
개요
밥풀 서비스는 밥 약속 신청을 통해 관심사와 목표를 공유하는 사람들과 일대일로 대화 할 수 있도록 기회를 만드는 플랫폼 입니다. 3주가 되지 않는 MVP 개발 기간에는 성능을 고려할 여력 없이 우선 빠른 구현에 집중했습니다. 별도의 유지보수 기간에 사용자들이 가장 자주 호출하는 프로필 페이징 API의 응답속도가 상대적으로 느리다는 것을 파악하고, 쿼리를 개선하는 것을 목표로 작업했습니다. 하지만 그 과정이 순탄치 못했습니다.
더미데이터 삽입 부터, 쿼리의 실행계획을 분석하고, 다양한 인덱스를 적용해가며 목표로 하는 쿼리 응답시간(1초 이내)이 도출될 때 까지 2~3주가 소요되었습니다. Real MySQL 8.0 서적, 검색, 유료 해결 서비스(크몽), LLM 등 다양한 루트를 활용해가며 성공적으로 쿼리를 개선한 고군분투의 과정을 기록했습니다.
🎯 슬로우 쿼리 확인하기
먼저, 문제되는 슬로우 쿼리를 확인하기 위해서는, 수행되는 쿼리에 대한 통계 데이터가 쌓이도록 MySQL 설정이 필요합니다. 설정을 하지 않을 경우 슬로우쿼리를 확인하는 조회 쿼리가 정상적으로 동작하지 않거나, 아래와 같은 오류를 만나볼 수 있습니다.
You do not have the SUPER privilege and binary logging is enabled
(you *might* want to use the less safe log_bin_trust_function_creators variable)이는 AWS RDS 생성시 기본 설정으로 시스템 액세스(SUPER 권한)를 제공하지 않기 때문입니다. 바이너리 로깅을 켜면 log_bin_trust_function_creators를 DB 인스턴스의 사용자 지정 데이터베이스(DB) 파라미터 그룹에서 true로 설정해야 했습니다. 설정 방법은 아래 이미지와 같습니다. (참고 링크 : AWS 공식문서)

설정을 완료했다면 아래의 쿼리를 활용해 슬로우 쿼리를 조회할 수 있습니다.
## 성능 개선 대상 식별
SELECT DIGEST_TEXT AS query,
IF(SUM_NO_GOOD_INDEX_USED > 0 OR SUM_NO_INDEX_USED > 0, '*', '') AS full_scan,
COUNT_STAR AS exec_count,
SUM_ERRORS AS err_count,
SUM_WARNINGS AS warn_count,
SEC_TO_TIME(SUM_TIMER_WAIT/1000000000000) AS exec_time_total,
SEC_TO_TIME(MAX_TIMER_WAIT/1000000000000) AS exec_time_max,
SEC_TO_TIME(AVG_TIMER_WAIT/1000000000000) AS exec_time_avg_ms,
SUM_ROWS_SENT AS rows_sent,
ROUND(SUM_ROWS_SENT / COUNT_STAR) AS rows_sent_avg, SUM_ROWS_EXAMINED AS rows_scanned,
DIGEST AS digest
FROM performance_schema.events_statements_summary_by_digest
WHERE SCHEMA_NAME = 'babpool_pro_v1_db'
AND COUNT_STAR > 50
AND DIGEST_TEXT LIKE 'SELECT%' -- 조회 쿼리만 한정해 식별하고 싶은 경우
AND DIGEST_TEXT NOT LIKE 'SELECT @@SESSION%'
AND DIGEST_TEXT NOT LIKE 'SELECT QUERY%'
ORDER BY AVG_TIMER_WAIT DESC;- 데이터베이스에서 실행된 모든 쿼리에 대한 포괄적인 성능 정보를 제공합니다.
- 실행 통계:
exec_count: 쿼리의 총 실행 횟수,err_count: 오류 발생 횟수,warn_count: 경고 발생 횟수
- 시간 관련 메트릭 :
exec_time_total: 총 실행 시간,exec_time_max: 최대 실행 시간,exec_time_avg_ms: 평균 실행 시간
- 데이터 처리량 :
rows_sent: 총 반환된 행 수,rows_sent_avg: 쿼리당 평균 반환 행 수,rows_scanned: 총 검사된 행 수
쿼리 개선 대상의 당위성 찾기
서비스 특성 상, 사용자들이 가장 많이 요청하는 데이터는 프로필 페이징을 위한 조회 결과일 것입니다. 그러나 이를 위해 4개의 테이블이 JOIN 되어야 하기 때문에 매우 낮은 성능을 보일 것이라 예측했습니다. 현재 운영 DB 에서 일정 횟수 이상 호출 되었으며 슬로우 쿼리를 찾기 위해 위의 식별쿼리를 수행했을 때, 출력된 결과는 이러한 예측을 증명했습니다.
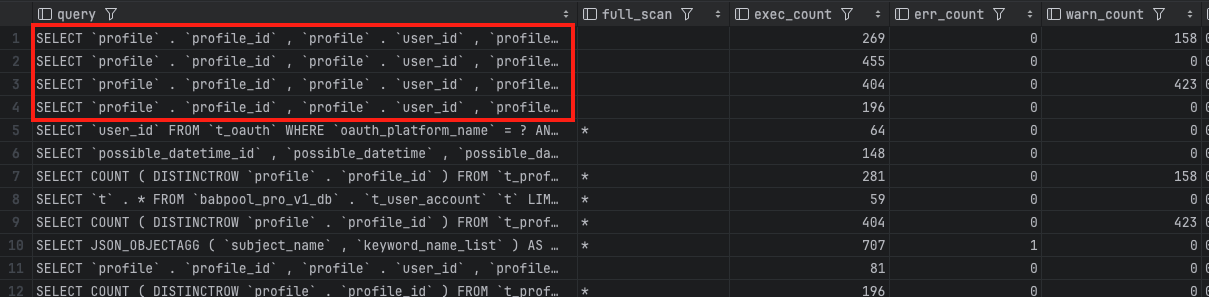
해당 4개의 쿼리는 각각 "특정 키워드와 특정 사용자 등급을 가진 프로필만 선택", "모든 활성 프로필을 선택 (가장 광범위한 결과)", "특정 키워드를 가진 모든 활성 프로필을 선택", "특정 사용자 등급을 가진 모든 활성 프로필을 선택" 으로 모두 프로필 페이징을 처리하기 위한 쿼리 입니다. 이로써 해당 프로필 페이징 쿼리가 전체 쿼리 중 가장 많이 호출되며, 평균 쿼리 수행 시간이 가장 느린 슬로우 쿼리 임을 확인 했습니다.
개선할 대상을 찾았으니, 개선을 위해 필요한 환경을 세팅하고 유의미한 성능비교를 위해 더미데이터를 삽입했습니다.
🔗 도커 MySQL 컨테이너으로 테스트 환경 세팅하기
해당 프로젝트는 AWS Freetier RDS를 사용하고 있어, 로컬 환경 처럼 멀티 코어나 빵빵한 램을 할당해 이들을 실행할 수 있는 환경이 못 됩니다. 때문에, 로컬에서 수행하는 성능 테스트 및 쿼리 개선 작업을 운영 환경과 유사하게 조성할 필요가 있었습니다. t2.micro 와 완벽하게 동일한 환경은 아니지만 가능한 유사하게 MySQL 도커 컨테이너를 메모리 1GB, CPU 1코어로 제한하여 실행하기로 결정했습니다.
| 제한하려는 자원 | 명령어 | 단위 |
|---|---|---|
| 메모리 | --memory | m(megabyte), g(gigabyte) |
| swap 메모리 | --memory-swap | m(megabyte), g(gigabyte) |
| CPU(상대적) | --cpu-shares | 1024(1cpu) |
| CPU(절대적) | --cpus | |
| CPU (호스트에 CPU가 여러 개 있을 때) | --cpuset-cpu | 사용하고 싶은 특정 cpu (0부터 시작합니다.) |
| 디스크 I/O 속도 | --device-write-bps, --device-read-bps | kb, mb, gb |
참고 링크 : docker 컨테이너 자원 할당 제한
1) 이미지 다운로드
$ docker pull mysql:latest2) MySQL 컨테이너 실행(자원 할당 제한)
$ docker run --name {컨테이너명} \
-e MYSQL_ROOT_PASSWORD={root패스워드} \
-d \
--cpus=1 \
--cpuset-cpus="0" \
--memory=1g \
--memory-swap=2g
-p 3305:3306 \
--device-write-bps /dev/sda:10mb
--device-read-bps /dev/sda:10mb
mysql--cpu-shares는 다른 컨테이너의 상태에 따라 실제 CPU 사용량이 변할 수 있지만,--cpus는 항상 일정한 최대 CPU 사용량을 보장합니다. 따라서 저는--cpus옵션을 사용했습니다.- 메모리 스왑 설정은 "시스템의 메모리 크기가 2 GB 까지라면 그 크기의 2 배의 swap 공간을 권고"하고 있음을 고려하여 2기가로 설정했습니다. (참고 링크 : 레드헷 공식 문서)
3) 컨테이너 리소스 사용량 통계 확인
docker stats {컨테이너명}
-- 출력 >
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
93ff05457d44 mysql-cpu1-memory1 0.48% 388.4MiB / 1GiB 37.93% 1.02kB / 0B 0B / 0B 37📦 더미데이터 Batch Insert
더미데이터 삽입 방법 결정
유의미한 성능 비교를 위해서 테이블당 최소 100만 건의 데이터를 삽입하고자 했습니다. 세 가지 대안이 떠올랐습니다.
(1) mockaroo 사이트에서 .sql 파일 생성
mockaroo서비스의 경우 무료 계정에서 sql 파일 당 1000건의 행까지만 생성 가능하기 때문에 가장 먼저 제외되었습니다.
(2) 프로시저 작성
- 예를들어 다음과 같이 프로시저를 작성해 원하는 만큼 행의 크기를 지정하고, 간편하게 쿼리를 삽입할 수 있습니다.
- 그러나, 보다 복잡한 관계(테이블 간의 개연성, 균등하게 분포된 데이터)를 고려하며 데이터를 삽입하기 위해서는 프로시저 보다 애플리케이션을 구현하는 것이 더욱 용이할 것으로 판단했습니다.
DELIMITER //
CREATE PROCEDURE InsertTestData(IN numRows INT)
BEGIN
DECLARE i INT;
SET i = 1;
START TRANSACTION;
WHILE i <= numRows DO
INSERT INTO t_possible_date (profile_id, possible_date) VALUES (i, DATE_ADD(CURDATE(), INTERVAL i DAY));
INSERT INTO t_possible_time (possible_date_id, possible_time_start) VALUES (i, i);
INSERT INTO t_appointment (appointment_receiver_id, possible_time_id, appointment_status) VALUES (i, i, 'PENDING');
SET i = i + 1;
END WHILE;
COMMIT;
END //
DELIMITER ;
CALL InsertTestData(1000000); -- 100만 건 삽입(3) 애플리케이션 구현
페이징 쿼리 개선을 테스트하기 위해 필요한 테이블은 4개 이며, 테이블마다 최소 100만 건의 데이터를 삽입해야 하는데, 반복문을 사용해 매 행마다 삽입 쿼리를 수행하는 것은 매우 비효율적이라고 판단했습니다. 따라서, Batch Insert를 사용하기로 결정했습니다.
해당 프로젝트는
MyBatis사용하기 때문에JPA Entity의PK Generate startegy가IDENTITY일 때Batch Insert를 비활성화 하는 문제에 대해 다루지 않겠습니다. 만약 해당 이슈를 겪는다면JdbcTemplate클래스의batchUpdate()메서드를 오버라이딩하여 해결할 수 있습니다.
JDBC Batch Insert
Batch Insert란 밑에 예제 쿼리와 같이 insert rows 여러 개를 연결해서 한 번에 입력하는 작업입니다. 가령 1000개의 삽입 문으로 구성된 배치가 있는 경우 데이터베이스는 여전히 1000개의 문을 각각 개별적으로 구문 분석, 컴파일 및 실행해야 합니다. 반면 일괄 삽입(Batch Insert)을 사용하면 여러 삽입 문을 단일 SQL 문으로 결합합니다.
# 개별 삽입 쿼리
INSERT INTO table VALUES (1, "hello");
INSERT INTO table VALUES (2, "world");
INSERT INTO table VALUES (3, "!");
# Batch Insert
INSERT INTO table VALUES (1, "hello"), (2, "world"), (3, "!");정리하자면 Batch Insert 는 다음과 같은 특징을 가지고 있습니다.
- 쿼리를 메모리에 저장하였다가 한번에 쿼리를 보내는 형태이다.
- 여러 작업을 일괄 처리로 함께 실행한다.
- 하나의 트랜잭션으로 묶인다.
- 데이터 베이스 호출 횟수가 줄어든다.
주의할 점은, MySQL에서 Bulk Insert를 사용하려면, DB URL 설정에 rewriteBatchedStatements=true 파라미터를 추가해야 합니다. true로 설정하지 않으면 Insert 쿼리가 여전히 단건으로 수행됩니다.
spring:
datasource:
url: jdbc:mysql://localhost:3306/batch_test?&rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999
driver-class-name: com.mysql.cj.jdbc.DriverrewriteBatchedStatements- 파라미터의 기본값은 false으로, 이 상태에서는 배치 작업을 수행해도 각 INSERT 문이 개별적으로 실행됩니다.
postfileSQL=true- Driver에 전송하는 쿼리를 출력합니다.
logger=Slf4JLogger- Driver에서 쿼리 출력 시 사용할 로거를 설정합니다.
maxQuerySizeToLog=999999- 출력할 쿼리 길이. MySQL 드라이버는 기본값이 0으로 지정되어 있어 값을 설정하지 않을 경우 쿼리가 출력되지 않습니다.
(참고 링크 : Spring JDBC를 사용하여 Batch Insert 수행하기)
JDBC Batch Insert 코드 작성
PrepareStatement를 이용하여 addBatch를 사용하는 방식입니다.
public void batchInsertUserAccount(int numberOfRows) {
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(INSERT_USER_ACCOUNT_SQL)) {
connection.setAutoCommit(false);
Random random = new Random();
for (int i = 0; i < numberOfRows; i++) {
preparedStatement.setLong(1, i + 100000000000000001L);
preparedStatement.setString(2, "user" + i + "@example.com");
preparedStatement.setString(3, STATUSES[random.nextInt(STATUSES.length)]);
preparedStatement.setString(4, "ROLE_USER");
preparedStatement.setString(5, GRADES[random.nextInt(GRADES.length)]);
preparedStatement.setString(6, "nickname" + i);
preparedStatement.setDate(7, Date.valueOf(java.time.LocalDate.now()));
preparedStatement.setDate(8, Date.valueOf(LocalDateTime.now().plusMinutes(random.nextInt(43200)).toLocalDate()));
preparedStatement.addBatch();
preparedStatement.clearParameters();
if (i % BATCH_SIZE == 0) {
preparedStatement.executeBatch();
connection.commit();
log.info("i 번째 배치 실행! : {}, Committed.", i);
}
}
preparedStatement.executeBatch();
connection.commit();
System.out.println("t_user_account 테이블 배치 삽입 성공!");
} catch (SQLException e) {
log.error("배치 삽입 중 오류 발생", e);
try {
connection.rollback();
} catch (SQLException rollbackEx) {
log.error("롤백 중 오류 발생", rollbackEx);
}
}
}MySQL Dump Export/Import
공들여 삽입한 원본 더미 데이터를 백업해두기 위해 덤프 파일을 생성할 필요가 있었습니다.
터미널을 열어 다음 명령어들을 통해 덤프파일을 생성하거나 덤프파일로 데이터를 가져올 수 있습니다.
데이터 Export
# Docker MySQL의 sh 접속
docker exec -it [Container-ID] sh
# MySQL 데이터 Dump
mysqldump -uroot -p [Database-Name] > /tmp/[File-Name].sql
# 해당 경로에 생성 확인
ls -al /tmp
# Docker Container 밖으로 파일 복사
docker cp [Container-ID]:/tmp/[File-Name].sql [PC의 저장할 경로]데이터 Import
# PC의 SQL File을 Docker 안으로 복사
docker cp [PC의 SQL 파일 경로] [Container-ID]:/tmp
# Docker MySQL의 sh 접속
docker exec -it [Container-ID] sh
# MySQL 데이터 Import
mysql -uroot -p [Database-Name] < /tmp/[File-Name].sql🤝🏻 요구사항 분석
프로필 리스트 페이지 구현을 위한 기획자의 요구사항은 다음과 같습니다
-
필요 데이터:
- 프로필 식별 값, 사용자 식별 값, 프로필 이미지 URL, 프로필 자기소개, 프로필 수정일자, 해당 사용자의 관심 키워드 집합
-
필터 조건:
- 1개 이상의 관심 키워드 중 하나라도 만족하는 프로필
- 1개 이상의 사용자 학년 중 하나라도 만족하는 프로필
-
정렬 기준: 최근 프로필 수정일자 순
이러한 요구사항을 충족하기 위해 다음 4개의 테이블(t_profile, t_user_account, t_m_user_keyword, t_keyword)을 JOIN하는 복잡한 쿼리가 필요했으며, 다음 사항들을 고려해야 했습니다.
- 4개 테이블의 INNER JOIN
- 서브쿼리를 통한 관심 키워드 정보 추출
- WHERE 절에서 키워드 ID와 사용자 학년 필터링
- GROUP BY를 통한 중복 제거
- ORDER BY로 최근 수정일자 순 정렬
- LIMIT OFFSET을 이용한 페이지네이션
SELECT profile.profile_id, profile.user_id, profile.profile_image_url, profile.profile_intro, profile.profile_contents,
profile.profile_modify_date,
(
SELECT GROUP_CONCAT(k.keyword_name)
FROM t_m_user_keyword muk
INNER JOIN t_keyword k ON muk.keyword_id = k.keyword_id
WHERE muk.user_id = profile.user_id
GROUP BY muk.user_id
) AS keyword_info, account.user_grade, account.user_nick_name
FROM t_profile as profile
INNER JOIN t_user_account account ON profile.user_id = account.user_id
INNER JOIN t_m_user_keyword muk ON profile.user_id = muk.user_id
INNER JOIN t_keyword k ON muk.keyword_id = k.keyword_id
WHERE muk.keyword_id IN
(598340246278506499, 598340246278506500, 598340246278506501, 598340246278506502,
598340246282702823, 598340246282702824, 598340246282702825, 598340246282702826,
598340246282702827, 598340246286893150, 598340246286893151,
598340246286893152, 598340246286893153, 598340246291091010, 598340246299478613)
AND account.user_grade IN
('FIRST_GRADE', 'SECOND_GRADE', 'THIRD_GRADE', 'FOURTH_GRADE', 'GRADUATE')
AND profile.profile_active_flag = 1
GROUP BY profile.profile_id
ORDER BY profile.profile_modify_date DESC
LIMIT 10 OFFSET 0;성능 이슈 발견
데이터 규모가 작을 때는 크게 와닿지 않았으나, 많은 데이터를 삽입한 환경(100만 ~ 200만 건)에서 심각한 성능 저하를 확인할 수 있었습니다:
- 첫 페이지 응답 시간: 약 25-27초
- 10페이지 응답 시간: 약 4분 10초대
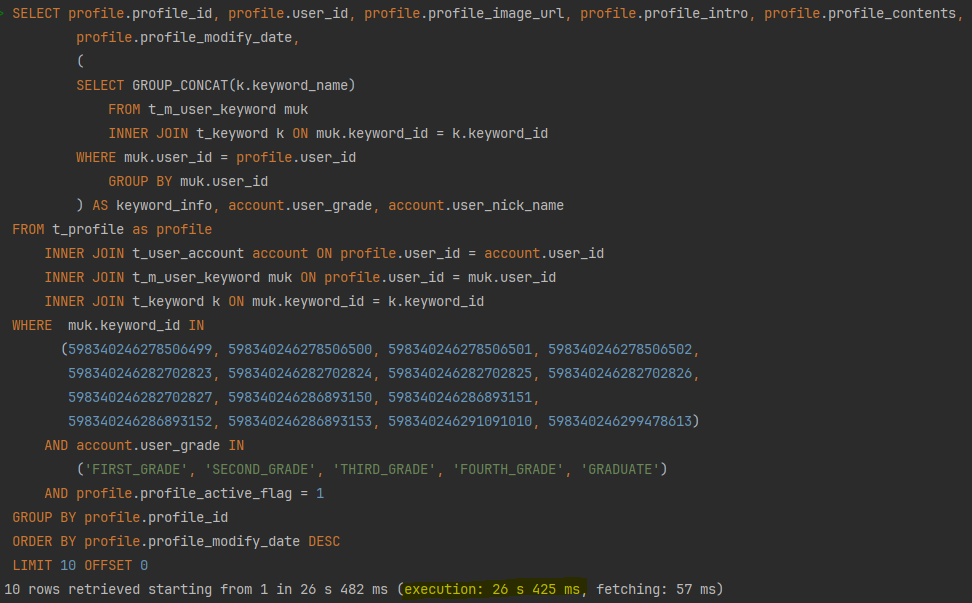
첫페이지 임에도 너무 긴 시간이 소요되었으며, 사용자가 페이지 후반부로 갈 수록 LIMIT OFFSET 절의 특징 때문에 기하급수적으로 응답속도가 저하되어 10페이지 기준 4분 ~ 4분 10초 가량의 시간이 소요되었습니다.

🧐 실행계획 분석
쿼리가 느린 원인을 분석하기 위해 Explain 명령어를 사용해 실행 계획을 분석했습니다. MySQL 서버는 쿼리의 실행계획을 수립할 때 사용 가능한 인덱스들로부터 조건절에 일치하는 레코드 건수를 파악해 최적의 실행계획을 선택합니다. 이 명령어로 옵티마이저가 클라이언트가 MySQL 서버에 요청한 SQL문을 어떻게 데이터를 불러올 것인지에 관해 수립한 실행 계획을 확인할 수 있습니다. 이 실행 계획 정보를 잘 활용하면 SQL 튜닝에 대한 힌트를 얻을 수 있습니다.

다음은 주요한 항목 위주로 총 6개의 실행계획 결과 필드를 해석한 내용입니다.
먼저, 첫 번째 필드 입니다.
1,PRIMARY,profile,,index,"PRIMARY,t_profile_t_user_account_user_id_fk",PRIMARY,8,,991674,10,Using where; Using temporary; Using filesortid : 1&select_type: PRIMARY- 메인 쿼리임을 의미합니다.
type: index&key: PRIMARY- 인덱스라고 표기되어 있어 "효율적으로 인덱스를 사용하고 있다" 라고 오해했던 type 입니다.
indextype은 인덱스를 처음부터 끝까지 읽는Index Full Scan으로, 풀 테이블 스캔과 동일하게 테이블의 모든 행을 읽습니다. 단지, 읽어들이는 크기가 일반적으로 작기 때문에ALL과 비교하였을 때 조금 더 빠르게 처리됩니다. 결과적으로 테이블의 모든 행을 읽어야 하기 때문에 성능저하가 발생되는 지점으로 판단했습니다. key: PRIMARY에서 profile 테이블의 기본 키(PRIMARY KEY) 인덱스를 사용하고 있음을 나타냅니다.
- 인덱스라고 표기되어 있어 "효율적으로 인덱스를 사용하고 있다" 라고 오해했던 type 입니다.
rows: 991,674&filtered: 10- profile 테이블에서 약99만개의 행을 읽을 것이라 추정하며, WHERE 조건을 적용 후에 약 10%의 행이 남을 것으로 예상되고 있음을 나타냅니다.
extra: Using where; Using temporary; Using filesort- extra 라는 단어에서 주는 '별 거 없을 거 같은' 느낌과는 다르게 성능에 대한 상당히 중요한 정보를 제공하는 속성이었습니다.
- 먼저
Using where를 살펴보자면, 가장 흔하게 나타날 수 있는 코멘트로 스토리지 엔진(여기서는 InnoDB)으로부터 받은 레코드를 MySQL 엔진이 별도의 필터링(profile.profile_active_flag = 1)을 처리하였기 때문에 나타났습니다. 위에서filtered: 10결과 값을 떠올려보면 최종적으로 쿼리에 일치하는 레코드는 9.9만여건 밖에 안 되지만, 스토리지 엔진은 99만건의 레코드를 읽은 것입니다. 읽은 레코드의 10%만 사용하고 있기 때문에 매우매우 비효율적인 과정이라고 볼 수 있습니다. - 다음으로
Using temprorary코멘트는 ORDER BY 정렬과 GROUP BY 그룹화를 위해 중간결과를 담아두기 위해 임시테이블을 사용했기 때문에 나타난 결과 입니다. 만약 ORDER BY 와 GROUP BY 에서 사용한 컬럼이 동일했다면 나타나지 않았을 것 입니다. - 마지막으로
Using filesort코멘트는 ORDER BY를 처리하기 위해 사용할 적절한 인덱스가 존재하지 않아, 조회된 레코드를 정렬해야 했기 때문에 나타난 코멘트 입니다. 해당 코멘트가 출력된다면 이 쿼리는 많은 부하를 일으키고 있다는 의미입니다. 따라서 가능하다면 적절한 인덱스를 생성하는 것이 필요하다고 판단했습니다.
두 번째 필드의 실행계획 입니다.
1,PRIMARY,account,,eq_ref,PRIMARY,PRIMARY,8,profile.user_id,1,30,Using wheretype: eq_ref- type 유형 중 효율적인 조인 유형입니다. profile 테이블의 각 행에 대해 account 테이블에서 유니크 인덱스를 사용하여 반드시 단 1건만 존재하는 행을 읽습니다.
rows: 1&filtered: 30&Extra: Using where- 각 profile 행에 대해 account 테이블에서 1 행만 읽으며, WHERE 조건
account.user_grade IN ('FIRST_GRADE', 'SECOND_GRADE', 'GRADUATE')을 적용한 후 약 30%의 행이 필터를 통과합니다. 때문에Using where코멘트가 나타났습니다.
- 각 profile 행에 대해 account 테이블에서 1 행만 읽으며, WHERE 조건
세 번째 필드의 실행계획 입니다.
1,PRIMARY,muk,,ref,"t_m_user_keyword_t_keyword_keyword_id_fk,t_m_user_keyword_t_user_account_user_id_fk",t_m_user_keyword_t_user_account_user_id_fk,8,profile.user_id,5,100,Using whereref: profile.user_id- ref 칼럼의 값을 통해 muk.user_id = profile.user_id로 조인되고 있음을 확인할 수 있습니다.
type : ref&rows: 5- 유니크하지 않은 인덱스를 사용하여 조인되며, 각 profile.user_id에 대해 muk 테이블에서 약 5개의 행이 평균적으로 일치하고 있음을 알 수 있습니다.
- 인덱스의 종류와 관계없이 Equal Join 으로 조회할 때 ref 타입이 사용됩니다. eq_ref보다는 빠르지 않지만, 동등 조건으로만 비교되므로 빠른 조회 방법 중 하나이기 때문에 문제가 없다고 판단했습니다.
네 번째 필드의 실행계획 입니다.
1,PRIMARY,k,,eq_ref,PRIMARY,PRIMARY,8,muk.keyword_id,1,100,Using indextype: eq_ref&ref:muk.keyword_id- k 테이블이 muk과 keyword_id으로 조인하고 있습니다.
- 유니크 인덱스를 사용하여 조인하기 때문에 문제 없다고 판단했습니다.
Extra: Using index- 해당 코멘트는 인덱스만 읽어서 쿼리를 처리할 수 있을 때 표시됩니다.
커버링 인덱스라고도 부릅니다. 필요한 컬럼이 모두 인덱스에 있기 때문에 데이터 파일을 읽어 올 필요가 없습니다. 매우 빠른 속도로 처리되는 부분임을 나타냅니다.
- 해당 코멘트는 인덱스만 읽어서 쿼리를 처리할 수 있을 때 표시됩니다.
(서브쿼리)다섯 번째 필드의 실행계획 입니다.
2,DEPENDENT SUBQUERY,muk,,ref,"t_m_user_keyword_t_keyword_keyword_id_fk,t_m_user_keyword_t_user_account_user_id_fk",t_m_user_keyword_t_user_account_user_id_fk,8,func,5,100,id: 2&select_type: DEPENDENT SUBQUERY- 서브쿼리 이며, 외부쿼리에 종속되어 있음을 알 수 있습니다.
- `ref: func``
- 참조용으로 사용되는 값인
profile.user_id를 그대로 사용하는 것이 아니라 일련의 연산을 거쳐서 참조하고 있음을 의미합니다.GROUP_CONCAT()함수를 사용하고 있기 때문에 나타났습니다.
- 참조용으로 사용되는 값인
(서브쿼리)여섯 번째 필드의 실행계획 입니다.
2,DEPENDENT SUBQUERY,k,,eq_ref,PRIMARY,PRIMARY,8,muk.keyword_id,1,100,type: eq_ref- 해당 필드도, 유니크 인덱스를 사용하여 조인하기 때문에 문제 없다고 판단했습니다.
🚀 페이징 쿼리 개선하기 (27s → 0.9s)
위의 실행계획 분석 결과를 바탕으로 쿼리를 개선할 방법을 찾던 중, 커버링 인덱스 적용을 먼저 시도해보았습니다.
커버링 인덱스
인덱스는 데이터를 효율적으로 찾는 방법이지만, MySQL의 경우 인덱스안에 포함된 데이터를 사용할 수 있으므로 이를 잘 활용한다면 실제 데이터까지 접근할 필요가 전혀 없습니다. 이처럼 쿼리를 충족시키는 데 필요한 모든 데이터를 갖고 있는 인덱스를 커버링 인덱스 (Covering Index 혹은 Covered Index) 라고합니다.
다시말해, SELECT, WHERE, ORDER BY, GROUP BY 등에 사용되는 모든 컬럼이 인덱스의 구성요소인 경우를 얘기합니다. 커버링 인덱스가 적용되면 아래와 같이 EXPLAIN 결과 (실행 계획) 의 Extra 필드에 Using index 가 표기됩니다.
인덱스 생성
- 해당 쿼리에서 사용된 profile 테이블의 컬럼은
profile_id, user_id, profile_modify_date, profile_intro, profile_image_url, profile_active_flag입니다. 해당 컬럼들을 사용해 인덱스를 생성할 때 주의해야할 점이 있습니다. WHERE, GROUP BY, ORDER BY 각각의 절이 인덱스를 사용하지 않는 경우를 고려해야 합니다.
GROUP BY
- 먼저 GROUP BY 절의 경우, 명시된 컬럼이 인덱스 컬럼의 순서와 같아야 합니다. 예를들어 현재 GROUP BY 절에
profile_id만 존재하기 때문에, 해당 컬럼으로 시작되는 인덱스만 사용할 수 있습니다.
WHERE + GROUP BY
- 여기서 WHERE 조건과 GROUP BY가 함께 사용되면 WHERE 조건이 동등 비교일 경우 GROUP BY 절에 해당 컬럼은 없어도 인덱스가 적용 됩니다. 현재 원본 쿼리가 다음과 같기 때문에
(profile_active_flag, profile_id)인덱스는 사용 가능합니다.AND profile.profile_active_flag = 1 GROUP BY profile.profile_id
ORDER BY
- ORDER BY 절의 경우에는, 인덱스의 컬럼이 ORDER BY의 컬럼과 순서와 정렬 방향(ASC/DESC)이 모두 일치해야 합니다. 따라서 ORDER BY 절 최적화를 위해서는 인덱스의 첫 번째부터
(profile_modify_date, user_id)순서로 컬럼이 있어야 합니다. 게다가 인덱스에 존재하지 않는 컬럼이 뒤에 존재하는 경우에도 해당 인덱스를 사용불가 합니다.
WHERE + ORDER BY
- 여기서 GROUP BY와 마찬가지로 ORDER BY 역시 WHERE 조건이 동등 비교인 경우에 ORDER BY 절에 해당 컬럼이 없어도 인덱스가 적용 됩니다. 따라서 쿼리가 다음과 같은 경우에
(profile_active_flag, profile_modify_date DESC, user_id DESC)인덱스는 사용 가능합니다.AND profile.profile_active_flag = 1 ORDER BY profile.profile_modify_date DESC, profile.user_id DESC
WHERE + GROUP BY + ORDER BY
- 위에서 정리한 인덱스 적용 원칙들을 참고하여 세 가지 절이 모두 있는 경우를 가정해보면, WHERE 절에서 사용한 컬림이 인덱스의 가장 앞에 존재하며, GROUP BY 에서 사용된 컬럼과 그 순서가 일치하면서, ORDER BY 절에 존재하는 컬럼들과 인덱스에 존재하는 컬럼, 순서, 정렬 방향이 모두 일치해야 합니다.
- 따라서, 원본쿼리를 기준으로 인덱스 적용 원칙을 지키기 위해서는 다음과 같이 쿼리를 수정해야 했습니다.
... AND profile.profile_active_flag = 1 GROUP BY profile.profile_id, profile.profile_modify_date, profile.user_id ORDER BY profile.profile_id, profile.profile_modify_date DESC, profile.user_id DESC - 그리고 커버링 인덱스
CREATE INDEX idx_t_profile_covering ON t_profile(profile_active_flag, profile_id, profile_modify_date DESC, user_id DESC, profile_intro, profile_image_url);를 추가하면 아래와 같이 Extra: Using Index 코멘트가 출력되는 것을 확인할 수 있었습니다. 
쿼리 수정
그러나, 이렇게 수정된 쿼리는 최근 수정한 프로필을 먼저 보여줘야 하는 정책을 위반하기 때문에 반영될 수 없었습니다. 대신, 대안으로 쿼리를 수정해 GROUP BY profile.profile_id를 제거했습니다. 수정된 쿼리는 다음과 같습니다.
SELECT
p.profile_id, p.user_id, p.profile_modify_date, p.profile_intro, p.profile_image_url
,(SELECT GROUP_CONCAT(k.keyword_subject)
FROM t_m_user_keyword muk
INNER JOIN t_keyword k ON muk.keyword_id = k.keyword_id
WHERE muk.user_id = p.user_id
GROUP BY muk.user_id
) AS keyword_names
,u.user_grade, u.user_nick_name
FROM
t_profile as p
INNER JOIN t_user_account u ON p.user_id = u.user_id
AND u.user_grade IN ('FIRST_GRADE', 'SECOND_GRADE', 'THIRD_GRADE', 'FOURTH_GRADE', 'GRADUATE')
INNER JOIN
(
SELECT muk.user_id
FROM t_m_user_keyword muk
WHERE muk.keyword_id IN (
598340246278506499, 598340246278506500, 598340246278506501, 598340246278506502,
598340246282702823, 598340246282702824, 598340246282702825, 598340246282702826,
598340246282702827, 598340246286893150, 598340246286893151, 598340246286893152,
598340246286893153, 598340246291091010, 598340246299478613
)
GROUP BY muk.user_id
) filtered_users ON p.user_id = filtered_users.user_id
WHERE p.profile_active_flag = 1
ORDER BY p.profile_modify_date DESC, p.user_id DESC
LIMIT 10 OFFSET 0;GROUP BY 절을 제거했기 때문에, 인덱스에 존재했던 profile_id를 제거하고 다음과 같이 새로운 인덱스를 생성했습니다. 그리고 수정된 쿼리에 다시 실행계획을 출력해보면 다음과 같이 Using Index 가 표시며 커버링 인덱스가 적용되고 있음을 확인할 수 있습니다.

CREATE INDEX idx_t_profile_covering_2 ON t_profile(profile_active_flag, profile_modify_date DESC, user_id DESC, profile_intro, profile_image_url);GROUP BY절이 사라졌기 때문에profile_id컬럼이 인덱스에서의 위치가 더이상 중요하지는 않지만,SELECT절에서는 여전히 사용되고 있습니다. 그럼에도 인덱스를 생성할 때profile_id컬럼을 명시하지 않은 이유는 MySQL 스토리지 엔진의 특징 때문입니다.InnoDB의 모든 테이블은Clustering Index로 구성되어 있습니다. 그리고 모든Non Clustered Index(Secondary Index)는 데이터 레코드의 주솟값으로PK를 가집니다. 즉,Clustered Key가 항상 포함되어 있습니다. 따라서profile_id가 포함되어 있지 않아도 생성한 인덱스에profile_id칼럼이 같이 저장된 효과를 냅니다.
쿼리가 수정됨에 따라 실행계획 출력 결과 다시 살펴보면, 이전과는 다른 새로운 행이 2개 추가되었습니다.
3,DERIVED,muk,,index,"t_m_user_keyword_t_keyword_keyword_id_fk,t_m_user_keyword_t_user_account_user_id_fk",t_m_user_keyword_t_user_account_user_id_fk,8,,1687896,100,Using whereselect_type: DERIVED- DERIVED는 파생 테이블을 의미하며, FROM 절의 서브쿼리를 나타냅니다.
type: index- 전체 인덱스 스캔을 수행하고 있습니다. 이는 인덱스를 사용하여 테이블의 모든 행을 읽는 것을 의미합니다. 개선할 필요성이 있습니다.
1,PRIMARY,<derived3>,,ref,<auto_key0>,<auto_key0>,8,p.user_id,10,100,Using indexselect_type: PRIMARY&table: <derived3>- 이 행은 메인쿼리가 from절의 파생테이블인 filtered_users와 어떻게 조인되는지를 보여줍니다.
- id가 3인 파생테이블을 가리키고 있습니다.
key: <auto_key0>- MySQL이 파생 테이블에 대해 자동으로 생성한 임시 인덱스를 의미합니다.
ref: p.user_id- 조인에 사용된 컬럼은 p.user_id이며, 이는 t_profile 테이블의 user_id입니다. 즉, 조인 조건이 p.user_id = filtered_users.user_id임을 나타냅니다.
카디널리티를 고려한 t_m_user_keyword 테이블 복합 인덱스 생성
profile 테이블에는 적절한 인덱스를 생성하여 성능을 개선했으니, 다음으로 t_m_user_keyword 테이블에 인덱스를 생성할 차례입니다.
사용자 테이블과 키워드 테이블의 N:M 관계를 저장하기 위해 t_m_user_keyword 매핑 테이블이 존재합니다. 해당 테이블은 현재 파생 테이블(filtered_users)에서 사용되고 있는데, keyword_id로 필터링하고 user_id를 가져오고 있습니다.
(SELECT muk.user_id
FROM t_m_user_keyword muk
WHERE muk.keyword_id IN (
598340246278506499, 598340246278506500, 598340246278506501, 598340246278506502,
598340246282702823, 598340246282702824, 598340246282702825, 598340246282702826,
598340246282702827, 598340246286893150, 598340246286893151, 598340246286893152,
598340246286893153, 598340246291091010, 598340246299478613
)
GROUP BY muk.user_id ) as 'filtered_users'SELECT 구문의 처리 순서를 고려하여 인덱스를 생성할 때, 다음과 같이 WHERE 절에서 사용된 keyword_id 를 선두에 두고, 필터링된 레코드를 그룹핑 하기 때문에 GROUP BY 절에서 사용된 user_id 를 두번째로 지정해 생성했습니다.
create index idx_t_m_user_covering2 on t_m_user_keyword (keyword_id, user_id);
그러나, 옵티마이저는 해당 인덱스를 사용하지 않았으며, extra: Using where가 표기되었습니다.

따라서 아래와 같이 순서를 뒤바꾼 복합인덱스도 생성하여 테스트 해본 결과, 옵티마이저는 순서를 바꾼 복합 인덱스를 선택했습니다.
create index idx_t_m_user_covering1 on t_m_user_keyword (user_id, keyword_id);
USE INDEX 옵티마이저 힌트를 사용하여 강제로 (keyword_id, user_id) 인덱스를 사용하도록 처리하자, 50% 가량 속도가 저하되었습니다.
USE INDEX:
원인은 카디널리티에 있었습니다. 어떠한 컬럼의 중복되지 않는 레코드의 수 즉, Cardinality 숫자가 높아야 인덱스 조회 시 더 효율적으로 인덱스를 활용할 수 있습니다. show index from t_m_user_keyword; 구문을 사용하면 해당 테이블의 인덱스 정보를 확인할 수 있습니다.

밥풀 서비스에 존재하는 keyword_id는 현재 20여가지 인 반면, user_id 는 사용자 테이블의 PK 으로, 카디널리티가 압도적으로(약100만) 높습니다. 따라서 (user_id, keyword_id) 순으로 복합인덱스를 생성하는 것이 더욱 효율적임을 증명했습니다.
JOIN 성능을 고려한 인덱스
마지막으로 t_user_account 테이블에 인덱스를 추가했습니다. JOIN, WHERE, SELECT 절에서 사용된 컬럼들을 고려하여 다음과 같은 인덱스를 생성했습니다.
CREATE INDEX idx_user_account_covering1 ON t_user_account (user_id, user_grade, user_nick_name);- InnoDB 스토리지 엔진에서 보조 인덱스(Secondary Index)는 기본 키(PK)를 자동으로 포함함에도 불구하고, 인덱스 생성 시
user_id를 첫 번째 컬럼으로 배치한 이유는, 인덱스 탐색 시에는 인덱스 정의에 명시적으로 포함된 컬럼만 사용되기 때문입니다. 따라서, 인덱스 검색 조건에 사용될 컬럼은 인덱스 정의에 명시적으로 포함되어야 합니다. - 그러나, 옵티마이저가 새로 생성한 인덱스를 사용하지 않고 t_user_account 테이블의 PRIMARY KEY를 사용하고 있습니다. 이는 옵티마이저가 PRIMARY KEY를 사용하여 JOIN을 수행하는 것이 더 효율적이라고 판단했기 때문입니다.
- 따라서, 해당 테이블에는 별도의 인덱스를 추가하지 않기로 결정했습니다.
데이터 개수 기반 방식을 결합
인덱스를 적용했을때 평균 시간을 약 900ms까지 줄일 수 있었으나, 조회 시간이 선형적으로 증가하는 문제는 해결이 불가했습니다. 이를 위해 데이터 개수 기반 방식을 수정된 쿼리에 결합하였습니다.
데이터 개수 기반 방식이란, 지정된 건수 만큼 결과 데이터를 반환하는 형태로, 처음 쿼리를 실행할 때와 그 이후 쿼리를 실행할 때의 쿼리 형태가 달라집니다. 우리의 수정된 페이징 쿼리는 ORDER BY 절에서 범위 조건 컬럼인 profile_modify_date 이 포함되어 있습니다. 해당 컬럼을 선두에 명시하여 (profile_modify_date, profile_id) 인덱스를 사용해서 file sort 작업 없이 원하는 건수만큼 순차적으로 데이터를 읽을 수 있어 처리 효율이 향상됩니다. 예를들어 첫 페이지 이후의 쿼리는 다음과 같이 작성할 수 있습니다.
...
where
(
(
profile_modify_date = {'페이지에 노출된 마지막 프로필의 수정일자'}
AND
id > {'페이지에 노출된 마지막 사용자 식별 값'}
)
or
(
profile_modify_date < {'페이지에 노출된 마지막 프로필의 수정일자'}
)
)
order by profile_modify_date desc, user_id desc
...페이징 카운트 쿼리 개선
밥풀 프로젝트는 페이징 방법으로 스크롤 또는 더보기 방식이 아닌, 전형적인 페이지 번호를 나타내는 페이지네이션방법으로 기획되었습니다. 따라서, 특정 조건들로 사용자가 프로필 페이징을 요청하면, 하단에 페이지 번호를 명시하기 위해 COUNT 쿼리의 수행이 반드시 필요합니다.
COUNT(*) vs SELECT * vs COUNT(DISTINCT column) vs COUNT(column) 비교
SELECT COUNT(*) 쿼리는 WHERE 조건을 만족하는 모든 행의 조회가 끝나야 개수를 반환할 수 있습니다. 차라리 SELECT * 쿼리를 수행 후, 애플리케이션 레이어에서 리스트 사이즈를 측정하는 것이 더 빠른 경우가 많습니다. 물론 네트워크 사용량은 COUNT(*) 이 더 적긴 합니다.
일반적으로 한 페이지당 보여주는 행의 개수는 10~50 정도에 페이지 번호의 범위는 10~20 정도이므로, 프로젝트 정책에 따라 적절한 값을 정한 뒤 SELECT * ~ LIMIT 을 사용하면 성능향상을 기대할 수 있습니다.
COUNT 쿼리에서도 커버링 인덱스를 적용해볼 수 있습니다만, 모든 구문에서 사용되는 컬럼을 커버하는 인덱스를 추가하기에 무리가 있고, 검색 필터 또는 조건이 기획 변경에 따라 변화 가능성이 열려 있음을 고려한 결과 커버링 인덱스는 적용에 어려움이 있다고 판단했습니다.
COUNT(DISTINCT) 는 COUNT(*) 와 동작방식이 상이합니다. 모든 행의 개수만 확인하는 COUNT(*) 과 달리 COUNT(DISTINCT) 는 중복 제거를 위해 테이블의 행을 모두 임시테이블로 복사(중복검사/행삽입) 후 임시테이블에서 최종 행의 개수를 반환합니다. 따라서 COUNT(*) 보다 성능이 좋지 않은 경우가 대부분입니다.
마지막으로 COUNT(column) 과 COUNT(*) 비교하자면, column이 Null 허용인 경우 각 행 마다 Null 여부를 확인해야 하기 때문에 COUNT(*) 보다 매우 낮은 성능을 보이며, Not null 컬럼의 경우, 각 행 마다 Null 여부를 확인하지는 않지만 inoodb_parallel_read_threads 설정 값에 따라 쿼리 성능을 달라질 수 있기 때문에 높은 확률로 COUNT(*) 성능이 더 좋습니다.
이렇게 4가지 정도의 집계 방법을 비교하여 결과적으로 COUNT(*) 함수를 사용하게 되었습니다.
COUNT(*) 튜닝
앞서 말씀드렸듯 기획에 의해 페이지네이션 방식을 사용해야하는 상황에서 COUNT 쿼리를 사용하지 않을 수 없었습니다. 이때 고려할 수 있는 튜닝 방법으로 아래 2가지가 있습니다.
1) 표시할 페이지 번호 범위 만큼의 레코드만 건수 확인
2) 임의의 페이지 번호 표기 후, 페이지 이동 발생 시 번호 갱신
최소한의 노력(변경)으로 튜닝할 수 있는 방법을 선택하는 것이 이상적이라 판단되어 추후 페이지 번호에 대한 보정이 필요한 두 번째 대안보다 첫 번째 대안을 활용하기로 결정했습니다.
