Pandas
파이썬 프로그래밍을 통한 데이터 조작 및 분석을 가능하게 해 주는 라이브러리
- numpy 기반으로 작성
- 분석에 대한 편리성 제공
설치법
pip install pandas
불러올 땐 이렇게 쓴다.
불러오기
import pandas as pd
보통은 pd로 줄인다.
데이터프레임
데이터프레임을 생성할 때는 일반적인 리스트와 다르게 pd.Dataframe을 사용한다.
dict_scores = {'A': [90, 86, 86, 73], 'B': [89, 78, 88, 95], 'C': [47, 65, 83, 74], 'D': [63, 69, 87, 52]}
dict_df = pd.DataFrame(dict_scores, subjects)
dict_df이런 식으로.
Numpy Array
Numpy 배열을 이용하면 배열의 각 열이 데이터프레임의 열이 된다.
np_scores = np.array([[90, 86, 86, 73], [89, 78, 88, 95], [47, 65, 83, 74], [63, 69, 87, 52]])
np_df = pd.DataFrame(np_scores, subjects, students)
np_df데이터프레임 분석 방법
axes and values
axes를 이용하면 데이터프레임의 축 정보를 반환한다.
np_df.axes

이렇게. index와 columns를 이용하면 똑같은 결과가 나온다.
values를 이용하면 numpy 배열로 변환해서 반환한다.
np_df.values
info and describe
info를 이용하면 데이터프레임의 요약 정보를 출력한다.
np_df.info()
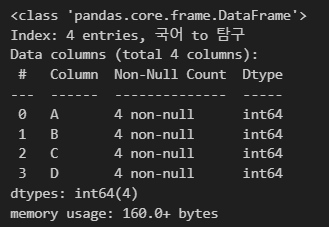
이런 식으로 출력해 준다.
describe는 통계를 출력해 준다.
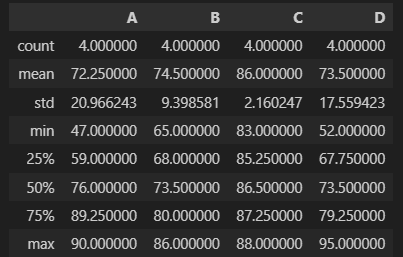
귀찮게 하나하나 일일이 통계를 매길 필요가 없다.
pd.options.display.float_format을 이용하면 자릿수 조정도 가능하다.
shape
그냥 크기 알려주는 친구다.
np_df.shape

이런 식으로 나온다.
데이터프레임 접근
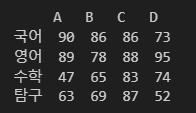
이런 표가 있다고 해 보자.
A 행만 가져오고 싶으면 np_df.A를 쓰면 된다.
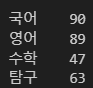
다른 것도 마찬가지겠다.
indexing
np_df['A'] 이렇게 쓰는 걸 말한다.
np_df['A']의 타입은 이렇다.
pandas.core.series.Series
데이터프레임 형태로 확인하려 한다면 괄호를 더 친다.
np_df[['A']]
boolean indexing
데이터프레임은 numpy와 마찬가지로 np_df > 70 이런 게 가능하다.
slicing
행 같은 거 접근할 때 쓴다.
np_df[값:값] 이렇게 쓴다.
indexing과 slicing을 같이 쓸 수도 있다.
np_df[['C']][-3:]

Modification
append
그냥 배열 끝에 삽입하는 거다.
new_row = pd.DataFrame(np.array([[78, 64, 91, 56]]), ['정보'], students)
np_df.append(new_row)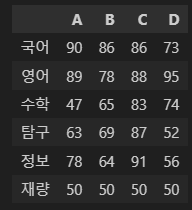
insert
배열 위치 지정해 줘서 삽입할 수 있다.
np_df.insert(5, 'F', np.array([91, 87, 93, 100]))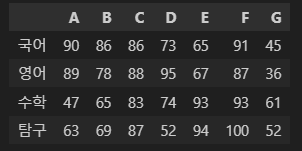
일괄 갱신
은 이렇게 할 수 있다.
np_df['F'] = 0
replace
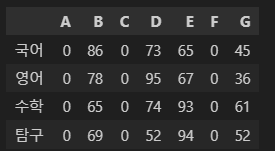
이렇게 돼 있는 걸
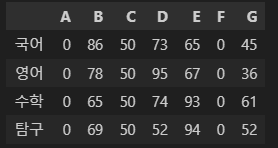
이렇게 쓸 때 사용한다.
np_df = np_df.replace({'C':0}, 50)
np_df이미 행이 있는 거에 삽입하면 갱신이 이루어진다.
delete
특정 열을 전체 삭제한다.
del np_df['G']
np_df축을 이용할 때는 drop을 쓴다.
np_df = np_df.drop(['F'], axis=1)
np_df롤 과제
https://oracleselixir.com/stats/champions/byTournament/LCK%2F2024%20Season%2FSpring%20Season
여기 들어가서 Download this Table 누르면 csv가 다운로드된다.
불러올 땐 코드를 이렇게 짜면 되겠고(과제 1)
(아 물론 진짜 저기에 황현민이라 적혀 있진 않다. 쓰기 편해서 장난쳐 놨다)
import pandas as pd
file_path = "황현민.csv"
df = pd.read_csv(file_path)값을 대강 볼 땐 이거 쓰면 되겠다(과제 2).
df.describe()탑 정글 미드 이런 건 이렇게 정렬할 수 있겠다(과제 3).
df = df.sort_values(by=['Pos'], ascending=True)포지션별 데이터프레임을 따로 관리하는 방법은 이렇다(과제 4).
float로 바꾼 이유는... 그냥 하면 % 때문에 이상하게 나온다.
Middle = df.loc[df.Pos == 'Middle', ['Champion', 'P+B%']]
Middle['P+B%'] = Middle['P+B%'].str.rstrip('%').astype(float)
Jungle = df.loc[df.Pos == 'Jungle', ['Champion', 'P+B%']]
Jungle['P+B%'] = Jungle['P+B%'].str.rstrip('%').astype(float)
Top = df.loc[df.Pos == 'Top', ['Champion', 'P+B%']]
Top['P+B%'] = Top['P+B%'].str.rstrip('%').astype(float)
ADC = df.loc[df.Pos == 'ADC', ['Champion', 'P+B%']]
ADC['P+B%'] = ADC['P+B%'].str.rstrip('%').astype(float)
Support = df.loc[df.Pos == 'Support', ['Champion', 'P+B%']]
Support['P+B%'] = Support['P+B%'].str.rstrip('%').astype(float)포지션별 픽밴 빈도 높은 탑 10위의 챔피언을 보여 줄 땐 이렇게 하면 된다(마지막).
print("Middle")
print(Middle.sort_values(by=['P+B%'], ascending=False)[:10])
print("Jungle")
print(Jungle.sort_values(by=['P+B%'], ascending=False)[:10])
print("Top")
print(Top.sort_values(by=['P+B%'], ascending=False)[:10])
print("ADC")
print(ADC.sort_values(by=['P+B%'], ascending=False)[:10])
print("Support")
print(Support.sort_values(by=['P+B%'], ascending=False)[:10])전체 코드
# Oracle Elixir excel file read dataframe receive
import pandas as pd
file_path = "황현민.csv"
df = pd.read_csv(file_path)
# dataframe.describe() to see value
df.describe()
# top jungle mid .... sorting
df = df.sort_values(by=['Pos'], ascending=True)
# position star dataframe divide manage
Middle = df.loc[df.Pos == 'Middle', ['Champion', 'P+B%']]
Middle['P+B%'] = Middle['P+B%'].str.rstrip('%').astype(float)
Jungle = df.loc[df.Pos == 'Jungle', ['Champion', 'P+B%']]
Jungle['P+B%'] = Jungle['P+B%'].str.rstrip('%').astype(float)
Top = df.loc[df.Pos == 'Top', ['Champion', 'P+B%']]
Top['P+B%'] = Top['P+B%'].str.rstrip('%').astype(float)
ADC = df.loc[df.Pos == 'ADC', ['Champion', 'P+B%']]
ADC['P+B%'] = ADC['P+B%'].str.rstrip('%').astype(float)
Support = df.loc[df.Pos == 'Support', ['Champion', 'P+B%']]
Support['P+B%'] = Support['P+B%'].str.rstrip('%').astype(float)
# radius position frequency count (pick + ban) top 10 champion present
print("Middle")
print(Middle.sort_values(by=['P+B%'], ascending=False)[:10])
print("Jungle")
print(Jungle.sort_values(by=['P+B%'], ascending=False)[:10])
print("Top")
print(Top.sort_values(by=['P+B%'], ascending=False)[:10])
print("ADC")
print(ADC.sort_values(by=['P+B%'], ascending=False)[:10])
print("Support")
print(Support.sort_values(by=['P+B%'], ascending=False)[:10])