
인공지능 : 사람의 지능을 만들기 위한 시스템이나 프로그램
강인공지능 : 사람가 구분이 안 될 정도로 강한 성능을 가진 인공지능
- 예시) 아이언맨의 자비스
약인공지능 : 특정 영업에서 작업을 수행하는 인공지능
- 예시) 자율주행 자동차, 구글의 인공지능 스피커
머신러닝, 딥러닝, 인공지능의 관계
인공지능 < 머신러닝 < 딥러닝
- 인공지능 : 사람의 지능을 만들기 위한 시스템이나 프로그램
- 머신러닝 : 스스로 규칙을 수정하는 프로그램
- 딥러닝 : 인공신경망에서 발전한 형태의 인공 지능으로, 뇌의 뉴런과 유사한 정보 입출력 계층을 활용해 데이터를 학습합니다
지도학습
- 입력과 타겟을 통해 모델을 훈련한다.
비지도학습
- 타깃이 없는 데이터를 통해 모델을 훈련
강화학습
- 주어진 환경으로부터 피드백을 받는 에이전트를 훈련시키는데, 특정 환경 환경에 최적화된 행동을 수행하고 수행에 대한 보상과 현재 상태를 받는다. 에이전트의 목표는 최대한 많은 보상을 받는 것이다.
규칙
- 가중치와 절편
- 가중치 : 입력과 곱하는 수
- 절편 : 더하는 수
모델 파라미터
- 가중치와 절편을 한번에 부르는 말
손실함수의 타겟과 예측의 차이
- 손실함수는 y = wx + b의 형태로 이뤄진다.
- 만약 예측값이 0.8인데 정답은 1이였다면?
- 규칙을 0.2정도 상향조정해야한다.
- 이때 손실함수의 최솟값을 효율적으로 찾는 방법이 필요한데
- 이를 최적화 알고리즘이라고 한다.
각 AI가 더 잘 처리하는 것
딥러닝 : 이미지/영상, 음성/소리, 텍스트/번역 = 비정형 데이터
머신러닝 : 데이터베이스, 레코드 파일, 엑셀/CSV = 정형 데이터
선형회귀
- 1차함수로 표현된다. ( y = wx + b )
- 기울기와 절편을 찾아내준다.
훈련 데이터에 잘 맞는 w와 b를 찾는 방법 ( 예에에에전 방식)
- 무작위로 w와 b를 정한다.
- x에서 샘플 하나를 선택하여 y_hat을 계산합니다. (무작위로 모델 예측)
- y_hat과 선택한 샘플의 진짜 y를 비교합니다. ( 예측한 값과 실제 값 비교 )
- y_hat이 y와 더 가까와지도록 w, b를 조정합니다. ( 모델 조정 )
- 모든 샘플을 처리할 때까지 다시 2~4 항목 반복
- w의 변화율 = (_increased - ) / (w_increased - w) == x[0]
- (변화율이 양수) w가 증가하면 이 증가
- (변화율이 음수) w가 감소하면 이 증가
문제점 ( 변화율을 더할 경우 )
- yhat과 y의 차이가 크다면 w와 b를 더 큰 폭으로 수정할 수 없다.
- yhat이 y보다 크면 yhat을 감소시키지 못한다.
개선
- 오차 역전파를 (오차와 변화율을) 이용해 가중치/절편을 업데이트한다
- w와 b를 임의의 값으로 초기와하고 훈련데이터 샘플을 하나씩 대입해 y와 의 오차를 구한다.
- 1에서 구한 오차를 w와 b의 변화율에 곱하고 이 값을 이용해 w와 b를 업데이트한다.
- 이 y보다 커지면 오차는 음수가되어 w와 b가 줄어드는 방향으로
- 반대로 이 y보다 커지면 오차는 양수가 되고 w와 b는 더 커지도록 업뎃
손실함수
- 제곱오차 = ( y - )^2
- 제곱오차를 가중치에 대해 미분 :
- 제곱오차를 절편에 대해 미분 :
뉴런
정방향 계산
def forpass(self, x):
y_hat = x * self.w + self.b # y = wx + b
return y_hat- , 을 리턴함.
역방향 계산
def backprop(self, x, err):
w_grad = x * err
b_grad = 1 * err
return w_grad, b_gradfit 메소드 구현
def fit(self, x, y, epochs=100)
for i in range(epochs): # 에포크만큼 반복합니다.
for x_i, y_i in zip(x,y): # 모든 샘플에 대해 반복
y_hat = self.forpass(x_i) # 정방향 계산
err = -(y_i - y_hat) # 오차 계산
w_grad, b_grad = self.backprop(x_i, err) # 역방향 계산
self.w -= w_grad # 가중치 업데이트
self.b -= b_grad # 절편 업데이트로지스틱 회귀
: 분류 알고리즘
- 모델 ( y=wx+b) → 활성화 함수(시그모이드) → 임계함수(계단) → 결과
아달린
- 버나드 위드로우 & 테드 호프 적응형 선형 뉴런 발표
시그모이드 함수
odds ratio(오즈) : (p=성공확률)
logit (로짓함수):
시그모이드 함수 :
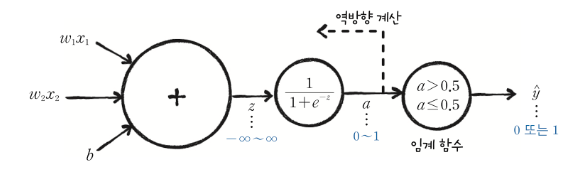
로지스틱 손실 함수
( 이진 크로스 엔트로피 | 로지스틱 손실 함수 )두가지 사용

로지스틱 손실함수를 미분
- L을 a에 대해 미분
- a를 z에 대해 미분
- z를 w에 대해 미분
=
※ 우리는 이걸 체인 룰(Chain Rule)이라고 하기로 했어요.
경사하강법의 종류
- 확률적 경사하강법 : 1개의 샘플을 중복되지 않도록 무작위 선택
- 미니배치 경사하강법 : 전체 샘플 중 몇개의 샘플을 중복되지 않도록 무작위 선택
- 배치 경사 하강법 : 전체 샘플을 모두 선택 → 그레이디언트 계산 (에포크)
훈련 노하우
- 학습률이 높을때 : 가중치의 변화가 커서 전역 최솟값을 지나칠 수 있다.
- 학습률이 적절할때 : 가중치의 변화가 안정적이므로 전역 최솟값에 잘 도착한다.
- 학습률이 낮을때 : 최솟값에 수렴하기까지 걸리는 시간이 오래걸린다. 로컬 미니멈에 빠질 수 있다.
스케일
표준화 : (특성값 - 평균)을 표준편차로 나눈다.
표준편차 공식 :
- 시그마(특성값 - 평균)의 제곱을 샘플의 수로 나누고 루트를 씌운 값
검증세트의 스케일과 훈련세트의 스케일은 서로 같은 스케일로 조정되야함.
(다를 경우 데이터 왜곡 발생)
과대적합 : 분산이 큼
과소적합 : 편향이 큼
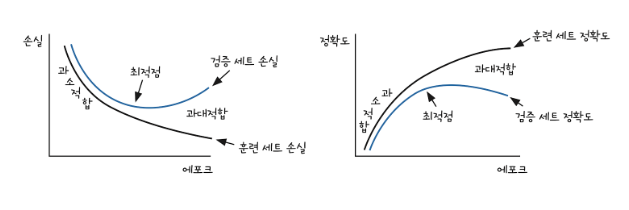
에포크가 너무 과해지면 과대적합이 된다.
과대적합을 해소하기 위한 규제
- 손실함수 + L1 norm(노름) = 라쏘(Lasso)
- 그레이디언트에서 alpha에 가중치의 부호를 곱하여 그레이디언트에 더한다.
- 손실함수 + L2 norm(노름) = 릿지(Ridge)
-
그레이디언트에서 alpha에 가중치를 곱하여 그레이디언트에 더한다.
교차 검증(Fold)
- 훈련 세트를 k개의 폴드(fold)로 나눈다.
- 모델을 훈련한 다음에 검증 세트로 평가합니다.
- 첫 번째 폴드를 검증 세트로 사용하고 나머지 폴드(k-1)개를 훈련 세트로 사용한다.
- 차례대로 다음 폴드를 검증세트로 사용하여 반복합니다.
- k개의 검증세트로 k번 성능을 평가한 후 계산된 성능의 평균을 내어 최종성능을 계산
-
