다음과 같은 Fully Connected Layers가 있다고 가정했을때, 우리는 예측값이 어떻게 나올지 수식으로 적을 수 있다.
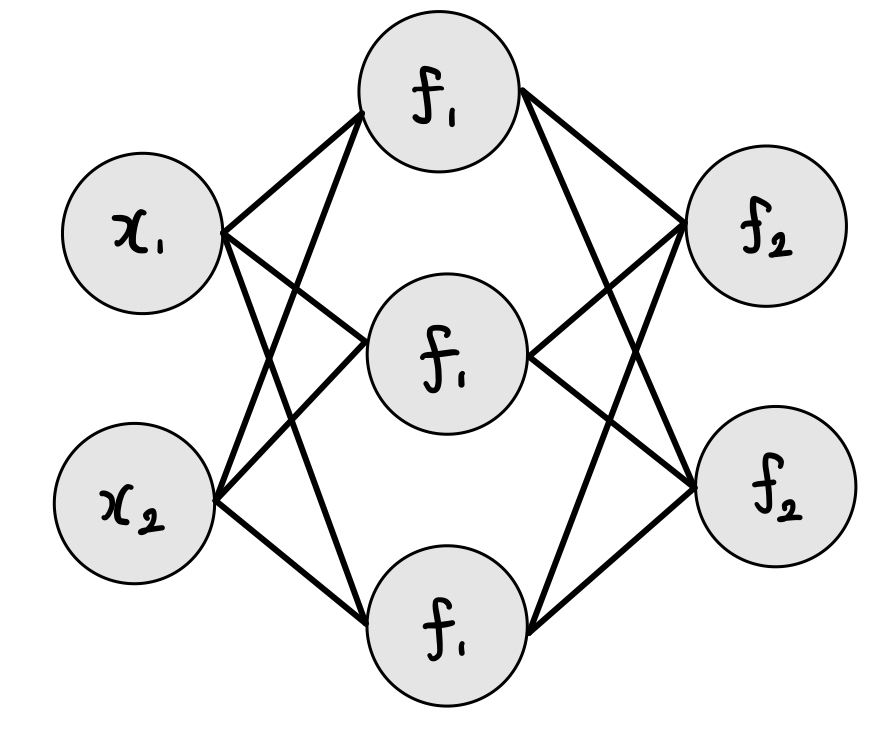
행렬과 벡터로 MLP 표현
#1
1번째 hidden layer에서 위에서 1번째 노드의 경우를 보면,
입력값: w2∗x1+w2∗x2+b1
출력값: f1(w3∗x1+w4∗x2+b2)
#2
1번째 hidden layer에서 위에서 2번째 노드의 경우를 보면,
입력값: w3×x1+w4×x2+b2
출력값: f1(w3×x1+w4×x2+b2)
#3
1번째 hidden layer에서 위에서 3번째 노드의 경우를 보면,
입력값: w5∗x1+w6∗x2+b3
출력값: f1(w5∗x1+w6∗x2+b3)
이를 행렬과 벡터로 더 보기좋게 나타낼 수 있다.
f1([x1x2]×[w1w2w3w4w5w6]+[b1b2b3])
hidden layer에서 output layer로 가는 과정도 포함시키면 수식은 다음과 같아진다.
f2(f1([x1x2]×[w1w2w3w4w5w6]+[b1b2b3])×⎣⎢⎡w7w8w9w10w11w12⎦⎥⎤+[b4b5])
Linear Activation을 사용하면 안되는 이유 설명
여기서 activation function인 f1과 f2가 Linear Activation이라고 가정해보자.
Linear Activation이 f(x)=x라 가정했을때, 입력값과 출력값은 동일하다. 즉, 수식이 간단해진다.
([x1x2]×[w1w2w3w4w5w6]+[b1b2b3])×⎣⎢⎡w7w8w9w10w11w12⎦⎥⎤+[b4b5]
전개해보면
[x1x2][w1w2w3w4w5w6]⎣⎢⎡w7w8w9w10w11w12⎦⎥⎤+[b1b2b3]⎣⎢⎡w7w8w9w10w11w12⎦⎥⎤+[b4b5]
[w1w2w3w4w5w6]⎣⎢⎡w7w8w9w10w11w12⎦⎥⎤는 [w1w2w3w4]로 대체할 수 있다.
[b1b2b3]⎣⎢⎡w7w8w9w10w11w12⎦⎥⎤+[b4b5]는 [b1b2]로 대체할 수 있다.
그러면 결과적으로
[x1x2][w1w2w3w4]+[b1b2]로 간소화된다.
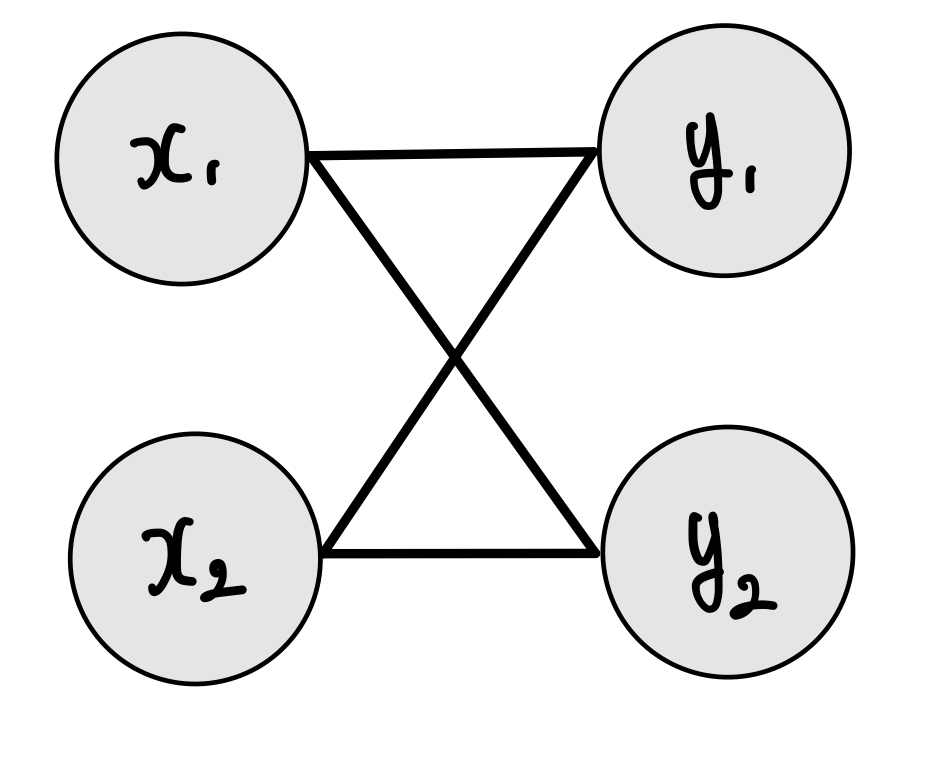
즉, hidden layer가 없는 것과 동일해진다. 그렇기에 신경망에 있어서 Linear Activation은 쓸모가 없다.
결론
Linear Activation은 쓸모가 없기 때문에 비선형성 Activation이 중요하다.

좋은 정보 얻어갑니다, 감사합니다.