
😨 문제 상황
오프라인 매칭 플랫폼 밥풀의 모니터링 서버는 구글 클라우드 VM 위에 구성되어 있습니다.
그러던 어느날, 그동안 잘 접속되던 Grafana 대시보드에 로그인을 시도하니, 500 Internal Server Error 가 응답되었습니다.

당시 화면 캡쳐가 없어서 유사한 이미지를 가져왔습니다. 위 Unknown 메시지 대신 Internal Server Error 메시지와 함께 500 응답이 내려왔습니다.
원인 분석을 위해 GCP를 통한 SSH 접속을 시도했습니다. 그런데! 아래와 같이 SSH 인증 실패 SSH authentication has failed가 발생하면서 연결되지 않는 문제가 발생했습니다.
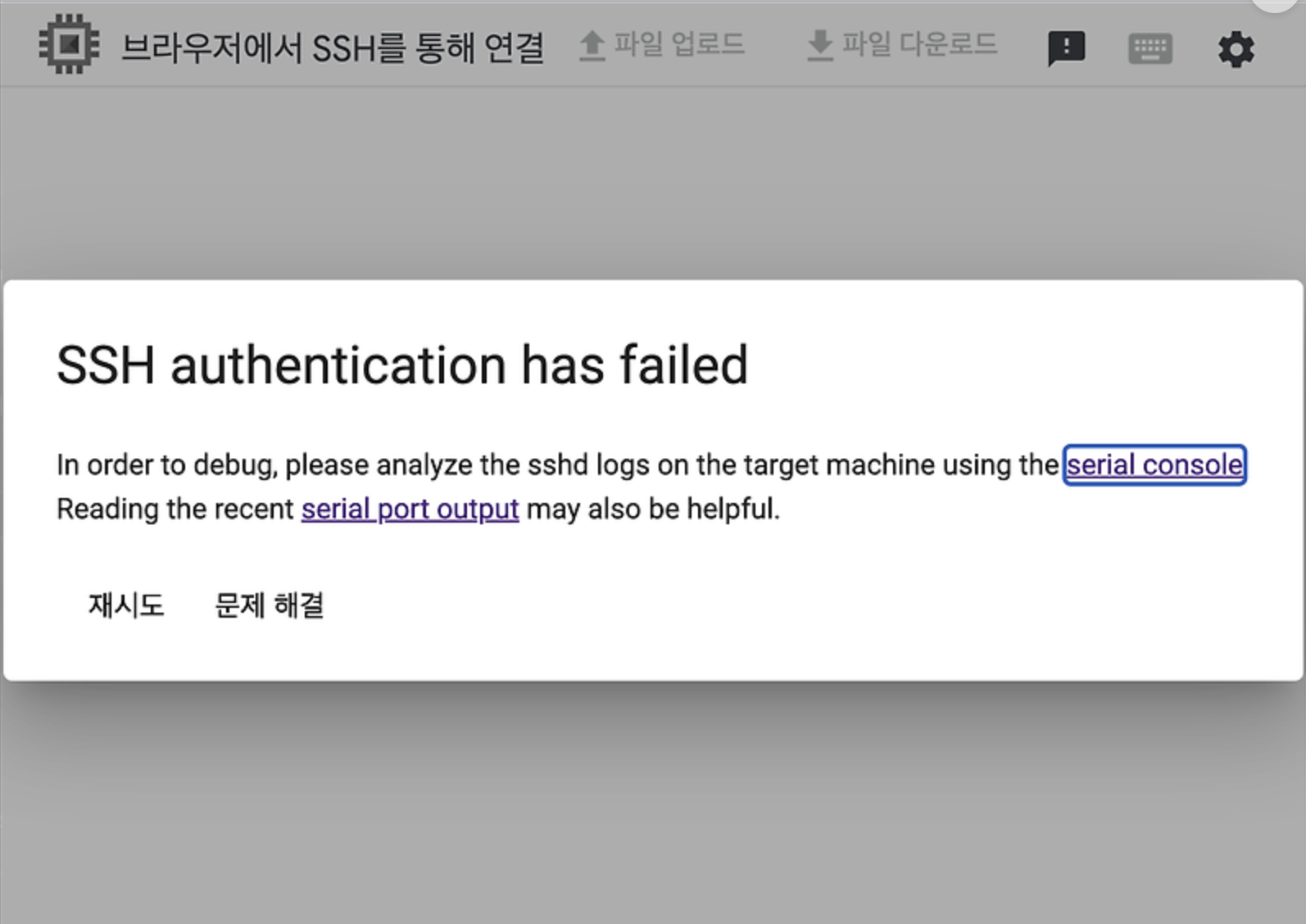
🩺 문제 진단
문제해결 버튼을 클릭하면, VM은 정상 상태라는 응답 뿐 이었습니다. 원인을 파악하기 위해 VM 인스턴스 → 로깅 페이지에 진입했고, 아래와 같이 ssh 키가 만료되었다는 오류 메시지를 확인했습니다.

시도) SSH 키 재생성 및 메타데이터 등록 (해결X)
최초에 SSH 키를 생성할 때, 만료기한을 따로 생성해둔 적이 없었던 것으로 기억하지만, expired 되었다고 하니 새로 생성을 시도했습니다. 키 생성, 설정, 접속 방법은 다음과 같습니다.
1. SSH 키 생성
- 운영체제에 따라 터미널 또는 명령 프롬프트에 다음 명령어를 입력
ssh-keygen -t rsa -f ~/.ssh/[KEY_FILENAME] -C [USERNAME]KEY_FILENAME: 생성할 키 파일의 이름 (예: gcp_key)USERNAME: 사용자 이름 (예: hyun)- 유의) GCP 사용자 이름과, 입력하는 이름이 일치해야 접속이 가능한다는 커뮤니티 글을 검색을 통해 발견했었습니다.
- 비밀번호 입력 요청이 나오면, 선택적으로 입력하거나 그냥 Enter를 눌러 넘어갈 수 있습니다.
- 위 명령어는 두 개의 파일을 생성합니다: [KEY_FILENAME] (비공개 키), [KEY_FILENAME].pub (공개 키)
2. GCP에 SSH 키 등록
- 콘솔 왼쪽 메뉴에서 "컴퓨팅 엔진" > "메타데이터"로 이동합니다.
- "SSH 키" 탭에서 "SSH 키 추가" 버튼을 클릭합니다.
- 로컬에서 생성한 [KEY_FILENAME].pub 파일의 내용을 복사하여 붙여넣습니다.
3. 서버 인스턴스에 접속
- GCP 콘솔에서 해당 인스턴스의 외부 IP 주소를 확인합니다.
- 터미널에서 다음 명령어를 실행합니다:
ssh -i ~/.ssh/[KEY_FILENAME] [USERNAME]@[외부IP]KEY_FILENAME: 앞서 생성한 비공개 키 파일의 경로USERNAME: SSH 키 생성 시 사용한 사용자 이름외부IP: GCP 인스턴스의 외부 IP 주소- 처음 접속 시 호스트 인증 메시지가 나타날 수 있습니다. "yes"를 입력하여 계속 진행합니다.
하지만, 위 방법은 저에게는 해결되지 않은 시도였습니다. 동일하게 SSH 접속 시도에 실패했습니다.
진단 성공) 부팅디스크 용량이 꽉 참
이번에는 직렬포트 출력 페이지에 진입했고, 이 곳에서 해당 문제의 원인을 찾을 수 있었습니다. (직렬포트는 해당하는 VM 인스턴스 후 로그 부분에서 클릭을 통해 확인할 수 있습니다.)
이전에 gcp authentication has failed 또는 gcp ssh Permission denied (publickey) 와 같은 키워드로 검색하는 과정에서 드물게 디스크 용량이 꽉 차서 SSH 접속이 불가했다는 내용을 보았으나, 한 번도 용량이 찼던 경험이 없었고, expired 라는 로그 메시지에 꽂혀, 디스크 용량에 대해서는 차순위로 미뤄뒀었습니다. 그런데 직렬포트 출력 페이지를 확인해보니 아래와 같이 No space left on device 메시지를 확인할 수 있었습니다.

GCP 는 SSH 접속 외에도 gcloud CLI 라는 shell 을 지원합니다. 브라우저 기반의 명령줄 인터페이스로, 구글 클라우드에서 돌아가는 컴퓨팅 리소스에 접근할 수 있습니다. gcloud를 통해서도 접속을 시도하면, 아래 캡쳐와 같이 디스크에 공간이 없어 Login Service 가 정상적으로 동작하지 못한다 는 것을 확인 할 수 있었습니다.
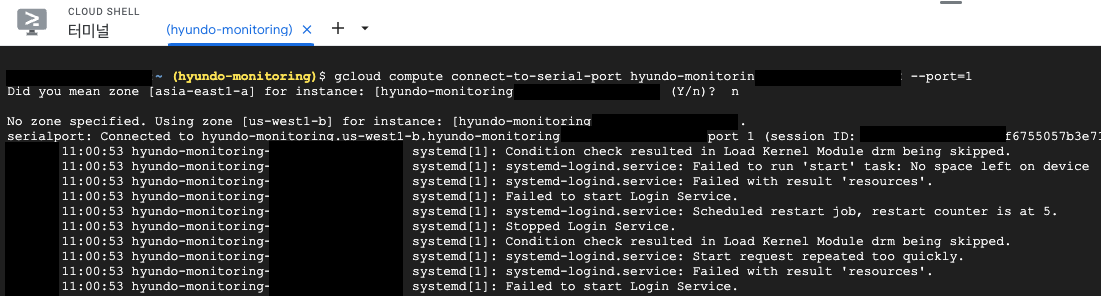
이로써, 약 2시간의 삽질 끝에 드디어 디스크의 용량이 꽉 찼기 때문 이라는 원인을 파악했습니다.
🏃♂️➡️ 시도 : 부팅디스크 용량 늘리기
그저 간단하게 Snapshot을 생성 → 해당 스냅샷으로 새로운 디스크를 생성 → 생성과정에서 기존 디스크보다 큰 용량을 가진 디스크를 생성 → VM에 새로 생성한 디스크를 연결 과정을 통해 VM에 정상 접속되는 행복회로를 머릿속에서 그렸으나.. 쉽게 해결되지 않았습니다.
블로그를 참고해 제가 수행한 과정은 다음과 같습니다. 참고한 링크는 이곳(GCP 부팅 디스크 용량 늘리기 : 스냅샷 활용) 입니다.
-
스냅샷 생성
- GCP 콘솔 왼쪽 메뉴에서 "Compute Engine" > "스냅샷"
- "스냅샷 만들기" 버튼을 클릭합니다.
- 이름: 원하는 이름 입력
- 소스 디스크: 현재 VM 인스턴스의 디스크 선택
- 유형: 스냅샷
- 위치: VM 인스턴스와 동일한 리전 선택
- 생성
-
새로운 부팅 디스크 생성
- "Compute Engine" > "디스크"
- "디스크 만들기" 버튼을 클릭합니다.
- 이름: 원하는 이름 입력
- 위치 및 리전: 기존 디스크와 동일하게 설정
- 디스크 소스 유형: "스냅샷" 선택
- 소스 스냅샷: 이전 단계에서 생성한 스냅샷 선택
- 디스크 유형: 필요에 따라 선택 (예: 표준 영구 디스크)
- 크기: 기존 디스크 크기보다 큰 크기로 설정 (예: 30GB -> 40GB)
- 생성
-
VM 인스턴스에 새 부팅 디스크 연결
- "Compute Engine" > "VM 인스턴스"
- 대상 VM 인스턴스를 선택하고 "중지" 버튼을 클릭하여 인스턴스를 중지합니다.
- "수정" > "부팅 디스크 분리" >"부팅 디스크 구성"
- "기존 디스크" 탭을 선택하고, 새로 생성한 디스크를 선택합니다.
- "선택" 버튼을 클릭합니다.
- 수정 완료
-
VM 인스턴스 재시작 및 확인
- 해당 인스턴스를 "시작/재개"
- SSH 접속 시도.
시도 결과
인스턴스 수정에서 디스크 사이즈를 기존 30G 에서 40G 으로 업데이트 하고 VM을 재시작했으나, 동일하게 SSH 접속이 불가했습니다.
원인은, 자동 파티션 확장을 위한 여유 디스크 공간이 없었기 때문입니다. 즉, 디스크의 크기를 늘려준 후, VM을 재시작할 경우 자동 파티션 확장을 위해 서비스가 동작해야 합니다. 그런데, 해당 서비스가 동작하는 과정에서 필요한 로그파일을 생성하거나 파일 쓰기 작업이 수행되기 위한 여유 공간이 조금도 없었기에 자동확장이 되지 않았음을 추정할 수 있었습니다.
그러니, 여유 공간이 조금이라도 있었다면 파티션 자동확장이 되어 위 과정을 끝으로 문제가 해결되었을 것입니다.
🌱 해결) 임시 VM에 Mount해서 용량 줄이기
전체 해결 과정을 크게 4단계로 요약하자면 다음과 같습니다.
1. 용량 늘린 부팅디스크 만들기
2. 임시 VM 만들어, 추가 디스크로 붙이기
3. Mount 하여 대용량 파일 줄이기
4. 원래 VM에 재연결 하기
위 단계들을
-
문제가 있는 VM 중지
-
원래VM에서 부팅 디스크를 분리
- GCP 콘솔에서 "Compute Engine" > "VM 인스턴스"로 이동.
- 문제가 있는 VM을 클릭 → 상세 페이지 → "디스크" 섹션의 부팅 디스크 영역.
- 디스크 옆의 더보기 메뉴(세 개의 점)를 클릭하고 "분리"를 선택.
-
디스크 크기 증가시키기
- "Compute Engine" → "디스크" → 분리한 디스크.
- 상단의 "디스크 크기 조정" → 원래 크기보다 큰 크기(예: 50GB)를 입력 후 완료.
-
임시 VM 생성
- "Compute Engine" > "VM 인스턴스" > "인스턴스 만들기"로 이동.
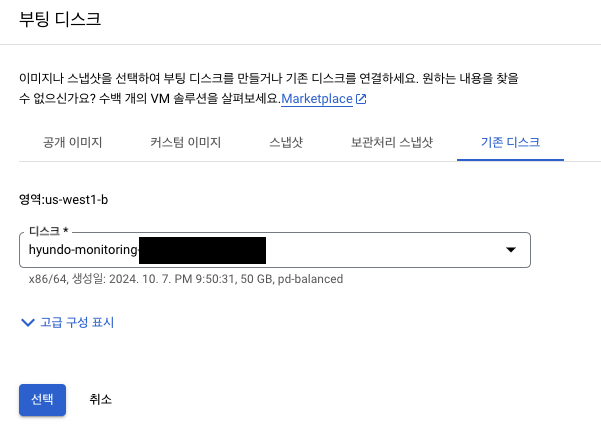
- 새로운 임시 VM을 생성, 크기가 증가된 문제의 디스크를 이 VM에 추가 디스크로 연결.
- 임시 VM의 이름을 입력합니다(예: temp-instance).
- 리전과 영역을 원래 VM과 동일하게 선택.
- 임시 VM 사양: Ubuntu 20.04, 10GB 부팅 디스크
- "새 디스크 추가"를 클릭합니다.
- "기존 디스크"를 선택하고, 크기를 조정한 문제의 디스크를 찾아 선택합니다.
- "모드" : "읽기/쓰기"(default)로 설정합니다. 설정을 완료하면 아래 이미지와 같이 표시됩니다.
- "만들기" 버튼을 클릭하여 임시 VM을 생성합니다.
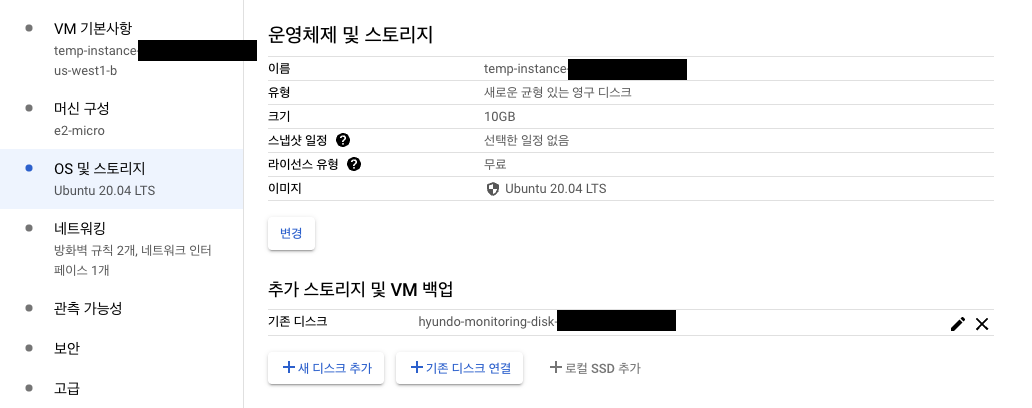
-
디스크 확인
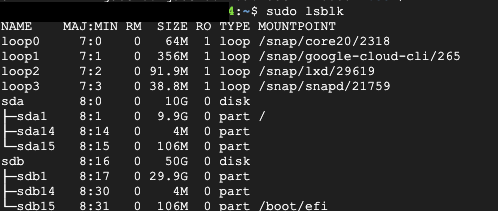
- 마운트 하기
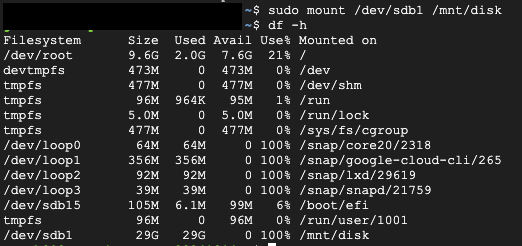
- 큰 파일/폴더 식별
du -sh /mnt/disk/*/mnt/disk/var폴더의 크기가 가장 컸다.
sudo du -h /mnt/disk/var | sort -rh | head -n 20 명령어로 /mnt/disk/var 디렉토리와 그 하위 디렉토리의 크기를 계산하고, 크기 순으로 정렬한 후 상위 20개를 보여줍니다.

- 로그 파일 용량 줄이기
sudo truncate -s 0 /mnt/disk/var/lib/docker/containers/9d18351b34b0ba2a9fa8c56e3be6e3defb08a7c891dd6c4f550f721c57fb24de/*-json.log- 마운트된 디스크에서 가장 큰 공간을 차지하는 파일들을 확인했습니다.
- Docker 관련 파일, 특히 컨테이너 로그 파일이 가장 많은 공간(약 19GB)을 차지하고 있었습니다.
- 불필요한 로그 파일을 정리하여 상당한 디스크 공간을 확보했습니다.
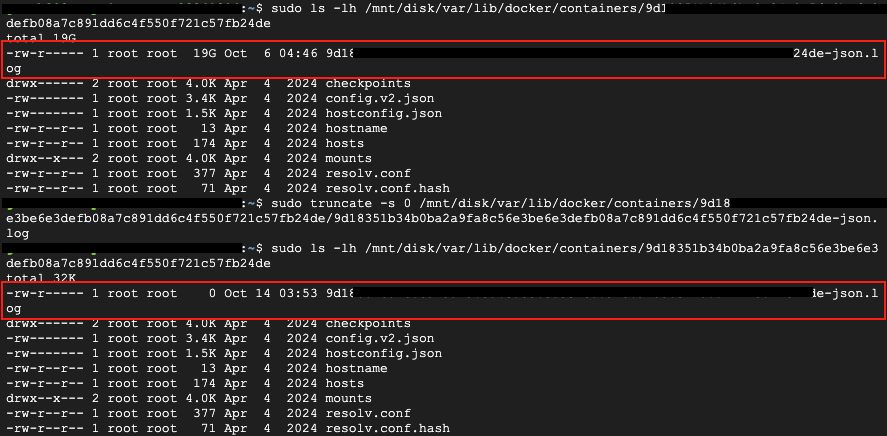
umount /mnt/newdisk
마운트 해제
- 임시 VM 중지, 디스크 분리
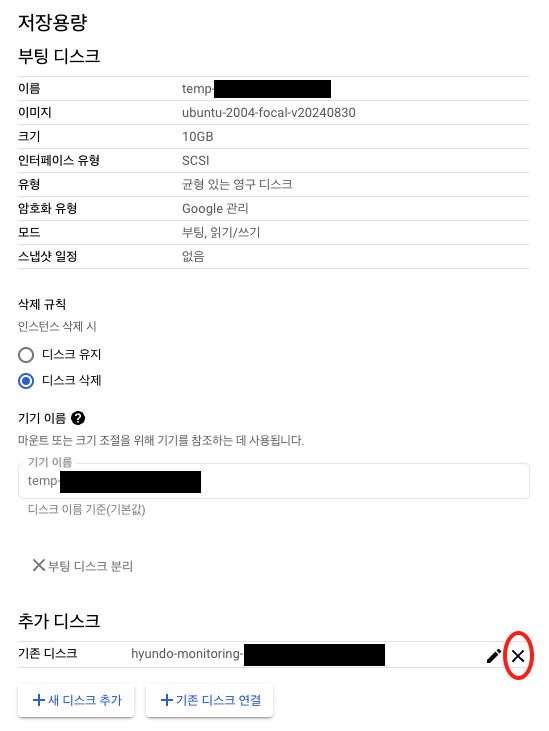
- 원래 VM에 디스크 연결
- 정리 작업 후, 임시 VM에서 디스크를 분리하고 원래 VM에 다시 연결했습니다.
- 원래 VM SSH 접속
- 원래 VM을 재시작하고 SSH 접속을 시도했습니다.
- 성공적으로 접속되었으며, df -h 명령어로 디스크 사용량을 확인했습니다.
- 용량이 성공적으로 늘어났는지 확인하기
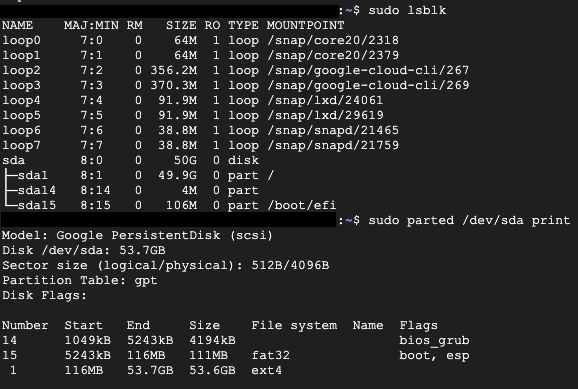
- 자동으로 파티션이 확장되었다.
- 임시 VM 삭제
💉 추가 조치
도커 로그 파일의 용량이 끝없이 늘어났던 이번 이슈를 재발방지 하기 위해 Docker 데몬 설정을 적용했습니다. 모든 컨테이너에 대해 기본 설정을 적용하려면, etc/docker/daemon.json 파일을 수정해야 합니다. 이 json-file 도커 로깅 드라이버가 기본적으로 최대 용량이 정해져있지 않기 때문에 만약 이번 모니터링 서버와 같이 로그가 많이 남는 서비스라면 저장 공간이 부족해지는 일이 발생할 수도 있습니다. 다음 명령어를 통해 daemon.json 파일 수정을 위한 vi 에디터를 실행합니다.
sudo vi /etc/docker/daemon.json아래와 같은 설정을 적용해주었습니다. max-size를 통해 로그 파일 크기가 5 기가에 도달하였을 때, 로그는 종료되지 않고 lotation 됩니다. 즉, 새로운 로그는 기존 파일을 덮어쓰지 않고 새 파일에 기록됩니다. 또한 max-file을 통해 파일의 개수가 이미 3개인 경우 가장 오래된 로그파일이 삭제되고 새 파일이 생성됩니다.
{
"log-driver": "json-file",
"log-opts": {
"max-size": "5G",
"max-file": "3"
}
}설정이 완료되면 Docker 데몬 재시작을 해야 합니다.
이 방식으로 로그는 계속 기록되며, 지정된 크기와 파일 수를 유지합니다. 따라서 애플리케이션은 중단 없이 계속 실행되고 로그도 계속 생성됩니다. 단, 오래된 로그는 자동으로 삭제되므로 중요한 로그는 별도로 백업하는 것이 좋을 것 같다고 판단했습니다.
🙆🏻♂️ 끝맺음
이 과정을 통해 디스크 공간 부족 문제를 해결하고 VM의 정상적인 작동을 복구할 수 있었습니다.
향후 유사한 문제를 방지하기 위해 정기적인 로그 관리와 디스크 사용량 모니터링의 중요성을 인식하게 되었습니다.
참고한 링크
