현대 AI의 뼈대가 된 2017년 구글의 전설적인 논문을 뜯어봅니다.
핵심 한 줄: 단어를 줄 세워 읽던 관행을 박살내고, 모든 단어의 얽힌 관계를 동시에 계산한 혁명적 아키텍처.
1. 왜 이 논문을 읽게 되었는가
최근 업무에서 RAG(검색 증강 생성) 시스템의 검색 성능을 높이는 작업을 하고 있습니다. 또한 다양한 거대 언어 모델(LLM)을 활용해 프롬프트를 최적화하는 일도 병행하고 있습니다.
이 과정에서 항상 비슷한 벽에 부딪혔습니다.
"왜 모델은 입력 길이가 길어지면 앞부분의 지시사항을 잊어버릴까?"
"문맥(Context)을 도대체 어떤 원리로 이해하는 걸까?"
이런 고민을 해결하려면 모델이 텍스트를 처리하는 근본적인 원리를 알아야 했습니다. 그래서 현재 우리가 사용하는 거의 모든 최신 AI의 뿌리가 되는 전설적인 논문, 2017년 구글의 "Attention Is All You Need" 를 다시 펼쳤습니다.
겉보기에는 복잡한 수식이 가득한 학술 논문입니다. 하지만 그 원리를 하나씩 뜯어보니 놀랍도록 직관적이었습니다. 오늘은 제가 이 논문을 공부하며 깨달은 점들을 여러분과 함께 나누고자 합니다.
2. 이 논문이 해결하려는 문제
이 논문이 나오기 전인 2017년 이전의 상황을 먼저 알아야 합니다. 당시 자연어 처리(NLP) 분야는 순환 신경망(RNN) 이라는 기술이 지배하고 있었습니다.
기존 방법의 한계
RNN의 가장 큰 특징은 단어를 '순서대로' 읽는다는 것입니다. "나는", "오늘", "밥을", "먹었다"라는 문장이 있으면 앞에서부터 차례대로 하나씩 입력했습니다.
이 방식에는 치명적인 단점이 두 가지 있었습니다.
| 한계 | 설명 |
|---|---|
| 장기 기억 상실 (Long-term dependency) | 문장이 조금만 길어지면 앞부분의 정보를 잊어버림 |
| 느린 속도 | 단어를 하나씩 순서대로 처리해야 하므로 컴퓨터의 '동시 계산(병렬 처리)'을 활용할 수 없음 |
왜 이 문제가 중요한가
대규모 데이터를 학습하려면 처리 속도가 생명입니다. 위키백과 전체를 학습시키려면 RNN 방식으로는 몇 년이 걸릴 수도 있습니다.
실제 사례
"The animal didn't cross the street because it was too tired."여기서 it은 동물일까요, 길일까요? 사람은 문맥을 보고 '동물'이라는 것을 바로 압니다. 하지만 옛날 AI는 문장 끝에 도달할 때쯤이면 문장 맨 앞의 animal이라는 단어와의 연결고리가 희미해져서 번역을 망치곤 했습니다.
3. 핵심 아이디어 (직관적으로 설명)
저자들은 아주 과감하고 단순한 아이디어를 던집니다.
핵심 한 문장
"단어를 순서대로 읽는 방식을 완전히 버리자. 대신 모든 단어들 사이의 '관계성'을 동시에 계산하는 어텐션(Attention) 기술만으로 문장을 이해하자."
비유 1: 칵테일 파티 효과 🎉
시끄러운 파티장을 상상해 보세요. 음악 소리와 사람들의 대화 소리가 뒤섞여 있습니다. 하지만 누군가 내 이름을 부르면 그 소리만 선명하게 들립니다.
트랜스포머의 '어텐션'도 이와 같습니다. 수십 개의 단어가 쏟아져 들어와도, 지금 당장 집중해야 할 핵심 단어에만 강하게 귀를 기울입니다.
비유 2: 수사관의 단서 연결망 🔍
영화에 나오는 수사관의 칠판을 떠올려 보세요. 범행 현장 사진, 흉기, 용의자 이름이 여기저기 붙어 있습니다. 수사관은 이것들을 순서대로 읽지 않습니다. 대신 관련 있는 것들끼리 '붉은 실'로 연결합니다.
트랜스포머는 문장 안의 모든 단어를 한 번에 칠판에 펼쳐놓고, 서로 연관 깊은 단어들끼리 굵은 선으로 연결합니다.
실제 상황 예시
"배를 먹으면서 배를 탔다."이 문장을 AI가 처리합니다. 순서대로 읽지 않습니다. 모든 단어를 동시에 봅니다.
- 첫 번째 '배' → '먹으면서' 와 강한 선으로 연결 (과일)
- 두 번째 '배' → '탔다' 와 강한 선으로 연결 (선박)
이렇게 동시에 문맥을 파악하여 두 단어의 뜻이 다르다는 것을 단번에 알아냅니다.
4. 수식 쉽게 이해하기
논문에서 가장 유명하고 중요한 핵심 수식입니다.
알파벳이 복잡해 보이지만, 도서관 검색 시스템으로 비유하면 아주 쉽습니다.
| 기호 | 도서관 비유 | 실제 의미 |
|---|---|---|
| Q (Query) | 검색창에 치는 검색어 | 내가 현재 집중하는 단어 |
| K (Key) | 도서관 책들의 제목 | 문장 안의 다른 모든 단어들 |
| V (Value) | 책들의 실제 내용 | 단어들이 가진 고유한 의미 |
| 안전장치(브레이크) | 숫자가 폭발적으로 커지는 것을 방지 | |
| softmax | 비율 변환기 | 점수들을 합쳐서 100% 비율로 만들어주는 함수 |
숫자 예시로 계산 과정 시연
Q (나의 질문) = [1, 0] → '강아지'
K1 (다른 단어) = [1, 0] → '멍멍이'
K2 (다른 단어) = [0, 1] → '자동차'- 내적 계산: Q·K1 = 100점 (완전히 닮음), Q·K2 = 0점 (완전히 다름)
- softmax 적용: K1 → 73%, K2 → 27%
- 최종 결합: K1의 의미를 73%만큼, K2의 의미를 27%만큼 가져와 하나로 섞어줌
이 수식의 직관적 재해석
이 수식은 결국 "문맥 믹서기" 입니다.
현재 단어에 주변 단어들의 의미를 '닮은 정도'에 비례하여 적절히 섞어주는 역할을 합니다.
이 수식이 없다면? 문장 안의 단어들은 서로 철저히 고립됩니다. "Apple" 옆에 "Steve Jobs"가 있든 "Banana"가 있든, AI는 문맥을 전혀 파악하지 못하게 됩니다.
5. 논문 Figure 해석
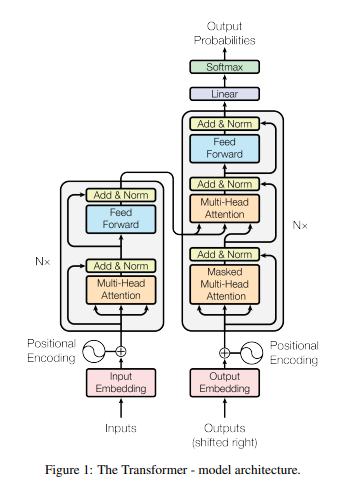
📊 Figure 1: 모델 아키텍처 (The Transformer - model architecture)
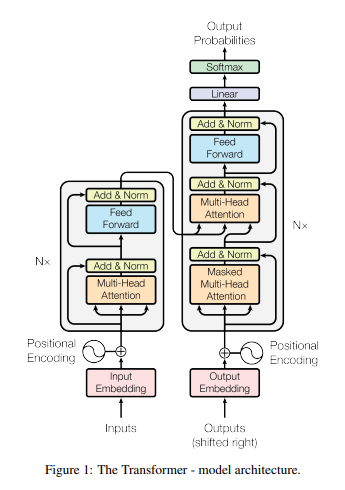
- 이 그림이 보여주는 것: 트랜스포머 모델의 전체 구조도. 왼쪽 회색 박스는 인코더(Encoder), 오른쪽 회색 박스는 디코더(Decoder)
- 실험 설정: 왼쪽·오른쪽 박스가 각각 6번씩(Nx=6) 햄버거 패티처럼 위로 겹겹이 쌓임
- 핵심 메시지: 기존에 필수로 쓰이던 RNN이나 CNN이 완전히 사라졌습니다. 오직 Multi-Head Attention 블록만 존재합니다.
내가 이해한 포인트
거대한 공장 컨베이어 벨트 같습니다. 왼쪽 인코더 공장에서는 외국어 문장을 씹고 뜯어 완벽한 '의미 덩어리'로 압축합니다. 오른쪽 디코더 공장은 이 덩어리 도면을 보고 번역된 한국어 단어를 하나씩 조립해냅니다.
- 이 그림이 중요한 이유: 단순한 구조(Attention + Feed Forward)만으로 언어 번역이 가능하다는 것을 시각적으로 증명합니다.
- 한계점: 블록이 하나만 그려져 있어 초보자는 층이 여러 개 쌓여있다는 사실(Nx)을 간과하기 쉽습니다.
📊 Figure 2 (왼쪽): 스케일드 닷-프로덕트 어텐션 (Scaled Dot-Product Attention)
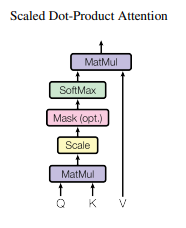
- 이 그림이 보여주는 것: Q, K, V 수식이 컴퓨터 내부에서 계산되는 순서도
- 연산 순서:
MatMul → Scale → Mask(옵션) → Softmax → MatMul - 핵심 메시지: 단어 간의 관계 파악이라는 복잡한 작업을 단순한 '행렬 곱셈' 으로 치환했습니다.
내가 이해한 포인트
행렬 곱셈은 GPU가 세상에서 가장 잘하는 일입니다. 트랜스포머가 기존 모델보다 압도적으로 빠르게 학습할 수 있는 비밀이 바로 이 단순한 행렬 곱셈 구조에 있었습니다.
- 한계점: 중간의
Mask(옵션)기능이 헷갈릴 수 있습니다. 이는 디코더에서 '미래의 단어를 미리 컨닝하지 못하게' 가려버리는 역할입니다.
📊 Figure 3 (오른쪽): 멀티 헤드 어텐션 (Multi-Head Attention)
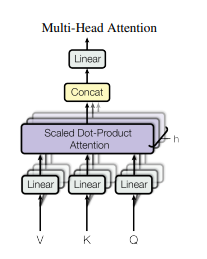
- 이 그림이 보여주는 것: 어텐션 연산을 한 번만 크게 하는 것이 아니라, 여러 개(논문에서는 8개)로 잘게 쪼개어 동시에 수행하는 구조
- 연산 순서:
Linear(8개로 분할) → 각 Head별 Attention → Concat → Linear - 핵심 메시지: 문장을 하나의 시야로만 보면 중요한 정보를 놓칠 수 있습니다. 다각도로 분석해야 합니다.
내가 이해한 포인트
8명의 전문가가 모인 조별 과제와 같습니다.
1번 전문가는 '문법'만, 2번은 '감정'만, 3번은 '인물 관계'만 분석합니다.
마지막에 각자의 보고서를 하나로 합치면 문장에 대한 완벽한 이해가 완성됩니다.
- 이 그림이 중요한 이유: 모델이 문맥을 풍부하게 포착하여 번역 성능을 끌어올릴 수 있었던 이유를 설명합니다.
- 한계점: AI가 스스로 8개의 머리마다 각기 다른 역할을 부여하도록 학습되지만, 구체적으로 어떤 머리가 어떤 역할을 하는지 사람이 완벽히 통제하기는 어렵습니다. (블랙박스 문제)
6. 실험 결과 분석
무엇을 증명했는가
저자들은 영어-독일어 번역과 영어-프랑스어 번역 대회(WMT 2014) 데이터를 사용하여, 기존의 모든 AI 모델을 꺾고 최고 성능(SOTA) 을 달성했습니다.
결과가 설득력 있는 이유
번역 품질 지표인 BLEU 점수에서 압도적인 1등을 차지했습니다. 더욱 놀라운 것은 기존 최고 모델들의 연산량 중 아주 적은 일부만 사용하고도 이 결과를 냈다는 점입니다.
성능은 올리고 비용은 깎아버린 완벽한 증명이었습니다.
통계적 신뢰성
학계 표준 데이터셋을 사용하고, Base 모델과 Big 모델 두 가지 버전을 모두 실험하여 일관된 성능 향상을 보여주었으므로 신뢰성이 매우 높습니다.
다른 해석 가능성
"단순히 파라미터(모델 크기)가 커져서 똑똑해진 것 아니야?"
이에 대해 저자들은 모델 크기가 작은 Base 버전으로도 과거의 무거운 모델들을 이겼습니다. 구조 자체가 우월하다는 것을 입증한 것입니다.
7. 비판적 관점
✅ 강점
- 압도적인 학습 속도 — 병렬 처리의 극대화
- 문장이 아무리 길어도 첫 단어와 끝 단어의 관계를 잃지 않음
- 모델 크기를 키우고 데이터를 많이 넣을수록 성능이 계속 우상향 (확장성)
- 어텐션 점수를 시각화하여 AI가 어디를 보는지 해석 가능
- 언어뿐만 아니라 이미지, 소리 등 모든 순차적 데이터에 적용 가능한 범용성
❌ 한계
- 메모리 문제: 문장이 길어지면 계산량이 길이의 제곱으로 폭발
- 기본적인 데이터 규칙을 몰라서 무식하게 많은 데이터를 먹여야만 똑똑해짐
- 위치 인코딩을 함수로 억지로 넣다 보니 아주 긴 문장에서는 길을 잃음
- 번역 결과를 내뱉을 때는 여전히 한 단어씩 순서대로 뱉어야 해서 추론이 느림
- 문맥 전체를 훑느라 바로 옆 단어와의 끈끈한 결속력을 가끔 무시함
실제 적용 시 문제
실제 RAG 시스템을 구축할 때 직면하는 가장 큰 문제가 바로 한계 1번( 문제) 입니다. 모델에 참고할 문서를 많이 넣어주면(Context Length 증가), 연산량이 제곱으로 폭발해 API 비용이 치솟고 응답이 심각하게 느려집니다. 온디바이스 AI처럼 메모리가 적은 기기에는 이 무거운 트랜스포머를 그대로 올리기가 불가능에 가깝습니다.
개선 가능성
최근에는 이 메모리 문제를 해결하기 위해 중요하지 않은 단어는 계산에서 빼버리는 Sparse Attention이나, 하드웨어 연산을 최적화한 FlashAttention 기술들이 나오며 한계를 극복해 나가고 있습니다.
8. 내가 얻은 인사이트
새롭게 알게 된 점
AI가 글을 이해하는 방식이 마법이 아니라는 것을 알았습니다. 철저하게 단어와 단어 사이의 유사도를 행렬 곱셈으로 구하고, 그 점수만큼 의미를 더하는 수학적 과정이었습니다.
기존 생각이 바뀐 부분
글은 항상 왼쪽에서 오른쪽으로, 순서대로 읽어야 한다고 생각했습니다.
하지만 트랜스포머는 텍스트를 순서가 있는 선(Line) 이 아니라, 모든 단어가 서로 연결된 촘촘한 그물망(Graph) 으로 바라봤습니다.
관점의 전환이 얼마나 파괴적인 혁신을 가져오는지 깨달았습니다.
9. 한눈에 정리
| 항목 | 내용 |
|---|---|
| 문제 | 기존 RNN은 단어를 순서대로 처리하느라 너무 느리고 긴 문장을 잘 까먹었다 |
| 해결 방법 | 순서대로 읽는 방식을 버리고, 모든 단어의 관계를 한 번에 계산하는 'Self-Attention' 도입 |
| 가장 중요한 기여 | 현대 LLM(ChatGPT, Gemini 등)의 뼈대가 되는 트랜스포머(Transformer) 아키텍처 최초 제안 |
| 가장 인상 깊었던 부분 | 복잡한 언어의 문맥 파악을 단순한 행렬 곱셈()으로 우아하게 풀어낸 발상의 전환 |
| 아쉬운 점 | 입력 길이가 길어지면 메모리 사용량이 제곱으로 폭발 — 현재 LLM 컨텍스트 윈도우 한계의 원흉 |
🧠 이 논문을 한 문장으로 말하면?
트랜스포머는 단어를 줄 세워 읽던 관행을 박살내고, 모든 단어의 얽힌 관계를 동시에 계산하여 AI의 폭발적 진화를 이끈 혁명적인 아키텍처다.
