2024년 5월 15일, AWS Aurora MySQL의 8.0.mysql_aurora.3.04.1 버전에서 발생한 오류로 장애를 조치하기위해 진행했던 작업과 공부했던 내용을 간단하게 정리한 글입니다.
장애 리포팅
2024년 5월 17일 16시 46분. CS팀으로부터 장애 리포팅이 들어옵니다.
"지금 API 호출이 안 되고 있습니다."
"504 Gateway Timeout이 발생하고 있어요"
17시 15분까지 미팅이 있었던 저는 30분이 지난 17시 16분에 해당 내용을 식별하게 되었고, TL분께서 저한테 현재 상황을 공유해 주셨습니다.
"현재 모든 고객사의 API 호출이 불가능한 상태이고, Argo에서 각 서비스 Pod의 로그를 확인했을 때 별다른 문제가 확인되지 않습니다. 관련해서 디깅 좀 해주시겠어요?"
해당 내용을 전달받은 저는 AWS 서비스의 상태를 확인하기 시작합니다. 그리고 AWS Aurora MySQL 인스턴스 중 하나의 CPU가 99%까지 올라가 있는 것을 확인하게 됩니다.

그리고 저는 아래의 내용을 채널에 공유하게 됩니다.
"저희 운영 DB가 죽은 것 같습니다."
원인 분석
운영 DB 인스턴스의 장애를 공유하자마자 바로 MySQL에 접속을 시도했습니다. CPU 수치가 최대치에 도달한 걸로 봐서는 Slow Query가 존재할 것이라 생각했기 때문입니다.
하지만 다급했던 저의 마음을 모르는 것인지 야속하게도 MySQL 인스턴스는 Too Many Connections 에러만 응답하기 시작합니다.
( MySQL Connection에 대한 내용은 여기에서 확인해주세요. )
참고!
이 때 발생한 Too many connection 에러는 해당 장애와는 무관했습니다.서비스 초기 단계여서 사양이 낮은 DB 인스턴스를 사용하게 되었는데, MSA 방식을 "일부" 도입하게 되면서 개발되는 앱의 갯수가 늘어났고, 앱 마다 일정 수의 Connection Pool을 확보하게 되면서 Connection 수치가 max_connections 에 도달해서 발생하던 문제였습니다.
이때 저는 아래의 고민을 하기 시작합니다.
- MySQL CPU가 최대치로 도달했으니 재부팅을 요청한다.
- max_connections 값에 대해서 상향 조정을 요청한다.
잠깐의 고민을 마치고 인프라팀 담당자분께 2번 내용으로 요청을 했습니다. 그 이유는 아래와 같습니다.
- 빠른 서비스 정상화를 위해 재부팅을 하는 것이 맞으나, 재부팅을 한다 하더라도 동일한 증상이 재현될 것이라 생각했습니다.
- MySQL 서버가 Too many connections 에러를 응답하는 걸로 봐서는 서버가 완전히 다운되지는 않았다는 것 입니다.
- 장애가 발생하는 상황에서 MySQL의 서버의 상태와 실행중인 쿼리를 살펴보는 것이 원인을 파악하는데 가장 최적의 상황이라고 생각을 했습니다.
- 실행 중인 RDS 인스턴스에 연결된 DB 파라미터 그룹에서 동적 파라미터로 지정된 값의 변경은 재부팅 없이 적용됩니다.
위 내용들을 근거로 인프라팀 담당자분에게 max_connections 값을 상향해 달라고 요청을 했습니다. 그 후 상향 조정된 값이 적용되자마자 MySQL 인스턴스에 접속하여 ProcessList를 확인했습니다.
SELECT * FROM information_schema.PROCESSLIST WHERE COMMAND != 'Sleep' ORDER BY TIME;하지만 예상과는 다르게 조회되는 Slow Query는 존재하지 않았습니다. 당연하게도 RDS 로그 및 이벤트 탭의 slowquery.log 파일에도 기록된 Slow Query는 존재하지 않았습니다.
예상했던 문제가 장애의 원인이 아니라는 것을 확인하자마자 더이상 지연시키지 않고 서비스 정상화를 위해 인프라팀 담당자분에게 인스턴스 재부팅을 요청하게 됩니다.
(재부팅 후 DB 인스턴스가 정상화되었으나, 예상했던대로 원인을 해결할 때까지 장애가 지속적으로 발생했습니다.)
원인 분석2
인프라팀에게 DB 인스턴스 재부팅을 요청드린 다음 저는 여러가지 로그 파일들을 확인하기 시작했고, 다음과 같이 이상한 부분을 발견할 수 있었습니다.
1. audit.log의 비정상적인 패턴
audit.log 파일의 파일명은 보통 .1로 끝나는데 1000번대까지 생성이 되어있습니다.
2. general.log.spillover 파일 기록

3. mysql-general.log 파일이 no space left on device 에러로 적재되지 않고 있다는 점

참고!
no space left on device 에러는 인스턴스에 저장 공간이 부족할 때 발생하는 에러입니다.
이러한 에러가 발생하고 있는 것이 의심스러워 모니터링 지표를 살펴보기 시작합니다.
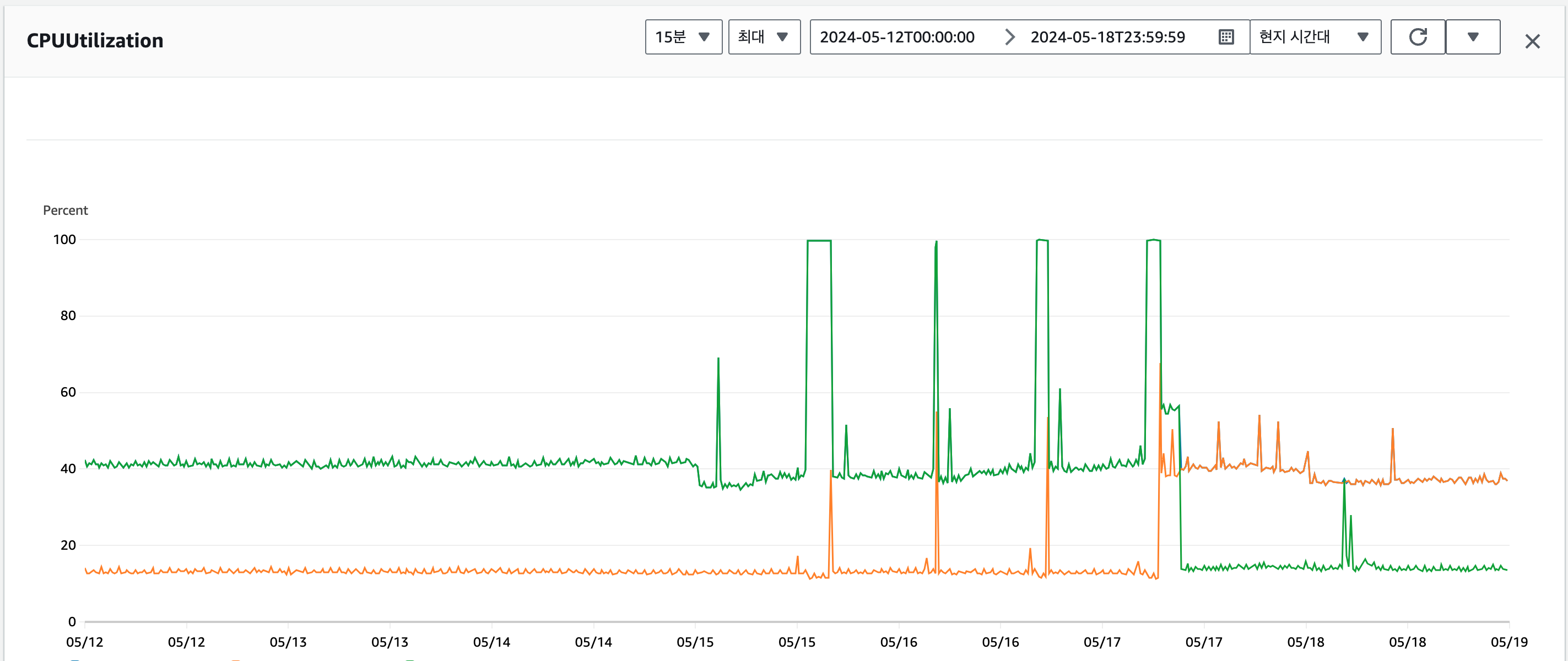
Amazon Aurora CloudWatch 지표 설명에서 FreeLocalStorage 항목을 아래와 같이 설명하고 있습니다.
사용 가능한 로컬 스토리지 양입니다.
다른 DB 엔진과 달리 Aurora DB 인스턴스의 경우, 이 지표는 각 DB 인스턴스에 사용 가능한 스토리지 크기를 보고합니다. 이 값은 DB 인스턴스 클래스에 좌우됩니다(요금에 대한 자세한 내용은 Amazon RDS 요금 페이지 참조).
DB 인스턴스 클래스를 큰 것으로 선택하면 인스턴스의 여유 스토리지 공간을 늘릴 수 있습니다.
(Aurora Serverless v2에는 적용되지 않습니다.)
정리를 하면 어떠한 이유로 DB 인스턴스의 LocalStorage 용량을 고갈시키면서 장애가 발생했고, AWS는 이러한 인스턴스를 FailOver 처리 하면서 다시 정상화되고, 다시 LocalStorage 용량을 고갈시키면서 장애가 발생, 다시 재부팅... 이러한 현상이 며칠동안 지속되고 있었습니다.
제일 먼저 해당 패턴이 언제부터 시작됐는지 식별하기 위해 FreeLocalStorage 지표의 범위를 더욱 늘려서 확인을 합니다.
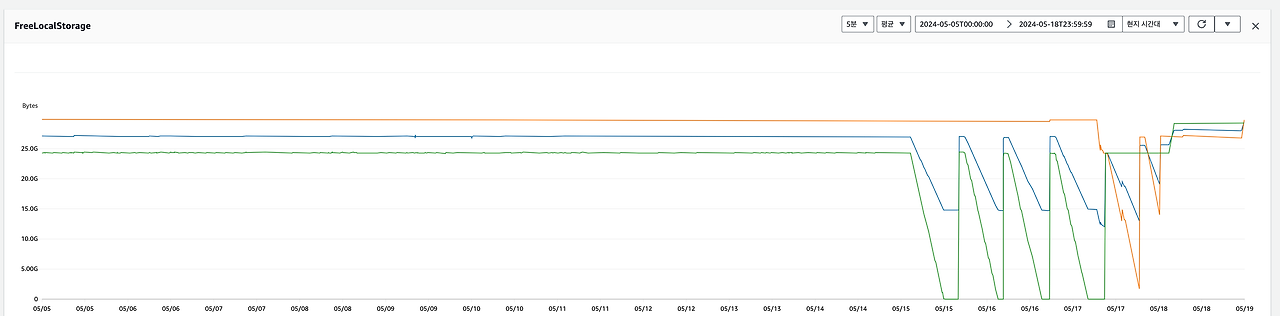
지표 상으로 해당 장애는 5월 15일 새벽 2시부터 발생하기 시작했다는 것을 알 수 있습니다. 그리고 이를 기반으로 서비스에 영향이 갈만한 부분들을 검토하기 시작합니다.
-
MySQL이 LocalStorage 용량을 어떠한 상황에서 사용하는지.
→ 각종 Logging과 가상 테이블 및 임시 테이블을 위해 사용됩니다. -
5월 13일(월요일)부터 문제가 발생한 시점인 5월 17일(목요일) 사이에 배포된 기능이 있는지.
→ Jenkins 히스토리와 Argo에서 발견된 배포 기록은 찾을 수 없었기 때문에 서비스 배포의 문제는 아니었습니다. -
데이터가 쌓이면서 SQL 실행 동작이 변경되면서 가상 테이블을 사용하는 케이스가 늘었는지.
MySQL에 설정된 메모리 용량을 over 하면 디스크에 기록하게 되면서 LocalStorage 용량을 소비할 수 있습니다.
그러나 이 부분에 대해서도 별다른 이상함을 찾지 못했습니다. (이 부분을 확인하기 위해 리서치하고 공부했던 내용은 추후 게시글로 작성할 예정입니다.) -
그 외 우리가 모르는 문제가 생겼는지. (AWS 문제 등)
처음으로 돌아가서...
여러가지의 가능성을 열고 살펴봤음에도 별다른 문제를 찾지 못했습니다. 그래서 AWS의 문제일 수 있다는 가정을 가지고 처음으로 되돌아가서 확인하기 시작합니다.
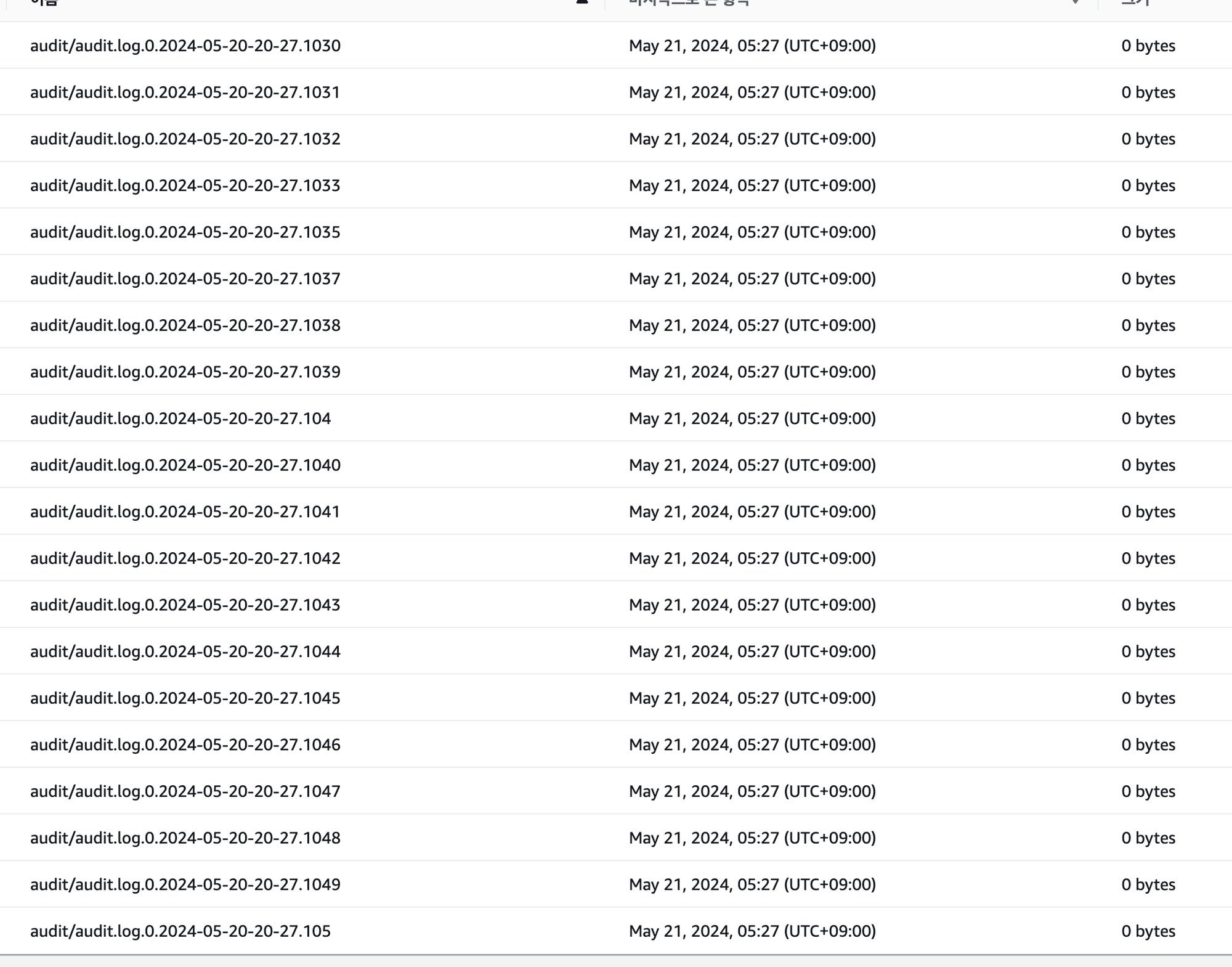
RDS 로그 및 이벤트 탭의 audit.log 파일의 패턴을 보면 파일이 비정상적으로 대량 생성되고 있었습니다.
이 부분에 대해서 AWS Case를 열어볼까 고민하며 리서치를 하던 중 아래의 문서를 발견하게 됩니다.
( Aurora MySQL 데이터베이스 엔진 업데이트 2024-03-15 (버전 3.04.2, MySQL 8.0.28과 호환) )
가용성 향상:
- Aurora 스토리지와 통신하는 구성 요소의 결함으로 인해 Aurora MySQL 작성기 DB 인스턴스가 장애 조치될 수 있는 문제를 수정했습니다. 이 결함은 소프트웨어 업데이트 이후 DB 인스턴스와 기본 스토리지 간의 통신이 중단되어 발생합니다.
- 감사 로깅 스레드로 인해 발생하는 잠금 경합에 따라 CPU 사용률이 높아지고 클라이언트 애플리케이션 제한 시간이 초과될 수 있는 문제를 해결했습니다.
일반적인 개선 사항:
- 다운로드 또는 로테이션 시 로그 파일에 액세스 할 수 없고 경우에 따라 CPU 사용량이 증가할 수 있는 감사 로그 파일 관리 관련 문제를 수정했습니다.
현재 저희가 사용 중인 인스턴스의 엔진 버전은 8.0.mysql_aurora.3.04.1으로 위 문제가 발생할 수 있는 버전이었습니다.
해당 문서의 내용을 토대로 MySQL의 Logging을 전부 비활성화하니 관련 이슈가 더 이상 발생하지 않았습니다.

그리고 이 내용을 공유하면서 장애 관련 조치는 일단락되었습니다. 추후 인프라팀에 Aurora MySQL 엔진 업그레이드를 요청한 다음 로그를 다시 활성화시켜 볼 예정입니다.
읽어주셔서 감사합니다.
