[책][대규모 시스템 설계] 사용자 수에 따른 규모 확장성
데이터베이스
어떤 데이터 베이스를 사용할 것인가?
비-관계형 데이터베이스가 바람직한 경우
대부분의 개발자에게는 관계형 데이터베이스가 최선일 것이지만 다음과 같은 경우에 비-관계형 데이터베이스를 고려해 보아야 한다.
- 아주 낮은 응답 지연시간이 요구되는 경우
- 다루는 데이터가 비정형인 경우
- 데이터를 직렬화하거나 역직렬화 할 수 있기만 하면 되는 경우
- 아주 많은 양의 데이터를 저장할 필요가 있는 경우
왜 아주 많은 양의 데이터를 저장할 필요가 있을 때 비-관계형 데이터베이스가 바람직할까?
- 수평적 확장성 (Horizontal Scalability)
- 전통적인 관계형 데이터베이스(RDBMS)는 대체로 수직적 확장(Scale-up) 방식 → 더 큰 서버, 더 좋은 CPU/메모리 필요.
- NoSQL은 기본적으로 수평적 확장(Scale-out) 구조를 지원 → 저렴한 서버 여러 대를 묶어 클러스터링 → 빅데이터 환경에 적합.
- 유연한 스키마 (Schema Flexibility)
- RDBMS는 테이블 구조(스키마)가 고정 → 데이터 구조 변경 시 마이그레이션 비용이 큼.
- NoSQL은 스키마리스(schema-less) 혹은 유연한 스키마 → 새로운 필드를 자유롭게 추가 가능 → 비정형 데이터(로그, JSON, IoT 센서 데이터 등)에 유리.
- 대규모 데이터 처리 성능 (High Throughput)
- RDBMS는 JOIN, 트랜잭션 기능은 강력하지만, 데이터 양이 폭발적으로 많아지면 병목이 발생하기 쉬움.
- NoSQL은 읽기/쓰기 성능 최적화에 초점 → 특정 쿼리 패턴(예: key-value 조회, document 조회)에 대해 초고속 응답 제공.
- 분산 저장 및 고가용성 (Distributed Storage & High Availability)
- NoSQL은 데이터 복제(Replication)와 샤딩(Sharding)을 기본적으로 지원 → 데이터가 여러 서버에 자동 분산 저장.
- 장애 발생 시 다른 노드에서 데이터 제공 가능 → 장애 허용성(Fault-tolerance)이 뛰어남.
수직적 규모 확장 vs 수평적 규모 확장
수평적 규모 확장이 더 나은 이유
서버로 유입되는 트래픽 양이 적을 때는 수직적 확장이 좋은 방법이다. 하지만 대규모 시스템을 설계할 때는 수평적 규모 확장이 더 나은 방법이다. 이유는 다음과 같다.
- 수직적 규모 확장에는 한계가 있다. 한 대의 서버에 CPU나 메모리를 무한대로 증설할 방법은 없다.
- 수직적 규모 확장법은 장애에 대한 자동복구 방안이나 다중화 방안을 제시하지 않는다. 서버에 장애가 발생하면 웹사이트/앱은 완전히 중단된다. (고가용성 제공 불가)
로드밸런서
로드밸런서는 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할을 한다. 사용자는 로드밸런서의 공개 IP 주소로 접속한다. 따라서 웹 서버는 공개 IP를 가질 필요가 없고, 서버 간 통신에는 사설 IP 주소를 사용하면 된다.
로드밸랜서를 사용하는 이유는 다음과 같다.
- 서버 1이 다운되면 모든 트래픽을 서버 2로 보낸다. 이로써 장애를 대비할 수 있다.
- 트래픽을 분산시켜 준다.
데이터베이스 다중화
데이터베이스 다중화 방식은 주 데이터베이스와 부 데이터베이스 여러대를 구성하는 방식으로 이루어진다. 주로 주 데이터베이스에 쓰기 연산을 하고, 부 데이터베이스에 읽기 연산을 하는 식이다.
데이터베이스 서버 가운데 하나가 다운되면 무슨 일이 벌어질까?
- 부 서버가 한 대 뿐인데 다운되면, 모든 읽기와 쓰기 연산은 주 데이터베이스가 하게된다.
- 주 데이터베이스 서버가 다운되면, 부 데이터베이스 중 한 대가 주 데이터베이스가 되게 된다. 이렇게 되면 부 데이터베이스에 있는 데이터가 최신 데이터가 아니기 때문에 주 데이터베이스가 복구되면 데이터를 최신화 시켜주거나 다른 방식을 사용하여 최신화 해주어야 한다.
캐시
캐시 사용 시 유의할 점
- 캐시는 데이터 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어난다면 고려해볼 만하다.
- 휘발되어도 괜찮은 데이터만 캐싱한다.
- 캐시의 ttl 설정은 주의를 기울여야 한다. ttl이 짧으면 hit가 줄어들고, 만료정책이 없으면 메모리에 데이터가 계속 남게된다.
- 캐시에 저장할 데이터의 원본을 갱신하는 경우 캐시 데이터를 단일 트랜잭션으로 처리하지 않으면 일관성 문제가 발생한다.
- 캐시 서버도 분산시켜 주어야 한다. (고가용성)
- 캐시 메모리는 과할당하는 게 좋다.
캐시 메모리 과할당
장점
- 캐시 미스 감소
- 성능 향상
과할당 기준
- 명확한 과할당의 기준은 없지만, 일반적으로 ‘실제 메모리 용량 기준 전체 메모리의 20~30% 이상의 캐시 설정’을 과할당이라고 보는 경우가 있다.
주의점
- 지나친 캐시 과할당은 캐시 자체 접근 시간이 증가하고, 메모리 부족으로 인해 다른 프로세스가 느려지거나 스왑이 발생할 수 있다.
콘텐츠 전송 네트워크(CDN)
CDN은 정적 콘텐츠를 전송하는 데 쓰이는, 지리적으로 분산된 서버의 네트워크이다. 이미지, 비디오, CSS, JavaScript 파일 등을 캐시할 수 있다.
CDN을 사용하면 서버로 부터 멀리 떨어진 해외에서도 정적 컨텐츠에 대한 접근 속도가 향상 된다.
AWS의 CDN 서비스
CloudFront는 AWS의 CDN 서비스이다. 사용자가 CloudFront에서 전송하는 콘텐츠를 요청할 경우 요청이 가까운 엣지 로케이션으로 라우팅된다.
CloudFront에는 EC2의 DNS주소를 입력하여 EC2에서 운영 중인 웹서버의 정적 컨텐츠를 캐싱할 수 있다.
CloudFront를 사용함으로서 비용을 절감할 수 있다. EC2는 아웃바운드 트래픽에 대해 과금당하고, S3는 데이터 업로드와 다운로드 모두 과금당한다. CloudFront를 사용하면 서버에 요청이 오기전에 캐싱하므로 비용 절감을 할 수 있다.
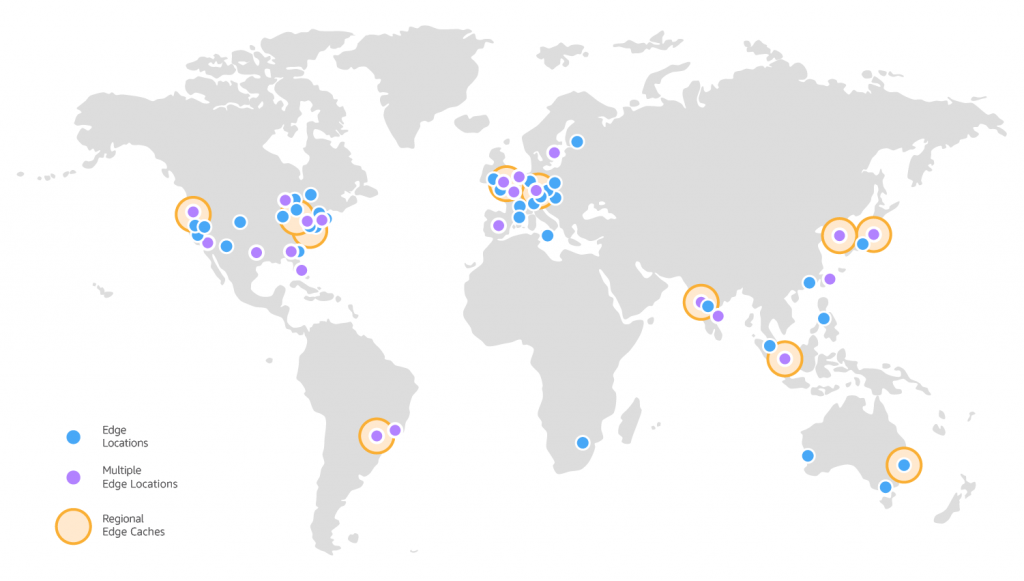
CDN 사용 시 고려해야 할 사항
- 비용: 자주 사용되지 않는 컨텐츠를 캐싱하는 것은 이득이 크게 되지 않으므로, 과금을 피하기 위해서는 CDN에서 빼는 게 좋다.
- 적절한 만료 설정: 시의성이 중요한 콘텐츠의 경우 만료 시점을 잘 정해야 한다.
- CDN 장애에 대한 대처 방안: CDN 자체가 죽었을 경우 해당 문제를 감지하여 원본 서버로부터 직접 콘텐츠를 가져오도록 클라이언트를 구성하는 것이 필요하다.
무상태 웹 계층
웹 계층을 수평적으로 확장하기 위해서는 상태 정보(ex. 사용자 세션 데이터)를 웹 계층에서 제거해야 한다.
상태 정보 의존적인 아키텍쳐
- 웹 계층에서 상태 정보를 저장한다면, 클라이언트는 정해진 웹 서버로만 통신해야 한다.
- 상태 정보 의존적인 웹 서비스를 위해서 대부분의 로드밸런서는 고정 세션이라는 기능을 제공한다. 하지만 이는 로드밸런서에 부담을 준다.
무상태 아키텍쳐
- 웹 서버는 상태 정보가 필요한 경우 공유 저장소로부터 데이터를 가져오도록 해야 한다.
- 로그인으로만 놓고 보자면 토큰을 사용하는 방법으로 개선할 수도 있다. - 세션 데이터는 NoSQL을 사용하면 이점이 있다. 트래픽 양에 다라서 자동 규모 확장이 자유롭기 때문이다.
데이터 센터
- 데이터 센터는 여러 데이터 센터를 이용하는 것이 좋다. 천재지변으로 인하여 데이터센터A가 마비되면 데이터센터B를 사용할 수 있도록 해야 한다.
- AWS는 한 리전(Region) 내 여러 가용 영역(AZ, Availability Zone)이라는 독립적인 데이터센터를 제공한다. 각 AZ는 별도의 전원, 네트워킹, 보안 시스템을 갖추고 물리적으로 분리되어 있다.
- EC2, RDS 등 주요 서비스 배포 시, 하나의 AZ 또는 여러 AZ에 분산 배치할지 사용자가 직접 선택한다. AZ에 리소스를 분산하라고 “권장”하지만, 반드시 여러 AZ에 분산해야 서비스를 쓸 수 있는 식의 “강제”는 하지 않는다.
메시지 큐
발행자가 메시지를 만들어 메시지 큐에 발행한다. 큐에는 보통 소비자 혹은 구독자라 불리는 서비스 혹은 서버가 연결되어 있는데, 메시지를 받아 그에 맞는 동작을 수행하는 역할을 한다.
메시지 큐의 장점
- API를 쓰면 장애가 전파된다. 근데 메시지 브로커는 그렇지 않다. 이벤트만 전송하면 된다.
- 시스템 결합도가 낮아진다.
로그, 메트릭, 자동화
- 로그: 에러 로그를 모니터링 해야 한다. 대규모 시스템에서 로그 수집이 필수다.
- 직접 구축: 엘라스틱서치, 키바나 사용
- 제품: DataDog - 메트릭: 메트릭을 잘 수집하면 사업 현황에 관한 유용한 정보를 얻을 수도 있다.
- https://medium.com/29cm/29cm-의-이굿위크-장애대응-기록-177b6b2f07a0 - 자동화: 빌드, 테스트, 배포 등의 절차를 자동화하여 개발 생산성을 크게 향상시킬 수 있다.
데이터베이스의 규모 확장
저장할 데이터가 많아지면 데이터베이스를 증설할 방법을 찾아야 한다.
데이터베이스 확장도 웹 서버와 마찬가지로 수직적 확장과 수평적 확장이 있다.
수평적 확장
데이터베이스의 수평적 확장은 샤딩이라고도 부른다. 샤딩은 대규모 데이터베이스를 샤드라고 부르는 작은 단위로 분할하는 기술을 일컫는다. 모든 사드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.
샤딩을 도입하면 시스템이 복잡해지고 풀어야 할 새로운 문제도 생긴다.
- 데이터의 재 샤딩: 데이터가 너무 많아져서 하나의 샤드로는 더이상 감당하기 어려울 때. 샤드 소진이라고 부르는 이러한 현상이 발생하면 샤드 키를 계산하는 함수를 변경하고 데이터를 재배치하여야 한다.
- 유명인사 문제: 커뮤니티를 예로 들면 인기글이 하나의 샤드에 쏠리는 경우 발생할 수 있는 문제다. 해결하기 위해서는 유명인사 각각에 샤드를 할당해야 할 수도 있다.
- 조인과 비정규화: 샤드를 물리적으로 나누게 되면 데이터를 조인하기가 어렵다.
샤딩
- 수직 샤딩, 수평 샤딩 기법이 있고, 물리적 샤딩과 논리적 샤딩 기법이 있다.
- 샤딩은 데이터를 분산하기 위한 방법이다. 가용성을 위한 master-slave 와는 다르다.
- 샤딩은 해싱 키를 뭐로 쓸지 정하는 게 중요하다.
- 게시판 DB 설계할 때 해싱 키는 게시판 id를 해싱 키로 잡는 게 좋다. dc inside를 예로들면 ‘야구 갤러리’에 글이 있고 글 안에 댓글이 있다. 따라서 게시판(갤러리) 기준으로 해싱키를 잡으면 좋음. 만약 글의 id를 해싱키로 잡았다면 게시판을 기준으로 게시글을 조회할 때 모든 db를 다 조회해야 할 수도 있다. - 샤딩을 할 때 PK로는 Snowflake 알고리즘을 사용한 키를 사용하는게 좋다. Snowflake 알고리즘은 오름차순 & 유니크 숫자를 만들기 위한 알고리즘이다.
