[논문 리뷰] SimulSpeech: End-to-End Simultaneous Speech to Text Translation
SimulSpeech: End-to-End Simultaneous Speech to Text Translation(https://aclanthology.org/2020.acl-main.350.pdf)
중간 단계를 없애고 음성에서 번역문을 직접 — 더 빠르고 더 정확한 동시 음성 번역
음성 인식 → 번역이라는 두 단계를 하나로 합치고,
CTC 분절기 + Wait-k + 두 가지 지식 증류로 오류 누적을 없앤 종단간 동시 음성 번역 시스템.
ACL 2020 | Yi Ren, Jinglin Liu, Xu Tan* et al. (Zhejiang University / Microsoft Research)
목차
- 서론
- Background
- Problem Definition
- Proposed Method / Approach
- Experiments & Results
- Discussion
- My Insights
- Summary
1. 서론
이 논문은 동시 통역 시스템의 오래된 구조적 문제를 정면으로 파고듭니다.
"왜 두 개의 모델을 이어 붙여야만 할까?"
기존의 동시 음성 번역 시스템은 두 단계로 작동합니다. 먼저 실시간 음성 인식기(ASR)가 소리를 텍스트로 바꿉니다. 그다음 실시간 번역기(NMT)가 그 텍스트를 다른 언어로 바꿉니다. 이 방식에는 치명적인 단점이 있습니다. 앞 단계에서 생긴 오류가 그대로 다음 단계로 전달됩니다. 두 모델을 거치므로 지연도 두 배로 쌓입니다.
이 논문은 음성을 텍스트로 바꾸는 중간 단계를 완전히 없애고, 소리에서 번역문을 직접 만들어내는 단일 모델 SimulSpeech를 제안합니다. 그리고 이 어려운 목표를 달성하기 위해 두 가지 지식 증류 기법을 새롭게 설계했습니다.
2. Background
논문의 핵심으로 들어가기 전에, 동시 번역의 기술적 맥락을 살펴봅니다.
동시 번역의 핵심 딜레마
동시 번역에서 속도와 정확도는 시소 관계입니다.
| 전략 | 번역 시작 시점 | 정확도 | 지연 |
|---|---|---|---|
| 빠르게 시작 | 단어 1~2개 후 | 문맥 부족 → 오역 위험 | 짧음 |
| 느리게 시작 | 문장 전체 후 | 높음 | 길어 사용자 불만 |
| Wait-k (균형점) | k개 단어 후 | k에 따라 조절 | k에 따라 조절 |
CTC: 분절의 핵심 도구
SimulSpeech의 분절기는 CTC(Connectionist Temporal Classification) 손실을 기반으로 작동합니다. 음성 프레임 수준의 출력을 텍스트 시퀀스로 매핑합니다. 여러 CTC 경로가 같은 텍스트 시퀀스에 대응하는 다대일 구조입니다.
예시로, "HELLO"에 해당하는 CTC 경로는 "HHE∅L∅LOO"와 "∅HHEEL∅LO" 등 여러 가지가 될 수 있습니다. 이 유연성 덕분에 프레임 수준의 정확한 레이블 없이도 단어 경계를 학습할 수 있습니다.
Wait-k 전략
번째 번역 단어를 생성할 때 소스 세그먼트 번째까지만 볼 수 있습니다. 가 클수록 더 많은 문맥을 보므로 정확도는 올라가지만 지연이 길어집니다.
3. Problem Definition
이 논문이 꼬집는 핵심 문제는 "2단계 캐스케이드 방식의 오류 누적과 이중 지연" 입니다.
캐스케이드 방식의 두 가지 구조적 문제
| 문제 | 설명 | 실제 예시 |
|---|---|---|
| 오류 누적 | ASR이 틀린 단어를 NMT에 전달 | "classic"을 "class sake"로 인식 → "clase sake"로 번역 |
| 이중 지연 | ASR의 wait-k + NMT의 wait-k가 합산 | ASR wait-1 + NMT wait-3 = 사실상 wait-4 수준의 지연 |
논문의 핵심 사례 (Figure 5)
논문이 직접 제시한 실제 번역 예시입니다.
| 시스템 | 출력 |
|---|---|
| 원문 | "the first on here is the classic apple." |
| ASR (wait-1) 오인식 | "the first on here is the class sake apple." |
| 캐스케이드 번역 결과 | "pero la primera vez es una manzana motivo de clase." ❌ |
| SimulSpeech (wait-3) 결과 | "la primera es una manzana clásica." ✅ |
"classic" 한 단어의 오인식이 전체 번역 품질을 망쳤습니다. SimulSpeech는 중간 텍스트를 거치지 않으므로 이 문제가 발생하지 않습니다.
4. Proposed Method / Approach
SimulSpeech는 음성 인코더 + 음성 분절기 + 텍스트 디코더 세 모듈로 구성됩니다.
전체 작동 흐름
- Pre-Net (특징 추출): 오디오 파형을 멜 스펙트로그램으로 변환합니다. 3층 합성곱 네트워크가 음향 특징을 추출합니다.
- 인코더 (마스크 자기 어텐션): 미래 프레임을 보지 못하게 마스킹한 트랜스포머 인코더가 은닉 상태를 생성합니다.
- 음성 분절기 (CTC): 인코더 출력을 받아 단어 경계를 감지합니다. 공백 문자가 예측되는 순간이 단어 하나의 끝입니다.
- 디코더 (Wait-k 어텐션): 분절기가 k개의 단어 경계를 감지하면 번역 단어를 하나씩 출력하기 시작합니다.
Wait-k 작동 예시: 일 때
| 시간 | 분절기 감지 | 디코더 행동 |
|---|---|---|
| "I" 입력 | 1번째 단어 경계 | 대기 |
| "am" 입력 | 2번째 단어 경계 | "나는" 출력 |
| "a" 입력 | 3번째 단어 경계 | 다음 번역 단어 출력 |
| ... | ... | 이후 매 세그먼트마다 즉시 출력 |
핵심 혁신: 두 가지 지식 증류
End-to-End 동시 번역은 음성 인식보다 훨씬 어렵습니다. 음성-번역문 사이의 정렬을 처음부터 학습해야 하기 때문입니다. 저자들은 이미 학습된 두 전문가 모델의 지식을 SimulSpeech에 주입하는 방식으로 이 문제를 해결했습니다.
1) 어텐션 수준 지식 증류 (Attention-Level KD)
직관: 두 전문가의 지식을 곱해서 모범 답안 만들기
- 전문가 A (ASR): 음성 ↔ 원문 텍스트의 정렬을 압니다 ()
- 전문가 B (NMT): 원문 텍스트 ↔ 번역 텍스트의 정렬을 압니다 ()
- 두 행렬을 곱하면 음성 ↔ 번역 텍스트의 이상적 정렬이 나옵니다
이 이상적 행렬을 0.05 임계값으로 이진화(Binarization)한 뒤, SimulSpeech의 어텐션이 이를 모방하도록 학습시킵니다.
비유: 두 전문가의 답안지를 합치기
음성 전문가는 "음성의 2~3초 구간이 'apple'이다"라고 알고, 번역 전문가는 "'apple'이 'manzana'에 해당한다"라고 압니다. 두 답안을 곱하면 "음성의 2~3초 구간이 'manzana'에 해당한다"는 완벽한 모범 답안이 됩니다.
2) 데이터 수준 지식 증류 (Data-Level KD)
전체 문장을 다 보고 번역하는 오프라인 NMT 교사 모델이 만들어낸 번역문으로 학습 데이터를 교체합니다.
실제 사람이 작성한 번역문보다 교사 NMT가 생성한 번역문이 SimulSpeech가 학습하기에 더 단순하고 일관된 분포를 가집니다. 학습 최적화가 쉬워집니다.
최종 손실 함수
| 항목 | 값 |
|---|---|
| (CTC) | 1.0 |
| (어텐션 KD) | 0.1 |
| (데이터 KD) | 1.0 |
📊 Figure 1 — Wait-k 동시 번역 전략 다이어그램
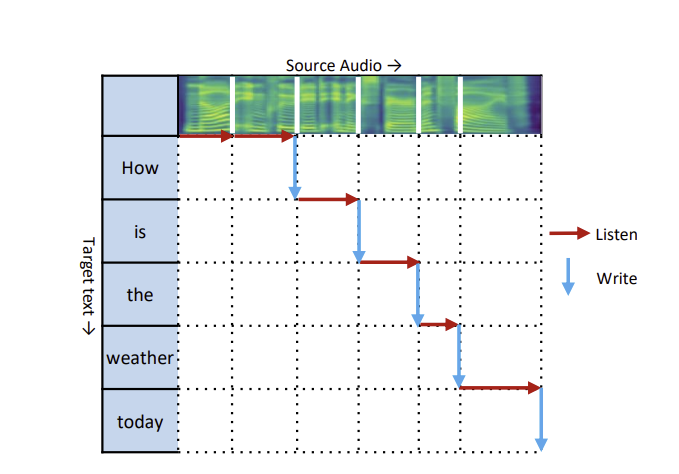
- 이 그림이 보여주는 것: "How is the weather today"라는 영어 소스 오디오가 시간 순서로 들어올 때, 설정 하에서 소스 세그먼트 읽기(Listen)와 번역 단어 쓰기(Write)가 어떻게 교차하는지 보여줍니다. 처음 2개 세그먼트를 읽은 뒤 첫 번째 번역 단어를 쓰고, 이후 세그먼트 하나가 들어올 때마다 번역 단어 하나를 씁니다.
- 핵심 메시지: Wait-k에서 는 "번역을 시작하기 전 미리 들을 세그먼트 수"입니다. 소스 세그먼트가 고갈되면 나머지는 전체 문장 번역으로 자연스럽게 전환됩니다.
내가 이해한 포인트
그림에서 Listen과 Write가 교차하는 패턴이 동시통역사의 작업 방식과 정확히 일치합니다. 전문 통역사도 "2~3단어를 먼저 듣고 → 번역 시작 → 계속 들으면서 번역 지속"이라는 리듬으로 작업합니다. Wait-k는 이 인간의 전략을 수식으로 공식화한 것입니다.
📊 Figure 2 — SimulSpeech 모델 구조 및 학습 파이프라인
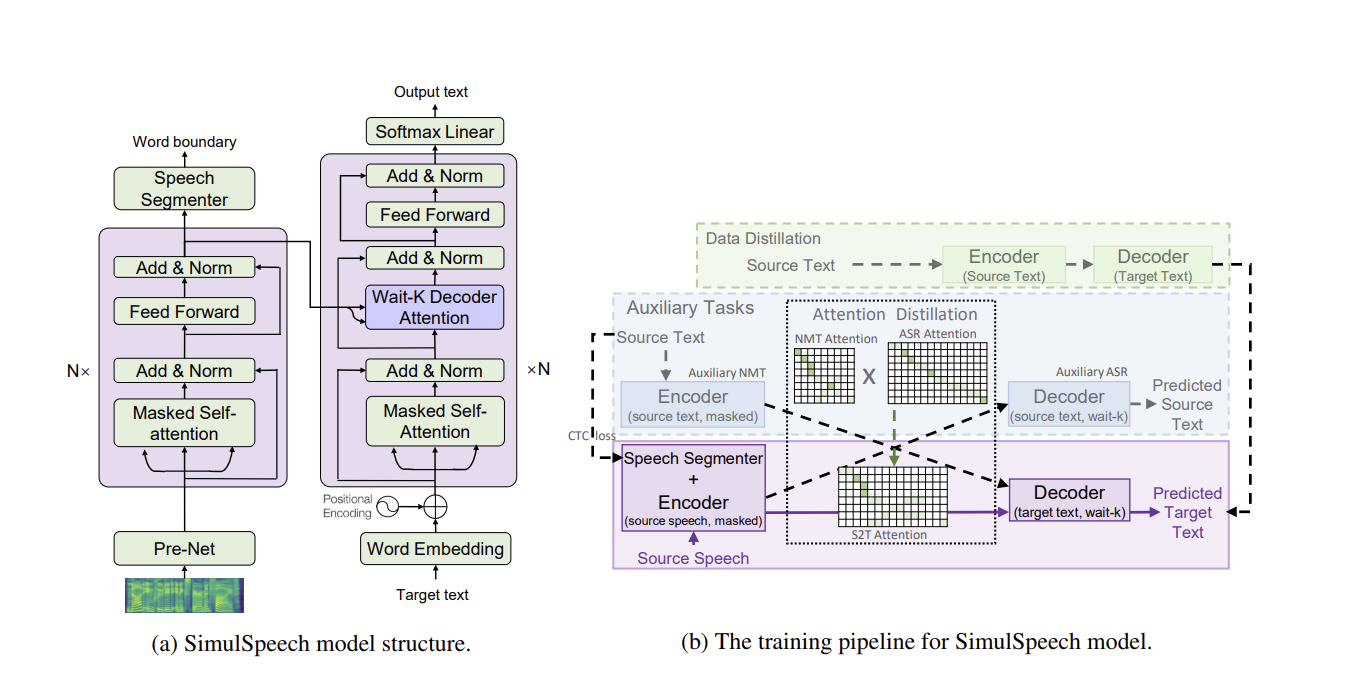
- (a) 모델 구조: Pre-Net → 마스크 자기 어텐션 인코더 N층 → 음성 분절기(소프트맥스 선형) → Wait-k 디코더 어텐션 N층 → 출력 텍스트. 인코더와 디코더 모두 기본 트랜스포머 구조를 따릅니다.
- (b) 학습 파이프라인: 보조 ASR 태스크(인코더 공유), 보조 NMT 태스크(디코더 공유), 오프라인 NMT 교사 모델, 데이터 수준 KD, 어텐션 수준 KD가 SimulSpeech 본 모델(보라색 박스)을 감싸는 구조.
- 핵심 메시지: SimulSpeech 자체는 보라색 박스 하나지만, 학습 시에는 ASR과 NMT 보조 태스크가 어텐션 행렬 지식을 제공합니다. 추론 시에는 보조 태스크 없이 본 모델만 작동합니다.
내가 이해한 포인트
보조 ASR과 보조 NMT가 인코더/디코더를 SimulSpeech와 공유한다는 점이 핵심입니다. 공유 덕분에 어텐션 행렬의 지식이 자연스럽게 SimulSpeech 파라미터에 스며듭니다. 별도의 교사 모델을 따로 훈련할 필요가 없습니다.
📊 Figure 3 — 어텐션 수준 지식 증류 상세 다이어그램

- 이 그림이 보여주는 것: ASR 어텐션 행렬()과 NMT 어텐션 행렬()을 행렬 곱하면 S2T 어텐션 교사 행렬()이 만들어집니다. 이를 이진화한 뒤 SimulSpeech가 예측한 어텐션과 비교해 Binarization Loss를 계산합니다.
- 핵심 메시지: 음성 길이(), 소스 텍스트 길이(), 번역 텍스트 길이() 세 차원에서 두 행렬을 곱해 차원이 맞는 음성-번역 정렬 행렬을 만드는 과정입니다.
내가 이해한 포인트
이진화(Binarization) 임계값 0.05는 어텐션 행렬에서 노이즈를 제거하고 명확한 정렬만 남기기 위한 것입니다. 부드러운 어텐션보다 날카로운 이진 신호가 SimulSpeech 학습을 안정적으로 가이드합니다.
📊 Figure 4 — 번역 품질(BLEU) vs 지연 시간(AP/AL) 트레이드오프
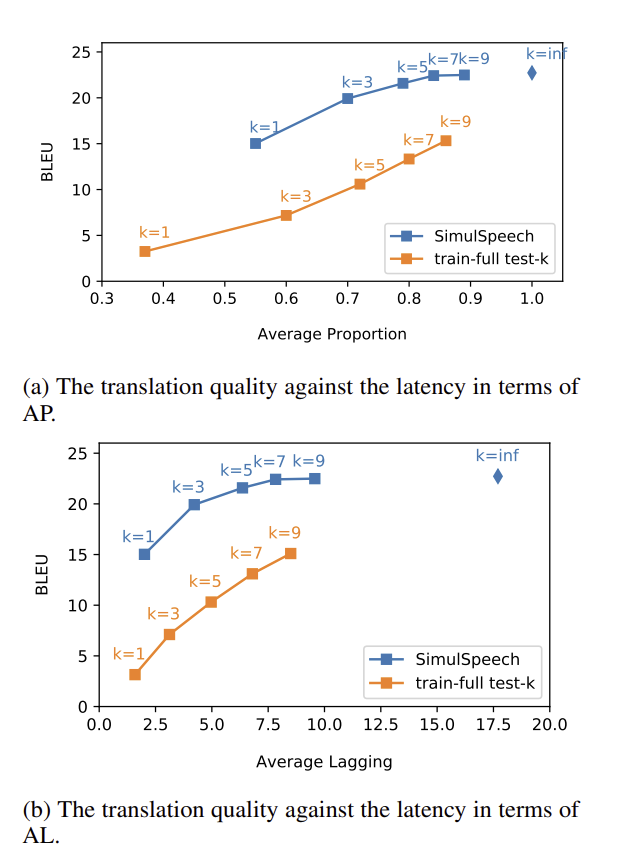
- 이 그림이 보여주는 것: En→Es 데이터셋에서 와 (오프라인) 각각의 BLEU 점수와 AP(Average Proportion)/AL(Average Lagging) 지연 값을 SimulSpeech와 train-full test-k 두 곡선으로 비교합니다.
- 핵심 메시지: 동일 지연 수준에서 SimulSpeech가 항상 train-full test-k보다 높은 BLEU를 기록합니다. 훈련 시부터 Wait-k 방식으로 학습한 것이 테스트 시 Wait-k를 적용하는 것보다 일관되게 우수합니다.
내가 이해한 포인트
곡선이 오른쪽 위로 갈수록(k가 커질수록) BLEU가 높아지고 지연도 길어집니다. 두 곡선 간의 수직 격차가 SimulSpeech의 지식 증류 효과를 시각적으로 증명합니다. 같은 지연이면 SimulSpeech가 항상 더 정확합니다.
📊 Figure 5 — 오류 누적 사례 분석

- 이 그림이 보여주는 것: "classic apple"이라는 영어 표현에서 ASR(wait-1)이 "class sake apple"로 오인식하고, 이 오류가 NMT 번역 결과까지 망치는 캐스케이드 오류 전파 과정. SimulSpeech(wait-3)는 "manzana clásica(클래식 사과)"로 올바르게 번역합니다.
- 핵심 메시지: 동일한 지연(ASR wait-1 + NMT wait-3 = SimulSpeech wait-3)에서 캐스케이드 방식은 오인식 하나로 전체 번역이 무너지지만, SimulSpeech는 음성-번역 직접 정렬로 이 문제를 피합니다.
📊 Figure 6 — SimulSpeech vs 캐스케이드 BLEU-지연 비교
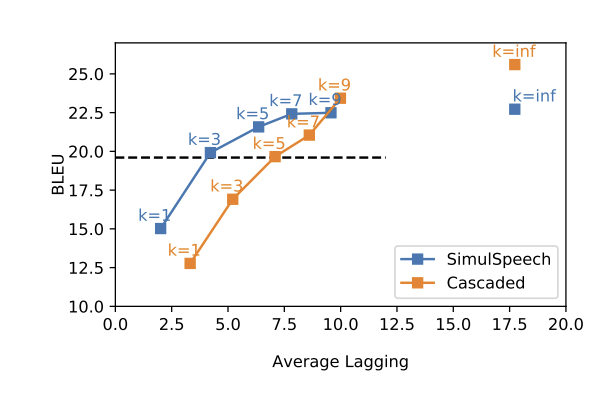
- 이 그림이 보여주는 것: AL(Average Lagging)을 X축, BLEU를 Y축으로 SimulSpeech와 캐스케이드 두 곡선을 비교합니다.
- 핵심 메시지: SimulSpeech wait-3이 캐스케이드 wait-5와 동일한 BLEU를 달성합니다. 즉 두 세그먼트 더 빨리 시작하면서 같은 번역 품질을 냅니다.
5. Experiments & Results
실험 설정
| 항목 | 내용 |
|---|---|
| 데이터셋 | MuST-C En→Es (496시간, 229,703문장), En→De (400시간, 265,625문장) |
| 모델 구조 | Transformer (히든 384, 헤드 4, 인코더 6층, 디코더 4층) |
| 음향 입력 | 멜 스펙트로그램 (50ms 프레임, 12.5ms 홉) |
| 평가 지표 | BLEU (번역 품질), AP / AL (지연 시간) |
| 학습 환경 | NVIDIA Tesla V100 × 2, 배치 64문장 |
번역 품질 결과 (Table 2: BLEU 점수)
| 1 | 3 | 5 | 7 | 9 | ∞ (오프라인) | |
|---|---|---|---|---|---|---|
| En→Es SimulSpeech | 15.02 | 19.92 | 21.58 | 22.42 | 22.49 | 22.72 |
| En→Es FS(오프라인 학습+Wait-k 테스트) | 3.25 | 7.18 | 10.52 | 13.33 | 15.32 | 22.72 |
| En→De SimulSpeech | 10.73 | 15.52 | 16.90 | 17.46 | 17.87 | 18.29 |
캐스케이드 vs SimulSpeech 비교 (Table 3: En→Es)
| Cascaded | SimulSpeech | 우위 | |
|---|---|---|---|
| 1 | 12.77 | 15.02 | SimulSpeech +2.25 ✅ |
| 3 | 16.91 | 19.92 | SimulSpeech +3.01 ✅ |
| 5 | 19.66 | 21.58 | SimulSpeech +1.92 ✅ |
| 7 | 21.05 | 22.42 | SimulSpeech +1.37 ✅ |
| 9 | 23.43 | 22.49 | Cascaded 우위 |
결과 해석
실시간 번역에서 중요한 구간에서는 SimulSpeech가 캐스케이드를 일관되게 앞섭니다. Figure 6 기준으로 SimulSpeech wait-3 ≈ Cascaded wait-5 입니다. 두 세그먼트 덜 기다리면서 같은 품질을 냅니다.
절제 실험 (Table 4: 각 기법의 기여도)
| 모델 | |||
|---|---|---|---|
| Naive S2T | 9.02 | 14.90 | 15.90 |
| + 보조 태스크 | 12.98 | 19.41 | 20.39 |
| + 보조 + Data KD | 13.77 | 20.98 | 21.52 |
| + 보조 + Attn KD | 13.74 | 20.64 | 20.90 |
| + 보조 + Data KD + Attn KD | 15.02 | 21.58 | 22.49 |
두 지식 증류 기법이 각각 독립적으로도 효과적이며, 함께 쓸 때 최고 성능을 냅니다.
6. Discussion
✅ 이 방법의 장점
- 오류 누적 해소 — ASR 오인식이 번역에 전파되는 캐스케이드 문제가 구조적으로 사라집니다.
- 이중 지연 제거 — 단일 모델이므로 Wait-k가 한 번만 적용됩니다. 같은 품질에서 더 빠릅니다.
- 어텐션 KD의 우아함 — 두 전문가 모델의 어텐션 행렬 곱으로 음성-번역 정렬 모범 답안을 자동 생성합니다. 별도의 음성-번역 정렬 데이터가 필요 없습니다.
- 단일 파라미터 최적화 — 모든 구성 요소가 동시에 학습되므로 전체 목표에 최적화됩니다.
❌ 한계점 및 트레이드오프
- 고정된 Wait-k — 으로 설정하면 단순한 단어도, 복잡한 전문 용어도 무조건 3세그먼트를 기다립니다. 문맥 난이도에 따른 유연성이 없습니다.
- 분절기의 취약성 — 화자가 기침하거나 "어..." 하고 머뭇거리면 분절기가 이를 단어 경계로 착각할 수 있습니다. 엉뚱한 타이밍에 번역이 시작될 위험이 있습니다.
- 큰 k에서 캐스케이드에 열세 — 구간에서는 캐스케이드가 앞섭니다. 지연이 충분히 허용되는 환경에서는 캐스케이드가 나을 수 있습니다.
- 데이터 요구량 — 학습 데이터가 (소스 음성, 소스 텍스트, 번역 텍스트) 세 가지 쌍으로 구성돼야 합니다. 데이터 구축 비용이 높습니다.
💡 개선 가능한 방향
- 적응형 Wait-k — 인식의 불확실성이 낮으면 바로 번역하고, 높으면 더 기다리는 동적 정책으로 발전시킵니다.
- 분절기 강화 — 묵음·잡음·머뭇거림을 단어 경계와 명확히 구분하는 더 정교한 분절 모듈이 필요합니다.
- 음성→음성 번역 — 저자들이 직접 언급한 향후 방향입니다. 타깃 언어를 텍스트가 아닌 음성으로 생성하는 음성→음성 동시 번역으로 확장합니다.
7. My Insights
새롭게 알게 된 점
"두 개의 전문가 어텐션 행렬을 곱하면 그 중간 다리를 건너뛴 정렬이 만들어진다"는 아이디어가 놀라웠습니다. 수학적으로 당연한 행렬 곱이지만, 이것을 지식 증류의 모범 답안으로 활용한다는 발상이 매우 창의적입니다. 복잡한 음성-번역 정렬을 처음부터 학습하지 않아도 된다는 실용적 우아함이 인상 깊었습니다.
기존 생각이 바뀐 부분
"오류 누적을 줄이려면 각 모듈의 정확도를 높여야 한다"고 생각했습니다.
하지만 SimulSpeech는 구조 자체를 바꿔 문제를 해결했습니다. 오류 누적이 발생하는 중간 단계를 없애버리니 아무리 각 모듈이 뛰어나도 피할 수 없는 구조적 문제가 사라졌습니다. 성능 개선보다 구조적 재설계가 더 근본적인 해법이 될 수 있음을 배웠습니다.
어디에 응용할 수 있을까?
국제 학술 컨퍼런스 실시간 자막 서비스에 SimulSpeech를 적용하면 흥미로울 것 같습니다. 특히 학술 발표는 단어 경계가 비교적 명확하고 발화 속도가 일정해서 분절기의 취약성이 줄어듭니다. wait-3 수준에서 캐스케이드 wait-5와 동등한 품질이 나오므로, 청중이 느끼는 자막 지연이 크게 줄어들 것 같습니다.
8. Summary
| 항목 | 내용 |
|---|---|
| 핵심 문제 | 캐스케이드 ASR+NMT의 오류 누적과 이중 지연 — 두 모델이 분리되어 최적화되지 않음 |
| 해결 방법 | CTC 분절기로 음성 세그먼트 감지 + Wait-k 디코더로 실시간 번역 + 어텐션/데이터 이중 지식 증류 |
| 핵심 기여 | 동시 번역 환경에서 캐스케이드 대비 일관된 BLEU 향상, SimulSpeech wait-3 ≈ Cascaded wait-5 |
| 가장 인상 깊었던 점 | ASR 어텐션 × NMT 어텐션 = S2T 정렬 모범 답안이라는 수학적으로 우아한 지식 증류 설계 |
| 아쉬운 점 | 고정 Wait-k의 유연성 부재, 분절기의 잡음 취약성, 에서 캐스케이드에 열세 |
| 확장 방향 | 적응형 Wait-k 정책, 강건한 분절기, 음성→음성 동시 번역 |
🧠 이 논문을 한 문장으로 말하면?
SimulSpeech는 ASR→NMT의 오류 누적 구조를 CTC 분절기와 Wait-k 디코더로 하나로 합치고, 두 전문가 어텐션의 행렬 곱을 모범 답안으로 삼는 이중 지식 증류로 학습을 안정화해, 같은 지연에서 캐스케이드를 능가하는 종단간 동시 음성 번역 시스템이다.
