단일행 함수를 다루기 전에 먼저 그 상위 개념인 내장 함수부터 알아보고 가자. 내장 함수의 특징은 다음과 같다.
- SQL을 작성할 때 유용한 기능이 제공되는 함수다.
- DBMS 제품마다 차이가 있다.
- '함수'라는 의미 그대로 특정 값을 입력하면 함수의 연산 과정에 따라 다른 값이 반환된다.
- 단일행 함수와 다중행 함수(그룹 함수)로 나뉜다
단일행 함수
- 한 행씩 입력되고, 한 행씩 반환한다.
- 중첩해서 사용이 가능하다.
- 문자함수, 숫자함수, 날짜함수, 변환함수, 기타함수(nvl, case, decode)가 있다.
문자함수
- LENGTH (컬럼명 혹은 표현식) : 문자열의 길이를 반환한다.
SELECT FIRST_NAME, LENGTH (FIRST_NAME)
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60;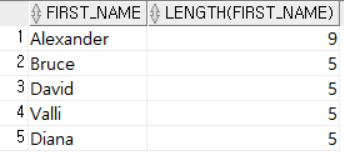 DEPARTMENT_ID가 60인 직원들의 이름의 글자 수를 출력했다.
DEPARTMENT_ID가 60인 직원들의 이름의 글자 수를 출력했다.
- LOWER (컬럼명 혹은 표현식) : 문자를 소문자로 변환한다.
- UPPER (컬럼명 혹은 표현식) : 문자를 대문자로 변환한다.
SELECT FIRST_NAME, LOWER (FIRST_NAME), UPPER (FIRST_NAME)
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60;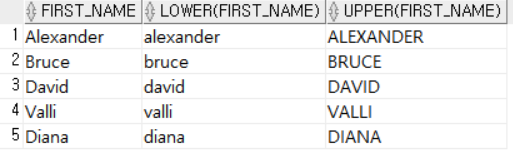 DEPARTMENT_ID가 60인 직원들의 이름을 각각 대문자 소문자로 바꾸어 출력한다.
DEPARTMENT_ID가 60인 직원들의 이름을 각각 대문자 소문자로 바꾸어 출력한다.
- SUBSTR (컬럼명 혹은 표현식, 시작위치) : 문자열에서 지정된 시작위치부터 끝까지 잘라서 반환한다.
- SUBSTR (컬럼명 혹은 표현식, 시작위치, 길이) : 문자열에서 지정된 시작위치부터 길이만큼 잘라서 반환한다.
SELECT JOB_ID, SUBSTR (JOB_ID, 4), SUBSTR (JOB_ID, 4, 2)
FROM EMPLOYEES
WHERE SALARY >= 10000;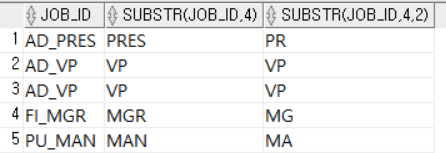 SALARY가 10000 이상인 직원들의 JOB_ID와 JOB_ID의 네 번째 글자부터 끝까지, 네 번째 글자부터 길이2만큼 잘라서 출력한다.
SALARY가 10000 이상인 직원들의 JOB_ID와 JOB_ID의 네 번째 글자부터 끝까지, 네 번째 글자부터 길이2만큼 잘라서 출력한다.
- INSTR (컬럼명 혹은 표현식, '텍스트') : 지정된 텍스트가 등장하는 위치를 반환한다.
- INSTR (컬럼명 혹은 표현식, '텍스트', 검색 시작 위치) : 지정된 텍스트가 등장하는 위치를 검색 시작 위치부터 찾아서 반환한다.
SELECT FIRST_NAME,
INSTR (FIRST_NAME, 'A'),
INSTR (FIRST_NAME, 'e', 2)
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60; DEPARTMENT_ID가 60인 직원들의 이름에서 'A'가 등장하는 위치와, 두 번째 위치에서 'e'가 등장하는 위치를 출력한다.
DEPARTMENT_ID가 60인 직원들의 이름에서 'A'가 등장하는 위치와, 두 번째 위치에서 'e'가 등장하는 위치를 출력한다.
- LPAD (컬럼명 혹은 표현식, 길이, '텍스트') : 지정된 길이보다 짧으면 왼쪽에 텍스트를 채워서 지정된 길이로 맞춘다.
- RPAD (컬럼명 혹은 표현식, 길이, '텍스트') : 지정된 길이보다 짧으면 오른쪽에 텍스트를 채워서 지정된 길이로 맞춘다.
SELECT FIRST_NAME, LPAD (FIRST_NAME, 15, '#'),
RPAD (FIRST_NAME, 15, '#')
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60;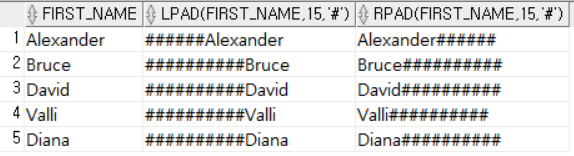
- CONCAT (컬럼명 혹은 표현식, 컬럼명 혹은 표현식) : 두 값을 합쳐서 새로운 텍스트를 반환한다.
SELECT CONCAT (FIRST_NAME, LAST_NAME)
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60;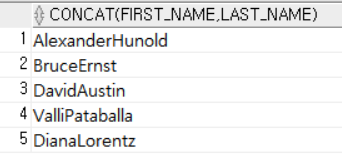 DEPARTMENT_ID가 60인 직원들의 FIRST_NAME과 LAST_NAME을 결합해서 출력한다.
DEPARTMENT_ID가 60인 직원들의 FIRST_NAME과 LAST_NAME을 결합해서 출력한다.
- 컬럼명 혹은 텍스트 || 컬럼명 혹은 텍스트 : 텍스트를 연결한다.
(JAVA에서 문자열을 잇는 +와 비슷하다.)
SELECT FIRST_NAME || ' ' || LAST_NAME
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60; 위의 CONCAT과 비슷하지만 FRIST_NAME과 LAST_NAME 뿐만 아니라'||'를 통해 공백문자도 결합해서 출력했다.
위의 CONCAT과 비슷하지만 FRIST_NAME과 LAST_NAME 뿐만 아니라'||'를 통해 공백문자도 결합해서 출력했다.
- REPLACE (컬럼명 혹은 문자열, '텍스트', '대체할 텍스트') : 텍스트에 해당하는 문자를 지정된 텍스트로 대체한다.
SELECT FIRST_NAME, REPLACE (FIRST_NAME, 'a', '*')
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60;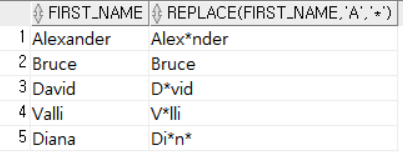
숫자 함수
숫자 함수를 설명하기 위해 DUAL테이블을 활용한다. DUAL테이블은 1행1열 테이블로 함수나 산술계산 결과를 단순히 확인하기 위해 사용한다.
- ROUND (컬럼 혹은 표현식) : 소수점 첫 번째 자리에서 반올림한다.
- ROUND (컬럼 혹은 표현식, 자리수) : 지정된 자리수까지 반올림한다. (음수도 가능)
SELECT ROUND (123.45), -- 소수점 첫 번째 자리에서 반올림한다.
ROUND (123.4567, 3), -- 소수점 세 번째자리까지 반올림한다.
ROUND (123.4567, 0), -- 1의 자리까지 반올림한다. (소수점 첫 번째 자리에서 반올림 한다.)
ROUND (123.4567, -1), -- 10의 자리까지 반올림한다.
ROUND (123.4567, -2) -- 100의 자리까지 반올림한다.
FROM DUAL;
- TRUNC (컬럼 혹은 표현식) : 소수점부분을 전부 버린다.
- TRUNC (컬럼 혹은 표현식, 자리수) : 지정된 자리수만 남기고 버린다.
SELECT TRUNC (1234.567), -- 소수점 이하를 전부 버린다.
TRUNC (1234.56, 1), -- 소수점 첫 번째자리만 남기고 버린다.
TRUNC (1234.1, 0), -- 1의 자리만 남기고 버린다.
TRUNC (1234.1, -2), -- 100의 자리만 남기고 버린다.
TRUNC (1234.1, -3) -- 1000의 자리만 남기고 버린다.
FROM DUAL;
- MOD (컬럼 혹은 표현식, 숫자) : 숫자만큼 나눈 나머지 값을 반환한다.
SELECT 5/2, MOD (5, 2)
FROM DUAL;
날짜 함수
- SYSDATE : 시스템의 현재 날짜와 시간정보가 포함된 날짜정보를 반환한다. 입력값이 없는 함수는 ()를 생략한다.
SELECT SYSDATE
FROM DUAL;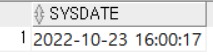
- MONTHS_BETWEEN (날짜, 날짜) : 두 날짜 사이의 개월 수를 반환한다.
SELECT FIRST_NAME,
HIRE_DATE,
MONTHS_BETWEEN (SYSDATE, HIRE_DATE),
TRUNC (MONTHS_BETWEEN (SYSDATE, HIRE_DATE))
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60;
DEPARTMENT_ID가 60인 직원의 이름과 고용일, 고용일과 현재 날짜 사이의 개월 수 차이를 출력했다. MONTHS_BETWEEN함수는 소수점 까지 표현하므로 TRUNC함수를 중첩해서 소수점을 버린 컬럼도 출력했다.
- ADD_MONTHS (날짜, 개월 수) : 지정된 날짜에서 개월 수 만큼 경과한 날짜를 반환한다.
SELECT SYSDATE,
ADD_MONTHS (SYSDATE, 1),
ADD_MONTHS (SYSDATE, 2),
ADD_MONTHS (SYSDATE, -3)
FROM DUAL;
- ROUND (날짜) : 정오를 기준으로 날짜를 반올림한다. 즉, 정오가 넘어가면 날짜가 하루 증가된 값을 반환한다. (시, 분, 초 값은 전부 0이다.)
- TRUNC (날짜) : 날짜에서 시분초값을 전부 버린다.
SELECT SYSDATE,
ROUND (SYSDATE),
TRUNC (SYSDATE)
FROM DUAL;
- 날짜 + 숫자 : 지정된 날짜에서 숫자만큼 경과된 날짜를 반환한다.
- 날짜 - 숫자 : 지정된 날짜에서 숫자만큼 이전의 날짜를 반환한다.
위 함수에서 정수 1을 하루로 간주한다. 예를 들어, SYSDATE - 1이면 현재 시스템 날짜에서 하루 전의 날짜, 시간을 반환한다. 또는 SYSDATE + 6/24이면 현재 시스템 날짜에서 6시간이 지난 날짜, 시간을 반환한다.
SELECT SYSDATE + 3,
SYSDATE - 3,
SYSDATE + 3/24,
SYSDATE - 3/24
FROM DUAL;
형변환 함수
- TO_CHAR (날짜, '포맷문자') : 날짜를 지정된 포맷의 문자열로 변환한다.
날짜의 포맷문자는 다음과 같다.
| 형식 | 설명 |
|---|---|
| CC | 세기 |
| YYYY,RRRR | 4자리 연도 |
| YY,RR | 2자리 연도 |
| MM | 2자리 월 |
| MON | 언어별 월 이름 약자(August -> Aug) |
| MONHT | 언어별 월 이름 전체 |
| DD | 2자리 일 |
| DDD | 1년 중 며칠 (1~366) |
| DY | 언어별 요일 이름 약자(수요일 -> 수) |
| DAY | 언어별 요일 이름 전체 |
| W | 1년 중 몇 번째 주(1~53) |
SELECT EMPLOYEE_ID,
FIRST_NAME,
TO_CHAR(SYSDATE, 'MM')
HIRE_DATE
FROM EMPLOYEES
WHERE TO_CHAR (HIRE_DATE, 'MM') = TO_CHAR (SYSDATE, 'MM'); 연도와 상관없이 이번 달 입사자를 출력한다.
연도와 상관없이 이번 달 입사자를 출력한다.
시간의 포맷문자는 다음과 같다.
| 형식 | 설명 |
|---|---|
| HH24 | 24시간으로 표현한 시간 |
| HH, HH12 | 12시간으로 표현한 시간 |
| MI | 분 |
| SS | 초 |
| AM, PM, A.M, P.M | 오전, 오후 |
SELECT TO_CHAR (SYSDATE, 'HH:MI:SS AM'),
TO_CHAR (SYSDATE, 'HH24:MI:SS A.M.')
FROM DUAL;
- TO_CHAR(숫자, '포맷문자') : 숫자를 지정된 포맷의 텍스트로 변환한다.
숫자의 포맷문자는 다음과 같다.
| 형식 | 설명 |
|---|---|
| 9 | 숫자의 한 자리를 의미(빈 자리 채우지 않음) |
| 0 | 숫자의 한 자리를 의미(빈 자리를 0으로 채움) |
| $ | 달러 표시를 붙여서 출력 |
| L | (Local) 지역 화폐 단위 기호를 붙여서 출력 |
| . | 소수점 표시 |
| , | 천 단위 구분기호를 표시 |
SELECT FIRST_NAME, TO_CHAR(SALARY, '$99,999.99')
FROM EMPLOYEES
WHERE SALARY >= 15000;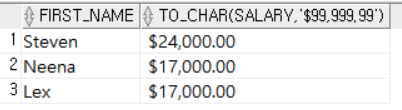 SALARY가 15000이상인 직원들의 이름과 SALARY를 달러 기호를 붙이고 천 단위 구분기호를 붙여 소수점 두 번째 자리까지 출력했다.
SALARY가 15000이상인 직원들의 이름과 SALARY를 달러 기호를 붙이고 천 단위 구분기호를 붙여 소수점 두 번째 자리까지 출력했다.
- TO_NUMBER ('텍스트', '포맷문자') : 지정된 포맷문자와 일치하는 텍스트를 숫자로 변환한다
SELECT TO_NUMBER('1,234', '9,999') + TO_NUMBER('1,234', '9,999')
FROM DUAL;
- TO_DATE('텍스트', '포맷문자') : 지정된 포맷문자와 일치하는 텍스트를 날짜로 변환
SELECT TO_DATE ('2001/01/01', 'YYYY/MM/DD')
FROM DUAL;
기타함수(NVL, DECODE)
- NVL (컬럼 혹은 표현식, 대체할 값) : 지정된 컬럼 혹은 표현식의 값이 NULL이면 대체할 값을 반환한다. 원래 값과 대체할 값의 타입이 같은 타입이어야 한다.
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY, COMMISSION_PCT,
NVL(COMMISSION_PCT, 0),
SALARY + SALARY*NVL(COMMISSION_PCT, 0) REAL_SALARY
FROM EMPLOYEES
WHERE SALARY >= 10000; SALARY가 10000이상인 직원들의 EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT 그리고 SALARY에 COMMISSION_PCT를 반영한 컬럼을 출력했다. `NVL`함수를 사용한 컬럼의 COMMISSION_PCT는 값이 NULL이면 0으로 표현된다.
SALARY가 10000이상인 직원들의 EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT 그리고 SALARY에 COMMISSION_PCT를 반영한 컬럼을 출력했다. `NVL`함수를 사용한 컬럼의 COMMISSION_PCT는 값이 NULL이면 0으로 표현된다.
- NVL2 (컬럼 혹은 표현식, NULL이 아닐 때 대체할 값, NULL일 때 대체할 값) : 지정된 컬럼이 NULL이거나 NULL이 아닐 때 대체할 값을 각각 반환한다. 대체할 값은 데이터타입이 동일한 타입이어야 한다.
SELECT EMPLOYEE_ID, FIRST_NAME, NVL2 (COMMISSION_PCT, '커미션 받음', '커미션 받지 않음')
FROM EMPLOYEES
WHERE SALARY >= 10000;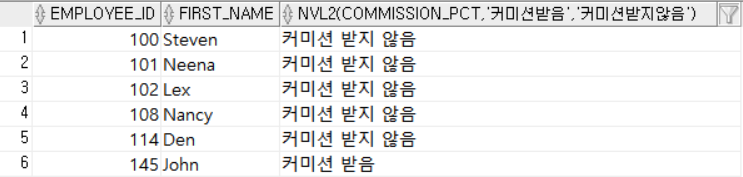 SALARY가 10000이상인 직원들의 EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT의 여부를 출력했다.
SALARY가 10000이상인 직원들의 EMPLOYEE_ID, FIRST_NAME, COMMISSION_PCT의 여부를 출력했다.
- DECODE 함수 : 특정 컬럼이나 표현식의 값에 따라 다른 값을 반환한다.
SELECT 컬럼1, 컬럼2
DECODE (컬럼 혹은 표현식, 값1, 표현식1, -- 컬럼 혹은 표현식의 값이 값1과 일치하면 표현식1이 최종 결과가 된다.
값2, 표현식2, -- 컬럼 혹은 표현식의 값이 값1과 일치하면 표현식1이 최종 결과가 된다.
값3, 표현식3, -- 컬럼 혹은 표현식의 값이 값1과 일치하면 표현식1이 최종 결과가 된다.
표현식4) -- 컬럼 혹은 표현식의 값이 값1,2,3, 모두와 일치하지 않으면 표현식4가 최종결과가 된다.
컬럼3 ...
FROM 테이블명;SELECT FIRST_NAME, DEPARTMENT_ID,
DECODE (DEPARTMENT_ID, 10, 'A팀',
20, 'A팀',
30, 'A팀',
40, 'A팀',
50, 'B팀',
60, 'B팀',
70, 'B팀',
80, 'C팀',
'D팀') AS TEAM
FROM EMPLOYEES;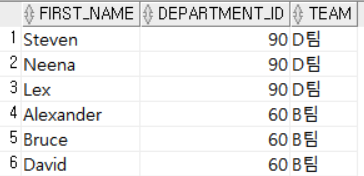 DEPARTMENT_ID를 A(10, 20, 30), B(40, 50, 60, 70),C(80)로 묶고 나머지는 D팀으로 지정하여 TEAM이라는 컬럼으로 출력했다.
DEPARTMENT_ID를 A(10, 20, 30), B(40, 50, 60, 70),C(80)로 묶고 나머지는 D팀으로 지정하여 TEAM이라는 컬럼으로 출력했다.
CASE문
CASE문은 DECODE함수와 마찬가지로 특정 조건에 따라 반환할 데이터를 지정할 때 사용한다. 하지만 CASE문은 일반적인 프로그래밍 언어의 if-else if문 처럼 DECODE보다 유연하게 사용할 수 있다.
SELECT 컬럼1, 컬럼2 ...
CASE
WHEN 조건식 THEN 표현식
WHEN 조건식 THEN 표현식
WHEN 조건식 THEN 표현식
ELSE 표현식
END
FROM 테이블명SELECT FIRST_NAME, SALARY,
CASE
WHEN SALARY >= 10000 THEN SALARY*0.1
WHEN SALARY >= 5000 THEN SALARY*0.2
ELSE SALARY*0.3
END AS BONUS
FROM EMPLOYEES; 직원들의 SALARY를 10000이상, 5000이상, 그 외로 나누고 각 범위에 따라 일정 비율을 곱한 값을 반환하고 BONUS라는 컬럼으로 표현했다.
직원들의 SALARY를 10000이상, 5000이상, 그 외로 나누고 각 범위에 따라 일정 비율을 곱한 값을 반환하고 BONUS라는 컬럼으로 표현했다.
차선이 모여 최선이 된다.