[논문 리뷰] Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
Whisper: Robust Speech Recognition via Large-Scale Weak Supervision(https://arxiv.org/pdf/2212.04356)
680,000시간의 지저분한 인터넷 데이터로 만든 만능 음성 인식 — 추가 학습 없이 사람 수준에 도달하다
깨끗한 데이터 1,000시간 대신 지저분한 인터넷 데이터 68만 시간을 쏟아부어,
어떤 환경에서도 추가 학습(Fine-tuning) 없이 바로 작동하는 다국어 음성 인식 시스템.
ICML 2023 | Alec Radford, Jong Wook Kim et al. (OpenAI)
목차
- 서론
- Background
- Problem Definition
- Proposed Method / Approach
- Experiments & Results
- Discussion
- My Insights
- Summary
1. 서론
이 논문은 음성 인식 분야에서 오랫동안 묻혀 있던 질문을 꺼냅니다.
"LibriSpeech에서 사람을 뛰어넘는 모델이, 왜 실제 세상에서는 엉망이 될까?"
2015년 Deep Speech 2는 LibriSpeech test-clean에서 사람 수준의 WER을 달성했습니다. 그런데 7년 후에도 여전히 시끄러운 환경이나 사투리가 섞인 음성 앞에서 기계는 사람보다 약 2배 더 많은 오류를 냅니다. 이 논문은 그 이유를 정확히 짚습니다. 훈련과 평가가 같은 데이터 분포 안에서만 이루어지기 때문입니다. 사람은 처음 보는 환경에서도 잘 인식하는데, 기계는 자기가 공부한 데이터와 조금만 달라져도 무너집니다.
Whisper는 이 문제를 해결하기 위해 완전히 다른 방향을 선택했습니다. 깨끗한 데이터를 만드는 데 공을 들이는 대신, 인터넷의 지저분하고 오류가 섞인 오디오-텍스트 쌍을 68만 시간 규모로 쏟아부었습니다.
2. Background
논문의 핵심으로 들어가기 전에, 왜 이 방향이 혁신적인지 배경을 살펴봅니다.
음성 인식의 두 가지 주류 방식
| 방식 | 대표 모델 | 장점 | 치명적 한계 |
|---|---|---|---|
| 비지도 사전학습 | wav2vec 2.0 | 레이블 없이 100만 시간 학습 가능 | 디코더가 없어 Fine-tuning이 반드시 필요 |
| 지도 학습 | 기존 ASR 시스템 | 정확도 높음 | 깨끗한 데이터 부족, 분포 밖 성능 급락 |
비지도 사전학습의 아킬레스건
wav2vec 2.0 같은 비지도 모델은 인코더 학습에는 탁월합니다. 하지만 그 결과를 실제 텍스트로 변환하려면 Fine-tuning이라는 추가 단계가 꼭 필요합니다. 그리고 Fine-tuning 과정에서 또 다른 문제가 생깁니다.
Fine-tuning된 모델은 특정 데이터셋의 버릇(spurious patterns) 을 학습합니다. LibriSpeech에서 Fine-tuning하면 LibriSpeech 스타일에 과적합되고, 다른 환경에서 성능이 뚝 떨어집니다.
이것은 비단 음성 인식만의 문제가 아닙니다. 컴퓨터 비전에서도 동일한 현상이 관찰됐습니다. ImageNet에서 Fine-tuning한 모델이 ImageNet에서 9.2% 성능이 오르면서 동시에 다른 7개 데이터셋에서 평균 성능은 전혀 오르지 않는 현상이 확인된 바 있습니다.
3. Problem Definition
이 논문이 꼬집는 핵심 문제는 "현재 음성 인식 벤치마크의 '초인간적 성능'은 착시다" 입니다.
사람 vs 기계 — 공정하지 않은 비교
| 평가 대상 | 학습 조건 | 실제 측정하는 것 |
|---|---|---|
| 사람 | 특정 데이터셋 학습 없음 | 분포 밖(OOD) 일반화 능력 |
| 기계 (Fine-tuned) | 해당 데이터셋으로 충분히 학습 | 분포 내(In-distribution) 암기 능력 |
같은 테스트를 치르지만 서로 다른 능력을 재고 있습니다. LibriSpeech에서 WER 1.4%를 달성한 모델이 다른 환경에서는 사람보다 2배 더 틀리는 이유가 여기 있습니다.
기존 데이터의 규모 한계
| 데이터 유형 | 규모 |
|---|---|
| 학술 지도 학습 데이터 (평균) | ~1,000시간 |
| SpeechStew (7개 데이터셋 합산) | 5,140시간 |
| 비지도 학습 (wav2vec 2.0) | 1,000,000시간 |
| Whisper (약지도 학습) | 680,000시간 |
핵심 통찰:
지도 학습과 비지도 학습 사이에 거대한 규모 격차가 있었습니다. Whisper는 이 격차를 약지도(Weakly Supervised) 학습으로 메웁니다. 정답이 100% 정확하지 않아도 됩니다. 양과 다양성으로 승부합니다.
4. Proposed Method / Approach
Whisper는 구조 자체는 평범한 인코더-디코더 트랜스포머입니다. 혁신은 구조가 아니라 데이터와 학습 방식에 있습니다.
모델 아키텍처 (Table 1 기준)
| 모델 | 레이어 | 너비 | 헤드 수 | 파라미터 |
|---|---|---|---|---|
| Tiny | 4 | 384 | 6 | 39M |
| Base | 6 | 512 | 8 | 74M |
| Small | 12 | 768 | 12 | 244M |
| Medium | 24 | 1,024 | 16 | 769M |
| Large | 32 | 1,280 | 20 | 1,550M |
입력 처리 파이프라인
- 오디오를 16,000Hz로 리샘플링합니다.
- 25ms 윈도우, 10ms 스트라이드로 80채널 로그 멜 스펙트로그램을 계산합니다.
- 전처리 최솟값을 전체 데이터 기준 전역 정규화(-1~1)합니다.
- 30초 단위로 잘라 인코더에 입력합니다.
핵심 혁신: 멀티태스크 특수 토큰
Whisper는 하나의 모델로 여러 작업을 처리합니다. 어떤 작업을 할지를 특수 토큰으로 지정합니다.
[이전 텍스트] → <|startoftranscript|> → <언어 토큰> → <작업 토큰> → <타임스탬프 여부> → 출력| 토큰 | 역할 |
|---|---|
<\|startoftranscript\|> | 출력 시작 신호 |
<언어 토큰> | 99개 언어 중 하나 지정 |
<\|transcribe\|> | 같은 언어로 받아쓰기 |
<\|translate\|> | 영어로 번역 |
<\|notimestamps\|> | 타임스탬프 없이 출력 |
<\|nospeech\|> | 음성 없음 (묵음 감지) |
<\|endoftranscript\|> | 출력 종료 신호 |
이것이 강력한 이유:
음성 인식, 번역, 언어 감지, 음성 활동 감지(VAD)를 하나의 모델이 처리합니다. 별도의 파이프라인이 필요 없습니다. GPT-2와 동일한 바이트 수준 BPE 토크나이저를 사용해 텍스트 정규화 단계도 불필요합니다.
수식 이해하기
직관: 눈 가리고 릴레이 소설 쓰기
| 기호 | 의미 |
|---|---|
| 입력된 30초짜리 오디오 | |
| 특수 토큰 지시사항 ("영어로 받아쓰기" 등) | |
| 지금까지 출력한 단어들 전부 | |
| 지금 뱉을 단 하나의 단어 | |
| 각 단어 확률을 전부 곱함 |
오디오()라는 주제가 주어집니다. 지시사항()을 받습니다. 앞사람들이 써놓은 문장()을 읽습니다. 그 흐름에 가장 자연스러운 다음 단어()를 고릅니다. 이 과정을 끝까지 반복하고 곱하면 전체 문장의 확률이 나옵니다.
68만 시간 데이터 정제 파이프라인
방대한 인터넷 데이터에는 쓰레기가 많습니다. 저자들은 여러 단계의 필터링을 적용했습니다.
- 기계 생성 자막 제거 — 기존 ASR 시스템이 만든 자막은 학습에 독이 됩니다. 전부 대문자/소문자만 있거나 쉼표가 없는 등 패턴으로 감지해 제거했습니다.
- 언어 불일치 제거 — 음성과 자막의 언어가 다른 쌍을 제거합니다. 단, 자막이 영어면 번역 학습 데이터로 재활용합니다.
- 중복 제거 — 퍼지 매칭으로 중복 텍스트를 제거합니다.
- 초기 모델로 재검수 — 첫 번째 모델을 훈련한 뒤 오류율이 높은 데이터 소스를 수동 검수해 저품질 소스를 추가 제거했습니다.
📊 Figure 1 — Whisper 전체 아키텍처 및 멀티태스크 학습 형식
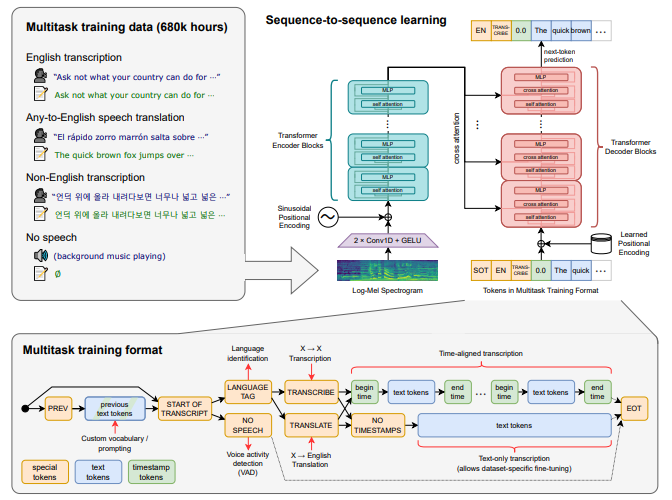
- 이 그림이 보여주는 것: 왼쪽은 680,000시간의 멀티태스크 학습 데이터 예시(영어 받아쓰기, 스페인어→영어 번역, 한국어 받아쓰기, 묵음 감지). 가운데는 인코더(로그멜 스펙트로그램 → 2-Conv + 트랜스포머 블록)와 디코더(크로스 어텐션 기반 트랜스포머 블록). 오른쪽은 특수 토큰 시퀀스가 각각 VAD, 언어 감지, 받아쓰기, 번역, 타임스탬프 예측으로 매핑되는 멀티태스크 출력 형식입니다.
- 핵심 메시지: 4가지 다른 학습 데이터 유형(영어 받아쓰기, X→영어 번역, 비영어 받아쓰기, 묵음)을 하나의 통일된 토큰 시퀀스로 표현합니다. 전통적 파이프라인의 여러 모듈이 특수 토큰 하나로 대체됩니다.
내가 이해한 포인트
이 그림에 한국어 예시("언덕 위에 올라 내려다보면...")가 직접 등장합니다. 한국어를 포함한 다국어 학습이 얼마나 자연스럽게 하나의 토큰 형식으로 통합됐는지 보여줍니다. 특히 묵음을<|nospeech|>토큰 하나로 처리하는 것이 인상적입니다. 별도의 VAD 모듈이 필요 없어집니다.
📊 Figure 2 — Zero-shot Whisper vs 지도 학습 모델의 강건성 비교
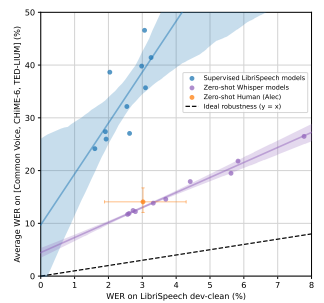
- 이 그림이 보여주는 것: X축은 LibriSpeech dev-clean WER(기준 분포 성능), Y축은 Common Voice + CHiME-6 + TED-LIUM 평균 WER(분포 밖 성능). 점선은 이상적 강건성(). 파란 점들은 지도 학습 LibriSpeech 모델들, 빨간 점들은 Zero-shot Whisper 모델들, 별표는 사람(Alec) 성능입니다.
- 핵심 메시지: LibriSpeech에서 비슷한 성능을 내는 지도 학습 모델(파란 점)과 Whisper(빨간 점)를 비교하면, 지도 학습 모델들은 Y축이 훨씬 위에 있습니다. 분포 밖에서 약 2배 더 많이 틀린다는 뜻입니다. 반면 Zero-shot Whisper는 사람의 95% 신뢰구간 안에 위치합니다.
내가 이해한 포인트
"기울기가 이상적 직선()에 가까울수록 강건한 모델"이라는 시각화 방식이 매우 직관적입니다. 지도 학습 모델들이 점선보다 훨씬 위에 몰려 있다는 것이 "LibriSpeech 성능이 좋을수록 다른 곳에서 더 많이 틀린다"는 역설적 패턴을 보여줍니다. Fine-tuning의 부작용을 이토록 명확하게 시각화한 그림입니다.
5. Experiments & Results
실험 설계의 핵심 원칙
저자들은 Whisper를 Zero-shot 환경에서만 평가했습니다. 즉, 평가 데이터셋의 훈련 데이터를 단 한 줄도 학습에 사용하지 않았습니다. 이것이 기존 SOTA 비교와 근본적으로 다른 점입니다.
| 항목 | 내용 |
|---|---|
| 평가 방식 | Zero-shot (어떤 평가셋도 Fine-tuning에 미사용) |
| 평가 데이터셋 | LibriSpeech + 12개 OOD 데이터셋 |
| 평가 지표 | WER + 텍스트 정규화 후 WER |
| 비교 대상 | wav2vec 2.0 Large + 사람 |
영어 음성 인식 핵심 결과 (Table 2 기준)
| 데이터셋 | wav2vec 2.0 Large | Whisper Large V2 | 상대 오류 감소 |
|---|---|---|---|
| LibriSpeech Clean | 2.7% | 2.7% | 0.0% |
| CHiME-6 (잡음) | 65.8% | 25.5% | 61.2% |
| Common Voice | 29.9% | 9.0% | 69.9% |
| CORAAL (사투리) | 35.6% | 16.2% | 54.5% |
| AMI IHM (회의) | 37.0% | 16.9% | 54.3% |
| 평균 (14개 셋) | 29.3% | 12.8% | 55.2% ✅ |
결과 해석
LibriSpeech에서는 두 모델이 동점(2.7%)입니다. 하지만 다른 환경으로 나가면 양상이 완전히 달라집니다. Whisper는 14개 데이터셋 평균에서 오류를 55.2% 줄였습니다. 특히 시끄러운 CHiME-6에서 65.8% → 25.5%로 떨어뜨린 것이 압도적입니다.
6. Discussion
✅ 이 방법의 장점
- Zero-shot 강건성 — Fine-tuning 없이도 사람의 강건성과 비슷한 수준에 도달했습니다.
- 멀티태스크 단일 모델 — 음성 인식, 번역, 언어 감지, VAD를 토큰 하나로 전환합니다.
- 스케일 다양성 — Tiny(39M)부터 Large(1,550M)까지 5가지 모델로 엣지-클라우드 전방위 대응이 가능합니다.
- 코드 및 모델 공개 — 오픈소스로 공개해 후속 연구의 기반이 되었습니다.
❌ 한계점 및 트레이드오프
- 환각(Hallucination) 현상 — 묵음 구간에서 모델이 앞뒤 문맥을 바탕으로 없는 말을 지어냅니다. 의료·법률 분야에서는 치명적입니다.
- 실시간 처리 불가 — 30초 단위로 처리하는 오프라인 구조입니다. 실시간 자막 서비스에 직접 쓸 수 없습니다. (→ MFLA 같은 후속 연구의 배경)
- 영어 편향 — 680,000시간 중 117,000시간만 비영어입니다. 비영어 언어 성능이 영어 대비 낮습니다.
- WER 평가의 한계 — Zero-shot 모델은 데이터셋별 표기 형식(띄어쓰기, 대소문자 등)을 모릅니다. 실제로 맞았지만 형식 차이로 오답 처리됩니다. 저자들이 텍스트 정규화를 직접 개발해 보완했지만, 과적합 위험도 있습니다.
💡 개선 가능한 방향
- 스트리밍 적용 — MFLA, Simul-Whisper 등 이미 등장한 연구들처럼 실시간 처리가 가능하도록 파인튜닝합니다.
- 환각 억제 — 음성 활동 감지를 강화하거나,
<|nospeech|>예측 신뢰도 임계값을 올려 묵음 구간 지어내기를 막습니다. - 저자원 언어 보완 — 아프리카어, 남미 언어 등 데이터가 부족한 언어를 집중 보강하거나, 데이터가 많은 언어에서 지식을 전이합니다.
7. My Insights
새롭게 알게 된 점
"LibriSpeech에서 사람보다 잘하는 모델이 왜 실전에서 더 나쁠까?"라는 질문의 답을 이 논문에서 명확하게 얻었습니다. 사람과 기계는 같은 시험을 보지만 전혀 다른 능력을 측정받고 있습니다. 사람은 처음 보는 환경에서의 일반화 능력을, 기계는 해당 분포 안에서의 암기 능력을 평가받습니다. 벤치마크 성능이 실제 능력을 얼마나 왜곡할 수 있는지 뼈저리게 느꼈습니다.
기존 생각이 바뀐 부분
"좋은 AI 모델을 만들려면 데이터를 최대한 깨끗하게 정제해야 한다"고 생각했습니다.
하지만 Whisper는 반대를 증명했습니다. 기계 생성 자막과 오류가 섞인 데이터를 엄청난 규모로 학습했고, 오히려 그 다양성 덕분에 어떤 환경에서도 무너지지 않는 강건함을 얻었습니다. "데이터 정제"가 답이 아니라 "데이터 다양성과 규모"가 강건성의 핵심이라는 관점이 바뀌었습니다.
어디에 응용할 수 있을까?
온디바이스 다국어 음성 비서를 생각해보면, Tiny(39M) 모델이 단 하나로 음성 인식, 언어 감지, 번역을 모두 처리한다는 점이 매력적입니다. 스마트폰에서 네트워크 없이도 한국어→영어 동시 번역이 가능한 오프라인 앱의 핵심 엔진이 될 수 있을 것 같습니다. 다만 환각 현상을 억제하기 위해 신뢰도 기반 필터링 레이어를 추가하는 것이 실사용에서 중요할 것 같습니다.
8. Summary
| 항목 | 내용 |
|---|---|
| 핵심 문제 | Fine-tuning된 모델은 특정 데이터셋에 과적합되어 실제 환경에서 성능이 급락 — 벤치마크 성능이 실제 강건성을 반영하지 않음 |
| 해결 방법 | 약지도(Weakly Supervised) 방식으로 인터넷 오디오-자막 680,000시간 수집 + 멀티태스크 특수 토큰 + Zero-shot 학습 |
| 핵심 기여 | 14개 OOD 데이터셋 평균 WER 55.2% 감소, 사람의 강건성 수준 달성, 음성 인식·번역·VAD·언어 감지 단일 모델 통합 |
| 가장 인상 깊었던 점 | "같은 시험인데 사람과 기계가 서로 다른 능력을 측정받는다"는 통찰 — LibriSpeech SOTA가 실제 강건성과 무관할 수 있음을 입증 |
| 아쉬운 점 | 묵음 구간 환각 현상, 오프라인 구조로 실시간 처리 불가, 비영어 언어 성능 불균형 |
| 확장 방향 | MFLA/Simul-Whisper로 실시간화, 환각 억제, 저자원 언어 보완, SpeechLLM 결합 |
🧠 이 논문을 한 문장으로 말하면?
Whisper는 완벽한 데이터 대신 68만 시간의 지저분한 인터넷 데이터와 멀티태스크 약지도 학습으로, Fine-tuning 없이도 어떤 환경에서든 사람 수준의 강건함을 달성한 음성 인식의 패러다임 전환이다.
