[Django] 알고 사용하자! Queryset 카운트 내부 동작
소개 📄
어느 서비스에서든 절대 빠질 수 없는 로직 중 하나는 바로 집계 로직입니다.
총 포스트 개수, 총 유저 수, 활동 중인 유저 수 등...
어떤 간단한 서비스더라도, 특정 조건에 부합하는 데이터가 총 몇 개인지 집계하는 일은 항상 필요하죠.
Django 에서는 강력한 내부 API를 이용하여 여러 방법으로 집계 로직들을 아주 간단하게 처리할 수 있습니다.
하지만 방법마다 내부 동작이 다르다는 사실, 혹시 알고 사용하고 계셨나요? 🧐
이번 포스트에서는 Django에서 Queryset을 집계할 때, 내부적으로 어떻게 동작하는지 소개해드리려고 합니다.
⠀
들어가기 전에 🎫
세팅
- MySQL 8.0 버전을 이용하였습니다.
- Django 3.2 버전을 이용하였습니다.
- Python 3.9.6 버전을 이용하였습니다.
- 테스트 테이블을 생성하였습니다.
id | int | auto_increment primary_key
name | varchar | null = True
type | varchar | null = True
(스토리지 엔진: InnoDB) - 테스트 테이블 내 총 780만 개의 더미 데이터를 삽입하였습니다.
(각 방법 별 내부 동작과 성능 차이를 보다 확실히 확인하기 위해 많은 양의 더미 데이터를 이용했습니다.)
가정
별도의 조건 없이 모델의 모든 데이터의 수를 집계한다고 가정합니다.
⠀
Queryset을 집계하는 대표적인 방법 🗄
국내외 블로그, GitHub 등에서 가장 많이 볼 수 있었던 세 가지 방법을 예제로 사용해보려 합니다.
1. len(Queryset)
queryset1 = Model.objects.all()
count = len(queryset1)2. Queryset.count
queryset1 = Model.objects.all()
count = queryset1.count()3. Queryset.aggregate Count
from django.db.models import Count
queryset1 = Model.objects.all()
count = queryset1.aggregate(count=Count('id'))⠀
독자 여러분들께서 장고를 사용해보셨다면, 아마 세 방법 중 하나 이상은 한 번쯤 보신 경험이 있으리라 생긱됩니다.
내부에선 어떻게 동작할까요 ? ⚙️
len(Queryset)
Django의 Queryset 은 Django가 정의한 사용자 정의 클래스입니다.
그리고 이 Queryset 클래스 안에는, 특별 메서드 __len__ 이 별도의 사용자 정의 메서드로 구현되어 있습니다.
때문에, 반환된 Queryset에 len 함수를 사용했을 때는 Queryset 클래스 안에 구현된 사용자 정의 특별 메서드 len 을 호출하게 됩니다.

* ( Queryset 클래스 내의 사용자 정의 특별 메서드 __len__ )
메서드의 첫 줄을 보니 self._fetch_all 이라는 심상치 않은 친구가 있네요.
보통 fetch의 의미는 실제로 반영하고, 가져온다는 의미로 사용되는데요...
계속해서 _fetch_all 을 확인 해보겠습니다.

* ( django/db/models/query.py - Queryset._fetch_all )
쿼리가 evaluate 되지 않아 캐시(_result_cache) 가 비어있다면 쿼리를 evaluate 시킨 후, 모델 객체 list 형태로 모두 캐싱하는 로직이 구현되어 있습니다.
위 로직이 모두 끝나면, __len__ 에서 캐시 변수의 길이를 integer 타입으로 반환합니다.
이렇게 len(Queryset)을 할 시엔 쿼리를 evaluate 시키고 반환된 모델 객체 list를 전부 캐싱까지 한 다음 해당 캐시의 길이를 반환하게 됨으로, SELECT * FROM table 을 실행하는 것을 알 수 있습니다.
SELECT * FROM table을 한다고 했지만
사실 쿼리를 hit 할 뿐만 아니라, 쿼리 결과를 iter 하며 Model 객체로 컨버팅 후 cache에 담는 시간 또한 치명적입니다
⠀
위 로직에 대해 더 자세히 보고싶으시다면 Django ModelIterable Class 를 확인해보세요 :)
Queryset.count
사실 Queryset에 len 메서드를 사용하는 경우는 극히 드물긴 합니다.(ㅎㅎ;;)
대부분은 거의 지금 소개해드릴 Queryset.count 또는 aggregate.Count를 많이 사용하곤 하는데요,
두 API의 동작 과정도 미묘하게 다릅니다.
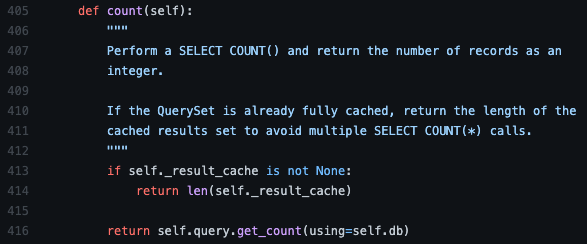
* ( django/db/models/query.py - Queryset.count )
Queryset 클래스 내부의 인스턴스 메서드 count가 구현되어 있는 곳으로 왔습니다.
친절하게 주석이 잘 달려 있네요. 대충 해석을 해볼까요?
SELECT COUNT() 를 실행하고 레코드의 개수를 integer 형태로 반환한다.
⠀
만약 쿼리셋이 이미 캐시되어 있다면 SELECT COUNT(*)를 중복 호출하는 행위를 방지하기 위해 캐시의 길이를 그대로 반환한다.
미리 정의한 가정에 따라 count만 진행할 예정이기 때문에 Queryset이 캐싱 되어 있을 리 만무합니다.
또한 카운트 쿼리를 날리는 것 정도는 까보지 않아도 이미 알고 있었던 내용입니다.
우리가 궁금한 것은 좀 더 세부적인 동작이기 때문에 좀 더 내부로 들어가보도록 하겠습니다.
계속해서 self.query.get_count() 가 구현되어 있는 곳으로 가보겠습니다.
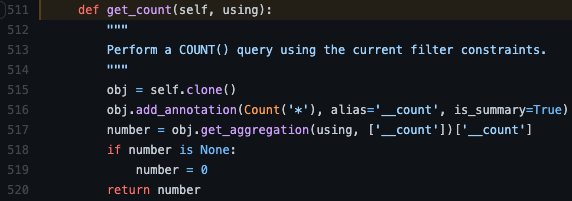
* ( django/db/models/sql/query.py - Queryset.get_count )
Count라는 익숙한 친구가 보이네요...? 맞습니다. aggregate의 Count 클래스입니다.
Count 생성자의 첫 번째 인자로 star(*)를 전달하며, COUNT(*) 쿼리를 만들도록 유도하고 있습니다.
또한 쿼리 결과를 dict 로 반환하는 get_aggregation 의 결과값에 바로 접근하여,
aggregate Count 방식과 다르게 결과 값을 바로 integer 타입으로 반환합니다.
이렇게 Queryset.count는 결국 최종적으로 aggregate Count를 호출하게 되며,
SELECT COUNT(*) FROM table 을 실행하는 것을 알 수 있습니다.
Queryset.aggregate Count
장고에서 제공해주는 aggregate API 입니다.
직접 사용하기 위해서는 아래와 같이 별도 import가 필요합니다.
from django.db.models import Count
aggregate Count를 이용하기 위해선 특정 필드를 반드시 설정해야 합니다.
설정 후에는 Queryset.aggregate에서 전달 받은 aggregate API와 (현재는 Count) 전달 받은 field를 분석 후,
최종적으로 get_aggregation에서 쿼리를 실행하고 결과값을 dict 타입으로 반환합니다.
이렇게 Queryset.aggregate(Count())는 SELECT COUNT(field) FROM table 을 실행하는 것을 알 수 있습니다.
(중요) Quryset.aggregate Count는 쿼리의 캐싱 여부를 확인하지 않는다.
놓치면 안되는 정말 중요한 내용이 하나 더 있습니다.
이번에는 쿼리가 캐싱 되어있지 않다는 가정 하에 포스팅을 작성하여 확인할 기회가 없었지만,
실무에서 모르고 사용했다가는 치명적일 수 있는 내용입니다.
아까 Queryset.count 메서드에
만약 쿼리셋이 이미 캐시되어 있다면 SELECT COUNT(*)를 중복 호출하는 행위를 방지하기 위해 캐시의 길이를 그대로 반환한다.
라고 작성되어있던 주석이 기억나시나요?
맞습니다. count는 그랬는데요, aggregate에는 캐시를 확인하는 로직이 별도로 없습니다.
쿼리가 evaluate 되어 캐시에 모두 저장되어있다 해도, aggregate는 상관하지 않고 매 번 새로운 count 쿼리를 날립니다.
반면, count는 쿼리가 evaluate 되어있으면 새로 쿼리를 날리지 않고 캐시의 길이를 반환합니다.
쿼리가 캐싱된 이후 실시간으로 create 후 다시 count를 해야 하거나 하는 로직을 작성하실 때, 주의하세요 !
(여담) Queryset.aggregate count(*)
✅ 알고 계시는 분들은 알고 계시겠지만 ! aggregate 에서도 Queryset.aggregate(count=Count('*')) 를 이용해서 특정 필드를 지정하지 않고 스타 표현식을 사용할 수 있어요
🚫 단, count=Count('id', filter=Q(id__gte=500)) 처럼 Count에 filter 인자를 넘기는 경우엔 스타를 사용할 수 없으니 주의하세요 !
성능 테스트 📟
대략적으로 설명은 끝났지만, 역시 직접 눈으로 확인해보는게 좋습니다.
테스트 조건은 세팅과 가정에 명시되어있는 그대로 780만 건의 데이터를 조건 없이 모두 count 하였습니다.
아래는 각 케이스 별로 총 5회씩 진행한 후, DB에 HIT된 쿼리와 평균 소요 시간입니다.
len(Queryset)
SELECT id, name, type FROM table
81.42s
Queryset.count
SELECT COUNT(*) FROM table
00.41s
Queryset.aggregate Count
SELECT COUNT(id) FROM table
00.49s
정리 📖
오늘 함께 알아본 내용을 정리해보겠습니다.
- len(Queryset)은 쿼리셋의 길이만 반환하는 것처럼 보이지만, 실제 내부 동작은 그렇지 않습니다. 모든 Queryset을 evaluate 시키기 때문에 사용에 주의하셔야겠습니다.
- Queryset.count의 쿼리는 스타 표현식 Count(*) 으로 실행됩니다
- Queryset.count는 궁극적으로 aggregate Count를 호출하게 됩니다.
- Queryset.count는 Queryset이 캐싱 되어 있으면 COUNT 쿼리를 다시 실행하지 않습니다.
- Queryset.aggregate Count는 필드를 지정해주어야 하지만, 스타 표현식도 이용할 수 있습니다.
- Queryset.aggregate Count는 Queryset의 캐싱 여부와 상관 없이, 매 번 COUNT 쿼리를 실행합니다.
마무리 🙇🏻♂️
이번 글에서는 Queryset 집계 방법에 따른 내부 동작의 차이에 대해 알아보았습니다. 🙆🏻♂️
이 글을 보시는 독자분들 모두 장고를 사용해보셨더라면, 세 방법 중 하나 이상은 사용해보셨으리라 생각됩니다.
아마 Queryset의 개수만 세고자 사용하셨겠지만, 생각보다 내부 로직이 서로 많이 다르니 상황에 따라 시의적절하게 사용하시는 것이 좋을 것 같습니다.
제가 이해를 잘못한 부분이 있다고 생각되시거나 글에 이해가 힘든 부분이 있으시다면, 언제든 지적과 질문 부탁드리겠습니다 !
그럼, 오늘도 즐거운 코딩 데이 보내세요 ! 💻
