다중행 함수(그룹 함수)
-
여러 행이 입력되고, 한 행씩 반환한다.
-
중첩은 한 번만 허용된다.
-
WHERE절에서 사용할 수 없다.
-
그룹 함수가 아니거나 그룹 함수가 포함되어 있지 않은 표현식은 SELECT절에 사용할 수 없다.
- 그룹 함수의 결과는 1행 혹은 그룹당 1행인데, 그룹 함수와 관련이 없는 컬럼은 그룹 함수의 결과와 행 개수가 일치하지 않기 때문이다.
COUNT 함수
- COUNT (*) : 조회된 행의 개수를 반환
SELECT COUNT (*)
FROM EMPLOYEES
WHERE DEPARTMENT_ID =80;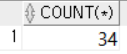 DEPARTMENT_ID가 80인 직원들의 행의 개수를 반환한다. 즉, 부서아이디가 80인 직원들의 수를 조회한다.
DEPARTMENT_ID가 80인 직원들의 행의 개수를 반환한다. 즉, 부서아이디가 80인 직원들의 수를 조회한다.
- COUNT (컬럼 혹은 표현식) : 컬럼 혹은 표현식이 NULL이 아닌 행의 개수만 반환
SELECT COUNT (COMMISSION_PCT)
FROM EMPLOYEES;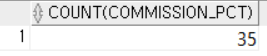 COMMISSION_PCT가 NULL이 아닌 행의 개수를 반환한다. 즉, 커미션을 받는 직원 수를 조회한다
COMMISSION_PCT가 NULL이 아닌 행의 개수를 반환한다. 즉, 커미션을 받는 직원 수를 조회한다
SUM, AVG, MIN, MAX 함수
- MIN (컬럼 혹은 표현식) : 컬럼 혹은 표현식의 최소값를 반환한다.
- MAX (컬럼 혹은 표현식) : 컬럼 혹은 표현식의 최대값를 반환한다.
- SUM (컬럼 혹은 표현식) : 컬럼 혹은 표현식의 합계를 반환한다.
- AVG (컬럼 혹은 표현식) : 컬럼 혹은 표현식의 평균를 반환한다.
위 함수 모두 NULL값은 제외된다.
SELECT MIN(SALARY) AS SALARY_MIN,
MAX(SALARY) AS SALARY_MAX,
SUM(SALARY) AS SALARY_SUM,
TRUNC(AVG(SALARY)) AS SALARY_AVG
FROM EMPLOYEES; 직원 전체의 최소,최대,평균급여와 급여합계를 조회한다.
직원 전체의 최소,최대,평균급여와 급여합계를 조회한다.
GROUP BY절
그 동안 다룬 그룹 함수는 지정된 테이블의 여러 행을 입력받아 하나의 결과만 반환했다. GROUP BY절을 사용하면 특정 컬럼을 기준으로 그룹화하여 행을 입력받고 그룹당 한 행씩 결과를 반환받을 수 있다. 그리고 GROUP BY절에 컬럼을 여러 개 입력하면 지정된 순서대로 그룹화 한다.
위에서 언급했다시피 그룹 함수가 아니거나 그룹 함수가 포함되어 있지 않은 표현식은 SELECT절에 사용할 수 없다. 그러나 GROUP BY절에 등장한 컬럼 혹은 표현식은 SELECT절에 그룹 함수와 함께 적을 수 있다. 그룹 함수 결과의 개수가 그룹화한 행의 개수와 일치하기 때문이다.
또한, ORDER BY절에서는 컬럼의 별칭을 사용할 수 없다. ORDER BY절이 별칭이 지정되는 SELECT절보다 나중에 실행되기 때문이다.
SELECT DEPARTMENT_ID,
TO_CHAR(HIRE_DATE, 'YYYY') AS HIRE_YEAR,
COUNT(*) AS CNT
FROM EMPLOYEES
WHERE DEPARTMENT_ID IS NOT NULL
GROUP BY DEPARTMENT_ID, TO_CHAR(HIRE_DATE, 'YYYY');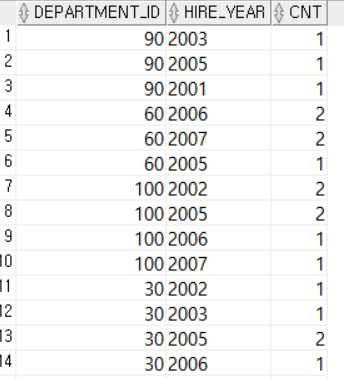 DEPARTMENT_ID로 그룹화한 후, 입사년도별로 직원수를 조회한다.
DEPARTMENT_ID로 그룹화한 후, 입사년도별로 직원수를 조회한다.
SELECT DEPARTMENT_ID,
MIN(SALARY) AS SALARY_MIN,
MAX(SALARY) AS SALARY_MAX,
SUM(SALARY) AS SALARY_SUM,
TRUNC(AVG(SALARY)) AS SALARY_AVG
FROM EMPLOYEES
WHERE DEPARTMENT_ID IS NOT NULL
GROUP BY DEPARTMENT_ID;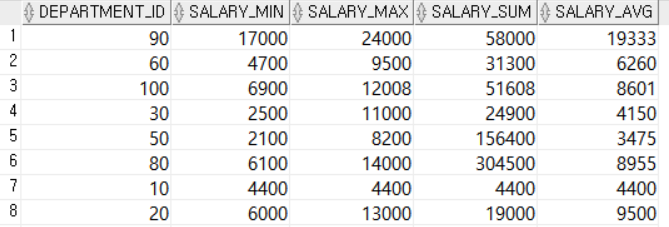 DEPARTMENT_ID별로 그룹화한 후, 그룹별 최소,최대,평균급여와 급여합계를 조회한다.
DEPARTMENT_ID별로 그룹화한 후, 그룹별 최소,최대,평균급여와 급여합계를 조회한다.
HAVING절
HAVING절은 GROUP BY절을 통해 그룹화한 결과값의 범위를 필터링하는데 사용한다. 그래서 HAVING절은 GROUP BY절이 존재할 때만 사용할 수 있다.
HAVING절과 WHERE절은 조회할 값을 특정 기준으로 필터링한다는 점에서 유사하지만 분명히 차이가 있다. 보다 정확히 이해하기 위해 각 절의 실행순서를 살펴본다.
- FROM : 조회할 테이블 확인
- ON : 조인 조건 확인
- JOIN : 테이블 조인 (병합)
4. WHERE : 행 추출 조건 확인
5. GROUP BY : 특정 컬럼을 기준으로 행을 그룹화
6. HAVING : 그룹화 이후 행 추출 조건 확인
- SELECT : 조회할 컬럼 지정
- DISTINCT : 중복 제거
- ORDER BY : 행 정렬**
중요한 부분은 4,5,6이다. WHERE절에서 먼저 실행되고, 그 후에 GROUP BY절과 HAVING절이 실행된다. 즉, WHERE절에서 지정된 조건으로 먼저 데이터를 필터링한 후, 해당 데이터를 갖고 GROUP BY절에서 지정된 컬럼을 기준으로 그룹화한다. 마지막으로 그룹화된 데이터를 HAVING절에서 지정된 조건으로 필터링한다.
다시 말해, WHERE절은 그룹화할 대상을 필터링한다. 따라서 그룹화할 대상이 감소되고 쿼리 성능이 향상된다.
SELECT TO_CHAR(HIRE_DATE, 'YYYY') AS 입사년도,
COUNT(*) AS 사원수
FROM EMPLOYEES
WHERE DEPARTMENT_ID IN (30, 50, 80)
GROUP BY TO_CHAR(HIRE_DATE, 'YYYY')
HAVING COUNT(*) >= 10
ORDER BY 입사년도;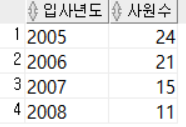 DEPARTMENT_ID가 30, 50, 80인 사원들을 먼저 조회한 후, 그 사원들을 대상으로 입사년도별로 그룹화한다. 그 중에서 입사한 사원수가 10명이상인 입사년도만 출력했다.
DEPARTMENT_ID가 30, 50, 80인 사원들을 먼저 조회한 후, 그 사원들을 대상으로 입사년도별로 그룹화한다. 그 중에서 입사한 사원수가 10명이상인 입사년도만 출력했다.
ROLLUP
GROUP BY절에 2개 이상의 컬럼 혹은 표현식이 있으면 첫 번째 식을 기준으로 그룹화를 하고, 해당 그룹안에서 두 번째 식을 기준으로 다시 그룹화한다. 이런 경우 ROLLUP은 첫 번째 그룹에 대한 부분합을 계산한다.
SELECT DEPARTMENT_ID,
JOB_ID,
COUNT(*) AS CNT,
SUM(SALARY)
FROM EMPLOYEES
GROUP BY ROLLUP (DEPARTMENT_ID, JOB_ID)
ORDER BY DEPARTMENT_ID ASC, JOB_ID ASC;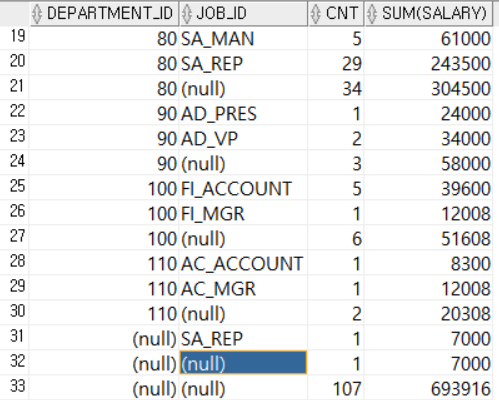 DEPARTMENT_ID를 기준으로 그룹화하고, 그 다음 JOB_ID를 기준으로 그룹화했다. NULL이 그룹화된 행의 부분합이다. 마지막 행의 NULL은 전체 데이터에 대한 합계다. 즉, 21번 행의 NULL은 DEPARTMENT_ID가 80인 그룹의 부분합을 나타내고 마지막 33번째 행의 NULL은 직원전체의 부분합을 나타낸다.
DEPARTMENT_ID를 기준으로 그룹화하고, 그 다음 JOB_ID를 기준으로 그룹화했다. NULL이 그룹화된 행의 부분합이다. 마지막 행의 NULL은 전체 데이터에 대한 합계다. 즉, 21번 행의 NULL은 DEPARTMENT_ID가 80인 그룹의 부분합을 나타내고 마지막 33번째 행의 NULL은 직원전체의 부분합을 나타낸다.