데이터 조작어(DML)
데이터 조작어라 부르는 DML(Data Manipulation Language)은 데이터베이스 내에 저장된 데이터를 조회, 추가, 수정, 삭제하기 위해 사용하는 명령어다. 그래서 DML에는 SELECT문, INSERT문, UPDATE문, DELETE문이 있다.
SELECT문과 FROM절
SELECT문은 데이터베이스에 저장되어 있는 데이터를 조회하는 데 사용한다. SELECT문의 FROM절은 조회할 테이블을 지정하고, SELECT절은 조회할 테이블의 열을 지정한다.
SELECT *
FROM 테이블명;*는 해당 테이블의 모든 열을 조회한다는 의미이다. 위와 같은 경우 FROM절에서 지정한 테이블의 모든 열을 조회한다.
특정 컬럼을 지정하여 조회
SELECT 컬럼1, 컬럼2, 컬럼3 ...
FROM 테이블명;위와 같이 작성하여 원하는 컬럼만 지정해 조회할 수 있다.
다음은 EMPLOYEES테이블에서 직원아이디, 이름, 연봉 컬럼을 조회한 예시다.
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY
FROM EMPLOYEES;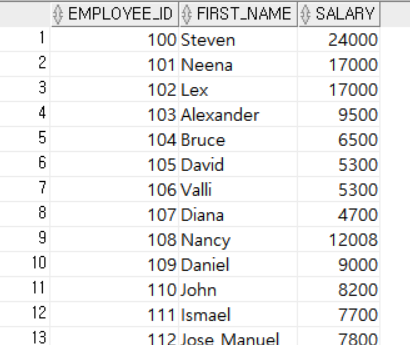
연산자를 활용한 컬럼
연산자를 활용해서 컬럼을 조회할 수 있다. 컬럼 한 개에 대한 연산식 뿐만 아니라 두 컬럼을 연산자를 통해 결합하여 하나의 컬럼처럼 조회할 수 있다.
다음은 EMPLOYEES테이블의 SALARY에 12를 곱한 값을 나타내는 컬럼을 추가로 출력한 예시다.
SELECT FIRST_NAME, SALARY, SALARY*12
FROM EMPLOYEES;
다음은 JOBS테이블의 MAX_SALARY와 MIN_SALARY의 차를 나타내는 컬럼을 추가로 출력한 예시다. 각각의 MAX_SALARY와 MIN_SALARY컬럼을 연산자로 조합하여 하나의 컬럼처럼 출력했다.
SELECT JOB_ID, MAX_SALARY-MIN_SALARY
FROM JOBS;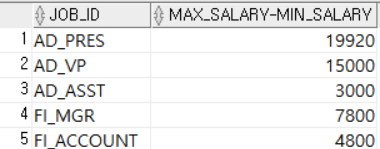
컬럼의 별칭 지정
SELECT 컬럼 별칭
FROM 테이블명;
SELECT 컬럼 "별칭"
FROM 테이블명;
SELECT 컬럼 AS 별칭
FROM 테이블명;
SELECT 컬럼 AS "별칭"
FROM 테이블명;위 네 가지 방법으로 컬럼의 별칭을 지정할 수 있다. 별칭을 지정하면 조회 결과에 컬럼이름 대신 별칭이 나온다. 가독성을 위해 첫 번째 방법은 지양하는 것이 좋다고 생각한다.
다음은 조회할 컬럼을 지정한 후 별칭을 적용한 예시다.
SELECT FIRST_NAME AS 이름, SALARY AS 월급, SALARY*12 AS 연봉
FROM EMPLOYEES;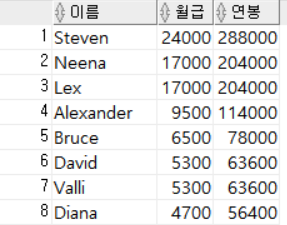
DISTINCT
SELECT DISTINCT 컬럼
FROM 테이블명;DISTINCT는 중복되는 데이터가 있는 행을 제외하고 출력하는 SQL의 예약어이다. 위와 같이 SELECT절의 컬럼 앞에 DISTINCT를 붙여 해당 컬럼의 값이 중복되는 행을 제외하고 출력할 수 있다.
SELECT DISTINCT MANAGER_ID
FROM EMPLOYEES;
SELECT DISTINCT MANAGER_ID, DEPARTMENT_ID
FROM EMPLOYEES;첫 번째 방법은 MANAGER_ID값이 같은 행을 제외한 후 출력하고, 두 번째 방법은 MANAGER_ID, DEPARTMENT_ID 둘 다 같아야 중복되는 행이라 간주한다.
ORDER BY절
ORDER BY절은 조회한 데이터를 특정 컬럼을 기준으로 정렬하는 데 사용한다. SELECT문을 작성할 때, 여러 절 중 가장 마지막 부분에 작성한다.
SELECT 컬럼1, 컬럼2, 컬럼3 ...
FROM 테이블명
ORDER BY 정렬기준 정렬옵션정렬옵션으로는 ASC와 DESC가 있다. ASC는 Ascending의 약자로 오름차순을 뜻하며, DESC는 Descending의 약자로 내림차순을 뜻한다. 정렬옵션을 생략하면 기본값은 ASC가 적용된다.
오름차순
SELECT FIRST_NAME AS 이름,
HIRE_DATE AS 입사일,
SALARY AS 월급
FROM EMPLOYEES
ORDER BY 입사일 ASC;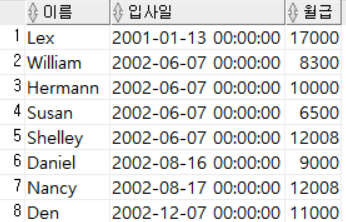
입사일을 기준으로 오름차순 정렬했다. ORDER BY에 컬럼명이 아니라 별칭을 적용해도 에러가 발생하지 않는 이유는 ORDER BY절이 가장 마지막에 실행되기 때문이다. SELECT절에서 먼저 컬럼의 별칭이 지정된 후 ORDER BY절이 실행된다.
내림차순
SELECT FIRST_NAME AS 이름,
HIRE_DATE AS 입사일,
SALARY AS 월급
FROM EMPLOYEES
ORDER BY 월급 DESC;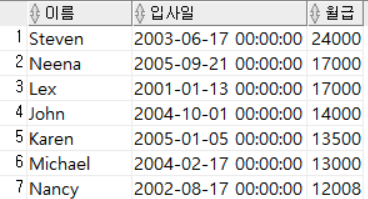
월급을 기준으로 내림차순 정렬했다.
여러 개의 정렬 기준 사용
SELECT FIRST_NAME AS 이름,
JOB_ID AS 직종,
SALARY AS 월급
FROM EMPLOYEES
ORDER BY 직종 ASC, 월급 DESC;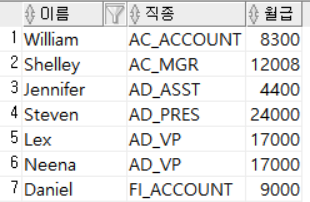
첫 번째 정렬 기준으로 JOB_ID를 지정했고, JOB_ID가 같을 경우 SALARY를 내림차순하여 정렬했다.
주의 사항
ORDER BY절을 통해 조회된 데이터를 정렬하는 것은 많은 자원을 소모한다. 그래서 출력할 데이터를 선정하는 시간보다 정렬하는 데 시간이 더 걸려 서비스 응답 속도가 느려질 수 있다. 따라서 정렬이 꼭 필요한 경우가 아니라면 ORDER BY절은 넣지 않는 것이 좋다.
WHERE절
SELECT 컬럼1, 컬럼2 ...
FROM 테이블명
WHERE 조건식WHERE절은 SELECT문으로 데이터를 조회할 때 특정 조건을 기준으로 원하는 행을 출력하는 데 사용한다. WHERE절 또한 연산자를 사용하여 더욱 구체적으로 데이터를 조회할 수 있다.
WHERE절의 조건식에 사용되는 컬럼명은 별칭을 사용할 수 없다. SQL의 실행순서 상 WHERE절이 SELECT절보다 먼저 실행되기 때문이다. 즉, WHERE절로 먼저 필터링을 한 후 SELECT절을 통해 컬럼에 별칭이 지정된다.
WHERE절에서 사용하는 연산자나 기호에 대해 주의해야 할 점은 다음과 같다.
-
SQL에서 값이 같은지 비교하는 연산자는
=이다.
(일반적인 프로그래밍 언어처럼==이 아니다.) -
SQL에서 문자열을 나타내는 기호는 작은 따옴표(
'')다.
일반적인 프로그래밍 언어처럼 큰 따옴표("")가 아니다. -
값이 NULL인 경우 비교 연산자를 통해 조회할 수 없다.
-
예약어(SELECT, FROM 등)는 대소문자를 구분하지 않지만, 데이터의 '값'은 대소문자를 구분한다.
예를 들어, SQL을 작성할 때 JOB_ID의 IT_PROG과 IT_Prog는 다르게 간주한다.
비교 연산자
SELECT FIRST_NAME AS 이름,
SALARY AS 월급
FROM EMPLOYEES
WHERE SALARY >= 10000;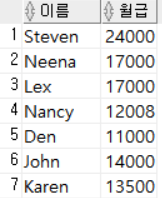
SALARY를 기준으로 SALARY가 10000이상인 행만 출력했다. 위에서 언급했던 것 처럼 WHERE절에는 별칭을 사용할 수 없다.
SELECT FIRST_NAME AS 이름,
JOB_ID AS 직종,
SALARY AS 월급
FROM EMPLOYEES
WHERE JOB_ID = 'IT_PROG';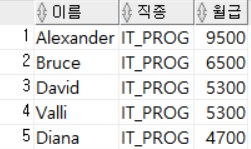
JOB_ID가 IT_PROG인 행만 출력했다.
NULL
데이터베이스에서 null은 아직 값이 결정되지 않았은 것을 의미한다. 그리고 null이 포함된 산술 연산의 결과는 항상 null이다. Java에서 null의 의미와 다르다.
위에서 언급했다시피 값이 null인 경우, 비교 연산자를 통해 조회할 수 없다. 대신에 IS NULL 혹은 IS NOT NULL이라는 예약어를 사용한다.
SELECT FIRST_NAME AS 이름,
JOB_ID AS 직종,
COMMISSION_PCT
FROM EMPLOYEES
WHERE COMMISSION_PCT IS NULL;
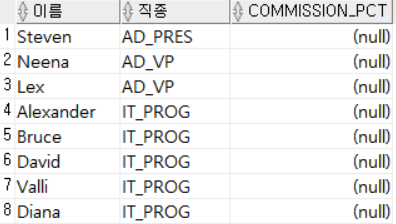
COMMISSION_PCT가 없는 직원의 이름, 직종, COMMISSION_PCT를 출력한 예시다. COMMISSION_PCT가 없는 행만 출력했으므로 결과도 당연히 COMMISSION_PCT열의 모든 값은 null이다.
논리 연산자
논리 연산자를 통해 여러 조건을 조합하여 WHERE절을 작성할 수 있다.
SELECT FIRST_NAME AS 이름,
JOB_ID AS 직종,
SALARY AS 급여,
COMMISSION_PCT
FROM EMPLOYEES
WHERE (COMMISSION_PCT IS NOT NULL) AND SALARY >= 10000;
COMMISSION_PCT가 있는 직원들 중, 급여가 10000이상인 직원들의 이름, 직종, 급여를 출력했다.
SELECT FIRST_NAME AS 이름,
JOB_ID AS 직종,
SALARY AS 급여,
DEPARTMENT_ID AS 부서아이디
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 40 OR DEPARTMENT_ID = 70 OR DEPARTMENT_ID = 110;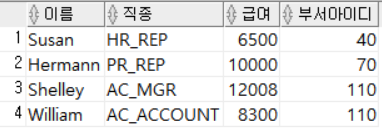
DEPARTMENT_ID가 40,70,110 중 하나인 직원들의 이름, 직종, 급여, 부서아이디를 출력했다.
BETWEEN
SELECT 컬럼1, 컬럼2 ...
FROM 테이블명
WHERE 컬럼 BETWEEN 하한값 AND 상한값;BETWEEN은 지정한 컬럼의 값의 범위에 속하는 행을 출력한다. 위에서 다룬 논리 연산자로 표현하면 WHERE 하한값 <= 컬럼 AND 컬럼 <= 상한값과 같다.
SELECT FIRST_NAME AS 이름,
SALARY AS 급여
FROM EMPLOYEES
WHERE SALARY BETWEEN 5000 AND 10000;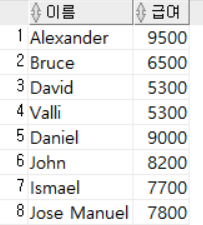
급여가 5000이상, 10000이하인 직원들의 이름과 급여를 출력했다.
IN
SELECT 컬럼1, 컬럼2 ...
FROM 테이블명
WHERE 컬럼 IN (값1, 값2 ...);IN은 지정한 컬럼에서 괄호 안의 값들 중 하나와 일치하는 행을 출력한다. 위에서 다룬 논리 연산자로 표현하면 WHERE 컬럼 = 값1 OR 컬럼 = 값2와 같다.
SELECT FIRST_NAME AS 이름,
DEPARTMENT_ID AS 부서아이디
FROM EMPLOYEES
WHERE DEPARTMENT_ID IN (40, 70, 110);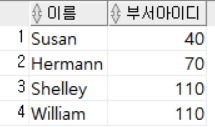
DEPARTMENT_ID가 40, 70, 110 중 하나인 직원들의 이름과 부서아이디를 출력했다.
LIKE '패턴'
SELECT 컬럼1, 컬럼2 ...
FROM 테이블명
WHERE 컬럼 LIKE '문자_'
SELECT 컬럼1, 컬럼2 ...
FROM 테이블명
WHERE 컬럼 LIKE '_문자'
SELECT 컬럼1, 컬럼2 ...
FROM 테이블명
WHERE 컬럼 LIKE '문자%'
SELECT 컬럼1, 컬럼2 ...
FROM 테이블명
WHERE 컬럼 LIKE '%문자%'LIKE 뒤의 _, %는 SQL의 패턴문자다. 패턴문자의 의미는 다음과 같다.
-
_는 임의의 문자 하나를 의미한다.- 예를 들어,
NAME LIKE '박_'는 NAME 컬럼에서 성이 '박'이고 이름이 한 글자인 사람을 조회한다.
- 예를 들어,
-
%는 0개 이상의 임의의 문자열을 의미한다-
예를 들어,
NAME LIKE '박%'은 NAME 컬럼에서 성이 '박'인 사람을 조회한다. 문자박뒤로 어느 문자열이 와도 상관이 없다. -
TITLE LIKE '%자바%'는 TITLE 컬럼에서자바가 포함되어 있는 책을 조회한다.
-
SELECT EMPLOYEE_ID AS 직원아이디
FIRST_NAME AS 이름
FROM EMPLOYEES
WHERE FIRST_NAME LIKE 'A%';
FIRST_NAME이 'A'로 시작하는 직원들의 직원아이디와 이름을 출력했다.
INSERT문
- 테이블에 새로운 행을 추가한다.
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3)
VALUES (값1, 값2, 값3);-- SAMPLE_USERS 테이블에 새로운 행을 추가한다.
INSERT INTO SAMPLE_USERS (USER_ID, USER_PASSWORD, USER_EMAIL, USER_NAME)
VALUES ('hong', 'zxcv1234', 'hong@gmail.com', '홍길동'); SMAPLE_USERS에 정의된 컬럼에 데이터를 입력하지 않으면 자동으로 NULL이 입력된다. 그러나 NULL을 허용하지 않는 컬럼이라면 오류가 발생한다.
SMAPLE_USERS에 정의된 컬럼에 데이터를 입력하지 않으면 자동으로 NULL이 입력된다. 그러나 NULL을 허용하지 않는 컬럼이라면 오류가 발생한다.
UPDATE문
- 테이블에 존재하는 행의 데이터를 변경한다.
- WHERE절에 조건식이 없으면 모든 행에서 해당 컬럼의 값을 변경한다.
- WHERE 조건식이 있으면 조건식을 만족하는 행에서만 해당 컬럼의 값을 변경한다.
UPDATE 테이블
SET
컬럼1 = 값1,
컬럼2 = 값2,
컬럼3 = 값3
WHERE 조건식-- SAMPLE_USERS 테이블에서 USER_TEL이 존재하는 행의 USER_POINT를 10000으로 변경한다.
UPDATE SAMPLE_USERS
SET
USER_POINT = 10000
WHERE
USER_TEL IS NOT NULL;

DELETE문
- 테이블에 저장된 행을 삭제한다.
- WHERE절에 조건식이 없으면 테이블의 모든 행을 삭제한다.
- WHERE 조건식이 있으면 조건식을 만족하는 행만 삭제한다.
DELETE FROM 테이블명
WHERE 조건식-- SAMPLE_PRODUCTS 테이블에서 PRODUCT_MAKER가 '삼성'인 행을 삭제한다.
DELETE SAMPLE_PRODUCTS
WHERE PRODUCT_MAKER = '삼성';

