RAG란 Ratriveal-Augment Generation의 약자로
Retriveal : 검색
Augment : 증강
Generation : 생성
검색증강생성으로 LLM 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스이다.
먼저, LLM은 주어진 맥락에 맞는 다음 문장을 확률적으로 추정하여 생성하는 방식이다.
LLM은 추정하여 생성하기 때문에 자연스럽게 Hallucination(환각)현상이 발생할 수 있다.
또한, 사용자가 구체적이고 최신의 응답을 기대할 때 오래되었거나 일반적인 정보를 제공하고, 신뢰할 수 없는 출처로부터 응답을 생성한다.
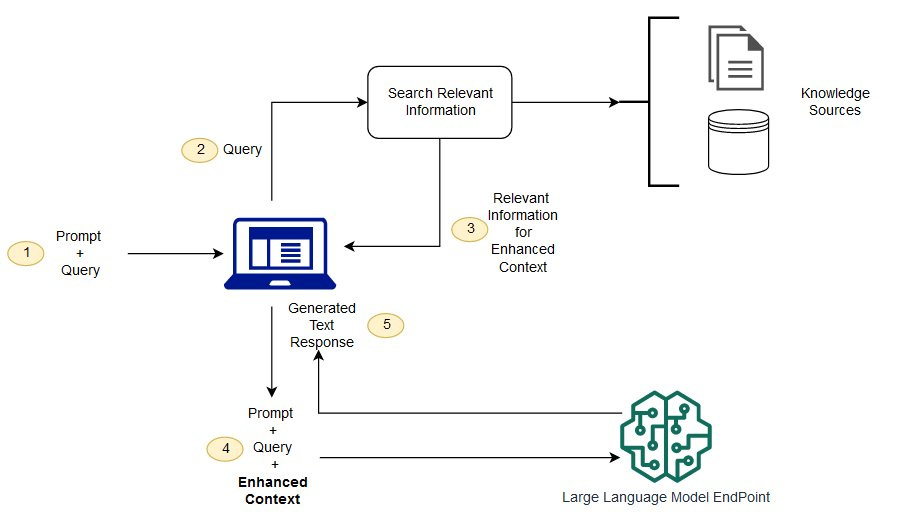
이때, LLM을 리디렉션하여 신뢰할 수 있는 사전 결정된 지식 출처에서 관련 정보를 검색하고 출력해주는 것을 RAG라고 일컫는다.
동작 방식
검색 단계
해당 단계에서 Vector DB 구성(indexing),입력 쿼리 처리(processing),쿼리에 따른 데이터 검색(searching)을 진행한다.
Indexing(데이터 준비하기)
- 데이터베이스에 문서를 저장하고 빠르게 검색할 수 있도록 구조화하는 과정이다.
- 문서 전체를 하나의 content로 담기는 어려우므로 다양한 데이터 포맷을 고려하여 분리
- 적절한 청크 사이즈를 정해 문자나 토큰 단위로 나눈다. 이는 검색 성능을 높여주는 역할을 한다.
Processing(사용자 쿼리 처리하기)
- 사용자의 입력(Query)을 처리하고, 검색을 위한 벡터 변환을 수행하는 과정이다.
- "RAG의 원리를 설명해줘" → [0.23, -0.98, 1.34, ...] 와 같이 변환
- 만약 사용자의 질문이 너무 짧아서 정보가 부족해 유사한 문서를 찾기 어렵거나, 길어서 의미가 모호해 정확한 정보를 찾지 못하는 경우를 위해 정제 혹은 확장시킨다.
Searching(쿼리와 적합한 청크 검색하기)
- 벡터 검색을 수행하고, 가장 적절한 문서를 찾아 반환하는 과정이다.
- 벡터 데이터베이스(FAISS, Pinecone 등)를 사용하여 질문과 유사한 문서 찾기
- 의미론적 검색이 가능한 Sematic, 용어 검색에 유리한 Lexical가 존재하는데 보통 Sematic 방법을 채택한다.
- 검색 결과 가중치 부여하여 문맥상 가장 적절한 문서가 최상위에 오도록 정렬한다
벡터 디비 종류
대부분 LangChain에서 지원한다(Elasticsearch,Pinecone, ChromaDB, Milvus 등이 있다.)생성 단계
해당 단계에서 검색된 정보를 기반으로 LLM이 응답을 생성하는 과정이다.
예시
아이폰 15 프로맥스와 아이폰 16 프로가 뭐가 다른거야?
→ 질문 임베딩과 문서들의 임베딩 유사도 비교
→ 가장 유사한 아이폰 15 프로맥스, 아이폰 16 프로 가이드 문서를 반환
→ RAG : LLM 프롬프트에 추가하여 답변 생성 (제원, 특징,구조 등)
→ Recommendation : 해당 상품 혹은 문서 그대로 전달
Advanced RAG
기본 RAG보다 더 정교한 검색 및 생성 기법을 적용하여 응답의 정확도와 신뢰성을 높이는 향상된 RAG 기법이다.
Multi-Query Retrieval : 쿼리를 여러 개의 버전으로 세분화 후 각각의 검색을 모두 수행함으로서 더 정교한 결과를 얻는다.
Hybrid Search : Lexical, Sematic 두 검색 결과를 모두 고려하여 searching
등등의 방법으로 성능을 개선해 사용자에게 신뢰도 높은 예측 결과를 제공한다.
