
📌 발단 : AWS 과금 발생
밥풀 프로젝트의 인프라 작업에 대한 책임감에 의해 프로젝트를 진행하는 동안 주기적으로 AWS Billings 서비스를 팔로잉 하고 있었습니다. 그러던 어느날 Simple Storage Service에서 0.01 $ 가 과금 예정임을 발견했습니다. 얼마 되지 않는 비용도 지출이기 때문에 빠른 시일내에 해결해야 하는 이슈라 판단했습니다.
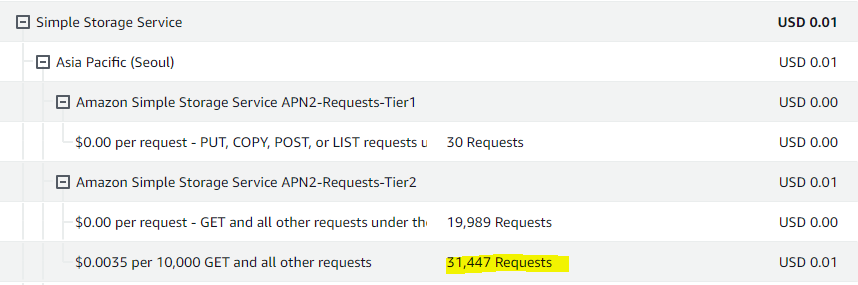
상세 내역을 펼쳐보니 과도하게 많은 요청수가 집계되어 있었습니다. 프로젝트를 홍보를 통해 사용자를 모집하긴 했었으나 대다수가 팀원들의 지인이었으며 사용자가 100명 미만이었습니다. 그럼에도 운영서버를 가동한지 2주일 만에 AWS Free Tier에서 무료로 제공해주는 20,000건의 요청을 모두 소진 후 추가로 약 30,000건의 요청이 집계된 것은 문제가 있음을 인지했습니다.
요청의 정체는 봇 이었습니다.
원인을 파악하기 위해 Proxy Server 역할을 하고 있는 Nginx 도커 컨테이너의 log 를 출력해본 결과 정말 다양한 요청들이 쌓이고 있었습니다. 문제가 되는 요청의 약 80% 이상이 GET /** 요청이었으며, 아래와 같이 .env, /Core/Skin/Login.aspx 등의 정적자원을 취득해가려는 시도가 과반수 이상이었습니다.
(IP 세부정보를 조회해본 결과 파리/독일/중국 등 다양한 국가에서 요청되는 점, 그리고 서울에 위치한 구글 검색엔진에서도 요청을 전송했다는 점이 신기했습니다.)

구글링 해본 결과 이들의 정체는 Bot 이었습니다. 이들이 요청을 전송하는 이유는 웹을 스캔하고, 검색엔진 노출을 위한 것으로 매우 흔한 상황이라고 합니다. 하지만, 만일 자원이 공개적으로 액세스 가능했더라면 보안상 위험할 수 있다고 합니다. 뿐만 아니라 서버에 부하를 일으켜 일반 사용자에게 부정적 경험을 제공할 수 있고 저의 상황처럼 예상하지 못한 비용이 발생할 수 있습니다.
 |
|---|
| 이미지 출처 : maliciousscary_requests_to_my_backend_server |
구조 파악 및 대안 탐색
아키텍처의 어떤 영역에 대안을 적용할 수 있을지 파악해야 봇 요청을 차단하는 적절한 방법을 찾을 수 있을 것이라 생각해, 먼저 밥풀 프로젝트의 아키텍처를 다시 살펴보았습니다. 밥풀 프로젝트의 클라우드 아키텍처는 아래와 같습니다.
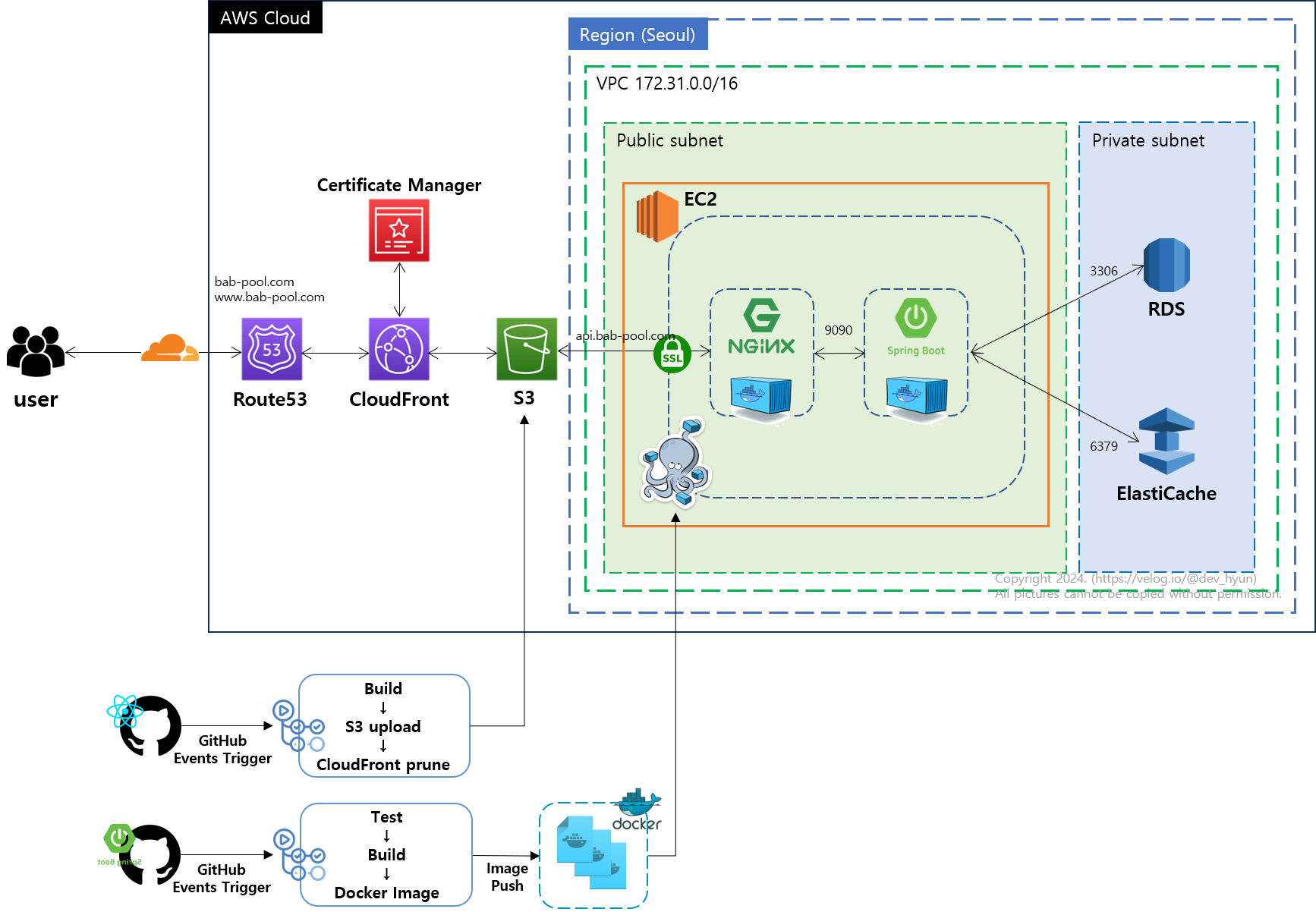
클라이언트가 요청할 수 있는 도메인은 프론트 영역인 루트 도메인 https://example.com 또는 백엔드 API 서버인 서브 도메인 https://api.example.com 입니다. 도메인의 구입은 CloudFlare에서 했으나, AWS 프리티어 계정을 사용하는 동안 ACM을 비롯해 여러 AWS 서비스들을 프로젝트에 활용해볼 목적으로 네임서버를 Route53에 두고 있습니다.
클라이언트가 프론트 도메인으로 페이지를 요청하면 Route53, CloudFront를 거쳐 S3으로부터 React로 빌드된 정적 자원을 응답받습니다. 백엔드 API 요청은 Route53에서 EC2, Nginx를 거쳐 Spring 서버로 부터 응답받습니다.
아키텍처를 살펴보아 크게 (1) 두 도메인의 공통적인 진입점에서 또는 (2) 프론트/백엔드 각 진입점에서 원하지 않는 요청을 제한할 수 있지 않을까 예상했습니다. 어느 부분에 도구를 적용해야 할지 범위를 정했으니, 어떤 도구가 주어질 수 있는지 살펴보았습니다.
🤖🙅🏻♀️ CloudFlare으로 Front 방어
최종적으로는 CloudFlare에서 제공하는 서비스를 적용했습니다만, 다른 대안들은 무엇이 있고 CloudFlare를 선택하게 된 과정을 함께 기록했습니다.
대안 1) AWS WAF Bot Control
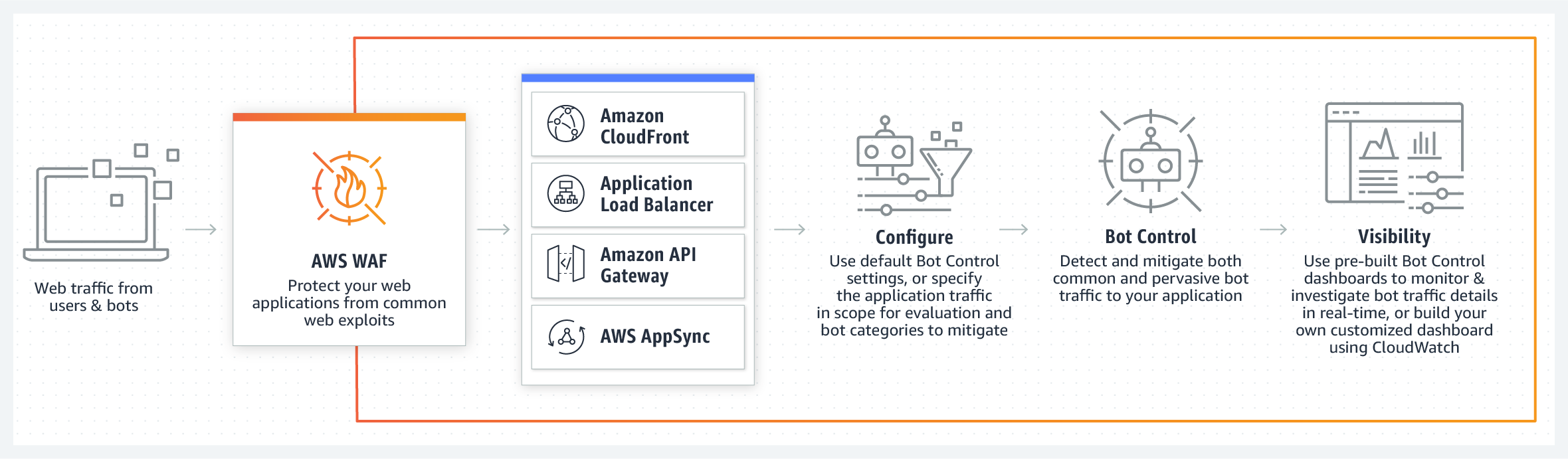
아키텍처 리마인드 과정에서 알 수 있듯 밥풀 프로젝트는 다수의 AWS 서비스를 사용하고 있습니다. 따라서 봇을 방어하는 솔루션도 AWS 에서 제공하는 서비스를 활용하는 대안을 가장 먼저 떠올렸고, WAF Bot Control (공식 홈페이지 링크) 서비스를 찾았습니다.
 |
|---|
| 이미지 출처 : https://aws.amazon.com/ko/waf/features/bot-control/ |
공식 홈페이지 링크의 설명에 의하면 WAF Bot Control 서비스는 봇 트래픽에 대한 제어를 손쉽게 차단할 수 있으며, 검색 엔진과 같은 일부 봇을 허용할 수도 있습니다. 두 도메인의 공통적인 진입점에 해당 서비스를 도입하면 가장 이상적이라 생각되었습니다. 다만 현재 아키텍처 구성 상 Route53 은 트래픽을 리다이렉트 해주는 역할을 하기 때문에 WAF를 이곳에 적용할 수는 없습니다. 서비스 개요를 읽어보면 CloudFront, Load Balancer, API Gateway 그리고 AppSync에 적용할 수 있습니다. 따라서 API Gateway 를 밥풀 아키텍처에 추가하는 방향을 고려했습니다.
하지만, 문제는 서비스 비용 입니다. 프리티어 계정 기준으로 알려진 봇에 대해 월 1,000만 건의 요청을 무료로 처리할 수 있으나, 이를 적용하기 위해 Web ACL 을 먼저 생성해야 하고, 해당 서비스는 월 5$ 비용이 부과됩니다.
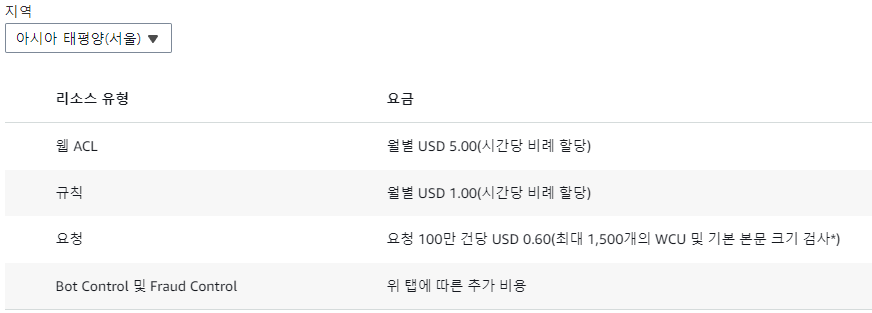 |
|---|
| 이미지 출처 : https://aws.amazon.com/ko/waf/pricing/ |
현재 봇으로 인해 발생되는 비용이 월 0.01 $ 인데 500배 비용 상승의 AWS WAF 서비스를 적용하는 것은 적합해 보이지 않았습니다. 만일 밥풀 서비스가 수익을 창출할 만큼 규모가 있거나, 다른 대안을 발견하지 못했다면 WAF Bot Control 적용을 긍정적으로 생각했을 것입니다.
대안 2) AWS CloudFront 지리적 접근 제한
'aws bot control', 'bot prevent' 등의 키워드로 더 검색해본 결과 비용이 발생하지 않는(프리티어 기준) 서비스 CloudFront Geo Restriction 지리적 제한 을 발견했습니다. (AWS AmazonCloudFront georestrictions 공식문서 링크)
CloudFront는 일반적으로 사용자의 지리적 위치와 상관없이 클라이언트가 요청한 정적 자원을 응답하는데, 해당 기능을 활성화 할 경우 허용목록/거부목록을 통해 요청을 전송한 클라이언트의 국가에 따라 HTTP 403 Forbidden 상태 코드를 응답할 수 있습니다.
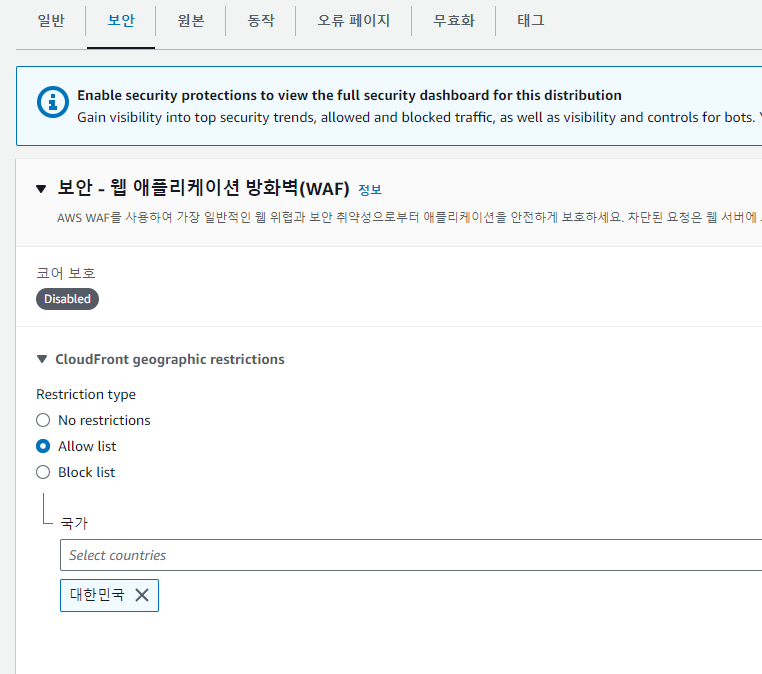
설정하는 방법은 위 캡처와 같이 CloudFront 대시보드 → 배포 → 보안 탭에서 허용 국가 목록 또는 거부 국가 목록을 설정하면 쉽고 빠르게 적용 됩니다.
해당 기능이 검색엔진, 크롤링 Bot 등의 요청을 제한하는데 특화된 기능은 아니지만 다음과 같은 이유로 문제를 해결하기 위한 하나의 대안으로써는 충분하다고 판단합니다.
- 대부분의 봇 요청이 해외 IP 에서 접근했으며
- 간편하게 설정 가능하며
- 추가 비용이 발생하지 않고
- 밥풀 플랫폼은 국내 사용자만 타겟팅 하여 서비스하기 때문
그럼에도 해당 방법을 최종 선택하지 않았던 이유는 (1) 오직 bot에 의한 요청만 제한하고 싶었으며 (2) 밥풀 플랫폼을 포함해 조직이 서비스를 제공하는 범위가 해외로 확장될 경우 해당 기능을 사용하지 못해 결국 동일한 문제를 다시 해결해야 했기 때문입니다.
선택) CloudFlare UnderAttack Mode
AWS에서 제공하는 서비스에서는 조건(무료 + 봇 차단에 특화)에 부합하는 기능은 존재하지 않았습니다. 대신 bot 요청을 제한하는 방법을 찾는 사람들이 보편적으로 선택하는 방법으로 CloudFlare의 UnderAttack Mode 서비스를 적용하고 있음을 알게 되었습니다.
👩🏻💻 적용 결과 Before → 日 100여건
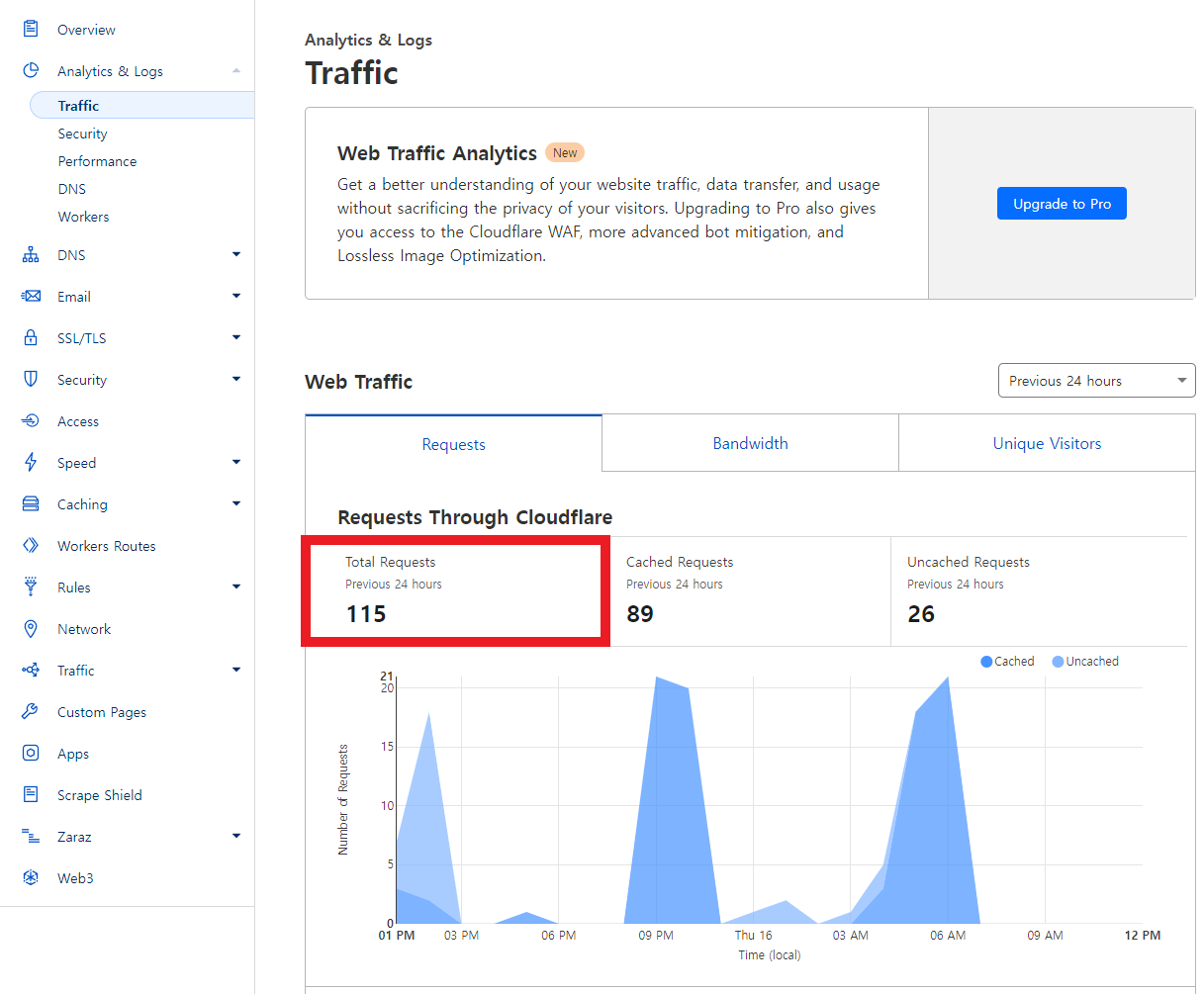 |  |
|---|---|
| 지난 24시간 요청 수 약 100여건 | 차단한 봇 요청 약 90여건 |
가장 최근 릴리즈가 배포된지 시간이 꽤 흐른 이후라서 평소보다 적은 요청 수와 봇 차단 수가 집계되는 것을 감안하여도, 일 요청 약 2,000건 에서 100 여건으로 개선된 것은 목표를 충분히 달성했다고 판단할 수 있었습니다.
🤖🙅🏻♂️ Nginx 설정으로 Backend 방어
프론트 영역에는 CloudFlare UnderAttack Mode 만 적용되어 있고, 백엔드는 별도의 크롤링 봇 차단 설정이 적용되어 있지 않은 상태에서의 지난 24시간 동안의 요청 수는 약 300 건 입니다(좌측 캡처 참고). 모니터링 서버를 구축한 이후로 일일 요청 수 추이는 우측 캡처와 같이 하루 약 300~400 건의 요청이 집계된 것을 확인할 수 있습니다. (특이점으로 2000건이 넘는 봇 요청이 집계된 몇몇 건은 제외.)
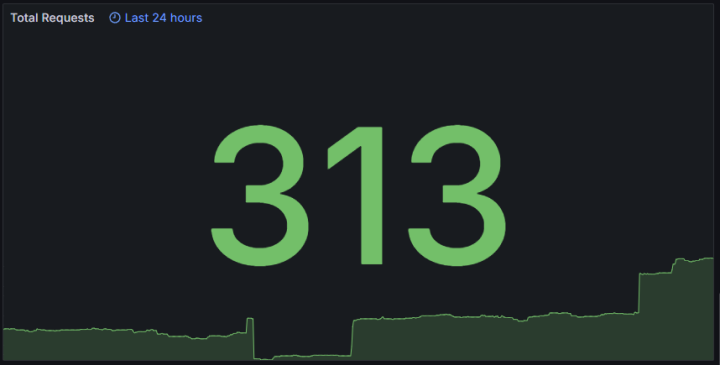 | 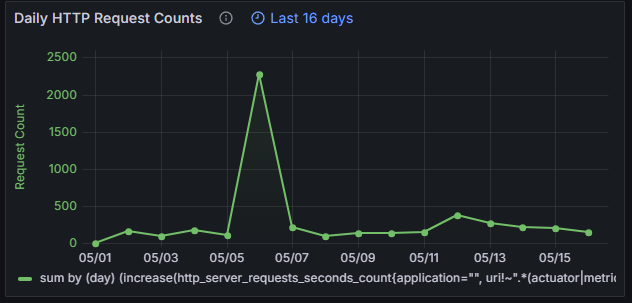 |
|---|---|
| 지난 24시간 동안의 요청 수 | 일일 요청 수 추이 |
이전 문단에서 밥풀 프로젝트의 아키텍처를 살펴봤을 때, 백엔드 서버로 전달된 요청은 Proxy 서버 역할을 수행중인 Nginx가 가장 먼저 맞닿게 됩니다. 따라서 크롤링 봇을 차단하는 방법으로 Nginx에 몇몇 설정을 적용하여 해결할 수 있을 것이라 판단해 아래와 같은 대안들을 찾게 되었습니다.
대안 1) IP 기반 지리적 차단
앞서 AWS에서 제공하는 IP 기반 지리적 접근 제한 서비스와 유사한 동작을 Nginx 에도 적용할 수 있습니다. 아래 두 가지 방법이 있지만, 역시 국내에서만 서비스하는 기업이 아니라면 적절하지 않은 방법이라고 판단했습니다. 따라서 아래와 같은 방법이 있다는 것만 알아두고, 프로젝트에는 적용 하지 않기로 결정했습니다.
CIDR 활용 특정 국가 IP 대역폭 차단
Nginx에서 특정 IP 접근 금지 시키기 (With Url 문자열 접근 막기)
geoip 모듈 활용
--with-http_geoip_module : 지리적 위치를 알아내는 GeoIP모듈인 ngx_http_geoip_module 모듈을 포함합니다.libgeoip라이브러리 필요합니다.
Module ngx_http_geoip_module
Installing GeoIP module for latest NGINX for Docker
http {
geoip_country /usr/share/GeoIP/GeoIP.dat;
map $geoip_country_code $allowed_country {
default no;
KR yes;
}
server {
location / {
if ($allowed_country = no) {
return 403;
}
}
}
출처: https://archijude.tistory.com/528 [글을 잠깐 혼자 써봤던 진성 프로그래머:티스토리]대안 2) robot.txt 파일 작성하기
robots.txt 는 크롤링 봇, 검색엔진 등에게 접근 가능/불가능한 경로를 안내하기 위한 파일 입니다. 파일을 구성하는 속성은 크게 User-agent, Allow, Disallow 그리고 Sitemap 네 가지가 있으며 각 역할은 아래와 같습니다.
 |
|---|
| 이미지 출처 : https://seo.tbwakorea.com/blog/robots-txt-complete-guide/ |
이에 기반하여 구글 애드센스, 페이스북, 구글, 네이버, 빙, 야후, 다음 검색엔진을 제외하고 모두 제한하도록 다음과 같이 파일을 작성했습니다. 작성한 파일은 웹 사이트의 root 디렉토리에 매핑하여 https://example.com/robots.txt 요청 시 해당 파일을 응답하도록 설정합니다. 정상적인 봇은 원칙적으로는 작성된 안내에 따라 동작할 것입니다.
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /
User-agent: Mediapartners-Google
Allow: /
User-agent: Yeti
Allow: /
User-agent: Bingbot
Allow: /
User-agent: facebot
Allow: /
User-agent: Slurp
Allow: /
User-agent: Daum
Allow: /적용 1) 특정 IP 차단하기
geo
http_x_forward_for
remote_addr
클라이언트의 HTTP 요청은 Gateway, LoadBalancer, Proxy 등의 서버들을 경유하여 밥풀 서버에 도착할 수 있습니다. 따라서 $remote_addr 에는 경유한 서버의 마지막 IP가 저장되어 있습니다.
이때, 최초의 클라이언트 IP는 $x-forwarded-for 헤더에 저장됩니다. (참고 링크 : https://wiki.tistory.com/entry/nginx-ingress-ip-config)
http_x_forward_for 를 사용하려 했으나, "-" 처럼 세팅 되어 있던데?
적용 2) 특정 키워드 차단하기
map $request_uri $bad_uri {
default 0;
~*(wp-includes|wlwmanifest|xmlrpc|wordpress|administrator|wp-admin|wp-login|owa|a2billing) 1;
~*(fgt_lang|flu|stalker_portal|streaming|system_api|exporttool|ecp|vendor|LogService|invoke|phpinfo) 1;
~*(Autodiscover|console|eval-stdin|staging|magento|demo|rss|root|mifs|git|graphql|sidekiq|c99|GponForm) 1;
~*(header-rollup-554|fckeditor|ajax|misc|plugins|execute-solution|wp-content|php|telescope) 1;
~*(idx_config|DS_Store|nginx|wp-json|ads|humans|exec|level|monitoring|configprops|balancer) 1;
~*(meta-data|web_shell_cmd|latest|remote|_asterisk|bash|Bind|binding|appxz|bankCheck|GetAllGameCategory) 1;
~*(exchangerateuserconfig|exchange_article|kline_week|anquan|dns-query|nsepa_setup|java_script|gemini-iptv) 1;
~*(j_spring_security_check|wps|cgi|asmx|HNAP1|sdk|evox) 1;
~*(_ignition|alvzpxkr|ALFA_DATA|wp-plain) 1;
~*(ldap|jndi|dns|securityscan|rmi|ldaps|iiop|corba|nds|nis) 1; # log4j
}elfinlas 님의 블로그를 참고해 설정파일을 생성했습니다. 모니터링 서버에서 actuator uri 를 사용하고 있어 제거하고, 로그에서 확인할 수 있는 일부 키워드를 추가했습니다. (참고 블로그 링크)
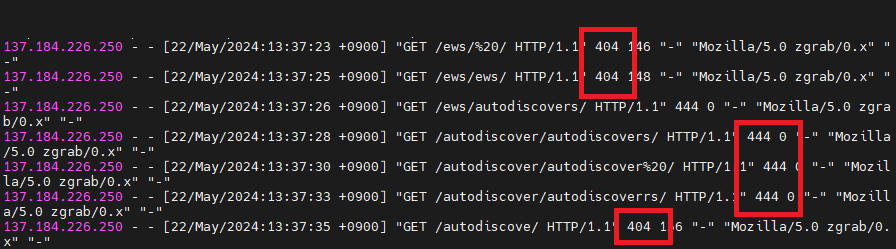
설정이 올바르게 적용되어 특정 키워드를 감지하면 444 상태코드를 응답했음을 확인할 수 있습니다. 그러나 100% 만족스럽지는 않습니다. 처음 2개의 GET 요청과 마지막 GET 요청에 대해서는 키워드가 필터링 되지 않아 결국 서버에게 전달되었기 때문입니다. 이에 nginx 설정을 다음과 같이 수정했습니다.
nginx 수정된 app.conf백엔드 서버가 허용하는 /api/** 를 포함한 URI 패턴을 제외하고 모두 차단되도록 수정했습니다.
적용 3) 불분명한 User Agent 차단하기
nginx 도커 볼륨 마운트 되어 있는 경로에 nginx-bots-prevention.conf 파일을 생성.
/home/사용자명/nginx/nginx-bots-prevention.conf
# Rate limiting settings
limit_req_zone $binary_remote_addr zone=one:10m rate=10r/s;
# Deny known bad user agents
map $http_user_agent $blocked {
default 0;
~*(?:bot|crawl|spider|baidu|yandex|bing|msnbot|curl|wget|python) 1;
}
적용 테스트
설정이 올바르게 적용되었는지 테스트 했습니다. VPN 확장 프로그램을 통해 IP를 178.xxx.xxx.xx 으로 변경 후 밥풀 백엔드 도메인으로 GET 요청을 전송했습니다.
 |
|---|
 |
Nginx 로그를 확인하니 HTTP 444 응답이 의도대로 내려왔으며, 제한하지 않은 IP에 대해서는 200 status code가 응답되는 것을 확인했습니다.
Trouble Shooting) [emerg] invalid condition
Nginx 설정 과정 중 다음과 같은 에러를 경험했습니다.
[emerg] 7#7: invalid condition "$bad_ip" in /etc/nginx/conf.d/custom.conf:8
nginx: [emerg] invalid condition "$bad_ip" in /etc/nginx/conf.d/custom.conf:81) include 위치는 http scope에
2) if 문 내부에 표현식은 1개만
# 잘못된 구문
if ($bad_ip || $bad_bot || $bad_uri) {
return 444;
}
# 수정된 구문
if ($bad_ip) {
return 444;
}
if ($bad_bot) {
return 444;
}
if ($bad_uri) {
return 444;
}3) 컨테이너를 stop, up 하는 것이 아니라, nginx를 reload 하기
docker exec <nginx-container-name-or-id> nginx -s reload4) nginx 명령어
#
nginx -T
# conf 문법 검사
nginx -t
# nginx 재실행
nginx -s reload👨🏻💻 적용 결과 Before → 日 10여건
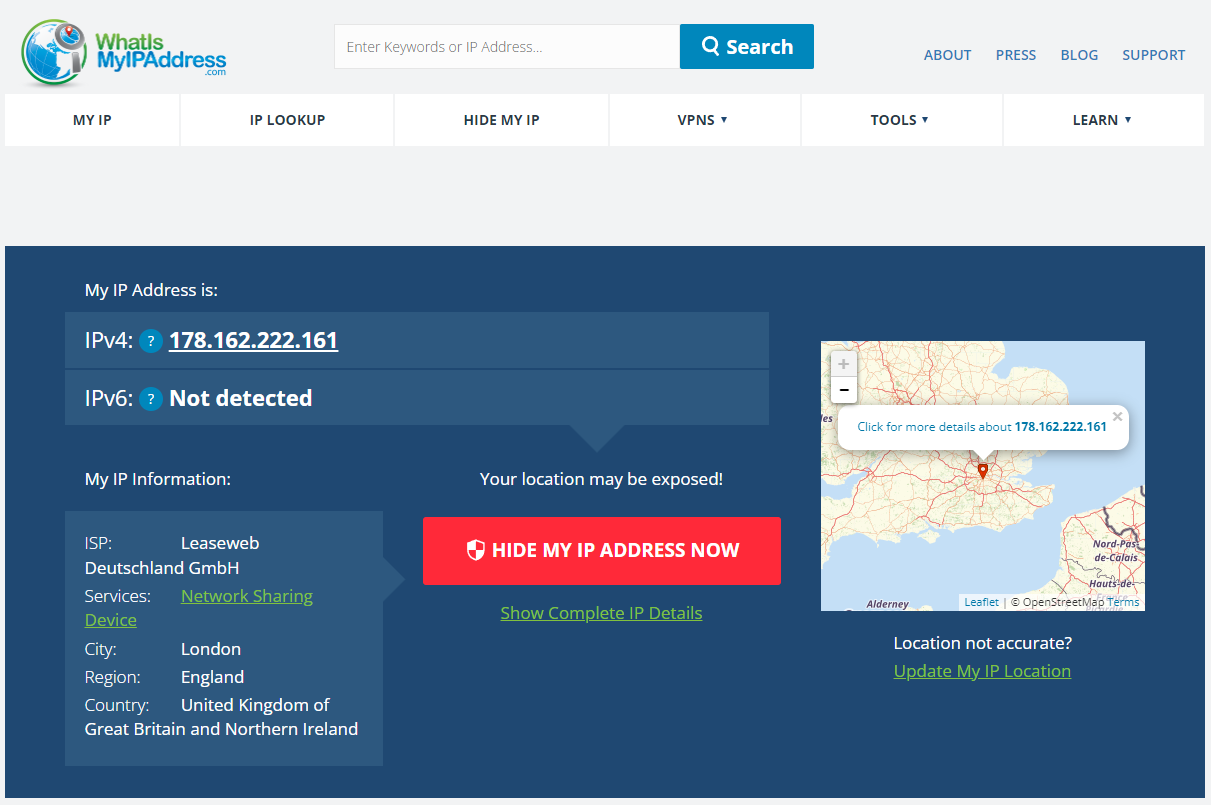
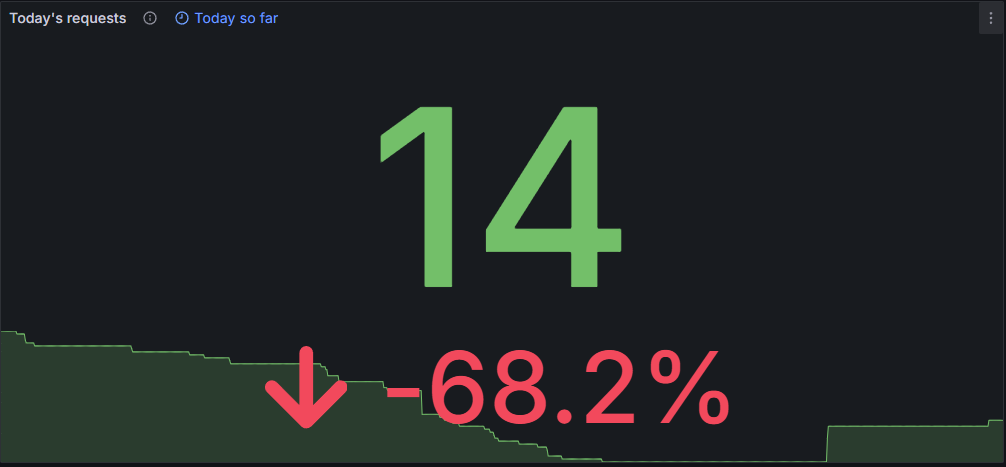 | 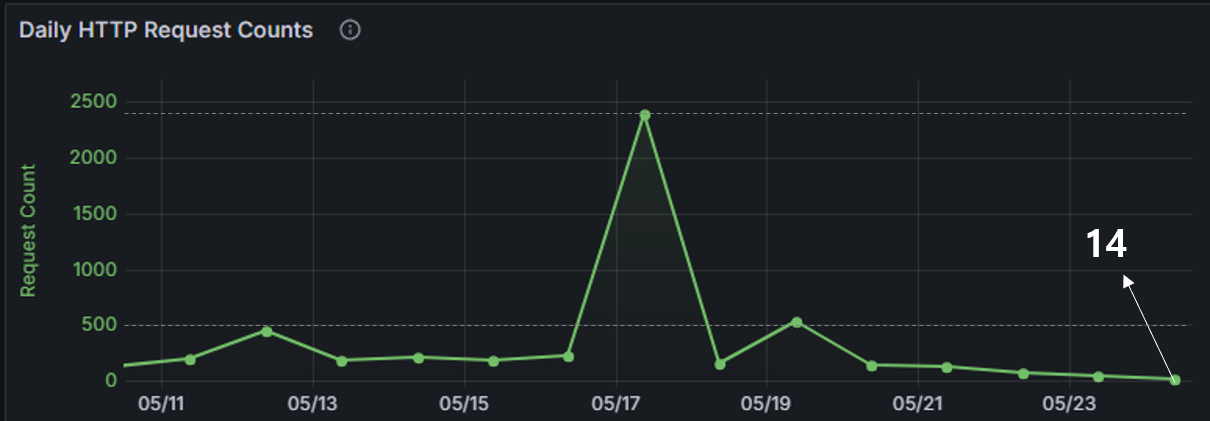 |
|---|---|
| 지난 24시간 요청 수 | 일일 요청 수 추이 |
봇 차단을 위한 Nginx 설정을 마치고 경과를 지켜본 결과, 백엔드 서버로의 올바르지 않은 요청 이슈가 성공적으로 개선되었음을 확인할 수 있었습니다. 평균 300건 이상의 봇 요청이 10건 미만으로 줄어들었습니다.(14건 중 9건은 실 사용자의 요청 수) 이렇게 적용을 마치고 나니 마치 모기에 대한 농담처럼 밥풀 서버에 관심을 주던 봇들이 사라지니 뭔가 허전한 마음이 들기도 합니다. 🤣
추가 개선의 여지는 남아있습니다. 백엔드 영역에서 Spring 서버로 전달되는 올바르지 않은 요청은 Nginx 설정에 의해 모두 차단되지만, Nginx는 여전히 봇들에 대한 트래픽을 부담해야하는 것은 동일합니다. 이 문제를 해결하기 위해 인프라 관점에서 EC2 서버 앞에 게이트웨이 또는 라우터를 배치하여 서버로 향하는 원치 않는 트래픽을 차단하는 것이 필요해 보였습니다만, 문제 해결 범위를 벗어났으며 목표로 하는 만큼 개선이 되었다고 판단하여 이는 다음 번 과제로 남겨두기로 결정했습니다.
