
1. 데이터 마이닝이란?
1-1) 왜 데이터를 마이닝을 하는가? (기업적 관점)
- 많은 양의 데이터가 수집, 저장된다.
- 웹 데이터, e 커머스
- 백화점, 식료품점의 구매 내역
- 카드 거래 내역
- 모바일 데이터
- 컴퓨터가 저렴해지고 성능이 좋아지고 있다.
- 강력한 경쟁 압력 (선진국의 성장률 감소)
- 고객을 위한 더 나은 맞춤형 서비스 제공 (ex. CRM)
1-2) 왜 데이터를 마이닝을 하는가? (과학적 관점)
- 데이터가 막대한 속도로 수집, 저장된다. (TB / hour)
- 위성의 센서들, 기상관측 데이터(바다, 풍향, 기압, 태풍, .... )
- 하늘을 관측하는 망원경 데이터
- 유전자 발현 데이터를 생성하는 마이크로어레이
- 수 테라바이트의 데이터를 생성하는 과학적 시뮬레이션
- 전통적인 기술로는 raw데이터 처리가 힘들다. (의미있는 데이터를 뽑아낼 수 없다.)
- 데이터 마이닝이 과학자를 돕는다.
- 데이터의 분류 및 분할
- 가설 형성
2) 데이터 마이닝이 무엇인가?
- 데이터에서 추출된, 이전에 알려지지 않았으며 잠재적으로 유용할 정보
- 의미있는 패턴을 찾기 위해 많은 양의 데이터를 자동, 반자동으로 탐색하고 분석한다.
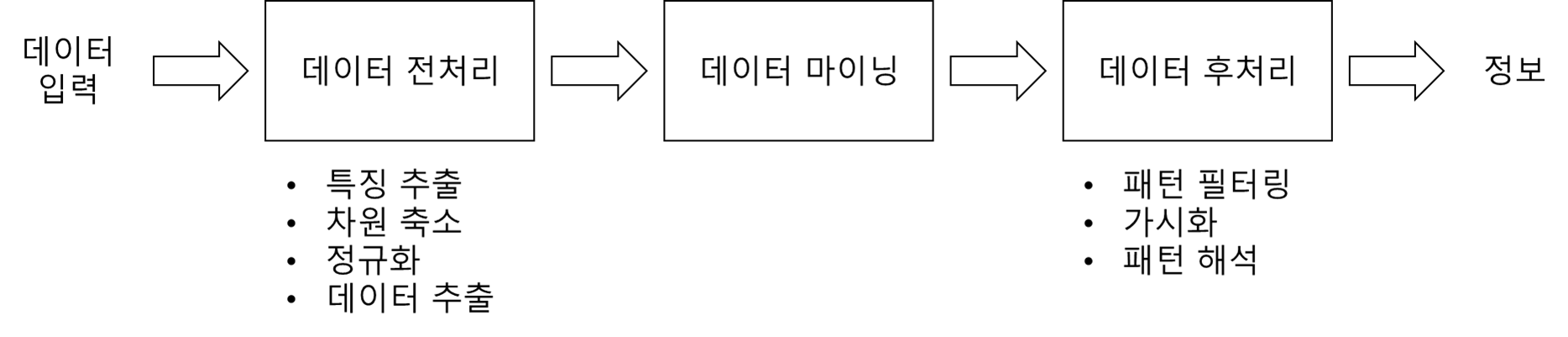

3) 데이터 마이닝이 아닌 것은 무엇인가?
- 데이터 마이닝이 아닌 경우
- 단순 정보 검색
- 예시
- 휴대폰 주소록에서 번호 찾기
- 검색 엔진에서 아마존 정보 찾기
- 데이터 마이닝인 경우
- 데이터에서 새로운 정보를 추출함
- 예시
- 위치 별 이름의 인구 분포
- 특정 이름은 특정 위치에서 더 널리 사용된다.
- 보스턴 지역에서 O’Brien, O’Rurke, O’Reilly…
- 특정 이름은 특정 위치에서 더 널리 사용된다.
- 검색 엔진이 문맥에 따라 유사한 문서를 그룹화 하는 것
- Amazon rainforest, Amazon.com
- 위치 별 이름의 인구 분포
4) 데이터 마이닝의 기원
-
기계 학습/AI, 패턴 인식, 통계 및 데이터베이스 시스템에서 아이디어 도출
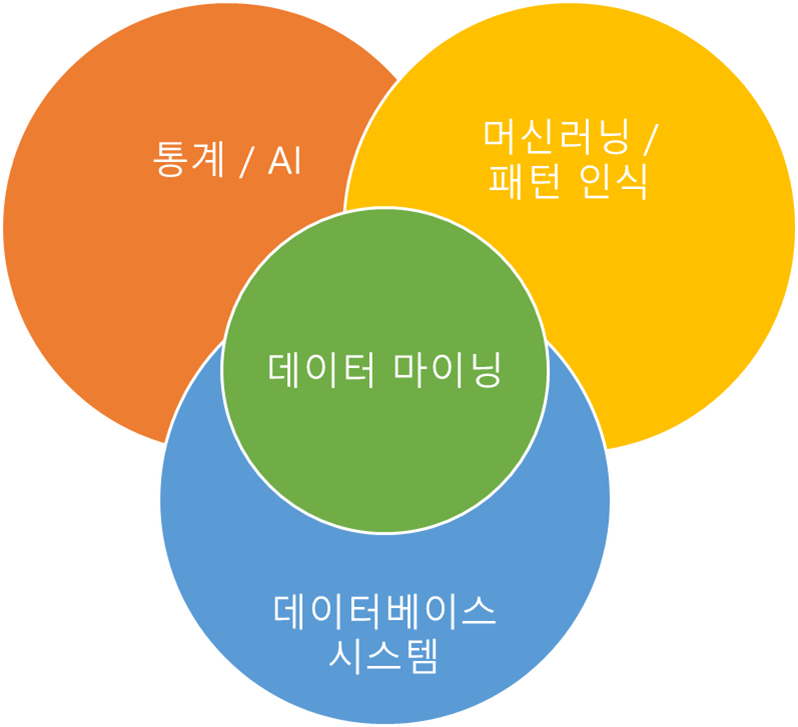
-
전통적 기술은 아래 이유로 적합하지 않다.
- 방대한 데이터
- 데이터의 고차원성
- 이질적이고 분산된 날 것의 데이터
5) 데이터 마이닝의 바른 이해
- 데이터 마이닝은 방대한 양의 데이터에 지능적인 기술을 적용시켜 마술같이 해답을 얻어내는 솔루션은 아니다.
- 데이터 마이닝은 전문적 비즈니스 지식과 고급 분석 기술을 결합하는, 상호작용적이고 반복적인 프로세스이다. (데이터 기반의 지식 발견 과정)
2. 데이터 마이닝 태스크
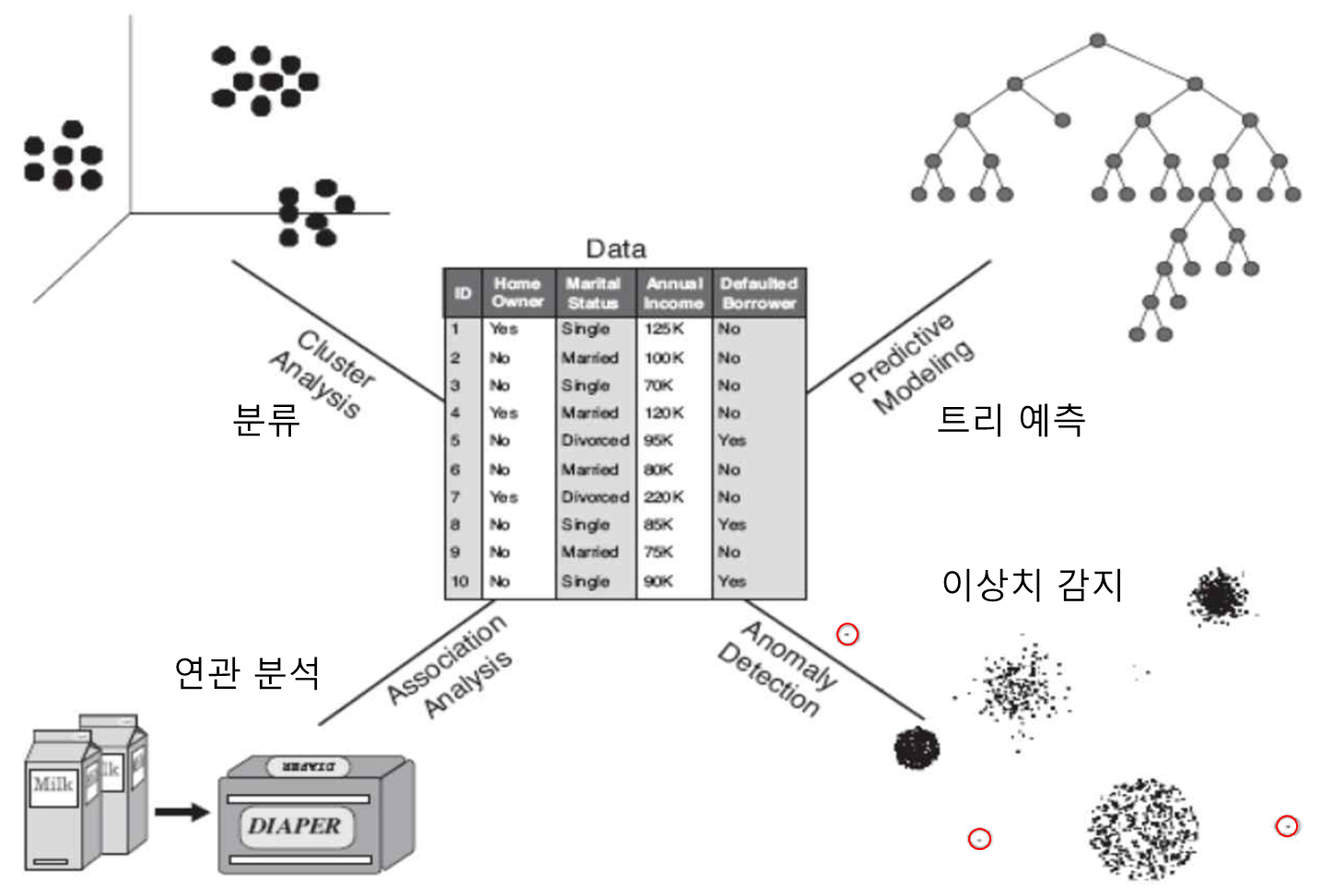
1) 데이터 마이닝이 할 수 있는 일
- 예측(Prediction)
- 일부 변수를 사용하여 다른 변수의 알 수 없거나 미래 값을 예측할 수 있다.
- 분류 (Classification)
- 회귀 (Regression)
- 이상치 탐지 (Anomaly Detection)
- 일부 변수를 사용하여 다른 변수의 알 수 없거나 미래 값을 예측할 수 있다.
- 표현(Description)
- 데이터를 사람이 설명할 수 있는 패턴으로 표현 (패턴 발견)
- 군집화 (Clustering)
- 연관 규칙 발견 (Association Rule Discovery)
- 순차적 패턴 발견 (Sequential Pattern Discovery)
- 예) GSP(DB의 패턴을 읽고 분석), PrefixSpan(GSP를 개선, 트리를 사용함)
- 예) GSP(DB의 패턴을 읽고 분석), PrefixSpan(GSP를 개선, 트리를 사용함)
- 데이터를 사람이 설명할 수 있는 패턴으로 표현 (패턴 발견)
1-2) 분류 (Classification)
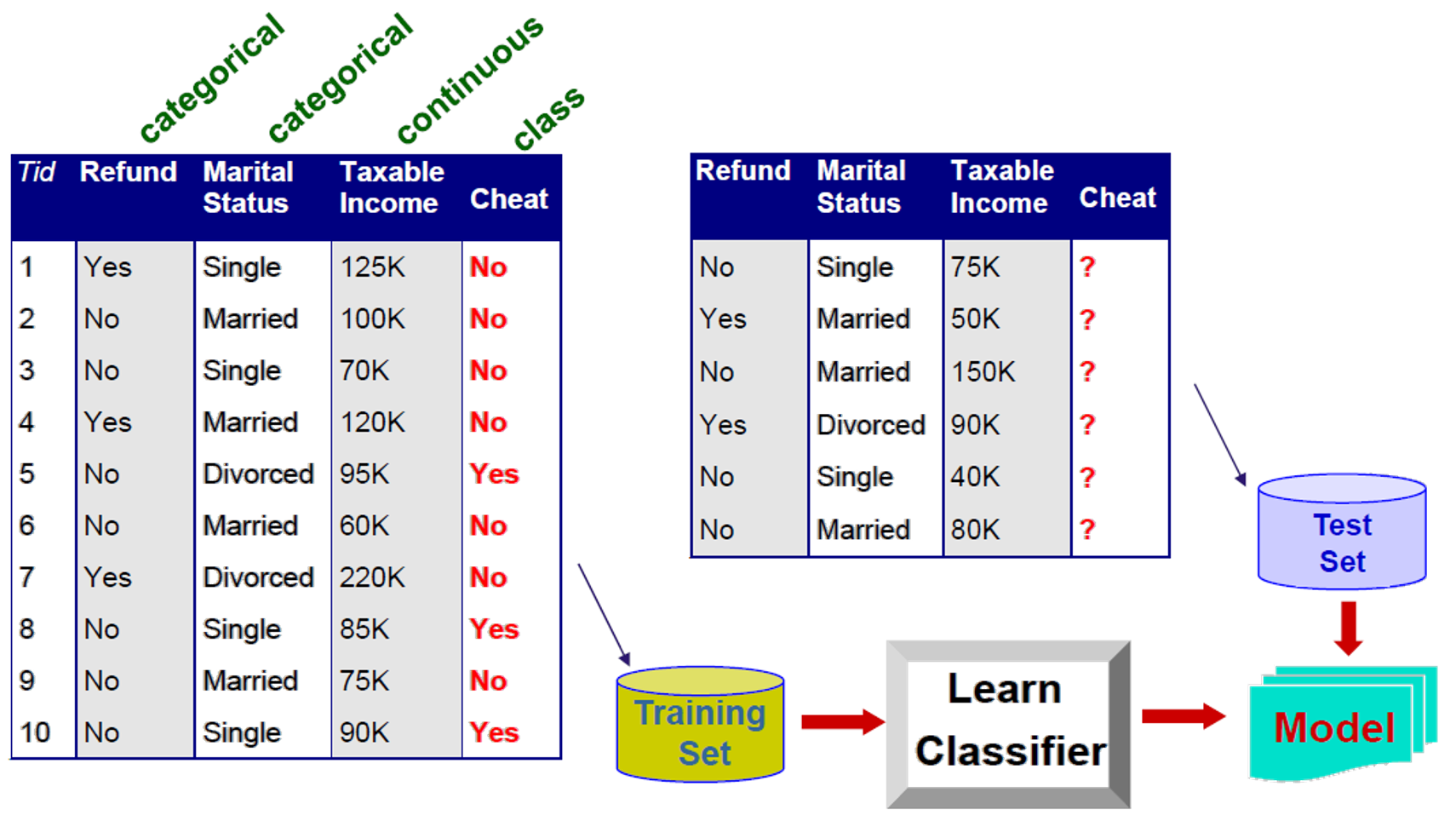
- 목표: 새로운 레코드가 들어왔을 때 가능한 정확하게 클래스가 할당되어야 한다.
- 검정 세트(test set)는 모형의 정확도를 확인하는 데 사용된다.
- 일반적으로, 주어진 데이터 세트는 모델을 구축하는 데 사용되는 훈련 세트와 이를 검증하는 데 사용되는 시험 세트로 구분된다.
- 과정
- 레코드 모음이 주어지면 (training set)
- 각 레코드는 속성(attribute) 집합이 포함되어 있으며, 속성 중 하나는 클래스이다.
- 다른 속성 값의 함수로서 클래스 속성에 대한 모델을 찾는다.
- 레코드 모음이 주어지면 (training set)
- 분류 예시
- 신용카드 이상 거래 검출
- 위성 사진에서 지형 분류(도시, 숲, 바다, ...)
- 뉴스 카테고리화(정치, 경제, 날씨, ...)
- 등등
1-3) 편차/이상치 감지
- 정상적인 동작에서 유의미한 편차를 감지한다.
- 예시
- 신용 카드 사기 탐지
- 네트워크 침입 감지 (대학 수준의 일반적인 네트워크 트래픽은 하루에 1억 개 이상의 연결에 도달할 수 있다.)
1-4) 군집화 (Clustering)
- 각각 속성 집합과 유사성 측도가 있는 데이터 점 집합이 주어지면 다음과 같은 군집을 찾는다.
- 한 군집에 있는 데이터들은 유사하다.
- 다른 군집에 있는 데이터들은 유사성이 적다.
- 유사도 측정
- 연속성을 가진 속성은 유클리드 거리로 유사도를 구한다. (피타고라스 정리와 비슷)
- 군집화 예시 (문서 군집화)
- 목표: 문서에 나타나는 중요한 용어를 기반으로 유사한 문서 그룹을 찾는다.
- 접근 방법: 각 문서에서 자주 발생하는 용어를 식별한다. 서로 다른 용어의 빈도수를 기준으로 유사성 측정한다. 이 유사도를 군집화하는 데 사용한다.
- 이득: 정보 검색은 클러스터를 활용하여 새 문서 또는 검색어를 군집화된 문서와 연결할 수 있다.
1-5) 연관 규칙 발견 (Association Rule Discovery)
- 주어진 컬렉션에서 몇 가지 항목을 포함하는 각각의 레코드 집합이 제공된다.
- 다른 항목의 발생을 기반으로 항목의 발생을 예측하는 종속성 규칙을 생성합니다.
- 현재 전자상거래에서 많이 사용된다.
- 예시

2) 데이터 마이닝의 과제
- 확장성(Scalability)
- 차원성(Dimensionality)
- 복잡하고 이질적인 데이터(Complex and Heterogeneous Data)
- 데이터 품질(Data Quality)
- 데이터 소유 및 배포(Data Ownership and Distribution)
- 사생활 보호(Privacy Preservation)
- 실시간 데이터(Streaming Data)
3. 데이터 마이닝 모델링
1) 데이터 마이닝 수행방법론
- CRISP-DM (CRoss-Industry Standard Process for Data Mining)
- 6단계로 구성
- 화살표는 단계간의 주요 의존관계를 표시, 외부의 원은 데이터 마이닝이 본질적으로 가지고 있는 순환적 특성을 의미

- 화살표는 단계간의 주요 의존관계를 표시, 외부의 원은 데이터 마이닝이 본질적으로 가지고 있는 순환적 특성을 의미
- 6단계로 구성
| 단계 | 내용 | 단계 | 내용 |
|---|---|---|---|
| 1. 비즈니스 이해 | - 업무 목적 결정 | 4. 모델링 | - 모델링 기법 선택 |
| - 상황 평가 | - 테스트 설계 생성 | ||
| - 데이터 마이닝 목표 결정 | - 모델 생성 | ||
| - 프로젝트 계획 수립 | - 모델 평가 | ||
| 2. 데이터 이해 | - 초기 데이터 수집 | 5. 평가 | - 결과 평가 |
| - 데이터 기술 | - 프로세스 재검토 | ||
| - 데이터 탐색 | - 향후 단계 결정 | ||
| - 데이터 품질 검증 | |||
| 3. 데이터 준비 | - 데이터 설정 | 6. 전개 | - 전개 계획 수립 |
| - 데이터 선택 | - 모니터링/유지보수 계획 수립 | ||
| - 데이터 정제 | - 최종 보고서 작성 | ||
| - 데이터 생성 | - 프로젝트 재검토 | ||
| - 데이터 통합 | |||
| - 데이터 형식 적용 |
