DETR 분석내용
기존의 객체 탐지기술과 비교했을때 매우 간단하며 또한 경쟁력 있는 성능을 보인다.
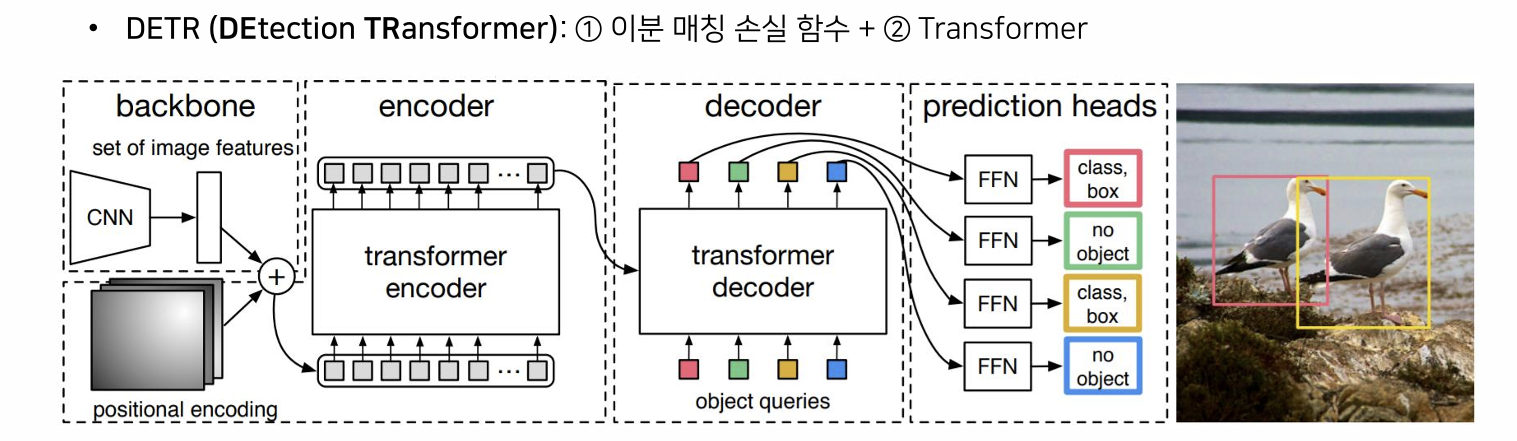
출처 - https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/DETR.pdf (4page)_
위 사진을 보면 알 수 있듯이,
backbone 으로 cnn모델을 사용해서 이미지 feature를 추출한다.
그리고 객체마다의 상대적 위치정보를 위해서 positional encoding을 추가함.
그렇게 두 정보가 인코더에 들어가게 되면,
각각의 디멘션(차원)을 가진 시퀀셜한 정보나열이 되는데,
이런 데이터들을 처리하기에 적합한 트랜스포머를 통해서 인코딩을 하게 되고, 디코더로 그 결과값들이 들어가게 되는데,
디코더에는 몇개의 쿼리를 통해서 디코딩을 하게 되는데
class와,해당 객체 위치를 bounding box로 나타낼수 있게 된다.
그래서 실제 오브젝트 디텍션 결과가 나올수 있도록 만드는게 DETR의 구조다.
이분 매칭 손실 함수?
기존 객체 탐지에는 방법들이 너무 복잡하고 다양한 라이브러리를 사용했다.
-> 사전 지식이 많이 필요했음.
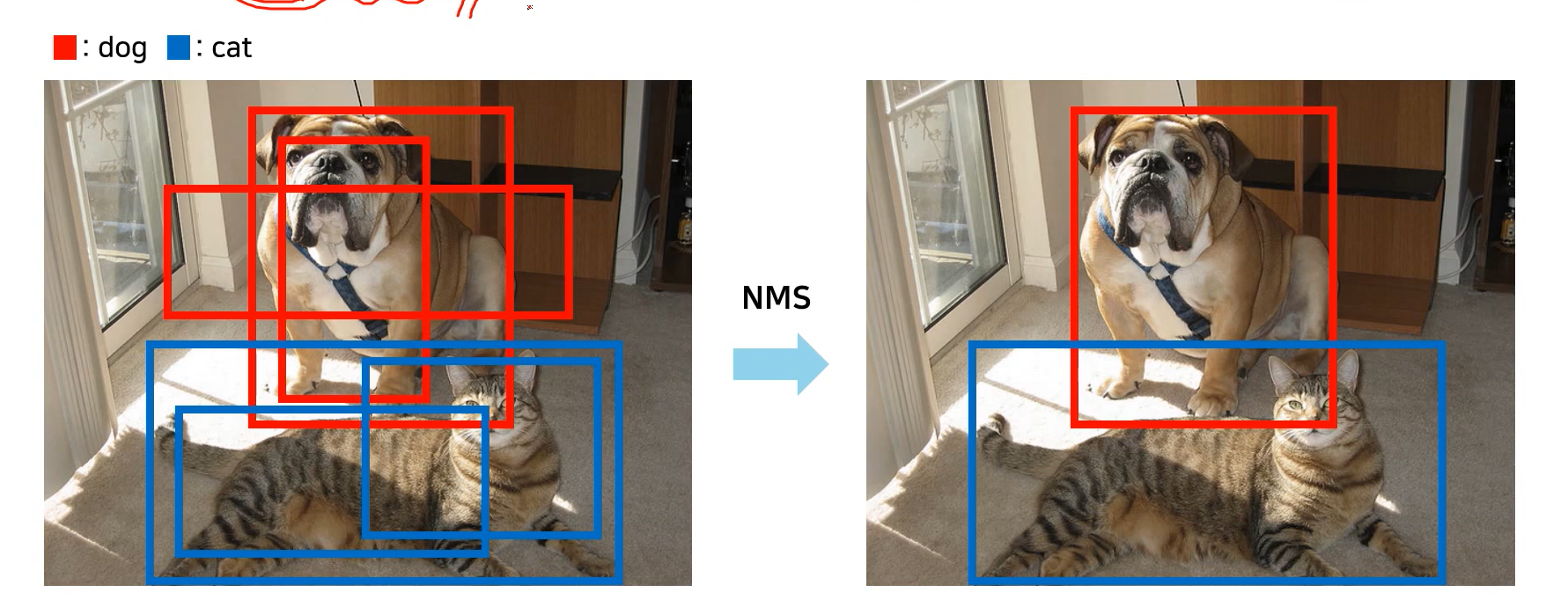
출처 - https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/DETR.pdf (2page)
사진처럼 원래는 왼쪽처럼 여러개의 bounding-box를 처리하기 위해서
NMS(Non-Maximum Suppression)을 사용해서 객체 탐지를 진행했다.
근데 그러기 위해서는 bounding-box의 형태나, 겹칠때의 처리방법등의 사진지식이 요구되었다. -> 아키텍처의 복잡화

출처 - https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/DETR.pdf (3page)
그래서 이분 매칭 을 통해서 이런 문제들(set prediction problem)을 직접적으로 해결한다
이런 문제들(set prediction problem) :
boundingbox의 순서나 겹치는 과정들..
임의로 전체 output 디멘션 의 갯수를 N개로 직접 정해버림.
이미지에서 N개 만큼의 오브젝트디텍션이 있을꺼다로 정해버리면 이제 직접적으로 해결할수 있는것이다.
-> NMS 가 필요없다.
그렇게 N개의 output 디멘션에 저장된 값과
그라운드 트루쓰를 비교하는데
이때 이분매칭을 사용한다.
사진과같은 예시를 보면
매칭을 통해서 인스턴스가 중복되지 않도록 유도할 수 있다.
(xywh)
실제 값과 예측 결과 값을 묶어서 필요없는 인스턴스도
제거가 가능하다.
그 후에 예측값이 비슷한 애들끼리 묶인걸 더 훈련시켜서
실제값과 유사해지도록 만드는거다.
학습이 잘 된다면 실제로 존재하는 위치 와 갯수 만큼만
prediction을 진행할 수 있도록 하는것
위치가 바뀐다고 해도 매칭만 잘되면 상관없기때문에
NMS 의 복잡성을 해결하는 방식이라고 할 수 있음.
트랜스 포머
연속적인 데이터의 나열이 있을때, 더 잘 학습할 수있게 하기 위한 것
어텐션을 통해서 전체 이미지의 문맥 정보를 이해함
long distance 에 대한 연관성 파악에 용이하다

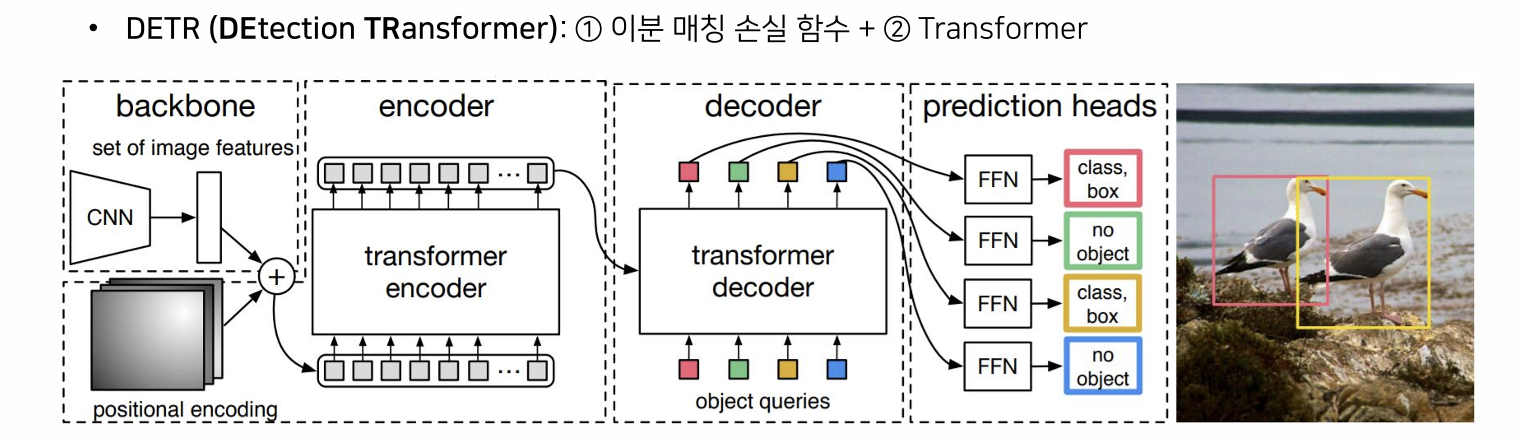
출처 - https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/DETR.pdf (5page)_
encoder 에서 이미지의 특징을 셀프어텐션을 통해서 이미지의 feature 정보간의 연관성을 파악할 수 있다.
decoder 에서 초기입력으로 N개의 쿼리를 입력으로 받고 인코딩된 정보를 통해서 전체 이미지에 대한 내용을 파악하고, 이미지 내 서로 다른 고유한 인스턴스(class, boundging box)를 구별 할 수 있다.
Encoder

출처 - https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/DETR.pdf (6page)_
d x HW 크기의 연속성을 띄는 feature map을 입력으로 받는다.
self attention map 을 시각화한 사진이다.
Decoder
출처 - https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/DETR.pdf (7page)_
Decoder 에서는 초기에 N개의 쿼리를 초기입력으로 사용함.
인코딩된 instance가 잘 구분이 되어있다면, 클래스와 경계선을 추출한다.
기본적인 아이디어 끝
-논문 시작 (End to End Object Detection with Transformers)
논문에서는 개별적인 instance를 예측해야 되는 문제로써 보고있다.
그래서 파이프라인 자체를 간소화 하는것이 목적이다(NMS 같은거 삭제)
진정한 형태의 ETE를 만들려고 함.
