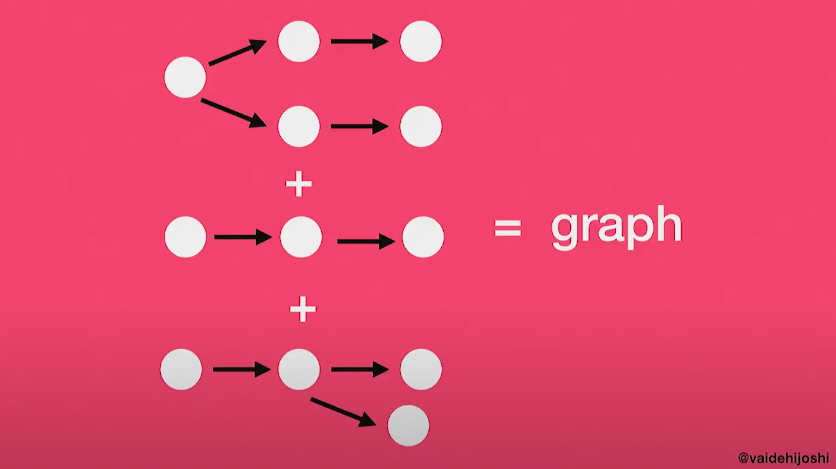
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
Journey는 이러한 syntax tree를 결합하여 (routes.rb 파일에 정의한) 당신의 모든 경로에 대한 그래프를 만든다. Journey의 코드는 실제로 generalized transition graph, 혹은 GTG라 부르는 것을 참조한다. 우리는 이를 state machine의 맥락에서 생각할 필요가 있다.
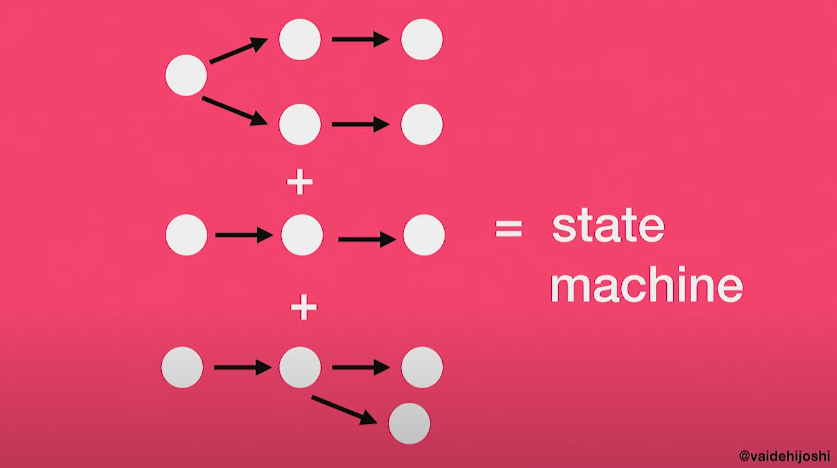
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
우리가 실제로 다루고 있는 state는 우리가 parse하는 중인, 그리고 우리가 그 URL을 따라 이미 parse한 request URL이다.
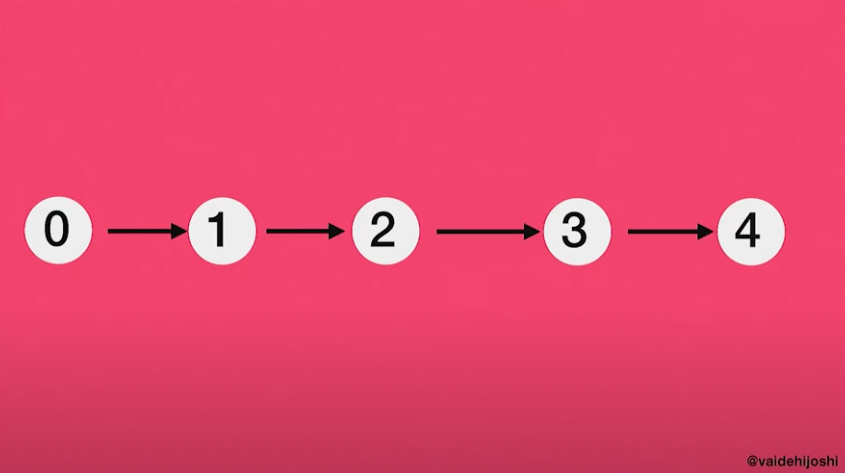
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
request가 router에 도달하면, Journey는 request URL의 각 하위 부분이 일치시켜가며 이 그래프의 하나의 노드 혹은 하나의 state를 한 번에 하나씩 체크해나간다.
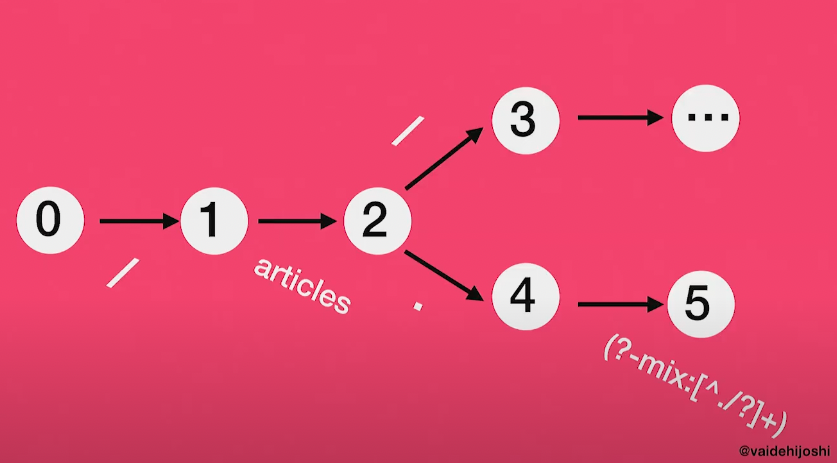
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
기본적으로 request URL을 한 번에 한 섹션씩 읽을 때, 그래프를 따라 이동하는데, 현재 상태에서 어떤 노드가 일치할지를 기준으로 그래프의 다음 파트로 진행된다.
즉 결합된 수많은 syntax tree 중의 한 노드가 해당되면, 그래프 안의 다음 경로로 이동하며 이 것이 Journey가 graph를 하나씩 걸어나가는 방법이다.
request URL parsing을 마칠 때 까지 Journey는 이 tree를 계속해 걸어나간다. 그리고 읽기를 마쳤을 때, 해당 문자열의 state와 일치하는 노드를 찾으면, Journey가 request와 함께 들어온 이 문자열이 어떤 route에 해당하는지 알 수 있게 된다.
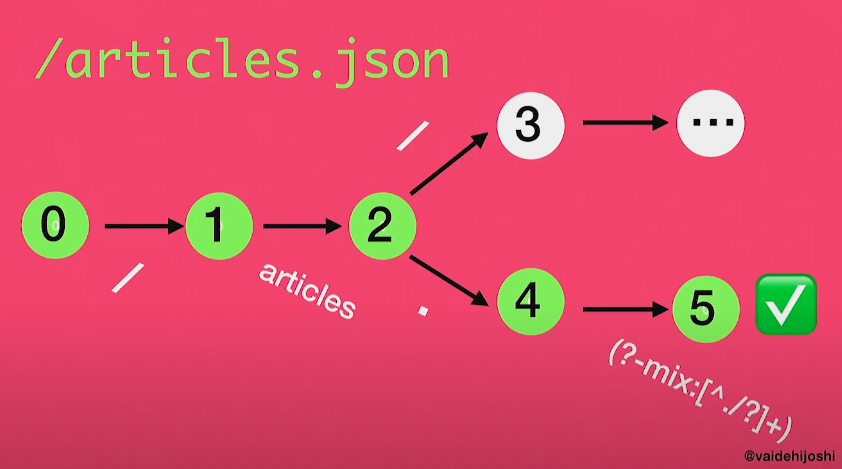
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
정리하자면, 당신과 내가 routes.rb 파일을 보고 이 request가 이 controller의 이 action으로 가는구나 라는 것을 쉽게 알 수 있지만, Journey는 우리가 하고 있는 것을 모방하고 복제하기 위해 위에서 설명한 모든 작업을 뒷단에서 data structure를 구현해내어 수행하고 있다. 하지만 굉장히 빠르게 수행되기 때문에 괜찮다.
한 로봇이 우리의 request URL을 들고 그래프를 따라 걷고 있다고 상상하자. 이 로봇은 reqeust URL 문자열을 체계적으로 확인하며 state maching graph structure에서 어떤 경로를 선택해야 할지 결정한다.
이러한 컨셉은 'nondeterministic finite automaton', 혹은 NFA라 부른다. NFA는 state machine의 한 종류이며, 한 번에 약간의 input을 처리하고 어떻게 transition(전이)할 것인가를 결정한다. 현재 갖고 있는 input과 현재 state를 확인하고, 이를 기반으로 그래프에서 어디로 나아갈지를 결정한다.
two possible outcomes
우리의 작은 로봇에게 주어질 결과는 2개가 있다. 우리가 입력한 request URL과 일치하는 state를 찾거나, 찾지 못하거나 이다.
실제 route와 일치하는 string의 끝에 도달하면, 우리는 우리의 request URL에 해당하는 경로가 있다는 것을 알 수 있다. 즉, 해당 경로에 맞는, 그리고 우리의 요청을 보낼 컨트롤러와 액션을 찾게된 것이다.
이렇게 해당 경로를 찾게 되면 Journey가 해야할 일은 단지 해당 컨트롤러 액션에 request를 dispatch하는 것이다.
아래의 url에서 이와 같은 과정을 비쥬얼화하여 볼 수 있다.
https://tenderlove.github.io/fsmjs/
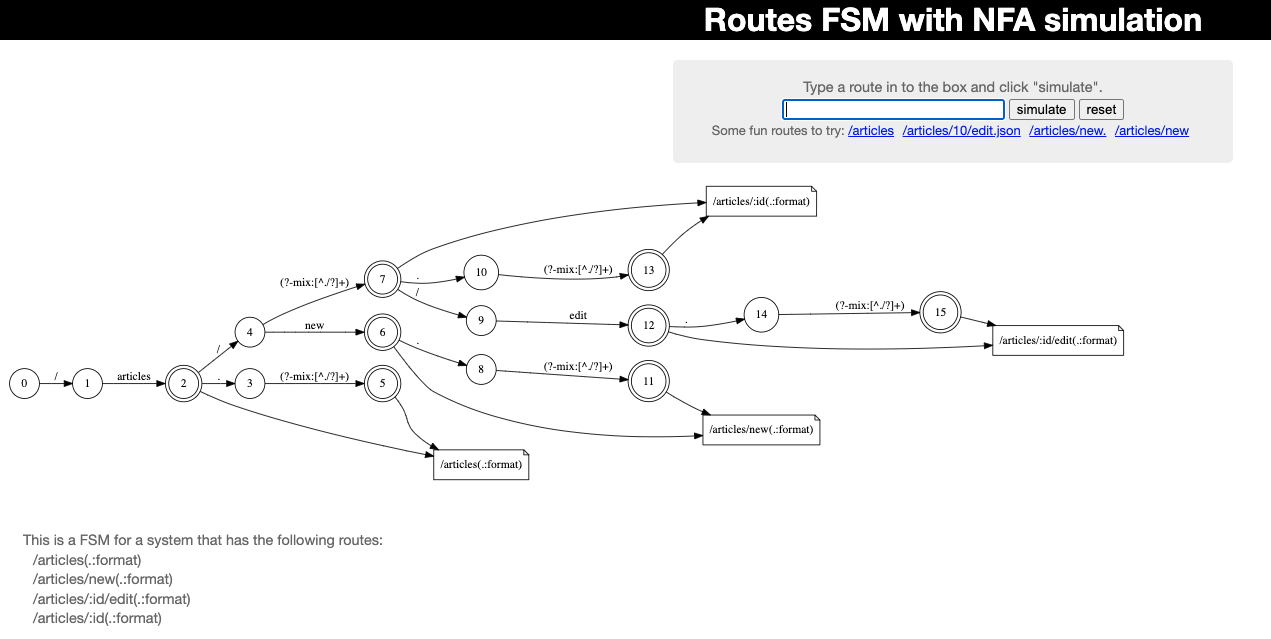
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
위에서의 컬러풀한 그래프와 별반 다르지 않다는 것을 알 수 있을 것이다. 이는 단지 4개의 경로를 가진 예이므로, 일반적인 케이스에서는 얼마나 클지 상상할 수 있을 것이다.
아래는 유효한 경로를 찾았을 경우의 NFA의 모습이다.
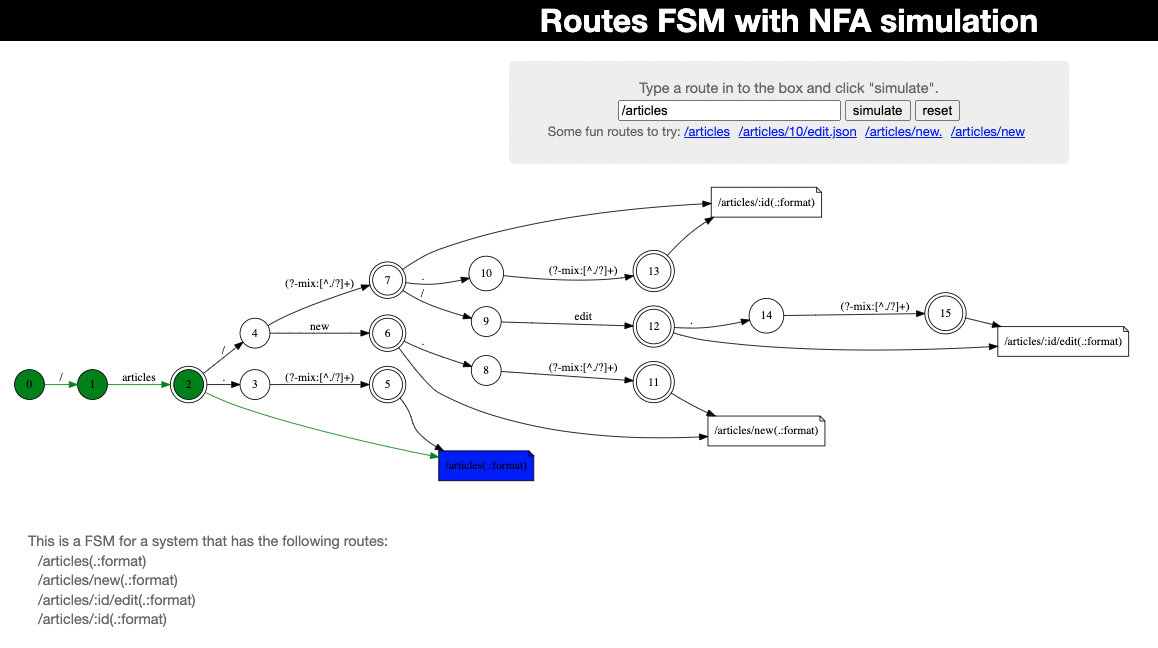
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
Journey가 유효한 state를 찾게 되면, Journey는 해당 request를 실제 controller action으로 dispatch하여 앞으로의 작업을 수행하도록 할 것이다.
만약 유효하지 않은 경로가 입력되면 어떻게 될까?
이러한 상태를 rejected state라 한다. 이 경우에는 state machine을 떠날 수 밖에 없다. 왜냐하면 더이상 나아갈 수 있는 곳이 없기 때문이다. 이 때는 에러를 일으키거나 '해당 route가 없습니다' 등의 메시지를 표현하는 것이 맞을 것이다.
아래는 rejected state의 NFA의 모습니다.
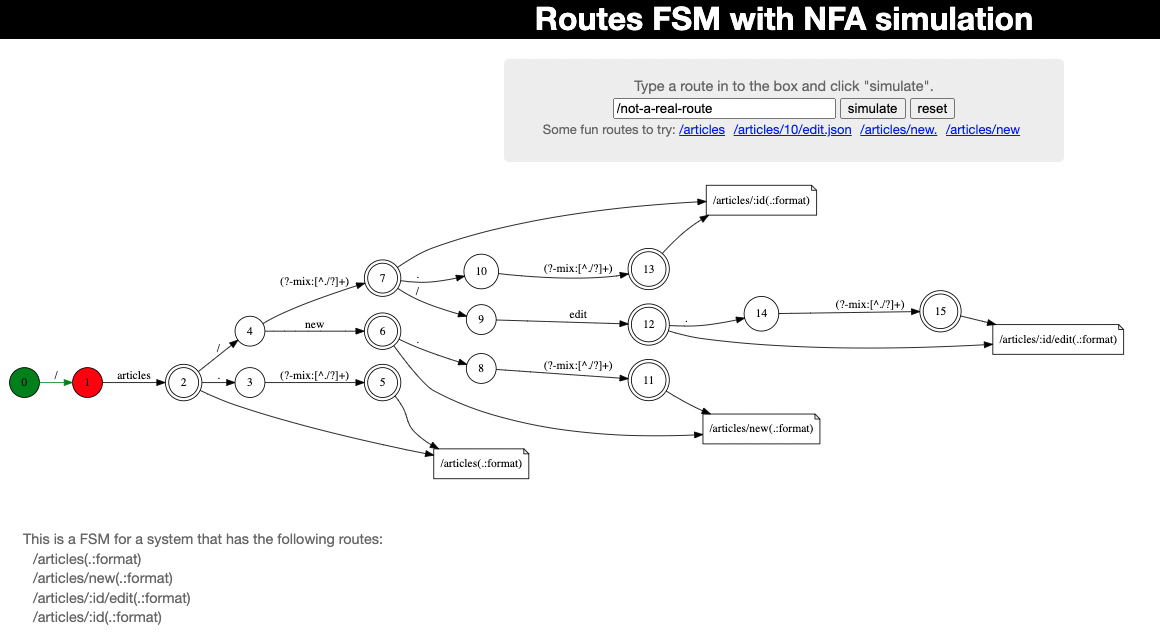
(출처: https://www.youtube.com/watch?v=lEC-QoZeBkM)
이러한 경우에는 아래와 같은 에러 페이지를 보게 된다.
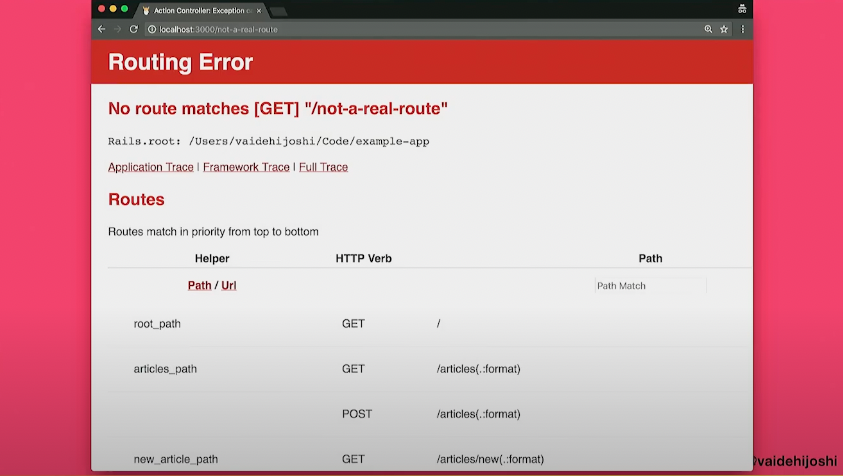
마무리
이로써 우리는 라우터 동작 까지의 request 라이프 사이클을 확인해보았다. Journey는 정규표현식 엔진이지만, Journey가 routing하는 과정에서 토큰화와 tree, grapth, automatons 등을 사용한다는 것을 배울 수 있었다. 이러한 개념과 동작방식은 Journey에만 국한되지 않는다. 다른 프레임워크, 레일즈의 다른 부분들, 컴파일러 등 여러 곳에서 실제로 이와 같은 과정을 찾아 볼 수 있다.
