이 가이드는 문서 기반 데이터베이스인 MongoDB에 데이터를 저장하고 검색하는 애플리케이션을 구축하기 위해 Spring Data MongoDB를 사용하는 과정을 안내합니다.
MongoDB 설치하기
MongoDB 구성
-
mongod:
mongod는 몽고디비의 핵심 서버 프로세스입니다. 이 프로세스는 실제 데이터베이스 서버를 실행하며, 데이터 저장, 쓰기, 읽기 작업을 처리합니다. 일반적으로 이 프로세스를 시작하여 몽고디비 서버를 구동합니다. -
mongos:
mongos는 몽고DB 샤딩을 관리하는 프로세스로, 샤딩된 환경에서 쿼리를 처리하고 샤드 간의 데이터 라우팅을 담당합니다. 여러 개의mongod인스턴스로 구성된 샤딩된 환경에서 사용됩니다. -
mongo:
mongo는 몽고DB의 기본 콘솔 클라이언트입니다. 몽고디비 서버에 접속하여 쿼리를 실행하거나 관리 작업을 수행할 수 있는 인터랙티브한 콘솔 환경을 제공합니다. -
mongosh:
mongosh는mongo셸의 새로운 버전으로, 더 많은 기능과 개선된 사용자 경험을 제공합니다. 몽고디비 쿼리, 관리 작업, JavaScript 사용 등을 지원합니다.mongosh는 이전 버전의mongo보다 더 많은 기능을 갖추고 있습니다.
샤딩이란?
샤딩(Sharding)은 대량의 데이터를 처리하고 저장하기 위해 데이터베이스를 분할하는 기술입니다. 이 기술은 데이터베이스에 수평적 확장을 가능하게 하여 단일 서버가 아닌 여러 서버에 데이터를 분산하여 저장함으로써 성능과 확장성을 향상시킵니다.
일반적으로 데이터베이스에는 수많은 데이터가 쌓이게 되면서 단일 서버로는 그 처리와 저장이 어려워집니다. 이 때문에 데이터베이스를 여러 대의 서버에 분산하여 저장하고, 쿼리를 분산하여 처리함으로써 데이터베이스의 확장성과 성능을 유지하면서 대규모의 데이터를 효율적으로 관리할 수 있게 됩니다.
샤딩은 데이터를 분할하는 과정에서 특정 기준에 따라 데이터를 나누는데, 이를 통해 각각의 샤드에 저장된 데이터는 서로 다른 서버에 분산 저장됩니다. 이렇게 나뉜 데이터를 쿼리할 때는 샤드 키(Shard Key)를 기반으로 해당 데이터가 어느 샤드에 저장되어 있는지를 찾아내고, 필요한 경우 여러 샤드에 분산된 데이터를 효과적으로 조합하여 결과를 반환합니다.
MongoDB 커뮤니티 에디션 설치
적절한 패키지 관리자를 사용하여 MongoDB Community Edition을 설치하려면 다음 단계를 따르세요.
- 패키지 관리 시스템에서 사용되는 공개 키 가져오기
아직 사용할 수 없는 경우 터미널에서 gnupg 및 curl을 설치합니다.
sudo apt-get install gnupg curlhttps://pgp.mongodb.com/server-7.0.asc 에서 MongoDB 공개 GPG 키를 가져오려면 다음 명령을 실행하십시오.
curl -fsSL https://pgp.mongodb.com/server-7.0.asc | \
sudo gpg -o /usr/share/keyrings/mongodb-server-7.0.gpg \
--dearmor
- MongoDB용 목록 파일 만들기
사용 중인 Ubuntu 버전에 대한 목록 파일/etc/apt/sources.list.d/mongodb-org-7.0.list를 생성합니다.
echo "deb [ arch=amd64,arm64 signed-by=/usr/share/keyrings/mongodb-server-7.0.gpg ] https://repo.mongodb.org/apt/ubuntu jammy/mongodb-org/7.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-7.0.list- 로컬 패키지 데이터베이스 다시 로드
로컬 패키지 데이터베이스를 다시 로드하려면 다음 명령을 실행하십시오.
sudo apt-get update- MongoDB 패키지 설치
MongoDB의 최신 안정 버전이나 MongoDB의 특정 버전을 설치할 수 있습니다.
sudo apt-get install -y mongodb-org
-
디렉터리
패키지 매니저를 통해 설치한 경우, 설치 중에 데이터 디렉터리인/var/lib/mongodb와 로그 디렉터리인/var/log/mongodb가 생성됩니다. -
기본적으로 MongoDB는
mongodb사용자 계정으로 실행됩니다. MongoDB 프로세스를 실행하는 사용자를 변경하는 경우, 이 사용자가 해당 디렉터리에 액세스할 수 있도록 데이터 및 로그 디렉터리의 권한을 수정해야 합니다. -
구성 파일
공식 MongoDB 패키지에는 구성 파일(/etc/mongod.conf)이 포함되어 있습니다. 이러한 설정(데이터 디렉터리 및 로그 디렉터리 지정 등)은 시작할 때 적용됩니다. 즉, MongoDB 인스턴스가 실행 중인 동안 구성 파일을 변경하는 경우, 변경 사항이 적용되려면 인스턴스를 다시 시작해야 합니다. -
절차
시스템에서 MongoDB Community Edition을 실행하는 방법은 다음과 같습니다. 이 지침은 공식mongodb-org패키지를 사용하는 것을 전제로 하며, Ubuntu에서 제공하는 비공식mongodb패키지가 아닌 것으로 가정합니다. -
초기화 시스템
mongod프로세스를 실행하고 관리하기 위해 운영 체제의 내장된 초기화 시스템을 사용합니다. 최근 버전의 Linux는 주로systemctl명령을 사용하는systemd를 사용하고, 이전 버전의 Linux는 주로service명령을 사용하는System V init을 사용하는 경향이 있습니다.
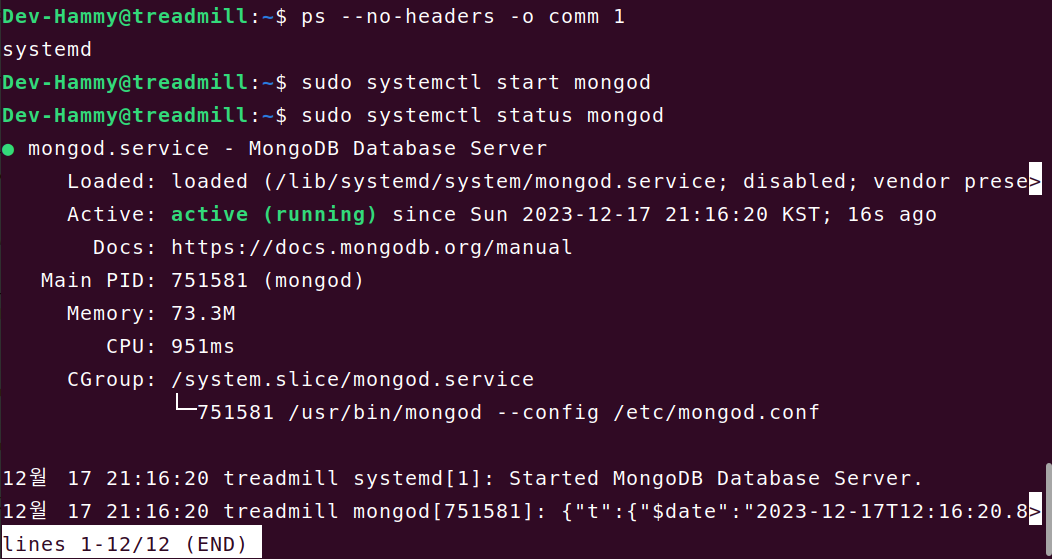
플랫폼이 어떤 초기화 시스템을 사용하는지 확실하지 않은 경우 다음 명령을 실행하십시오.
ps --no-headers -o comm 1그런 다음 결과에 따라 아래에서 적절한 탭을 선택합니다.
systemd- 아래systemd(systemctl)탭을 선택합니다.init- 아래System V Init(service)탭을 선택합니다.
저는 systemd를 따라 설치하겠습니다.
초기화 시스템 사용하기
- 몽고디비 시작하기
몽고디비 프로세스를 시작하려면 다음 명령을 사용하세요:
sudo systemctl start mongod- 몽고디비를 시작할 때 다음과 유사한 오류가 발생하는 경우:
Failed to start mongod.service: Unit mongod.service not found.
아래 명령을 실행하세요:
그런 다음 위의 시작 명령을 다시 실행하세요.sudo systemctl daemon-reload
- 몽고디비가 성공적으로 시작되었는지 확인하세요.
sudo systemctl status mongod- 몽고디비를 시스템 재부팅 후에도 자동으로 시작하도록 하려면 다음 명령을 사용하세요:
sudo systemctl enable mongod
- 몽고디비를 중지할 수도 있습니다:
sudo systemctl stop mongod- 몽고디비 프로세스를 다시 시작하려면 다음 명령을 사용하세요:
sudo systemctl restart mongod몽고디비 프로세스의 상태를 확인하거나 중요한 메시지 및 오류를 확인하려면 /var/log/mongodb/mongod.log 파일의 출력을 확인할 수 있습니다.
- 몽고디비 사용하기
동일한 호스트 머신에서 몽고디비와 mongosh 세션을 시작하세요. mongosh를 실행할 때는 명령줄 옵션이 없이 localhost에서 기본 포트 27017로 실행 중인 몽고디비에 연결할 수 있습니다.
mongoshmongosh를 사용하여 다른 호스트 및/또는 포트에서 실행 중인 몽고디비 인스턴스에 연결하는 등 mongosh를 사용하여 연결하는 방법에 대한 자세한 내용은 mongosh 문서를 참조하세요.
What You Will Build
Spring Data MongoDB를 사용하여 MongoDB 데이터베이스에 Customer POJO(Plain Old Java Objects)를 저장합니다.
Starting with Spring Initializr
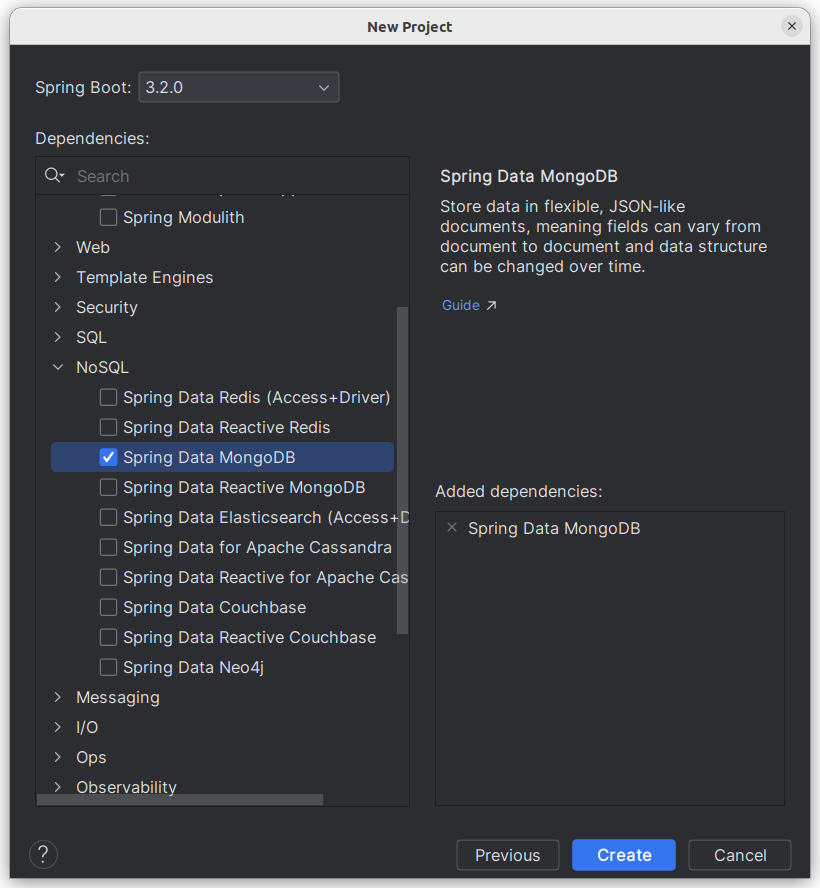
단순 엔터티 정의
MongoDB는 NoSQL 문서 저장소입니다. 이 예에서는 Customer 개체를 저장합니다. 다음 목록은 Customer 클래스(src/main/java/guides/accessingdatamongodb/Customer.java)를 보여줍니다.
package guides.accessingdatamongodb;
import org.springframework.data.annotation.Id;
public class Customer {
@Id
public String id;
public String firstName;
public String lastName;
public Customer() {}
public Customer(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
@Override
public String toString() {
return String.format(
"Customer[id=%s, firstName='%s', lstName='%s']",
id, firstName, lastName);
}
}여기에는 id, firstName 및 lastName의 세 가지 속성이 있는 Customer 클래스가 있습니다. id는 대부분 MongoDB에서 내부용으로 사용됩니다. 또한 새 인스턴스를 생성할 때 엔터티를 채우는 단일 생성자가 있습니다.
이 가이드에서는 간결성을 위해 일반적인 getter와 setter를 생략했습니다.
id는 MongoDB ID의 표준 이름에 적합하므로 Spring Data MongoDB에 태그를 지정하기 위해 특별한 주석이 필요하지 않습니다.
다른 두 속성인 firstName과 lastName은 주석이 추가되지 않은 상태로 유지됩니다. 속성 자체와 동일한 이름을 공유하는 필드에 매핑된 것으로 가정합니다.
편리한 toString() 메소드는 고객에 대한 세부 정보를 인쇄합니다.
MongoDB는 데이터를 컬렉션에 저장합니다. Spring Data MongoDB는
Customer클래스를customer라는 컬렉션에 매핑합니다. 컬렉션 이름을 변경하려면 클래스에 Spring Data MongoDB의@Document주석을 사용할 수 있습니다.
간단한 쿼리 만들기
Spring Data MongoDB는 MongoDB에 데이터를 저장하는 데 중점을 둡니다. 또한 쿼리 파생 기능과 같은 Spring Data Commons 프로젝트의 기능을 상속합니다. 기본적으로 MongoDB의 쿼리 언어를 배울 필요는 없습니다. 몇 가지 메소드를 작성할 수 있으며 쿼리가 자동으로 작성됩니다.
이것이 어떻게 작동하는지 확인하려면 다음 목록(src/main/java/guides/accessingdatamongodb/CustomerRepository.java)에 표시된 대로 Customer 문서를 쿼리하는 저장소 인터페이스를 만듭니다.
package guides.accessingdatamongodb;
import org.springframework.data.mongodb.repository.MongoRepository;
import java.util.List;
public interface CustomerRepository extends MongoRepository<Customer, String> {
public Customer findByFirstName(String firstName);
public List<Customer> findByLastName(String lastName);
}CustomerRepository는 MongoRepository 인터페이스를 확장하고 작동하는 값 및 ID 유형(각각 Customer 및 String)을 연결합니다. 이 인터페이스에는 표준 CRUD 작업(생성, 읽기, 업데이트 및 삭제)을 포함한 많은 작업이 포함되어 있습니다.
메소드 signature를 선언하여 다른 쿼리를 정의할 수 있습니다. 이 경우 기본적으로 Customer 유형의 문서를 찾고 firstName과 일치하는 문서를 찾는 findByFirstName을 추가합니다.
또한 성으로 사람 목록을 찾는 findByLastName도 있습니다.
일반적인 Java 애플리케이션에서는 CustomerRepository를 구현하는 클래스를 작성하고 쿼리를 직접 작성합니다. Spring Data MongoDB를 매우 유용하게 만드는 것은 이 구현을 생성할 필요가 없다는 사실입니다. Spring Data MongoDB는 애플리케이션을 실행할 때 즉시 이를 생성합니다.
이제 이 애플리케이션을 연결하고 어떻게 보이는지 확인할 수 있습니다!
애플리케이션 클래스 생성
Spring Boot는 @SpringBootApplication 클래스의 동일한 패키지(또는 하위 패키지)에 포함된 리포지토리를 자동으로 처리합니다. 등록 프로세스를 더 효과적으로 제어하려면 @EnableMongoRepositories 주석을 사용할 수 있습니다.
기본적으로
@EnableMongoRepositories는 현재 패키지에서 Spring Data의 저장소 인터페이스 중 하나를 확장하는 인터페이스를 검색합니다. 프로젝트 레이아웃에 여러 프로젝트가 있고 저장소를 찾을 수 없는 경우basePackageClasses=MyRepository.class를 사용하여 Spring Data MongoDB에 유형별로 다른 루트 패키지를 스캔하도록 안전하게 지시할 수 있습니다.
Spring Data MongoDB는 MongoTemplate을 사용하여 find* 메소드 뒤에 있는 쿼리를 실행합니다. 더 복잡한 쿼리에 템플릿을 직접 사용할 수 있지만 이 가이드에서는 이에 대해 다루지 않습니다. (Spring Data MongoDB 참조 가이드 참조)
이제 Initializr가 생성한 간단한 클래스를 수정해야 합니다. 일부 데이터를 설정하고 이를 사용하여 출력을 생성해야 합니다. 다음 목록은 완성된 AccessingDataMongodbApplication 클래스(src/main/java/guides/accessingdatamongodb/AccessingDataMongodbApplication.java)를 보여줍니다.
package guides.accessingdatamongodb;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class AccessingDataMongodbApplication implements CommandLineRunner {
@Autowired
private CustomerRepository repository;
public static void main(String[] args) {
SpringApplication.run(AccessingDataMongodbApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
repository.deleteAll();
// save a couple of customers
repository.save(new Customer("Alice", "Smith"));
repository.save(new Customer("Bob", "Smith"));
// fetch all customers
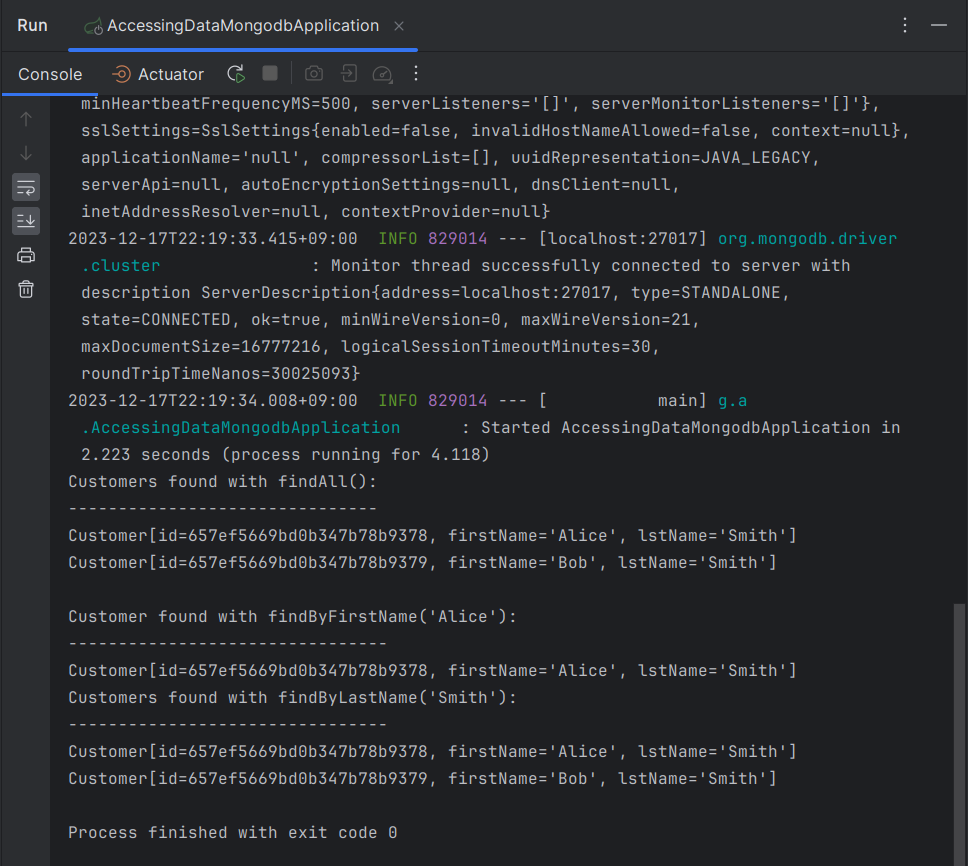
System.out.println("Customers found with findAll():");
System.out.println("-------------------------------");
for (Customer customer : repository.findAll()) {
System.out.println(customer);
}
System.out.println();
// fetch an individual customer
System.out.println("Customer found with findByFirstName('Alice'):");
System.out.println("--------------------------------");
System.out.println(repository.findByFirstName("Alice"));
System.out.println("Customers found with findByLastName('Smith'):");
System.out.println("--------------------------------");
for (Customer customer : repository.findByLastName("Smith")) {
System.out.println(customer);
}
}
}AccessingDataMongodbApplication에는 CustomerRepository의 인스턴스를 자동 연결하는 main() 메서드가 포함되어 있습니다. Spring Data MongoDB는 동적으로 프록시를 생성하고 거기에 주입합니다. 몇 가지 테스트를 통해 CustomerRepository를 사용합니다. 먼저, 몇 가지 Customer 개체를 저장하고 save() 메서드를 시연하고 사용할 일부 데이터를 설정합니다. 다음으로 findAll()을 호출하여 데이터베이스에서 모든 Customer 개체를 가져옵니다. 그런 다음 findByFirstName()을 호출하여 이름으로 단일 Customer를 가져옵니다. 마지막으로 findByLastName()을 호출하여 성이 Smith인 모든 고객을 찾습니다.
기본적으로 Spring Boot는 로컬로 호스팅되는 MongoDB 인스턴스에 연결을 시도합니다. 애플리케이션을 다른 곳에 호스팅된 MongoDB 인스턴스로 지정하는 방법에 대한 자세한 내용은 참조 문서를 읽어보세요.
AccessingDataMongodbApplication은 CommandLineRunner를 구현하므로 Spring Boot가 시작될 때 run 메서드가 자동으로 호출됩니다. 다음과 같은 내용이 표시됩니다(쿼리와 같은 다른 출력도 포함).